使用基于CNN的集成电路的自然语言处理的制作方法
本发明总体上涉及机器学习领域,更具体地涉及使用基于细胞神经网络或细胞非线性网络(cnn)的集成电路的自然语言处理。
背景技术:
表意符号(ideogram,意符、表意文字)是表示想法或概念的图形符号。一些表意符号只能通过熟悉先前的惯例才能理解;其他表意符号通过与物理对象的图像相似性来表达其意义。
机器学习是人工智能的应用。在机器学习中,计算机或计算设备被编程为像人类那样思考,使得可以教导计算机自己学习。神经网络的发展是教导计算机以人类思考和理解世界的方式对世界进行思考和理解的关键。
技术实现要素:
公开了使用基于细胞神经网络或细胞非线性网络(cnn)的集成电路的自然语言处理的方法。根据本发明的一个方面,在具有安装在其上的至少2-d符号创建应用模块的计算系统中接收自然语言文本串并形成多层二维(2-d)符号。2-d符号包括表示“超级字符”的k位数据的n×n像素矩阵。矩阵被划分成m×m个子矩阵,每个子矩阵包含(n/m)×(n/m)个像素。k、n和m是正整数,并且n优选地是m的倍数。每个子矩阵表示被定义在表意符号收集集合中的一个表意符号。“超级字符”表示由多个表意符号的特定组合形成的含义。在基于细胞神经网络或细胞非线性网络(cnn)集成电路中,通过经由具有双值3×3滤波器内核的经训练的卷积神经网络模型对2-d符号进行分类来学习“超级字符”的含义。
根据另一方面,通过下述操作实现经训练的卷积神经网络模型:(a)通过基于包含足够大量的多层2-d符号的标记(labeled,有标签的、示踪的)数据集的图像分类对卷积神经网络模型进行训练来获得卷积神经网络模型,卷积神经网络模型包括多个有序(ordered)滤波器组,多个有序滤波器组中的每个滤波器都包含标准3×3滤波器内核;(b)通过基于一组内核转换方案将多个有序滤波器组中的当前被处理的滤波器组的相应的标准3×3滤波器内核转换为对应的双值3×3滤波器内核,来修改卷积神经网络模型;(c)对经修改的卷积神经网络模型进行再训练,直至达到期望的收敛标准;(d)对另一滤波器组重复(b)至(c),直至所有多个有序滤波器组都已转换为双值3×3滤波器内核。
表意符号收集集合包括但不限于象形图、图标、徽标、意音(logosyllabic)字符、标点符号、数字、特殊字符。
本发明的目的、特征和优点之一是使用基于cnn的集成电路,该基于cnn的集成电路具有用于执行同时卷积的专用内置逻辑,使得在硬件中执行用于自然语言处理的图像处理技术(即,卷积神经网络)。
通过结合附图研究下面对本发明实施方式的详细描述,本发明的其他目的、特征和优点将变得明显。
附图说明
考虑到以下描述内容、后附的权利要求书和附图,本发明这些和其他特征、方面以及优点将被更好地理解:
图1是示出根据本发明的实施方式的示例二维符号的框图,该二维符号包括表示“超级字符”的数据的n×n像素矩阵,用于促进对其中包含的多个表意符号的组合含义进行机器学习;
