caffemodel模型压缩方法、系统、设备及介质与流程
本发明涉及算法领域,具体涉及一种caffemodel模型压缩方法、系统、设备及介质。
背景技术
pvanet-faster-rcnn(一种物体检测模型)是一种基于卷积神经网络的对图像中物体进行检测的算法模型。在caffe(一种深度学习框架)框架下训练标准的pvanet-faster-rcnn模型得到的caffemodel(深度学习框架模型)模型的尺寸是369mb(兆,计算机中的一种存储单位),该模型由若干层构成,其中fc6(全连接层第6层)层和fc7层(全连接层第7层)的权重参数合计约占352mb。
当用gpu(图形处理器)卡计算该模型时,369mb大小的caffemodel模型将驻留在gpu显存中,caffemodel模型中的参数量较大,占用gpu显存资源较多,无法在显存资源紧张的gpu显卡上运行,导致gpu运算性能下降。
技术实现要素:
本发明要解决的技术问题是为了克服现有技术中caffemodel模型在运算时占用gpu显存,导致gpu运算性能下降的缺陷,提供一种caffemodel模型压缩方法、系统、设备及介质。
本发明是通过下述技术方案来解决上述技术问题:
一种caffemodel模型压缩方法,所述caffemodel模型压缩方法包括:
利用caffe框架导入一训练后的caffemodel模型,所述caffemodel模型包括fc6层和/或fc7层,所述fc6层和/或fc7层的权重矩阵为第一权重矩阵;
获取所述第一权重矩阵;
将所述第一权重矩阵中的绝对值大于和等于预设阈值的元素设置为1,并将所述第一权重矩阵中的绝对值小于所述预设阈值的元素设置为0后,生成掩码矩阵,所述预设阈值为一正值;
利用训练集训练所述caffemodel模型,迭代后,所述fc6层和/或fc7层的权重矩阵为第二权重矩阵;
将所述第二权重矩阵中的每项元素与所述掩码矩阵中对应的每项元素相乘生成第三权重矩阵,将所述fc6层和/或fc7层的权重矩阵设置为所述第三权重矩阵;
返回所述利用训练集训练所述caffemodel模型,迭代后,所述fc6层和/或fc7层的权重矩阵为第二权重矩阵的步骤;
直至达到预设迭代结束条件,则迭代结束,将所述第三权重矩阵转化为对应的csr(一种稀疏矩阵压缩存储格式)稀疏矩阵格式生成压缩权重矩阵,将所述caffemodel模型的权重矩阵设置为所述压缩权重矩阵。
较佳地,所述将所述caffemodel模型的权重矩阵设置为所述压缩权重矩阵的步骤还包括:
迭代结束后,获得所述caffemodel模型的训练精度为迭代训练精度;
迭代前的所述caffemodel模型的训练精度为原始训练精度,计算所述迭代训练精度相比所述原始训练精度的下降比例,若所述下降比例高于预设精度比例,则降低所述预设阈值,返回生成所述掩码矩阵的步骤;
所述将所述第三权重矩阵转化为对应的稀疏矩阵格式生成所述压缩权重矩阵的步骤包括:
直至所述下降比例低于所述预设精度比例,将所述第三权重矩阵转化为对应的稀疏矩阵格式生成所述压缩权重矩阵。
较佳地,所述预设精度比例的范围为0.1%-0.5%。
较佳地,所述将所述caffemodel模型的权重矩阵设置为所述压缩权重矩阵的步骤之后还括:
利用所述fc6层和/或fc7层接收输入数据,并将所述输入数据与所述压缩权重矩阵作相乘运算得到输出数据。
一种caffemodel模型压缩系统,所述caffemodel模型压缩系统包括导入模块、掩码生成模块、迭代模块、掩码模块、返回模块和转化模块;
