一种基于大数据智能推荐方法和装置与流程
本发明属于大数据领域,尤其涉及一种基于粉丝公会的大数据智能推荐方法和装置。
背景技术:
现有的明星的商业价值评估主要是通过传统的抽样调查进行,传统的抽样调查体系有着数据来源单一、数据样本小、时效性差、精确度不高等明显缺陷。
技术实现要素:
本发明提供了一种基于粉丝公会的大数据智能推荐方法,用于克服传统明星的商业价值评估的一个或多个缺陷。
一种基于粉丝公会的大数据智能推荐方法,包括如下步骤:获取用户数据,该用户数据包括静态数据和动态数据,其中静态数据是用户预先填写的数据,至少包括如下的一种:年龄、性别、职业、收入、地区、学历、第一兴趣爱好、婚姻状况。动态数据至少包括如下的一种:浏览、搜索、点击、收藏、购买、参与的话题;对获取的用户的静态数据进行统计分析得到第一标签;对获取的用户的动态数据进行建模分析,得到第二标签;将获取的第一标签和第二标签进行处理获得明星标签;明星活动推荐,根据获得明星标签对明星活动进行推荐。
其中,所述对获取的用户的动态数据进行建模分析,包括,对用户的购买的产品、用户关联关系、用户参与的话题其中的一个或多个进行分析得到第二标签。进一步地根据明星标签对明星活动进行推荐,进一步包括统计分析特定品牌下用户的标签将其作为品牌的标签或特定广告下的用户标签将其作为广告标签,并根据事先建立的品牌、广告与标签的关系,对明星进行品牌、广告的推荐。
进一步地还包括一种基于粉丝公会的大数据智能推荐装置,其包括:数据获取模块,用于获取用户数据,该用户数据包括静态数据和动态数据,其中静态数据是用户预先填写的数据,至少包括如下的一种:年龄、性别、职业、收入、地区、学历、第一兴趣爱好、婚姻状况。动态数据至少包括如下的一种:浏览、搜索、点击、收藏、购买、参与的话题;第一标签产生模块,用于对获取的用户的静态数据进行统计分析得到第一标签;第二标签产生模块,用于对获取的用户的动态数据进行建模分析,得到第二标签;明星标签产生模块,用于将获取的第一标签和第二标签进行处理以产生明星标签;明星活动推荐模块,用于根据获得明星标签对明星活动进行推荐。
通过获取明星的粉丝数据,并对分析数据进行分析得到用户的特征,对用户分析获取明星的粉丝的标签并将该标签作为明星标签,进而根据明星标签对明星参与的活动进行推荐,本发明的数据可以来源于网站例如微博、特定app、论坛等,数据来源多样并且数据量较大,可以准确地评估明星的商业价值。
附图说明
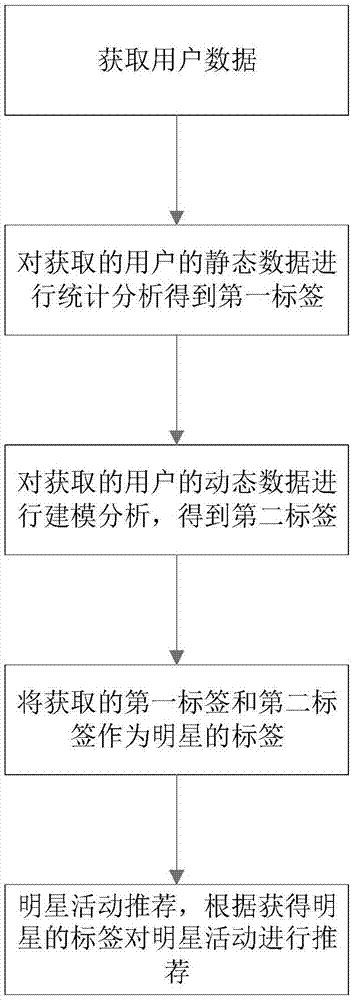
图1本发明基于粉丝公会的智能推荐方法流程图。
图2本发明基于粉丝公会的智能推荐装置的示意图。
图3智能推荐装置中的标签产生模块。
具体实施方式
为了能够更清楚地理解本发明的上述目的、特征和优点,下面结合附图和具体实施方式对本发明进行进一步的详细描述。需要说明的是,在不冲突的情况下,本申请的实施例及实施例中的特征可以相互组合。
在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是,本发明还可以采用其他不同于在此描述的其他方式来实施,因此,本发明的保护范围并不受下面公开的具体实施例的限制。
实施例一
如图1所示一种基于粉丝公会的大数据智能推荐方法,包括如下步骤:
s1、获取用户数据,该用户数据包括静态数据和动态数据,其中静态数据是用户预先填写的数据,至少包括如下的一种:年龄、性别、职业、收入、地区、学历、第一兴趣爱好、婚姻状况。动态数据至少包括如下的一种:浏览、搜索、点击、收藏、购买、参与的话题。
由于获取的数据可能不完整,需要对数据进行清洗,可以使用自动清洗方式,在自动清洗滞后也可以进行人工清洗,以保证数据的完整性。
