一种基于孤立森林算法的用电数据异常检测模型的制作方法
本发明涉及一种基于孤立森林算法的用电数据异常检测模型,涉及电力数据分析、电力数据异常预测、电力数据挖掘和数技术和智能电网技术领域。
背景技术
近年来,围绕用电侧的异常模式检测问题,发展了基于统计、基于距离和基于学习的三大类技术方法。从数据的角度看,并借鉴机器学习领域的常用概念,可以将这些方法分成两大类:有监督和无监督的。有监督的方法通常需要足够的带标签的训练样本,这意味着用电数据中需要包含用户的类型信息,即该用户是否为异常用户。这样的数据需要人类专家鉴定,并且无法形成较大的规模。因此有监督的方法虽然大多数情况下能够达到理论上的最佳性能,却很难广泛应用于没有标签数据的异常用电模式识别。无监督的方法则不需要知道用户本身的类型信息,它能够从大量的用电数据中学习到特定的知识,并用于寻找异常的用电模式。随着智能电表的普及和配用电大数据的发展,电网的用电侧数据逐步表现出海量数据和高复杂度的特征。传统的用电异常检测模式已经难以满足现有的要求,而近年来被广泛应用于异常检测的神经网络和机器学习的方法,绝大多数对于训练样本的需求较高,无法很好地应用于缺少样本标签的用电数据集上。
技术实现要素:
本发明的目的是克服现有技术的缺陷,提供一种基于孤立森林算法的用电数据异常检测模型,是一种无监督的用电数据异常检测模型,通过分析用户用电数据之间的内在联系,给出代表每一个用户的异常分数以评估该用户的疑似异常概率,这些异常分数将成为电力公司的重要参考,以提高用电异常排查工作的效率,降低运营成本,在进行用电数据的异常检测时,不仅能够快速地处理大量的数据,而且能够适应缺乏训练样本的情况,能够更好地满足于电力部门的实践需求。
实现上述目的的技术方案是:一种基于孤立森林算法的用电数据异常检测模型,包括特征提取模块、特征降维模块、孤立森林计算模块、构建专家样本模块和二次训练模块,其中:
所述特征提取模块从原始数据集中提取用户的用电数据的时间序列作为初始特征集,然后对初始特征集进行无量纲化和特征选择处理;
所述特征降维模块采用主成分分析法和自编码网络法对初始特征集进行降维得到有效特征集;
所述孤立森林计算模块采用孤立森林算法计算出每个用户的异常分数以判定用户数据有无异常;
所述构建专家样本模块通过电力专家的经验筛选标准异常样本;
所述二次训练模块将所述标准异常样本加入到所述原始数据集中,然后进行二次训练,得到最终的用户异常分数排序。
上述的一种基于孤立森林算法的用电数据异常检测模型,其中,所述特征提取模块的特征提取过程包括以下步骤:
s11,预处理:原始数据集中存在着大量的明显的错误的数据,如数据为负值、零值和异常大值,这些为负值、零值和异常大值的数据将在预处理中被清洗,最终我们得到清洗后的数据集;
s12,提取基于均值的指标:由于用户的用电量通常有按工作日周期分布的趋势,我们将统计原始数据集中每个用户工作日和非工作日的平均用电量,即周一到周五的平均用电量、周六的平均用电量和周日的平均用电量,这样可以得到新的7个特征值;
s13,提取基于趋势的指标:通过研究一些通过人工辨别的窃电用户的用电曲线,采用滑动窗口的思想,提取用电曲线的上升和下降趋势指标。
上述的一种基于孤立森林算法的用电数据异常检测模型,其中,所述提取基于趋势的指标中,采用滑动窗口的思想,将一个用户的用电数据看作一个时间序列,并将其分成三个相邻的窗口,依次记为w1,w2和w3;其中w2的长度是固定的,我们将其看作是主要的滑动窗口,然后我们计算w1和w3中数据的平均值和标准差,w1的平均值记为avg1,w3的平均值记为avg3,w1的标准差记为std1,w1的标准差记为std3;然后我们计算下降趋势d的公式如下:
