一种基于运动轨迹的3D卷积神经网络的行为识别方法与流程
本发明属于图像识别技术领域,具体涉及一种基于运动轨迹的3d卷积神经网络的行为识别方法。
背景技术:
人体行为识别是一个涉及计算机视觉和模式识别等领域的综合性研究问题,近年来受到学者和研究人员越来越广泛的重视。行为识别在智能监控、虚拟现实、视频检索、人机交互、客户类型、购物行为分析等现实生活中有着广泛的应用,但杂乱的背景、遮挡、光照和视点变化等因素都会影响行为识别的性能,因此开发先进的行为识别算法就有着迫切的需要。
传统的行为识别方法主要由两步组成,第一步是提取视频图像的特征,特征主要由人工特征和深度学习特征组成;第二步利用学习的分类器对特征进行分类。在真实场景中,不同的行为在外观和运动模式上有明显的不同,因此很难选择合适的人工特征,而深度学习模型可以通过样本学习特征从而具有比人工特征更好的优势。基于深度学习行为识别技术主要分为3d卷积神经网络与2d卷积神经网络两个方向。
2d卷积神经网络不能很好的捕获时序上的信息,而3d卷积神经网络通过在卷积层进行3d卷积从而在视频序列中提取在时间和空间维度都具有区分性的时空特征,但目前的3d卷积神经网络忽视了视频时间维和空间维的差异性,没有考虑到行人的运动信息,因而在时间维度上还残留更多的高频信息,在网络中难以形成行人的抽象化表示和特征的不变性。
技术实现要素:
本发明的目的是提供一种基于运动轨迹的3d卷积神经网络的行为识别方法,提高视频中人体行为的识别精度。
本发明所采用的技术方案是,一种基于运动轨迹的3d卷积神经网络的行为识别方法,具体按照以下步骤实施:
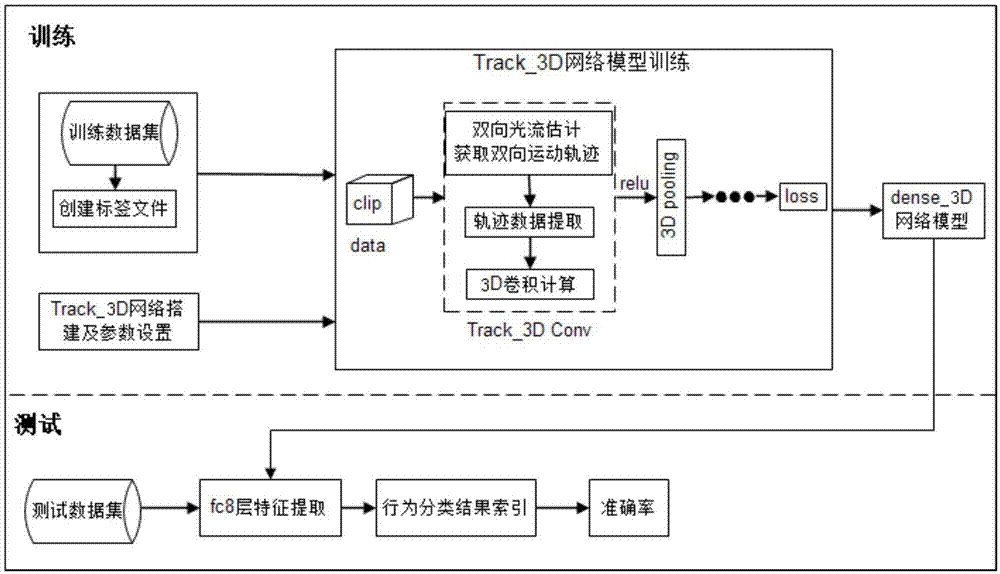
步骤一,行为识别网络模型训练,具体按照以下步骤实施:
步骤1,建立行为识别数据集,数据集包含n种行为类别,将第n种行为的视频个数记为vnumn,0≤n≤n-1,在第n种行为视频中按顺序抽取前kn个视频作为训练视频,kn=round(3/4×vnumn),把所有抽取的训练视频作为训练数据集vtrain,其中
步骤2,创建训练标签labeltrain与测试标签labeltest,在训练数据集vtrain中,第n种行为类别下的第k个视频
训练标签labeltrain的格式为:
在测试数据集vtest中,第n种行为类别下的第s个视频
测试标签labeltest格式为:
步骤3,双向光流计算,获取前向、后向运动轨迹列表,对输入的视频段数据
步骤4,根据步骤3得到的运动轨迹列表,把视频段数据
步骤5,建立基于运动轨迹的3d卷积神经网络结构track_3d;
步骤6,对步骤5建立的基于运动轨迹的3d卷积神经网络结构进行训练,具体为:打开训练标签labeltrain文件,按行读取视频路径、视频名称和视频段起始帧号,在视频名称对应的视频中以起始帧号为首帧连续读取16帧视频段
步骤二,行为识别网络模型测试,具体为:读取测试标签labeltest中的视频路径、视频名称以及起始帧号,将测试数据集中的视频按照以起始帧号为第一帧的连续16帧视频段输入到经过训练的基于运动轨迹的3d卷积神经网络模型中,输出各个视频段的行为分类信息,最后将输出的行为分类信息与该测试视频对应的测试标签labeltest信息作比较,统计分类正确个数,计算得到准确率;
步骤三,若步骤二的得到的准确率大于等于95%,则认为步骤一的步骤6训练的基于运动轨迹的3d卷积神经网络结构为最终的需求;若准确率小于95%,则需要调整基于运动轨迹的3d卷积神经网络结构的内置参数,然后重复步骤一中的步骤6和步骤二,直到准确率满足要求。
