融合多通道文本特征的药物毒物不良反应智能问答方法与流程
本发明涉及一种融合多通道文本特征的药物毒物不良反应智能问答方法。
背景技术
药物和毒物种类繁多,因装修、服装、食品、药物等因素出现不良反应较为常见,而日常或临床不良反应因体质、轻重、来源等不同,表现亦有差异,主诉语言规范性不好、形式不一,如何辅助人们日常或医师临床实现快速、智能的药物、毒物定性比对与种类归属,缩小不良反应的排查范围,对于临床诊治与预防保健,都具有较好的辅助决策作用与实用价值。
目前生活中不良反应的未知毒物筛查,还存在以下问题:(1)病人体内低药物、毒物浓度加大了分析的难度;(2)中毒症状与疾病难以区分,需中毒病人的主动联想配合;(3)检测方法的时效性;(4)药物毒物检测专业,检测的时间与人力成本较高,容易错过轻度反应时的处理时机。当前基于统计分析与深度学习拟合的文本处理方法,对高质量、大规模领域语料要求较高,而单一药物毒物不良反应案例数据非常有限,面对非规范的开放性不良反应与医案描述,药物毒物不良反应特征处理则极易陷入文本特征稀疏性的问题,限制了药物毒物案例的使用效率。
技术实现要素:
本发明的目的就是提供一种准确度高、可靠性好、实用性强、成本低的融合多通道文本特征的药物毒物不良反应智能问答方法。
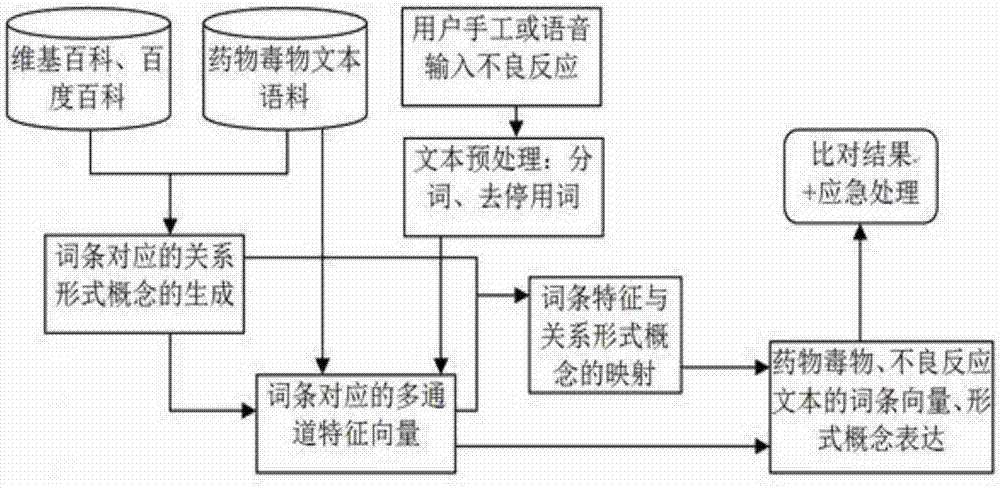
本发明的融合多通道文本特征的药物毒物不良反应智能问答方法,是一种采用自然语言文本处理技术,利用不同通道文本特征,即包括底层分布特征、词条条目特征、词条分类标签特征、目录特征,把特征表征与形式化概念进行融合处理的策略,实现快速、高效的药物毒物不良反应比对映射的算法,其包括以下四个步骤:
1、形式化概念的构建:获取开放及药物毒物相关文本语料,解析获得相应的关系形式背景及形式化概念,具体步骤如下:
(1.1)关系形式背景:定义领域概念背景形式,即以关系为核心的关系形式背景,关系形式背景定义为一个三元关系组集合k,k=(g,m,ri),其中g为词条对象的集合;m为标注词条的集合;ri其值域为g、m间的多值实体关联的集合,(g,m,ri)∈k表示g在关联ri下,具有m值,关系形式背景简单记为k。定义中多值关联ri泛指一切形式上的关联,可以是通用的is-a关系、组成关系、位置关系、因果关系,或是特定领域存在的关联或属性,如研究属性、纲目属性、出生属性,乃至未名关联等等,ri可以是明晰单一的、也可是模糊复合的。
(1.2)关系形式概念:定义以关系为核心的形式化概念,定义如下:
在关系形式背景k=(g,m,ri)下,对于集合
(a)映射f1:g0→ri,记为
映射
(b)映射f2:m0→ri,记为
映射
如果集合间分别满足条件
(1.3)基于步骤(1.1)、(1.2)的定义,从开放协作数据库中,如中文维基百科、百度百科、药物毒物领域文本等,获取词条关系形式背景以及关系形式概念。
(1.4)重复(1.3)迭代扩展关系形式背景与关系形式概念,直至关系形式概念格规模达到预定规模,形式化概念初始化结束。
2、多通道词向量构建:以上述关系形式概念为标识基础,对文本词条多通道特征进行训练,其训练思路,采用经典的skip-gram模型思路,不同通道文本特征处理的具体步骤如下:
(2.1)文本句法分布特征:基于原始药物毒物、词条通用性语料,进行简单分词预处理;
(2.2)词条目录特征的处理:词条的目录信息,从一定的角度,刻画了词条的语义,算法以词条为目标词条,目录词条为上下文词条,对词条-目录信息,进行神经网络的训练,获取特征向量;