所述导入模块用于利用caffe框架导入一训练后的caffemodel模型,所述caffemodel模型包括fc6层和/或fc7层,所述fc6层和/或fc7层的权重矩阵为第一权重矩阵;
所述掩码生成模块用于获取所述第一权重矩阵,并将所述第一权重矩阵中的绝对值大于和等于预设阈值的元素设置为1,并将所述第一权重矩阵中的绝对值小于所述预设阈值的元素设置为0后,生成掩码矩阵,所述预设阈值为一正值;
所述迭代模块用于利用训练集训练所述caffemodel模型,迭代后,所述fc6层和/或fc7层的权重矩阵为第二权重矩阵;
所述掩码模块用于将所述第二权重矩阵中的每项元素与所述掩码矩阵中对应的每项元素相乘生成第三权重矩阵,将所述fc6层和/或fc7层的权重矩阵设置为所述第三权重矩阵;
所述返回模块用于返回所述利用训练集训练所述caffemodel模型,迭代后,所述fc6层和/或fc7层的权重矩阵为第二权重矩阵的步骤;
所述转化模块用于直至达到预设迭代结束条件,则迭代结束,将所述第三权重矩阵转化为对应的csr稀疏矩阵格式生成压缩权重矩阵,将所述caffemodel模型的权重矩阵设置为所述压缩权重矩阵。
较佳地,所述caffemodel模型压缩系统还包括精度比较模块,所述精度比较模块用于迭代结束后,以及获得所述caffemodel模型的训练精度为迭代训练精度,迭代前的所述caffemodel模型的训练精度为原始训练精度;
所述精度模块还用于计算所述迭代训练精度相比所述原始训练精度的下降比例,若所述下降比例高于预设精度比例,则降低所述预设阈值,调用所述掩码矩阵生成模块;
所述转化模块还用于直至所述下降比例低于所述预设精度比例,将所述第三权重矩阵转化为对应的稀疏矩阵格式生成所述压缩权重矩阵。
较佳地,所述预设精度比例的范围为0.1%-0.5%。
较佳地,所述caffemodel模型压缩系统还括运算模块,所述运算模块用于利用所述fc6层和/或fc7层接收输入数据,并将所述输入数据与所述压缩权重矩阵作相乘运算得到输出数据。
一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现如上所述的caffemodel模型压缩方法。
一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现如上所述的caffemodel模型压缩方法的步骤。
本发明的积极进步效果在于:
本发明通过将caffemodel模型的fc6层和/或fc7层的权重矩阵的各元素与预设阈值比较后生成只包括0和1元素的掩码矩阵,继续训练caffemodel模型,将每次迭代后生成的第二权重矩阵的各元素与掩码矩阵的对应位置的每项元素相乘,最终迭代结束后,得到的caffemodel模型的权重矩阵包括一些无效元素0,并将此权重矩阵转化为csr稀疏矩阵格式,从而达到降低caffemodel模型的存储空间的效果。
附图说明
图1为本发明的实施例1的caffemodel模型压缩方法的流程图。
图2为本发明的实施例2的caffemodel模型压缩方法的流程图。
图3为本发明的实施例3的caffemodel模型压缩系统的模块示意图。
图4为本发明的实施例4的caffemodel模型压缩系统的模块示意图。
图5为本发明的实施例5的电子设备的结构示意图。
具体实施方式
下面通过实施例的方式进一步说明本发明,但并不因此将本发明限制在所述的实施例范围之中。