图2a至图2b是示出根据本发明实施方式的用于划分图1的二维符号的示例分区方案的框图;
图3a至图3b示出了根据本发明实施方式的示例表意符号;
图3c示出了根据本发明实施方式的包含基于拉丁字母的西方语言的示例象形图;
图3d示出了根据本发明实施方式的示例表意符号的三个相应基本颜色层;
图3e示出了根据本发明实施方式的用于字典式定义的示例表意符号的三个相关层;
图4a是示出根据本发明的一种实施方式的用于对二维符号中包含的多个表意符号的组合含义进行机器学习的示例基于细胞神经网络或细胞非线性网络(cnn)的计算系统的框图;
图4b是示出根据本发明的一种实施方式的用于基于卷积神经网络执行图像处理的示例基于cnn的集成电路的框图;
图5a是示出根据本发明实施方式的使用多层二维符号对书面自然语言进行机器学习的示例过程的流程图;
图5b是示出根据本发明实施方式的利用图像处理技术经由多层二维符号的示例自然语言处理的示意框图;
图6a至图6c共同地是示出根据本发明实施方式的从自然语言文本串形成包含多个表意符号的二维符号的示例过程的流程图;
图7是示出根据本发明实施方式的基于卷积神经网络的示例图像处理技术的示意框图;
图8是示出根据本发明的一种实施方式的基于cnn的集成电路中的示例cnn处理引擎的框图;
图9是示出根据本发明实施方式的图8的示例cnn处理引擎内的示例图像数据区域的框图;
图10a至图10c是示出根据本发明实施方式的图9的示例图像数据区域内的三个示例像素位置的框图;
图11是示出根据本发明的一种实施方式的用于在图8的示例cnn处理引擎中的像素位置处执行3×3卷积的示例数据布置的框图;
图12a至图12b是示出根据本发明实施方式的两个示例2×2池化操作的框图;
图13是示出根据本发明的一种实施方式的图8的示例cnn处理引擎中的图像数据的2×2池化操作的框图;
图14a至图14c是示出根据本发明的一种实施方式的输入图像内的图像数据区域的各种示例的框图;
图15是示出根据本发明实施方式的多个cnn处理引擎经由示例时钟偏移电路被连接作为环路的框图;
图16是示出根据本发明实施方式的使用基于cnn的集成电路的自然语言处理的示例过程的流程图;
图17是示出根据本发明实施方式的实现具有双值3×3滤波器内核的经训练的卷积神经网络模型的示例过程的流程图;
图18是示出示例数据转换方案的框图;以及
图19是示出根据本发明的示例滤波器内核转换方案的框图。
具体实施方式
本文对“一种实施方式”或“实施方式”的参照意味着关于该实施方式描述的具体特征、结构或特性可以被包括在本发明的至少一种实施方式中。在说明书中各处出现的措辞“在一种实施方式中”不一定都指同一实施方式,也不是与其它实施方式互斥的单独的或替代的实施方式。本文所使用的术语“竖向”、“水平”、“对角线”、“左”、“右”、“顶部”、“底部”、“列”、“行”、“对角线地”旨在出于描述的目的而提供相对位置,并非旨在指定绝对参照标准。另外,本文所使用的术语“字符”和“文字(script)”可互换使用。