计算上升趋势r的公式如下:
我们计算窗口w2在滑动过程中下降趋势d和上升趋势r的最大值,并将其作为这段时间序列的下降趋势指标和上升趋势指标。
上述的一种基于孤立森林算法的用电数据异常检测模型,其中,所述孤立森林计算模块的计算过程为:
s21,从训练集中进行采样,并根据算法构建孤立树,孤立树的建立过程如下:
s211,从训练数据点随机抽取子样本作为孤立树中的根节点;
s212,随机指定某个维度,在当前节点数据中生成一个切割点p,切割点p是在当前节点的指定维度的最大值和最小值之间随机生成的;
s213当前节点数据空间被切割点p划分为2个子空间:指定维度小于切割点p的数据被放在当前节点的左子树,大于或等于切割点p的数据被放在当前节点的右子树;
s214,在子节点中,重复步骤s212和步骤s213构造新的子节点,直到子节点中只有一个数据或子节点达到定义的高度;
s22,将训练样本带入孤立森林中的每颗孤立树进行测试,记录路径长度,然后计算每个样本的异常分数。
本发明的基于孤立森林算法的用电数据异常检测模型,是一种无监督的用电数据异常检测模型,通过分析用户用电数据之间的内在联系,给出代表每一个用户的异常分数以评估该用户的疑似异常概率,这些异常分数将成为电力公司的重要参考,以提高用电异常排查工作的效率,降低运营成本,在进行用电数据的异常检测时,不仅能够快速地处理大量的数据,而且能够适应缺乏训练样本的情况,能够更好地满足于电力部门的实践需求。
附图说明
图1为本发明的基于孤立森林算法的用电数据异常检测模型的框图;
图2为孤立森林算法分析出的异常点示意图;
图3a为典型的窃电曲线示意图;
图3b为典型的窃电曲线示意图。
具体实施方式
为了使本技术领域的技术人员能更好地理解本发明的技术方案,下面结合附图对其具体实施方式进行详细地说明:
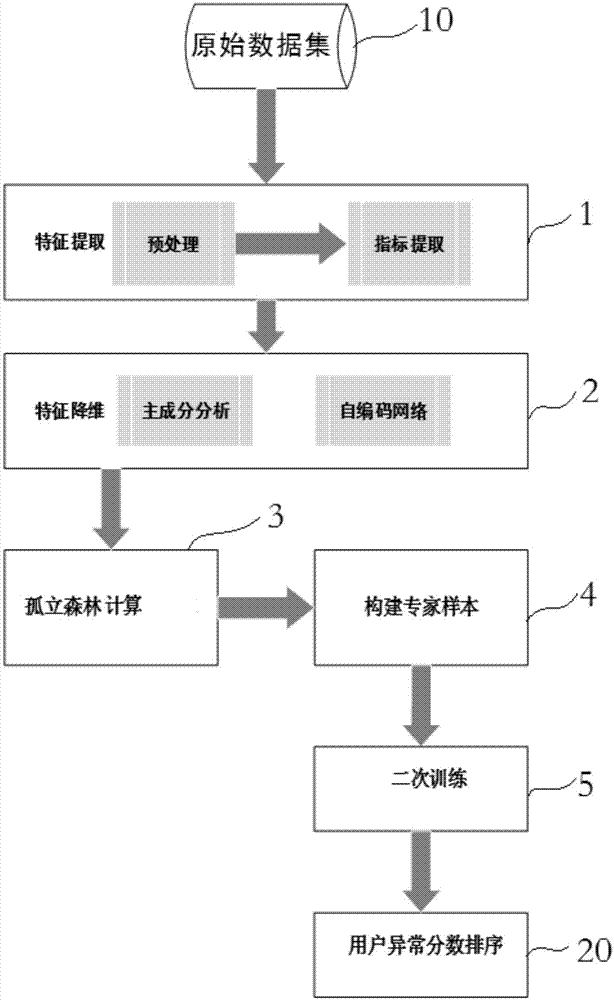
请参阅图1和图2,本发明的最佳实施例,一种基于孤立森林算法的用电数据异常检测模型,包括特征提取模块1、特征降维模块2、孤立森林计算模块3、构建专家样本模块4和二次训练模块5。
特征提取模块1从原始数据集中10提取用户的用电数据的时间序列作为初始特征集,然后对初始特征集进行无量纲化和特征选择处理;特征降维模块2采用主成分分析法和自编码网络法对初始特征集进行降维得到有效特征集;孤立森林计算模块3采用孤立森林算法计算出每个用户的异常分数以判定用户数据有无异常,图2为孤立森林算法分析出的异常点xi、x0的示意图;构建专家样本模块4通过电力专家的经验筛选标准异常样本,二次训练模块5将标准异常样本加入到所述原始数据集中,然后进行二次训练,得到最终的用户异常分数排序20。
对于n个用户m天的日用电量数据,我们将一个用户的所有用电数据提取出来,组成矩阵的一行。那么所有用户的数据可以用一个n×m的矩阵来表示,我们记为x。矩阵x是由用户的日用电量数据组成的原始特征集。基于原始特征集,我们可以进一步提取特征:特征提取模块1的特征提取过程包括以下步骤:
s11,预处理:原始数据集10中存在着大量的明显的错误的数据,如数据为负值、零值和异常大值,这些为负值、零值和异常大值的数据将在预处理中被清洗,最终我们得到清洗后的数据集x0;
s12,提取基于均值的指标:由于用户的用电量通常有按工作日周期分布的趋势,我们将统计原始数据集中每个用户工作日和非工作日的平均用电量,即周一到周五的平均用电量、周六的平均用电量和周日的平均用电量,这样可以得到新的7个特征值;