caffe是一种开源深度学习框架,本实施例基于caffe深度学习框架实现,可以对pvanet-faster-rcnn训练后得到的caffemodel模型文件进行压缩。caffemodel模型中fc6层的weights(权重)参数和fc7层的weights参数均以稠密矩阵的形式存在。在实施之前,需要准备的文件包括:pvanet-faster-rcnn训练后的待压缩的caffemodel模型,训练该caffemodel模型时的训练集。
实施例1
本实施例提供一种caffemodel模型压缩方法,压缩过程中可对caffemodel模型的fc6层和fc7层进行相同的压缩处理,也可单独分别对fc6层和fc7层进行压缩处理。
如图1所示,caffemodel模型压缩方法包括:
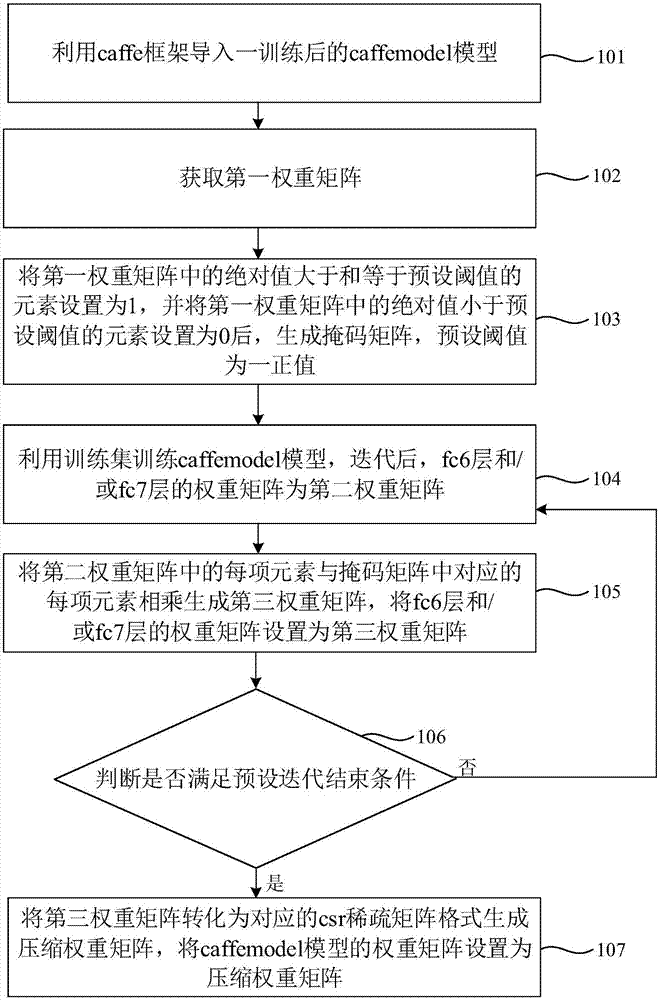
步骤101:利用caffe框架导入一训练后的caffemodel模型,caffemodel模型包括fc6层和/或fc7层,fc6层和/或fc7层的权重矩阵为第一权重矩阵。
步骤102:获取第一权重矩阵。
步骤103:将第一权重矩阵中的绝对值大于和等于预设阈值的元素设置为1,并将第一权重矩阵中的绝对值小于预设阈值的元素设置为0后,生成掩码矩阵,预设阈值为一正值。
本实施例中,fc6层与fc7层选用的预设阈值根据实际情况可分别选择不同的值。
步骤104:利用训练集训练caffemodel模型,迭代后,fc6层和/或fc7层的权重矩阵为第二权重矩阵。
步骤105:将第二权重矩阵中的每项元素与掩码矩阵中对应的每项元素相乘生成第三权重矩阵,将fc6层和/或fc7层的权重矩阵设置为第三权重矩阵。
步骤106:判断是否满足预设迭代结束条件,若是,则迭代结束,执行步骤107,若否,则返回步骤104。
直至达到预设迭代结束条件,则迭代结束。预设迭代结束条件可以与caffe框架导入的训练后的caffemodel模型训练时的迭代结束条件相同。
步骤107:将第三权重矩阵转化为对应的csr稀疏矩阵格式生成压缩权重矩阵,将caffemodel模型的权重矩阵设置为压缩权重矩阵。
从而使得caffemodel模型的占用空间大大减小,可使得caffemodel模型在进行后续运算时占用gpu显存空间减少,从而提高gpu运算性能。
实施例2
本实施例提供一种caffemodel模型压缩方法,本实施例与实施例1相比,其区别在于,caffemodel模型压缩方法在步骤107之前还包括:
步骤107-1:迭代结束后,获得caffemodel模型的训练精度为迭代训练精度,迭代前的caffemodel模型的训练精度为原始训练精度。
步骤107-2:计算迭代训练精度相比原始训练精度的下降比例。
步骤107-3:判断下降比例是否高于预设精度比例,若是,则执行步骤107-4,若否,执行步骤107。预设精度比例的范围可设置为0.1%-0.5%。
步骤107-4:降低预设阈值,返回步骤103。
步骤107包括:
直至下降比例低于预设精度比例,将第三权重矩阵转化为对应的稀疏矩阵格式生成压缩权重矩阵。
本实施例中的预设精度比例选择为0.5%。
在实际应用中,用该方法对一个可以检测20种物体的pvanet-faster-rcnn的caffemodel模型进行压缩,caffemodel模型的初始大小为369mb,应用此方法将caffemodel模型压缩后为37mb时,模型精度下降比例仅为0.36%。获得了与caffemodel初始模型的原始训练精度相当,但占用空间更小的新模型。
优选地,将caffemodel模型的权重矩阵设置为压缩权重矩阵的步骤之后还括:
利用fc6层和/或fc7层接收输入数据,并将输入数据与压缩权重矩阵作相乘运算得到输出数据。