本发明的特征还在于,
步骤一中的步骤3具体按照以下步骤实施:
步骤3.1,将输入的视频段数据
步骤3.2,采用光流计算方法进行视频灰度图像img_gray[i]的前向和后向运动轨迹提取。
步骤3.2具体按照以下步骤实施:
步骤(1),当前视频帧图像img_gray[i]的像素坐标表示为:
步骤(2),获取当前视频帧图像img_gray[i]的前一帧图像img_pre与后一帧图像img_back,其中img_pre=img_gray[i-1],img_back=img_gray[i+1];若当i=1时,表示当前帧没有前一帧图像,则把img_pre置为空;若当i=16时,表示当前帧没有后一帧图像,则把img_back置为空;
步骤(3),计算相邻两帧图像的光流场,采用光流场计算方法分别计算img_gray[i]与img_pre、img_back之间的前向光流场和后向光流场ω_pre[i],ω_back[i],
步骤(4),根据光流场生成img_gray[i]的前向运动轨迹列表
步骤(5),根据光流场生成img_gray[i]的后向运动轨迹列表
步骤一中的步骤4具体按照以下步骤实施:
步骤4.1,根据imgc[i]中第j个像素点位置
步骤4.2,在前向运动轨迹列表pos_pre中得到前向匹配像素点位置
步骤4.3,在后向运动轨迹列表pos_back中得到后向匹配像素点位置
步骤4.4,将
步骤4.2具体为:
①判断i是否为1;
②若i=1,该像素点所在图像没有前向列表,则该像素点在前一帧图像中对应的像素点位置
③若i≠1,在前向运动轨迹列表pos_pre中得到前向匹配像素点位置
步骤4.3具体按照以下步骤实施:
①判断i是否为16;
②若i=16,该像素点所在图像没有后向列表,则该像素点在后一帧图像中对应的像素点位置
③若i≠16,在后向运动轨迹列表pos_back中得到后向匹配像素点位置
步骤一中的步骤5建立基于运动轨迹的3d卷积神经网络结构track_3d,该网络的输入为训练数据集vtrain,大小为c×16×w×h,其中c=3为通道个数,16为连续视频帧数,w×h为视频图像的分辨率,网络结构的总层数为30层,包括依次连接的:数据层(data)、track_3d卷积层(conv1a)、激活层(relu1a)、3d池化层(pool1)、3d卷积层(conv2a)、激活层(relu2a)、3d池化层(pool2)、3d卷积层(conv3a)、激活层(relu3a)、3d卷积层(conv3b)、激活层(relu3b)、3d池化层(pool3)、3d卷积层(conv4a)、激活层(relu4a)、3d卷积层(conv4b)、激活层(relu4b)、3d池化层(pool4)、3d卷积层(conv5a)、激活层(relu5a)、3d卷积层(conv5b)、激活层(relu5b)、3d池化层(pool5)、全连接层(fc6)、激活层(relu6)、drop层(drop6)、全连接层(fc7)、激活层(relu7)、drop层(drop8)、全连接层(fc8)以及softmax(loss)层。
步骤一中的步骤6训练网络模型的方法具体按照以下步骤实施:
步骤6.1,利用caffe架构下的函数compute_volume_mean_from_list_videos.cpp将视频段训练数据集vtrain生成train_ucf101_mean.binaryproto均值文件;