(2.3)词条标签特征的处理:词条标签,是词条语义的不同粒度的类别信息。算法以词条为目标词条,标签词条为上下文词条,对词条-标签信息,进行神经网络的训练,获取特征向量;
(2.4)词条条目特征的处理:词条条目,是词条属性信息。算法以词条为目标词条,条目词条为上下文词条,对词条-条目信息,进行神经网络的训练,获取特征向量;
以上特征的提取,没有考虑概念的完整逻辑性,只是从不同的角度对词条的所有语义进行了表征,词条特征区分性好,但可解释性不好。
3、多通道特征向量与形式概念的映射:概念看成特征的组合与指代,即不同的特征组合形成不同的概念,而不同概念指代了某一特征的集合,为了刻画领域文本概念,需建立特征向量与形式概念的映射,具体步骤如下:
利用前面获取不同通道的特征向量以及关系形式概念格,采用随机森林集成学习方法,对特征与概念的映射关系,进行训练;
(3.1)以多关系形式概念为标签,每一词条只以某一标签进行最大熵计算,完成向量分量分裂值的确定;
(3.2)如果存在多个概念标签其对应的最大信息增益相同,则当前以内涵少的概念进行分裂;
(3.3)重复上述过程,直至每个子集的标签数小于某阈值。
4、最后,采用随机森林决策树,对药物毒物不良反应进行比对决策,该过程的步骤如下:
(4.1)药物毒物既存医案文本的处理,获取每个医案的词条向量与关系形式概念集;
(4.2)不良反应文本描述的简单文本预处理,获取其对应词条的尽可能多的特征向量;
(4.3)基于随机森林的,进行特征向量的分类决策,计算出其向量与关系形式概念的相似度;
(4.4)基于多通道特征向量与关系形式概念,在词条与概念两个语义层次,实现不良反应与药物读物的智能比对;
(4.5)推荐多个候选疑似药物毒物及其应急处理方案。
本发明的药物毒物不良反应比对映射方法,采用的硬件设备为手机,首先,病人提供不良反应症状信息;然后,算法进行文本语义的分析,实现快速的药物毒物的比对与筛选,给出不良反应处理建议规程。
本发明的融合多通道文本特征的药物毒物不良反应智能问答方法与现有技术相比有如下优点:
1、文本语料的规模与标识质量要求不高,减少了特征工程的影响,特征的获取通道更为全面,可以更好缓解特征稀疏的问题;
2、在词向量特征表征基础上,引入了更多的结构化概念逻辑,使其语义表达形式,兼顾了定量计算性与定性解释性。
3、由于引入了更多的语义背景,对不同背景用户的开放文本描述的适应性更好;
4、本方法比对的过程,无需人工干预,整个语义比对过程全自动完成,优于以往浅层次检索与工作量极大的本体工程;
5、本方法采用移动设备实现,软硬件简单可靠,使用方便,具有药物毒物比对方便、成本低廉、筛查、应对时效性好等优势。
附图说明
图1为本发明的系统结构组成框图。
具体实施方式
一种融合多通道文本特征的药物毒物不良反应智能问答方法,所采用的系统包括手机、文本语义特征处理软件和用户。用户输入不良反应症状,方法自动把药物毒物比对结果与处理办法通过移动设备呈现在用户面前,简易快捷、时效性好。
系统中硬件要求如下:手机采用kirin655处理器,内存4g以上,至少2g以上存储空间。系统中的软件要求如下:android7.0,软件开发平台为java。在上述最低配置的情况下,建议文本描述长度不要超过1000字。
药物毒物比对方法主要依赖词条分布特征与开放协作知识库的形式背景信息,知识工程的限制较小,并考虑了多通道文本特征,在开放的应用环境,具有更好的适应性设计,能为人们构建药物毒物知识智能小助手提供核心技术支持。
- 还没有人留言评论。精彩留言会获得点赞!