当模型进行前向计算时,fc6层的输入数据与fc6层的权重矩阵进行相乘产生该层输出数据,fc7层的输入数据与fc7层的权重矩阵进行相乘产生该层输出数据。相比之前,压缩后的caffemodel模型的占用空间大小,使得在模型前向计算时,模型占用的gpu显存资源空间减少,大大提高了gpu的运行性能。
实施例3
本实施例提供一种caffemodel模型压缩系统,如图3所示,caffemodel模型压缩系统包括导入模块201、掩码生成模块202、迭代模块203、掩码模块204、返回模块205和转化模块206。
导入模块201用于利用caffe框架导入一训练后的caffemodel模型,caffemodel模型包括fc6层和/或fc7层,fc6层和/或fc7层的权重矩阵为第一权重矩阵。
掩码生成模块202用于获取第一权重矩阵,并将第一权重矩阵中的绝对值大于和等于预设阈值的元素设置为1,并将第一权重矩阵中的绝对值小于预设阈值的元素设置为0后,生成掩码矩阵,预设阈值为一正值。
本实施例中,fc6层与fc7层选用的预设阈值根据实际情况可分别选择不同的值。
迭代模块203用于利用训练集训练caffemodel模型,迭代后,fc6层和/或fc7层的权重矩阵为第二权重矩阵。
掩码模块204用于将第二权重矩阵中的每项元素与掩码矩阵中对应的每项元素相乘生成第三权重矩阵,将fc6层和/或fc7层的权重矩阵设置为第三权重矩阵。
返回模块205用于调用迭代模块203。
转化模块206用于当直至达到预设迭代结束条件,迭代结束后,将第三权重矩阵转化为对应的csr稀疏矩阵格式生成压缩权重矩阵,将caffemodel模型的权重矩阵设置为压缩权重矩阵。预设迭代结束条件可以与caffe框架导入的训练后的caffemodel模型训练时的迭代结束条件相同。
从而使得caffemodel模型的占用空间大大减小,可使得caffemodel模型在进行后续运算时占用gpu显存空间减少,从而提高gpu运算性能。
实施例4
本实施例提供一种caffemodel模型压缩系统,本实施例与实施例3相比,区别在于,如图4所示,caffemodel模型压缩系统还包括精度比较模块207,精度比较模块207用于迭代结束后,以及获得caffemodel模型的训练精度为迭代训练精度,迭代前的caffemodel模型的训练精度为原始训练精度;
精度比较模块207还用于计算迭代训练精度相比原始训练精度的下降比例,若下降比例高于预设精度比例,则降低预设阈值,调用掩码矩阵生成模块;预设精度比例的范围可设置为0.1%-0.5%。
转化模块206还用于直至下降比例低于预设精度比例,将第三权重矩阵转化为对应的稀疏矩阵格式生成压缩权重矩阵。
本实施例中的预设精度比例选择为0.5%。
在实际应用中,用该方法对一个可以检测20种物体的pvanet-faster-rcnn的caffemodel模型进行压缩,caffemodel模型的初始大小为369mb,应用此方法将caffemodel模型压缩后为37mb时,模型精度下降比例仅为0.36%。获得了与caffemodel初始模型的原始训练精度相当,但占用空间更小的新模型。
优选地,caffemodel模型压缩系统还括运算模块,运算模块用于利用fc6层和/或fc7层接收输入数据,并将输入数据与压缩权重矩阵作相乘运算得到输出数据。
当模型进行前向计算时,fc6层的输入数据与fc6层的权重矩阵进行相乘产生该层输出数据,fc7层的输入数据与fc7层的权重矩阵进行相乘产生该层输出数据。相比之前,压缩后的caffemodel模型的占用空间大小,使得在模型前向计算时,模型占用的gpu显存资源空间减少,大大提高了gpu的运行性能。