步骤6.2,将步骤一中的步骤5建立的基于运动轨迹的3d卷积神经网络结构、步骤6.1的均值文件和步骤一中的步骤2的训练标签labeltrain文件的所在路径写入网络结构文件track3d_ucf101_train.prototxt中;
步骤6.3,设置训练参数并写入配置文件track3d_solver.prototxt;
步骤6.4,在caffe架构下调用命令语句完成训练./build/tools/train_net.bintrack3d_solver.prototxt,生成经过训练的基于运动轨迹的3d卷积神经网络结构track3dmodel。
步骤二具体按照以下步骤实施:
步骤2.1,创建一个输出标签文件outputlabel,该标签的作用主要用于设置提取的特征名称,要求对同一个视频中的同一个视频段在输出标签文件和测试标签文件中的描述在同一行。
outputlabel的具体格式如下:
步骤2.2,按行读取测试标签labeltest文件中视频路径、视频名称和视频段起始帧号,在视频名称对应的视频中以起始帧号为首帧连续读取16帧视频段作为一个输入,送入经步骤一中的步骤6训练好的网络模型track3dmodel中,提取fc8层的输出数据,该数据为视频段按照概率大小排序的最终分类结果索引表{index[s]|1≤s≤n},其中index[s]表示排名第s的类别编号,把索引表保存为一个特征文件,特征文件存放路径及名称就是outputlabel文件中该视频段描述所在行的文件路径及特征名称;
步骤2.3,读取所有特征文件,获取所有视频段对应的index[1],将index[1]和测试标签文件labeltest中对应的视频类别号进行大小对比,若相等则为分类正确,若不相等则为分类不正确,正确的分类个数除以特征文件个数得到准确率。
本发明的有益效果是:本发明一种基于运动轨迹的3d卷积神经网络的行为识别方法,优化了原始3d卷积神经网络不能获取图像运动轨迹信息的缺点,并在提取图像稠密运动轨迹时,采用基于稠密光流提取视频图像的前后向运动轨迹方法,避免了直接提取连续16帧视频图像会产生数据缺失,数据重复等问题,大大提高对于行为的识别精度。
附图说明
图1是本发明的一种基于运动轨迹的3d卷积神经网络的行为识别方法的流程示意图;
图2是一种基于稠密光流提取视频图像的前后向运动轨迹流程示意图;
图3是根据运动轨迹列表数据提取流程示意图;
图4是根据运动轨迹列表提取数据后数据放置具体操作图;
图5是基于运动轨迹的3d卷积神经网络结构示意图;
图6是3d卷积的具体操作过程示意图;
图7激活函数relu的函数图。
具体实施方式
下面结合附图和具体实施方式对本发明进行详细说明。
本发明的一种基于运动估计的3d卷积神经网络的行为识别方法的流程示意图如1所示,由行为识别网络模型训练过程和行为识别测试过程组成。
网络模型训练主要包括以下步骤:
步骤1:通过网络下载,获取行为识别数据集(例如ucf101、hmdb51数据集等),该数据集包含n种行为类别,第n种行为的视频个数记为vnumn,0≤n≤n-1,在第n种行为视频中按顺序抽取前kn个视频作为训练视频,kn=round(3/4×vnumn),把所有抽取的训练视频作为训练数据集vtrain,其中
步骤2:创建训练标签labeltrain与测试标签labeltest,在训练数据集vtrain中,第n种行为类别下的第k个视频
训练标签labeltrain的格式为:
在测试数据集vtest中,第n种行为类别下的第s个视频