进一步为了保证获取用户数据的多样性,提高推荐的准确度,还可以所有搜索过所述明星的用户的数据、参与明星话题讨论的用户的数据作为潜在的粉丝,进一步地还可以根据获取到的粉丝关注的其他人的信息。
s2、对获取的用户的静态数据进行统计分析得到第一标签;这一步主要是获取年龄分布、性别比例等用户填写的静态数据获取第一标签。在有些情况下,针对特定的分析对象可以事先设置该第一标签。
s3、对获取的用户的动态数据进行建模分析,得到第二标签;
用户的动态数据主要有用户为了购买行为而产生的数据,例如购买的产品、浏览产品的时间等;此外,还有用户参与的话题活动,例如用户参与的旅游、美食等话题。
相应地对对用户的动态数据进行建模可以针对用户的购买行为和用户参与的话题活动,而进行建模,进而产生第二标签。应该知道,这两种建模方式可以单独进行也可以组合进行。
其中对对用户购买行为的建模包括:获取用户购买产品的次数、价格、收藏的产品以及时间、浏览产品的时间、搜索产品的时间、购买产品的时间。根据以上计算出用户的第二标签,例如根据用户的购买的产品划分用户的兴趣,如用户主要购买电子产品,则认为是电子达人;而如果用户主要购买的产品为图书,则认为是阅读达人等。
其中用户收藏的时间、浏览产品的时间、搜索产品的时间、购买产品的事件,越近赋予的权重越大。
对用户参与的话题活动的建模主要为:首先设置了一个话题分类集{t1,…tn},其中ti为(0≤i≤n)为第i个话题分类,用户对话题分类ti的感兴趣程度用wi来表示。因此用户话题兴趣模型m可以通过如下公式:m=<uid|(t1,w1),...,(ti,wi)>来表示,其中uid代表用户的全局唯一标识符。这些话题可以通过网络爬虫的方式从相应的网站上获取并以文本的形式存储在数据库中。
用户在参与话题活动时,均会产生一些行为数据,这些行为数据可以用来刻画用户对该话题的感兴趣程度。常用的用户行为数据包括:点赞次数、浏览次数、浏览时间、转发次数、搜索等,具体表示方法如下:
(1)li,点赞次数。用户对某个话题点赞最能说明用户对这一话题的喜爱,点赞次数越多,表明用户这这一话题越感兴趣,反之则表示兴趣度越低。
(2)bw,表示浏览话题的次数。
(3)ti,浏览时间。在本实施例中,当用户发起第一次请求时的时间戳t,到用户再次发起请求的时间戳t之间的时间差,记为用户的浏览时间,浏览时间越短,表明用户可能越不喜欢该类话题,可能没有全部浏览。
(4)shr,表示用户分享的次数。类似于该类有明显代表用户喜爱的标签类型,因该给予较大的权重。
(5)sh,表示用户搜索活动主题的次数。
将以上数据进行归一化相加作为用户对话题的感兴趣程度,并筛选出前x(x为大于或等于1的正整数),个权重较大的话题作为用户感兴趣的话题。
s4、将获取的第一标签和第二标签进行处理获得明星标签。
所述的处理包括:取第一标签、第二标签的并集,并去除相同的标签。
s5、明星活动推荐,根据明星标签对明星活动进行推荐。
进一步的,所述明星活动包括:产品品牌合作计划、代言广告计划、公益活动、电视剧本等。
对产品品牌合作计划:可以通过网络爬虫的方式获取特定品牌或广告下用户的数据,并统计分析特定品牌下用户的标签将其作为品牌的标签或特定广告下的用户标签将其作为广告标签。在获取到品牌标签或广告标签后,根据事先建立的品牌、广告与标签的关系,对明星进行品牌、广告的推荐。
通过获取明星的粉丝数据,并对分析数据进行分析得到用户的特征,对用户分析获取明星的粉丝的标签并将该标签作为明星标签,进而根据明星标签对明星参与的活动进行推荐,本发明的数据可以来源于网站例如微博、特定app、论坛等,数据来源多样并且数据量较大,可以准确地评估明星的商业价值。
实施例二
