基于相似度的数据信息储存方法及系统与流程
本发明涉及信息技术领域,更具体地,涉及一种基于相似度的数据信息储存方法及系统。
背景技术
大数据(bigdata),指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产,其具有5大特点:大量、高速、多样、价值、真实性。但是,目前的大数据查询多为人力手动,效率较低。因此,有必要开发一种基于相似度的数据信息储存方法及系统。
公开于本发明背景技术部分的信息仅仅旨在加深对本发明的一般背景技术的理解,而不应当被视为承认或以任何形式暗示该信息构成已为本领域技术人员所公知的现有技术。
技术实现要素:
本发明提出了一种基于相似度的数据信息储存方法及系统,其能够通过对比概要字符串与已知字符串,分类关键词并计算相似性,将储存的信息分类,提升储存与查找的效率与精度。
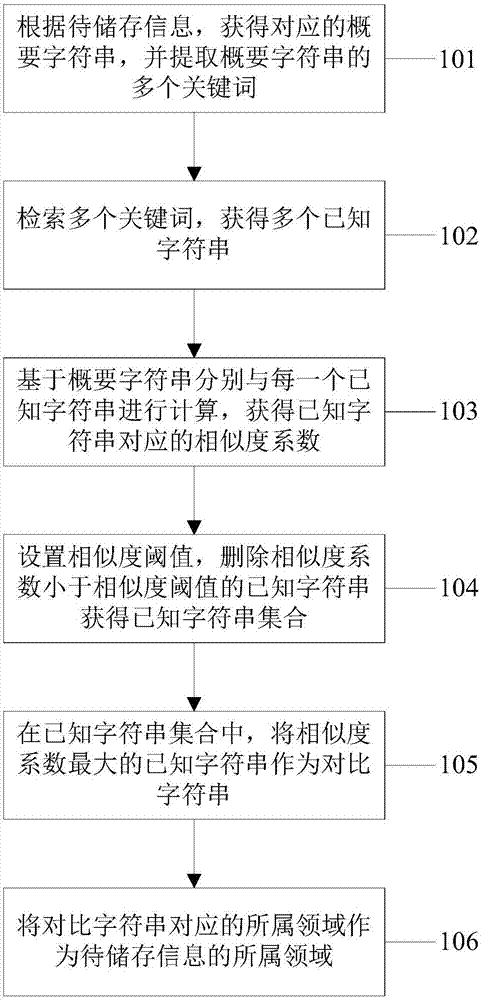
根据本发明的一方面,提出了一种基于相似度的数据信息储存方法。所述方法可以包括:根据待储存信息,获得对应的概要字符串,并提取所述概要字符串的多个关键词;检索所述多个关键词,获得多个已知字符串;基于所述概要字符串分别与每一个所述已知字符串进行计算,获得所述已知字符串对应的相似度系数,设置相似度阈值,删除所述相似度系数小于所述相似度阈值的已知字符串,获得已知字符串集合;在所述已知字符串集合中,将相似度系数最大的已知字符串作为对比字符串;将所述对比字符串对应的所属领域作为所述待储存信息的所属领域。
优选地,每一个所述已知字符串包括至少一个所述关键词。
优选地,还包括:将所述多个关键词根据重要程度进行排序,并对每一个关键词赋予重点因子。
优选地,所述相似度系数为:
fj=∑aiwi(1)
其中,fj表示第j个已知字符串的相似度系数,j取[1,m],m表示已知字符串的个数,wi表示该已知字符串与概要字符串相同的关键词,ai表示该关键词对应的重点因子,i取[1,n],n表示关键词的个数。
根据本发明的另一方面,提出了一种基于相似度的数据信息储存系统,其上存储有计算机程序,其中,所述程序被处理器执行时实现以下步骤:根据待储存信息,获得对应的概要字符串,并提取所述概要字符串的多个关键词;检索所述多个关键词,获得多个已知字符串;基于所述概要字符串分别与每一个所述已知字符串进行计算,获得所述已知字符串对应的相似度系数;设置相似度阈值,删除所述相似度系数小于所述相似度阈值的已知字符串,获得已知字符串集合;在所述已知字符串集合中,将相似度系数最大的已知字符串作为对比字符串;将所述对比字符串对应的所属领域作为所述待储存信息的所属领域。
优选地,每一个所述已知字符串包括至少一个所述关键词。
优选地,还包括:将所述多个关键词根据重要程度进行排序,并对每一个关键词赋予重点因子。
优选地,所述相似度系数为:
fj=∑aiwi(1)
其中,fj表示第j个已知字符串的相似度系数,j取[1,m],m表示已知字符串的个数,wi表示该已知字符串与概要字符串相同的关键词,ai表示该关键词对应的重点因子,i取[1,n],n表示关键词的个数。
本发明的方法和装置具有其它的特性和优点,这些特性和优点从并入本文中的附图和随后的具体实施方式中将是显而易见的,或者将在并入本文中的附图和随后的具体实施方式中进行详细陈述,这些附图和具体实施方式共同用于解释本发明的特定原理。
附图说明
通过结合附图对本发明示例性实施方式进行更详细的描述,本发明的上述以及其它目的、特征和优势将变得更加明显,其中,在本发明示例性实施方式中,相同的参考标号通常代表相同部件。
图1示出了根据本发明的基于相似度的数据信息储存方法的步骤的流程图。
具体实施方式
下面将参照附图更详细地描述本发明。虽然附图中显示了本发明的优选实施方式,然而应该理解,可以以各种形式实现本发明而不应被这里阐述的实施方式所限制。相反,提供这些实施方式是为了使本发明更加透彻和完整,并且能够将本发明的范围完整地传达给本领域的技术人员。
图1示出了根据本发明的基于相似度的数据信息储存方法的步骤的流程图。
在该实施方式中,根据本发明的基于相似度的数据信息储存方法可以包括:步骤101,根据待储存信息,获得对应的概要字符串,并提取概要字符串的多个关键词;步骤102,检索多个关键词,获得多个已知字符串;步骤103,基于概要字符串分别与每一个已知字符串进行计算,获得已知字符串对应的相似度系数;步骤104,设置相似度阈值,删除相似度系数小于相似度阈值的已知字符串,获得已知字符串集合;步骤105,在已知字符串集合中,将相似度系数最大的已知字符串作为对比字符串;步骤106,将对比字符串对应的所属领域作为待储存信息的所属领域。
