基于MapReduce的BP神经网络建筑能耗预测方法与流程
本发明属于建筑物能耗预测领域,尤其是一种基于mapreduce的bp神经网络建筑能耗预测方法。
背景技术:
随着城市化进程的不断加速,能源问题日益突出,建筑节能已经成为了当今社会发展的研究热点,对建筑系统能耗进行全面的评估和综合分析是进行节能改造或节能设计的前提和基础,而建立反应能耗变化的预测模型是从宏观尺度上分析认识建筑能耗变化与发展特性为公共建筑节能工作提供决策依据的有效途径和重要手段。
bp神经网络预测具有很强的非线性映射能力,善于从输入和输出信号中寻找规律,不需要精确的数学模型,并且计算能力强。但是传统bp神经网络容易导致局部最小值,固定的学习率在学习过程中容易出现瘫痪现象或学习时间过长。
技术实现要素:
本发明所解决的技术问题在于提供一种基于mapreduce的bp神经网络建筑能耗预测方法,采用mapreduce结合bp神经网络,通过并行计算来调整和校正神经网络中的连接权值,实现了对建筑物的能耗预测,解决了建筑物能耗预测结果准确性低的问题,以及bp神经网络容易陷入局部极值、求解精度低的问题。
实现本发明目的的技术解决方案为:
基于mapreduce的bp神经网络建筑能耗预测方法,包括以下步骤:
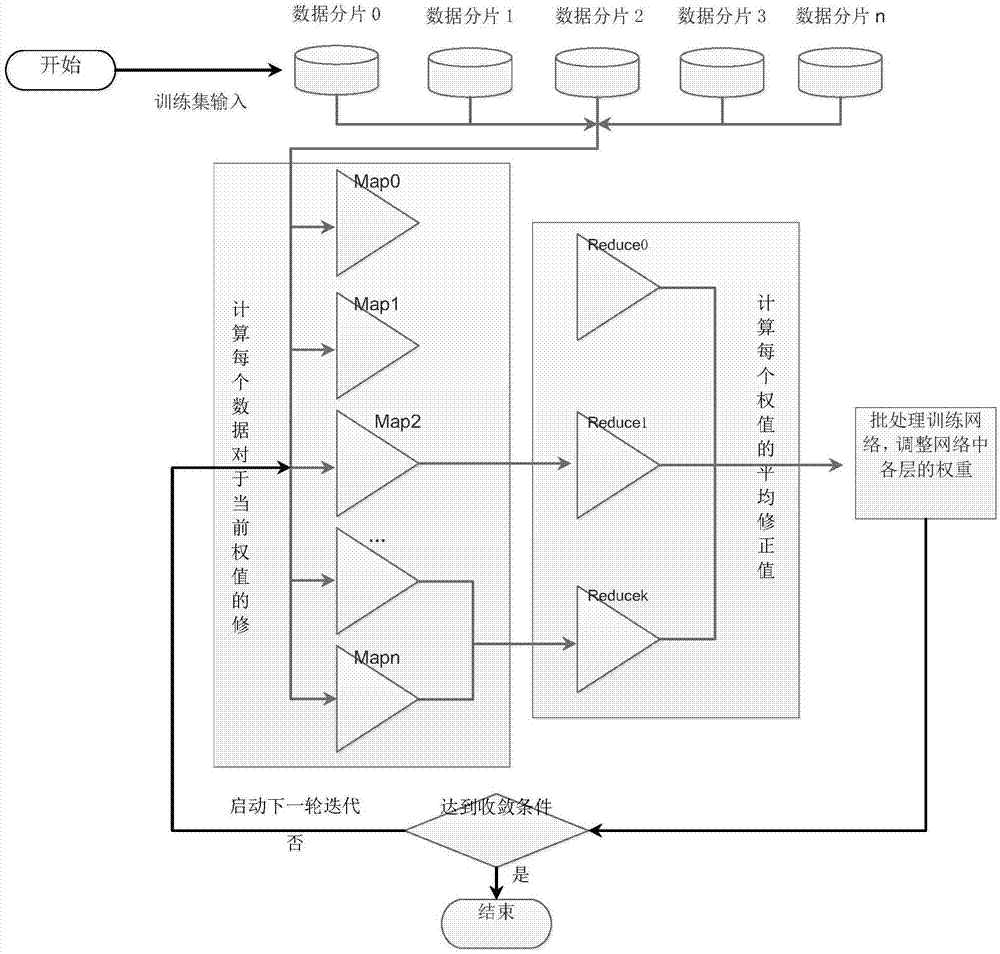
步骤1:将经过数据预处理后的建筑能耗数据集分为n个数据分片作为训练样本,每个训练样本均包括影响因子数据,将训练样本分别传送至n个映射任务模块,每个映射任务模块接收一个训练样本;
步骤2:映射任务模块对训练样本进行bp神经网络训练,并计算当前网络隐含层到输出层的连接权值a及其变化量b,生成的中间结果(a,b)并输出给归约任务模块;
步骤3:归约任务模块接收映射任务模块的(a,b)序列,将连接权值a相同的序列分到同一个归约任务模块中;
步骤4;计算所有连接权值a及其变化量b的平均值并输出;
步骤5:批处理训练网络,调整网络中隐含层、输出层的权重;
步骤6:若bp神经网络的误差达到预设的误差目标或学习次数达到预设最大迭代次数,则停止训练,输出建筑能耗bp神经网络预测模块,否则转到步骤2;
步骤7:预测建筑能耗。
进一步的,本发明的基于mapreduce的bp神经网络建筑能耗预测方法,数据预处理为:通过分析建筑能耗数据系统中的等价类关系,根据不一致记录的情况,去掉冗余的属性,得到一个与原来数据系统具有相同特性的训练数据集。
进一步的,本发明的基于mapreduce的bp神经网络建筑能耗预测方法,建筑能耗数据中的影响因子包括:墙体平均传热系数、墙体平均热惰性指标、屋顶传热系数、体形系数、平均窗墙比、建筑朝向、外墙太阳辐射吸收系数、综合遮阳系统。
进一步的,本发明的基于mapreduce的bp神经网络建筑能耗预测方法,步骤6中的误差目标为:平均相对误差小于5%或标准误差小于3%。
进一步的,本发明的基于mapreduce的bp神经网络建筑能耗预测方法,步骤6中的最大迭代次数为30次。
进一步的,本发明的基于mapreduce的bp神经网络建筑能耗预测方法,映射任务模块中还包括阈值配置数据,阈值配置数据包括隐含层神经元的阈值和输出层神经元的阈值。
本发明采用以上技术方案与现有技术相比,具有以下技术效果:
1、本发明的基于mapreduce的bp神经网络建筑能耗预测方法采用mapreduce,实现并行运算,避免了bp神经网络陷入局部极值、求解精度低;
2、本发明的基于mapreduce的bp神经网络建筑能耗预测方法采用bp神经网络,调整和校正神经网络中的连接权值,实现了对建筑物的能耗预测,解决了建筑物能耗预测结果准确性低的问题。
附图说明
图1是本发明的基于mapreduce的bp神经网络建筑能耗预测方法流程图;
图2是本发明的基于mapreduce的bp神经网络建筑能耗预测方法的数据预处理流程图;
图3是本发明的基于mapreduce的bp神经网络建筑能耗预测方法的bp神经网络训练流程图。