s13,提取基于趋势的指标:通过研究一些通过人工辨别的窃电用户的用电曲线,采用滑动窗口的思想,提取用电曲线的上升和下降趋势指标。从图3a和图3b中两个典型的窃电曲线中我们可以发现,用电量的突然上升和突然下降都是十分重要的信息,于是采用滑动窗口的思想,将一个用户的用电数据看作一个时间序列,并将其分成三个相邻的窗口,依次记为w1,w2和w3;其中w2的长度是固定的,我们将其看作是主要的滑动窗口,然后我们计算w1和w3中数据的平均值和标准差,w1的平均值记为avg1,w3的平均值记为avg3,w1的标准差记为std1,w1的标准差记为std3;然后我们计算下降趋势d的公式如下:
计算上升趋势r的公式如下:
我们计算窗口w2在滑动过程中下降趋势d和上升趋势r的最大值,并将其作为这段时间序列的下降趋势指标和上升趋势指标。
原始特征集x具有很高的维度和数据冗余,经过特征提取之后,得到了重叠度较低的特征集。为了进一步较低特征的维度,使用尽可能少的参数描述原始特征集尽可能多的信息,通常采用特征降维的相关算法:
(1)主成分分析(principalcomponentanalysis,pca)是一种具有代表性的数据降维算法。主成分分析本质上属于非监督算法,可以用来处理不带标签的数据。它可以降低数据的维度,并使得降低了维度的数据之间的方差最大,从而保留更多的信息,也是主成分分析法的基本思想;
(2)自编码网络,就是利用神经网络试图计算出原始数据的一种更简洁的表达方式,达到数据降维的目的:首先初始化编码和解码两个神经网络,然后按照原始训练数据与输出数据之间误差最小化的原则对自编码网络进行训练;
上述两种方法相比较,自编码网络其实是增强的主成分分析:自编码网络具有非线性变换单元,因此学出来的编码可能更精炼,对输入的表达能力更强。但是自编码网络是训练出来的,故它的表达能力受限于训练样本的普适程度,因此具有一定的局限性。
孤立森林计算模块3的计算过程为:
s21,从训练集中进行采样,并根据算法构建孤立树(itree),孤立树的建立过程如下:
s211,从训练数据点随机抽取子样本作为孤立树中的根节点;
s212,随机指定某个维度,在当前节点数据中生成一个切割点p,切割点p是在当前节点的指定维度的最大值和最小值之间随机生成的;
s213当前节点数据空间被切割点p划分为2个子空间:指定维度小于切割点p的数据被放在当前节点的左子树,大于或等于切割点p的数据被放在当前节点的右子树;
s214,在子节点中,重复步骤s212和步骤s213构造新的子节点,直到子节点中只有一个数据或子节点达到定义的高度;
s22,将训练样本带入孤立森林中的每颗孤立树进行测试,记录路径长度,然后计算每个样本的异常分数。
最后通过电力专家的经验筛选标准异常样本,再将这些标准异常样本加入到原始数据集中,然后进行二次训练,得到最终的异常识别模型。
本发明的基于孤立森林算法的用电数据异常检测模型,采用数据预处理方法并结合孤立森林算法计算出每个用户的异常分数以判定用户数据有无异常。采用特征提取对原始数据中的负值、零值、异常大值等进行清洗,再进行特征降维,进一步从原始数据中获取有效的特征。从样本数据集中采样并进行训练,计算出每个样本的异常分数进行比对。从而在大量数据中,找出与其他数据的规律不太相符的数据点。
综上所述,本发明的基于孤立森林算法的用电数据异常检测模型,是一种无监督的用电数据异常检测模型,通过在大量实际数据的应用实践,证明了该模型的高效性和精准性,具有良好的实际应用潜力,在进行用电数据的异常检测时,不仅能够快速地处理大量的数据,而且能够适应缺乏训练样本的情况,能够更好地满足于电力部门的实践需求。
本技术领域中的普通技术人员应当认识到,以上的实施例仅是用来说明本发明,而并非用作为对本发明的限定,只要在本发明的实质精神范围内,对以上所述实施例的变化、变型都将落在本发明的权利要求书范围内。
- 还没有人留言评论。精彩留言会获得点赞!