测试标签labeltest格式为:
在本实施方案中训练视频段个数
步骤3:双向光流计算,获取前向、后向运动轨迹列表,对输入的视频段数据
步骤3.1:将输入的视频段数据
步骤3.2:采用
(1)当前视频帧图像img_gray[i]的像素坐标表示为:
(2)获取当前视频帧图像img_gray[i]的前一帧图像img_pre与后一帧图像img_back,其中img_pre=img_gray[i-1],img_back=img_gray[i+1];若当i=1时,表示当前帧没有前一帧图像,则把img_pre置为空;若当i=16时,表示当前帧没有后一帧图像,则把img_back置为空;
(3)计算相邻两帧图像的光流场,采用
(4)根据光流场生成img_gray[i]的前向运动轨迹列表
(5)根据光流场生成img_gray[i]的后向运动轨迹列表
在本实施方案中,w=112,h=112,因为第一帧图像没有前一帧图像,第16帧图像没有后一帧图像,故第一帧图像没有前向运动轨迹列表,第16帧图像没有后向运动轨迹列表,故前向轨迹列表大小为15×112×112,后向轨迹列表大小为15×112×112。
步骤4:根据步骤3得到的运动轨迹列表,把视频段数据
步骤4.1:根据imgc[i]中第j个像素点位置
步骤4.2:在前向运动轨迹列表pos_pre中得到前向匹配像素点位置
①判断i是否为1;
②若i=1,该像素点所在图像没有前向列表,则该像素点在前一帧图像中对应的像素点位置
③若i≠1,在前向运动轨迹列表pos_pre中得到前向匹配像素点位置
步骤4.3:在后向运动轨迹列表pos_back中得到后向匹配像素点位置
①判断i是否为16;
②若i=16,该像素点所在图像没有后向列表,则该像素点在后一帧图像中对应的像素点位置
③若i≠16,在后向运动轨迹列表pos_back中得到后向匹配像素点位置
步骤4.4,将
在本实施方案中,输入数据
步骤5:建立基于运动轨迹的3d卷积神经网络结构track_3d,该网络的输入为训练数据集vtrain,大小为c×16×w×h,其中c=3为通道个数,16为连续视频帧数,w×h为视频图像的分辨率,网络结构的总层数为30层,包括依次连接的:数据层(data)、track_3d卷积层(conv1a)、激活层(relu1a)、3d池化层(pool1)、3d卷积层(conv2a)、激活层(relu2a)、3d池化层(pool2)、3d卷积层(conv3a)、激活层(relu3a)、3d卷积层(conv3b)、激活层(relu3b)、3d池化层(pool3)、3d卷积层(conv4a)、激活层(relu4a)、3d卷积层(conv4b)、激活层(relu4b)、3d池化层(pool4)、3d卷积层(conv5a)、激活层(relu5a)、3d卷积层(conv5b)、激活层(relu5b)、3d池化层(pool5)、全连接层(fc6)、激活层(relu6)、drop层(drop6)、全连接层(fc7)、激活层(relu7)、drop层(drop8)、全连接层(fc8)以及softmax(loss)层。具体的网络结构图如图5。
在本实施方案中,各个网络层的输入数据大小、滤波器个数、核大小和输出数据大小如表1所示:
表1
3d卷积计算过程如图6所示,在进行3d卷积时,按3d卷积核大小的滑动窗在连续视频帧组成的数据立方体内进行滑动,每一个滑动窗内的数据立方体为一个卷积区域,3d卷积层的输出为各个卷积区域和3d卷积核的点乘求和。