如图2、图3所示的一种基于粉丝公会的明星推荐装置,其包括:
数据获取模块,用于获取用户数据,该用户数据包括静态数据和动态数据,其中静态数据是用户预先填写的数据,至少包括如下的一种:年龄、性别、职业、收入、地区、学历、第一兴趣爱好、婚姻状况。动态数据至少包括如下的一种:浏览、搜索、点击、收藏、购买、参与的话题;
标签产生模块,用于根据用户数据产生第一标签和第二标签,并对第一标签和第二标签进行处理以产生明星标签。
明星活动推荐模块,用于根据获得明星标签对明星活动进行推荐。
所述明星活动包括:产品品牌合作计划、代言广告计划、公益活动、电视剧本等。
对产品品牌合作计划:可以通过网络爬虫的方式获取特定品牌或广告下用户的数据,并统计分析特定品牌下用户的标签将其作为品牌的标签或特定广告下的用户标签将其作为广告标签。在获取到品牌标签或广告标签后,根据事先建立的品牌、广告与标签的关系,对明星进行品牌、广告的推荐。
如图3所示标签产生模块,进一步包括:
第一标签产生模块,用于根据用户的静态数据进行统计分析得到第一标签;
第二标签产生模块,用于根据用户的动态数据进行建模分析,得到第二标签;
其中用户的动态数据主要有用户为了购买行为而产生的数据,例如购买的产品、浏览产品的时间等;此外,还有用户参与的话题活动,例如用户参与的旅游、美食等话题。
其中第二标签产生模块,还包括:对用户的动态数据进行建模可以针对用户的购买行为和用户参与的话题活动,而进行建模,进而产生第二标签。应该知道,这两种建模方式可以单独进行也可以组合进行。
其中对对用户购买行为的建模包括:获取用户购买产品的次数、价格、收藏的产品以及时间、浏览产品的时间、搜索产品的时间、购买产品的时间。根据以上计算出用户的第二标签,例如根据用户的购买的产品划分用户的兴趣,如用户主要购买电子产品,则认为是电子达人;而如果用户主要购买的产品为图书,则认为是阅读达人等。
其中用户收藏的时间、浏览产品的时间、搜索产品的时间、购买产品的事件,越近赋予的权重越大。
对用户参与的话题活动的建模主要为:首先设置了一个话题分类集{t1,…tn},其中ti为(0≤i≤n)为第i个话题分类,用户对话题分类ti的感兴趣程度用wi来表示。因此用户话题兴趣模型m可以通过如下公式:m=<uid|(t1,w1),...,(ti,wi)>来表示,其中uid代表用户的全局唯一标识符。这些话题可以通过网络爬虫的方式从相应的网站上获取并以文本的形式存储在数据库中。
用户在参与话题活动时,均会产生一些行为数据,这些行为数据可以用来刻画用户对该话题的感兴趣程度。常用的用户行为数据包括:点赞次数、浏览次数、浏览时间、转发次数、搜索等,具体表示方法如下:
(1)li,点赞次数。用户对某个话题点赞最能说明用户对这一话题的喜爱,点赞次数越多,表明用户这这一话题越感兴趣,反之则表示兴趣度越低。
(2)bw,表示浏览话题的次数。
(3)ti,浏览时间。在本实施例中,当用户发起第一次请求时的时间戳t,到用户再次发起请求的时间戳t之间的时间差,记为用户的浏览时间,浏览时间越短,表明用户可能越不喜欢该类话题,可能没有全部浏览。
(4)shr,表示用户分享的次数。类似于该类有明显代表用户喜爱的标签类型,因该给予较大的权重。
(5)sh,表示用户搜索活动主题的次数。
将以上数据进行归一化相加作为用户对话题的感兴趣程度,并筛选出前x(x为大于或等于1的正整数),个权重较大的话题作为用户感兴趣的话题。
明星标签产生模块,用于将获取的第一标签和第二标签进行处理以产生明星标签。
所述的处理包括:取第一标签、第二标签的并集,并去除相同的标签。
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!