一种基于k近邻回归算法的云计算竞价实例价格预测方法与流程
本发明涉及云计算实例价格预测领域,特别是涉及一种基于k近邻回归算法的云计算竞价实例价格预测方法。
背景技术:
为了处理日益增长的数据量,很多应用需要部署在更高的硬件配置之上。但是对于多数个人或者中小型企业来说,构建这些硬件环境的开销过于昂贵。相反,云计算pay-as-you-go的价格模式非常适合用户将应用迁移到云上,降低自己购买和维护硬件的开销。云计算主要有三种服务模式,分别是软件及服务(saas)、平台及服务(paas)和基础架构及服务(iaas)。amazonec2是iaas的代表之一,可以提供给用户cpu、网络、内存、存储等基础硬件资源。
amazonec2提供给用户许多购买选项,这些可以分为三大类:预留实例、按需实例和竞价实例。预留实例允许用户通过较低的价钱购买长时间的实例使用权,适合于长期的应用使用。按需实例的价格比预留实例要高,但是在计费方式上是按照秒来计费,适合于短期的应用使用。为了保证能够满足用户需求高峰期,amazon提供了大量的冗余计算能力,但是大多时候很多的资源是闲置浪费的。为了充分利用这些闲置的资源,提高资源使用率并减少成本开销。amazon在2009年12月提出了一种名为竞价实例的新类型实例去售卖这些闲置的资源来提高资源的利用率。
竞价实例允许用户提出一个固定的每小时价格,该价格是用户可以承受的最大价格。竞价实例的价格收到市场供需关系的影响波动。当竞价实例的价格不高于用户的出价的时候用户可以获得实例的使用权,同时用户支付的价钱不是自己的出价,而是竞价实例的实际价格。当竞价实例的价格变化到高于用户的竞价的时候,用户将会被强制中断自己的实例。这种情况下,amazon将会给用户2分钟的警告时间,用户可以在这段时间内保存自己的数据或者是将自己的数据进行迁移。
amazon认为合理的使用竞价实例,可以比按需实例节省高达90%的开销。但是由于竞价实例的波动比较大,会有竞价失败或者实例被中断的情况,所以如果提前预知竞价实例的价格可以帮助用户合理的进行出价设置,实例选择等问题,进而帮助用户在节省成本的同时提高可靠性。
技术实现要素:
本发明的目的是:通过amazon提供的api获取的价格数据,然后建立基于k近邻回归算法的价格预测模型根据历史价格去预测竞价实例的未来价格。
为了达到上述目的,本发明的技术方案是提供了一种基于k近邻回归算法的云计算竞价实例价格预测方法,其特征在于,包括以下步骤:
步骤1、获取云计算竞价实例s的历史价格;
步骤2、对步骤1获得的数据进行预处理,使得数据间隔统一化;
步骤3、利用步骤2获得的数据生成训练集及测试集;
步骤4、以维度方差最大为标准划分训练集,构建k-d树;
步骤5、利用步骤4构建的k-d树对测试集中的任意样例进行k近邻搜索,确定当前样例的k近邻样本;
步骤6、对当前样例的k近邻样本的求平均值,该平均值即为当前样例对应的竞价实例的价格,也为预测的竞价实例价格。
优选地,所述步骤1包括:
步骤101、预先设定云计算竞价实例s的所在地区region、所属类型type及操作系统os;
步骤102、获取云计算竞价实例s的历史价格。
优选地,所述步骤2包括以下步骤:
将步骤1获得的数据按照时间戳进行重采样,将数据间隔统一化。
优选地,所述步骤3包括:
步骤301、采用滑动窗口方法将步骤2获得的数据生成样例,每个样例包含数据x和标签y;
步骤302、将步骤301获得样例中的部分数据作为训练集,其余部分数据作为测试集。
优选地,所述步骤5包括:
步骤501、获取测试集中的新样例x;
步骤502、通过遍历步骤4构建的k-d树确定新样例x的k近邻样本。
由于采用了上述的技术方案,本发明与现有技术相比,具有以下的优点和积极效果:本发明利用k近邻回归算法进行云计算竞价实例价格预测,以帮助用户合理的进行出价设置,实例选择等问题。本发明具有快速高效,贴合需求等优点。该发明对于想要如何选择云计算竞价实例出价的用户具有普遍适用性。可在企业中进行推广和应用,具有较强的社会及商业价值。
附图说明
图1是本发明的整体流程图;
图2是本发明中k近邻回归算法流程图。
具体实施方式
下面结合具体实施例,进一步阐述本发明。应理解,这些实施例仅用于说明本发明而不用于限制本发明的范围。此外应理解,在阅读了本发明讲授的内容之后,本领域技术人员可以对本发明作各种改动或修改,这些等价形式同样落于
本技术:
所附权利要求书所限定的范围。
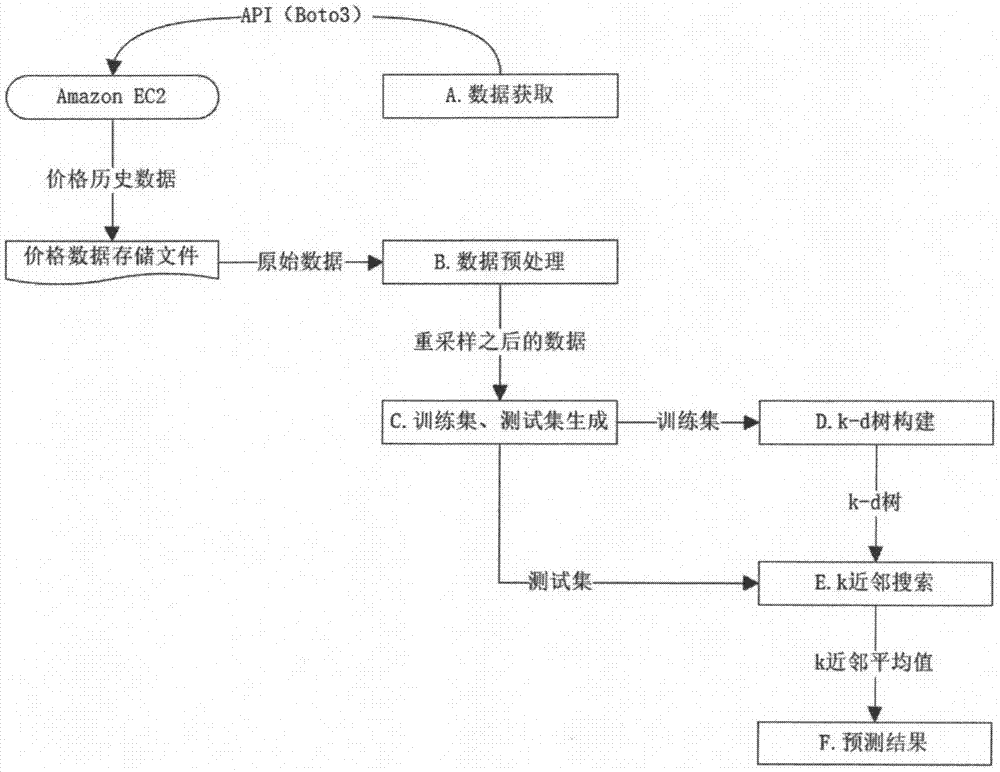
本发明的实施方式涉及一种基于k近邻回归算法的云计算竞价实例价格预测方法,如图1所示,包括以下步骤:a.数据获取;b.数据预处理;c.训练集、测试集生成;d.k-d树构建;e.k近邻搜索;f.预测结果。
其中,步骤a具体包括:
a1.预先设定云计算竞价实例s所在的地区region,竞价实例所属类型type,竞价实例的操作系统os;
a2.通过使用amazon提供的api(如boto3)获取云计算竞价实例s的90天历史价格;出于效率考虑,将竞价实例的价格存储在txt文件中。
步骤b具体包括:将数据按照时间戳进行重采样,将数据间隔设定为1小时。
步骤c具体包括:
c1.确定预测的时长为1天(24小时),采用滑动窗口方法将生成样例,滑动窗口的大小为5天(120小时),滑动窗口每次滑动大小为24,每个样例包含数据x(长度为120)和标签y(长度为24)。
c2.将80%的数据样例作为训练集,其余作为测试集。在测试集中,我们将预测x对应的y值,该y值即预测的竞价实例的价格。
步骤d具体包括:针对训练集,我们以维度方差最大为标准划分数据,知道每个节点为单一的样例而无法划分,构建k-d树。
步骤e具体包括:
e1.获取测试集中的新样例的x;
e2.选择k值为2,通过遍历k-d树确定x的k近邻样本。
步骤f具体包括:对x的k近邻样本的y求平均值,该平均值即为x对应的竞价实例的价格,也为预测的一天竞价实例价格。
不难发现,本发明利用k近邻回归算法进行云计算竞价实例价格预测,以提高预测准确率为目标,能够为用户提供准确的竞价实例预测价格。本发明具有快速高效,贴合需求等优点。该发明对于想要如何选择云计算竞价实例出价的用户具有普遍适用性。可在企业中进行推广和应用,具有较强的社会及商业价值。
技术特征:
技术总结
本发明涉及一种基于k近邻回归算法的云计算竞价实例价格预测方法,包括以下步骤:A.数据获取:获取云计算竞价实例的历史价格;B.数据预处理:对获取的历史价格进行预处理;C.训练集、测试集生成:使用预处理之后的数据生成训练集和测试集;D.k‑d树构建:使用训练集构建k‑d树;E.k近邻搜索:针对于测试集在k‑d树中进行k近邻搜索;F.预测结果:根据搜索到的k近邻求平均值得到预测的价格。本发明能够为用户预测未来一段时间的竞价实例的价格,帮助用户在选择实例、实例出价等方面做出更好的决策。
技术研发人员:王鹏伟;蒋昌俊;章昭辉;刘文强
受保护的技术使用者:东华大学
技术研发日:2018.07.06
技术公布日:2018.12.18
- 还没有人留言评论。精彩留言会获得点赞!