池化层主要通过下采样减少数据的空间分辨率,常用的操作为池平均(average-pooling)操作或池最大(max-pooling)操作。在具体的实施例中,核大小为2×2×2,操作为池最大操作,输入数据每经过一级池化处理大小就会由原来的mm×nn×ll变为
激活层是对输入的数据进行激活操作,即若每个数据元素符合条件,则数据被激活,使其向下一层传递,否则的话则不被传递。在本文激活层采用的激活函数为修正线性单元(rectifiedlinearunit,relu),
drop层是随机对一些神经元进行抑制,使其处于未激活状态。
全连接层在整个网络中起到“分类器”的作用,主要目的是整合经过卷积层或池化层处理后具有类别区分性的局部信息,用于分类或回归。
softmax层主要是对全连接之后的数据进行归一化操作使其范围必须在[0,1]之间。
步骤6:对步骤5建立的基于运动轨迹的3d卷积神经网络结构进行训练,具体为:打开训练标签labeltrain文件,按行读取视频路径、视频名称和视频段起始帧号,在视频名称对应的视频中以起始帧号为首帧连续读取16帧视频段
步骤6.1:利用caffe架构下的函数compute_volume_mean_from_list_videos.cpp将视频段训练数据集vtrain生成均值文件train_ucf101_mean.binaryproto;
步骤6.2:把步骤5中建立的网络结构、均值文件路径和标签文件路径写入网络结构文件track3d_ucf101_train.prototxt中;
步骤6.3:设置训练参数并把设置好的训练参数写入网络配置文件track3d_solver.prototxt中,参数的具体设置如表2所示:
步骤6.4:在caffe架构下调用命令语句./build/tools/train_net.bintrack3d_solver.prototxt进行训练,训练过程结束生成最终训练模型track3dmodel;
网络模型track3dmodel生成后,对网络模型进行测试,其主要包括以下步骤:
步骤(1),创建一个输出标签文件outputlabel,该标签主要用于设置提取的特征名称,要求对同一个视频中的同一个视频段在输出标签文件和测试标签文件中的描述在同一行。
outputlabel的具体格式如下:
步骤(2),按行读取测试标签labeltest文件中视频路径、视频名称和视频段起始帧号,在视频名称对应的视频中以起始帧号为首帧连续读取16帧视频段作为一个输入,送入步骤6训练好的网络模型track3dmodel中,提取fc8层的输出数据,该数据为视频段按照概率大小排序的最终分类结果索引表{index[s]|1≤s≤n},其中index[s]表示排名第s的类别编号,把索引表保存为一个特征文件,特征文件存放路径及名称就是outputlabel文件中该视频段描述所在行的文件路径及特征名称;
步骤(3),读取所有特征文件,获取所有视频段对应的index[1],将index[1]和测试标签文件labeltest中对应的视频类别号进行大小对比,若相等则为分类正确,若不相等则为分类不正确,正确的分类个数除以特征文件个数得到准确率。
分析测试结果,若准确率低于95%,则调整配置文件track3d_solver.prototxt内的参数,主要调整初始学习率base_lr,最大迭代次数max_iter,重新训练网络模型,用重新训练的网络模型进行测试,直到满足准确率要求。
- 还没有人留言评论。精彩留言会获得点赞!