具体实施方式
下面详细描述本发明的实施方式,所述实施方式的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施方式是示例性的,仅用于解释本发明,而不能解释为对本发明的限制。
基于bp神经网络的建筑能耗预测方法,如图1所示,包括以下步骤:
步骤1:将经过数据预处理后的建筑能耗数据集分为n个数据分片作为训练样本,每个训练样本均包括影响因子数据,将训练样本分别传送至n个映射任务模块,每个映射任务模块接收一个训练样本。其中,数据预处理为:通过分析建筑能耗数据系统中的等价类关系,根据不一致记录的情况,去掉冗余的属性,得到一个与原来数据系统具有相同特性的训练数据集。建筑能耗数据中的影响因子包括:墙体平均传热系数、墙体平均热惰性指标、屋顶传热系数、体形系数、平均窗墙比、建筑朝向、外墙太阳辐射吸收系数、综合遮阳系统。
步骤2:映射任务模块中还包括阈值配置数据,阈值配置数据包括隐含层神经元的阈值和输出层神经元的阈值,映射任务模块对训练样本进行bp神经网络训练,并计算当前网络隐含层到输出层的连接权值a及其变化量b,生成的中间结果(a,b)并输出给归约任务模块。
步骤3:归约任务模块接收映射任务模块的(a,b)序列,将连接权值a相同的序列分到同一个归约任务模块中。
步骤4;计算所有连接权值a及其变化量b的平均值并输出。
步骤5:批处理训练网络,调整网络中隐含层、输出层的权重。
步骤6:若bp神经网络的误差达到平均相对误差小于5%或标准误差小于3%或学习次数达到30次,则停止训练,输出建筑能耗bp神经网络预测模块,否则转到步骤2。
步骤7:预测建筑能耗。
具体来说,数据预处理的过程为:根据粗糙集理论,采用mapreduce的并行算法对数据样本进行约简,即通过分析建筑能耗系统中的等价类关系,确定系统中的不一致记录的情况,从而去掉冗余的属性,得到一个与原来的系统具有相同特性的相对简约的系统。算法描述图2所示,具体为:
将数据集合分为若干个数据分片,判断每个数据分片的不一致子集是否为核属性,得到每个数据分片的核集和混合状态集合;再合并核集相同的数据分片,并统计混合状态集合的不一致记录数;计算每个数据分片的非核属性的重要参数sgf,并将sgf最小的属性加入核集,若sgf等于记录数,则输出每个数据分片的核集,否则返回计算每个数据分片的非核属性的重要参数sgf,直到sgf等于记录数。
具体来说,构建建筑能耗的bp神经网络预测模型的训练过程如图3所示,具体为:
以建筑能耗数据的影响因素作为输入、建筑能耗数据作为输出,计算隐含层各单元的输入输出,计算输出层各单元的输入输出,再计算输出层各单元的校正误差,计算隐含层各单元的校正误差,并根据误差值调整隐含层到输出层的连接权值和输出层各单元的输出阈值,直到全部样本都训练完且学习次数、误差均满足阈值,则得到训练完的预测模型。
阈值配置数据用两行float型数据表示,第一行与隐含层神经元个数相同,表示隐含层各神经元的阈值,第二行与输出层神经元相同,表示输出层各神经元的阈值。利用训练好的网络对样本数据进行预测时,输入数据也必须为float型,且与训练样本的输入个数相同。网络预测结束后,结果输出到hdfs的output文件夹下,文件中的输出数据同样为fioat型,与训练样本的输出个数相同。
本发明通过选取几幢大型公共建筑能耗信息的数据采集,将过去1年内的数据量(约100万条)进行bp网络模型训练,并选取部分典型建筑的预测结果和当前同期数据对比,通过30次本地迭代的bp神经网络,满足平均相对误差小于5%、标准误差小于3%,较为准确地实现了对建筑能耗的预测。
以上所述仅是本发明的部分实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进,这些改进应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!