实施例5
图5为本实施例提供的一种电子设备的结构示意图。所述电子设备包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现实施例1的caffemodel模型压缩方法。图5显示的电子设备30仅仅是一个示例,不应对本发明实施例的功能和使用范围带来任何限制。
如图5所示,电子设备30可以以通用计算设备的形式表现,例如其可以为服务器设备。电子设备30的组件可以包括但不限于:上述至少一个处理器31、上述至少一个存储器32、连接不同系统组件(包括存储器32和处理器31)的总线33。
总线33包括数据总线、地址总线和控制总线。
存储器32可以包括易失性存储器,例如随机存取存储器(ram)321和/或高速缓存存储器322,还可以进一步包括只读存储器(rom)323。
存储器32还可以包括具有一组(至少一个)程序模块324的程序/实用工具325,这样的程序模块324包括但不限于:操作系统、一个或者多个应用程序、其它程序模块以及程序数据,这些示例中的每一个或某种组合中可能包括网络环境的实现。
处理器31通过运行存储在存储器32中的计算机程序,从而执行各种功能应用以及数据处理,例如本发明实施例1所提供的caffemodel模型压缩方法。
电子设备30也可以与一个或多个外部设备34(例如键盘、指向设备等)通信。这种通信可以通过输入/输出(i/o)接口35进行。并且,模型生成的设备30还可以通过网络适配器36与一个或者多个网络(例如局域网(lan),广域网(wan)和/或公共网络,例如因特网)通信。如图所示,网络适配器36通过总线33与模型生成的设备30的其它模块通信。应当明白,尽管图中未示出,可以结合模型生成的设备30使用其它硬件和/或软件模块,包括但不限于:微代码、设备驱动器、冗余处理器、外部磁盘驱动阵列、raid(磁盘阵列)系统、磁带驱动器以及数据备份存储系统等。
应当注意,尽管在上文详细描述中提及了电子设备的若干单元/模块或子单元/模块,但是这种划分仅仅是示例性的并非强制性的。实际上,根据本发明的实施方式,上文描述的两个或更多单元/模块的特征和功能可以在一个单元/模块中具体化。反之,上文描述的一个单元/模块的特征和功能可以进一步划分为由多个单元/模块来具体化。
实施例6
本实施例提供了一种计算机可读存储介质,其上存储有计算机程序,所述程序被处理器执行时实现实施例1所提供的caffemodel模型压缩方法。
其中,可读存储介质可以采用的更具体可以包括但不限于:便携式盘、硬盘、随机存取存储器、只读存储器、可擦拭可编程只读存储器、光存储器件、磁存储器件或上述的任意合适的组合。
在可能的实施方式中,本发明还可以实现为一种程序产品的形式,其包括程序代码,当所述程序产品在终端设备上运行时,所述程序代码用于使所述终端设备执行实现实施例1所述的caffemodel模型压缩方法中的步骤。
其中,可以以一种或多种程序设计语言的任意组合来编写用于执行本发明的程序代码,所述程序代码可以完全地在用户设备上执行、部分地在用户设备上执行、作为一个独立的软件包执行、部分在用户设备上部分在远程设备上执行或完全在远程设备上执行。
虽然以上描述了本发明的具体实施方式,但是本领域的技术人员应当理解,这仅是举例说明,本发明的保护范围是由所附权利要求书限定的。本领域的技术人员在不背离本发明的原理和实质的前提下,可以对这些实施方式做出多种变更或修改,但这些变更和修改均落入本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!