在一个示例中,每一个已知字符串包括至少一个关键词。
在一个示例中,还包括:将多个关键词根据重要程度进行排序,并对每一个关键词赋予重点因子。
在一个示例中,相似度系数为:
fj=∑aiwi(1)
其中,fj表示第j个已知字符串的相似度系数,j取[1,m],m表示已知字符串的个数,wi表示该已知字符串与概要字符串相同的关键词,ai表示该关键词对应的重点因子,i取[1,n],n表示关键词的个数。
具体地,根据本发明的基于相似度的数据信息储存方法可以包括:根据待储存信息,获得对应的概要字符串,通过分析,提取概要字符串的多个关键词,将多个关键词根据重要程度进行排序,并对每一个关键词赋予重点因子,基于多个关键词,通过检索,获得多个已知字符串,其中,每一个已知字符串包括至少一个关键词,将已知字符串与概要字符串相同的关键词及其对应的重点因子代入公式(1),计算求取每一个已知字符串对应的相似度系数,设置相似度阈值,删除相似度系数小于相似度阈值的已知字符串,减少工作量,获得已知字符串集合;在已知字符串集合中,将相似度系数最大的已知字符串作为对比字符串;将对比字符串对应的所属领域作为待储存信息的所属领域。
本方法通过对比概要字符串与已知字符串,分类关键词并计算相似性,将储存的信息分类,提升储存与查找的效率与精度。
应用示例
为便于理解本发明实施方式的方案及其效果,以下给出一个具体应用示例。本领域技术人员应理解,该示例仅为了便于理解本发明,其任何具体细节并非意在以任何方式限制本发明。
根据本发明的基于相似度的数据信息储存方法包括:
根据待储存信息,获得概要字符串为华为p20(极光色,6gb,128gb),通过分析,提取概要字符串的5个关键词,并将5个关键词根据重要程度进行排序为华为、p20、128gb、极光色、6gb,并对每一个关键词赋予重点因子:华为为0.3、p20为0.25、128gb为0.25、极光色为0.1、6gb为0.1,基于5个关键词,通过检索,获得3个已知字符串为华为p20黑色6gb64gb、华为mate10与p20pro,将已知字符串与概要字符串相同的关键词及其对应的重点因子代入公式(1),计算求取华为p20黑色6gb64gb对应的相似度系数为0.65,华为mate10对应的相似度系数为0.3,p20pro对应的相似度系数为0.25,设置相似度阈值为0.3,删除相似度系数小于相似度阈值的已知字符串,获得已知字符串集合,在已知字符串集合中,将相似度系数最大的已知字符串华为p20黑色6gb64gb作为对比字符串,将对比字符串对应的所属领域作为待储存信息的所属领域。
综上所述,本发明通过对比概要字符串与已知字符串,分类关键词并计算相似性,将储存的信息分类,提升储存与查找的效率与精度。
本领域技术人员应理解,上面对本发明的实施方式的描述的目的仅为了示例性地说明本发明的实施方式的有益效果,并不意在将本发明的实施方式限制于所给出的任何示例。
根据本发明的实施方式,提供了一种基于相似度的数据信息储存系统,其上存储有计算机程序,其中,所述程序被处理器执行时实现以下步骤:根据待储存信息,获得对应的概要字符串,并提取所述概要字符串的多个关键词;检索所述多个关键词,获得多个已知字符串;基于所述概要字符串分别与每一个所述已知字符串进行计算,获得所述已知字符串对应的相似度系数;设置相似度阈值,删除所述相似度系数小于所述相似度阈值的已知字符串,获得已知字符串集合;在所述已知字符串集合中,将相似度系数最大的已知字符串作为对比字符串;将所述对比字符串对应的所属领域作为所述待储存信息的所属领域。
在一个示例中,每一个已知字符串包括至少一个关键词。
在一个示例中,还包括:将多个关键词根据重要程度进行排序,并对每一个关键词赋予重点因子。
在一个示例中,相似度系数为:
fj=∑aiwi(1)
其中,fj表示第j个已知字符串的相似度系数,j取[1,m],m表示已知字符串的个数,wi表示该已知字符串与概要字符串相同的关键词,ai表示该关键词对应的重点因子,i取[1,n],n表示关键词的个数。
本发明通过对比概要字符串与已知字符串,分类关键词并计算相似性,将储存的信息分类,提升储存与查找的效率与精度。
本领域技术人员应理解,上面对本发明的实施方式的描述的目的仅为了示例性地说明本发明的实施方式的有益效果,并不意在将本发明的实施方式限制于所给出的任何示例。
以上已经描述了本发明的各实施方式,上述说明是示例性的,并非穷尽性的,并且也不限于所披露的各实施方式。在不偏离所说明的各实施方式的范围和精神的情况下,对于本技术领域的普通技术人员来说许多修改和变更都是显而易见的。
- 还没有人留言评论。精彩留言会获得点赞!