本文参照图1至图19讨论本发明的实施方式。然而,本领域技术人员将容易理解,本文关于这些附图给出的详细描述是出于解释的目的,因为本发明超出了这些受限的实施方式。
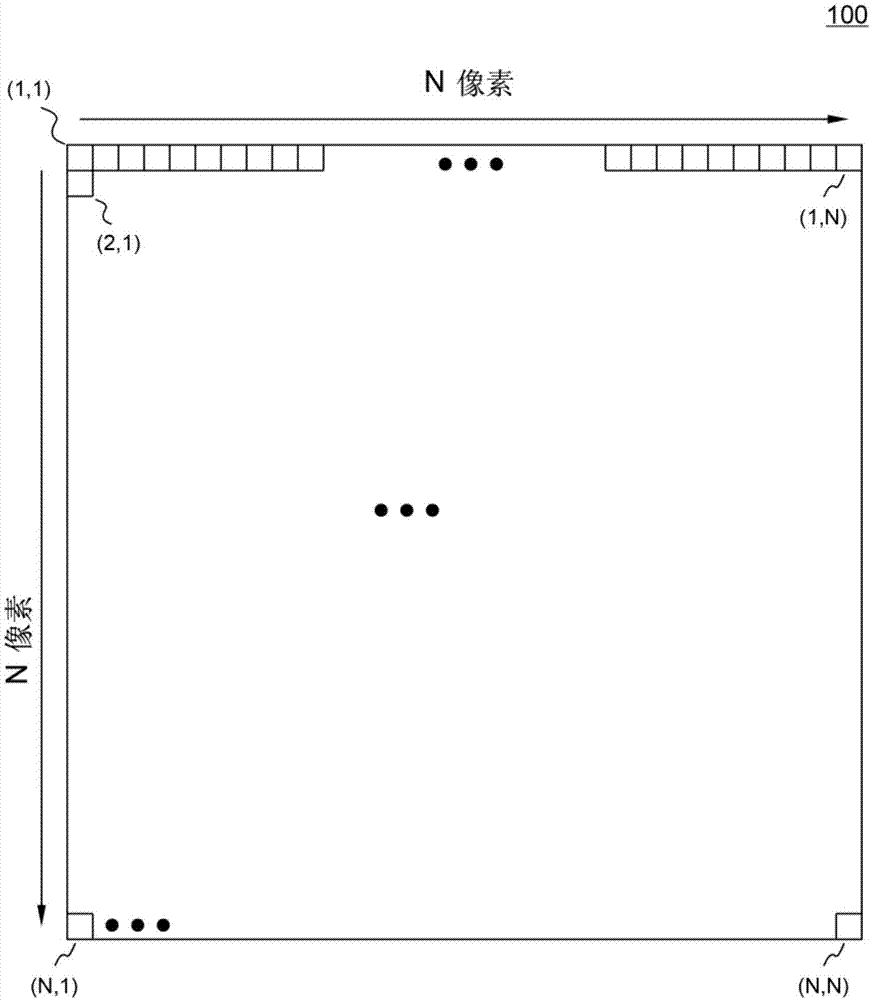
首先参照图1,图1示出了一框图,该框图示出了用于促进对其中包含的多个表意符号的组合含义进行机器学习的示例性二维符号100。二维符号100包括包含“超级字符(super-character)”的数据的n×n像素(即,n列×n行)的矩阵。像素按照首先是行然后是列进行排序,如下所示:(1,1)、(1,2)、(1,3)、...(1,n)、(2,1)、..、(n,1)、...(n,n)。n是正整数或正的整数(wholenumber),例如在一种实施方式中,n等于224。
“超级字符”表示至少一个含义,每个含义均由多个表意符号的特定组合形成。由于表意符号可以用特定大小的像素矩阵表示,因此二维符号100被分划成m×m个子矩阵。每个子矩阵表示被定义在人类的表意符号收集集合中的一个表意符号。“超级字符”包含最少两个和最多m×m个表意符号。n和m都是正整数或正的整数,并且n优选是m的倍数。
如图2a所示,图2a是将二维符号划分为m×m个子矩阵212的第一示例分区方案210。在该第一示例分区方案中,m等于4。m×m个子矩阵212中的每一个子矩阵均包含(n/m)×(n/m)个像素。当n等于224时,每个子矩阵包含56×56个像素,并且有16个子矩阵。
图2b中示出了将二维符号划分为m×m个子矩阵222的第二示例分区方案220。在第二示例分区方案中,m等于8。m×m个子矩阵222中的每一个子矩阵均包含(n/m)×(n/m)个像素。当n等于224时,每个子矩阵包含28×28个像素,并且有64个子矩阵。
图3a示出了可以在子矩阵222(即,28×28个像素)中表示的示例表意符号301-304。本领域普通技术人员将理解,具有56×56个像素的子矩阵212也可以适于表示这些表意符号。第一示例表意符号301是表示骑自行车的人的图标的象形图。第二示例表意符号302是表示示例中文字符的意音(logosyllabic,形音并存的)文字或字符。第三示例表意符号303是表示示例日文字符的意音文字或字符,并且第四示例表意符号304是表示示例韩文字符的意音文字或字符。另外,表意符号也可以是标点符号、数字或特殊字符。在另一实施方式中,象形图可以包含其他图像的图标。该文献中使用的图标被人类定义为标号或表示,该标号或表示借助其相似物或类似物来代表其对象。
图3b示出了表示标点符号311、数字312和特殊字符313的几个示例表意符号。此外,象形图可以包含基于拉丁字母的一个或多个西方语言单词,例如,英语、西班牙语、法语、德语等。图3c示出了包含基于拉丁字母的西方语言的示例象形图。第一示例象形图326示出了英语单词“mall”。第二示例象形图327示出了拉丁字母
可以使用单个二维符号来表示表意符号的仅有限数量的特征。例如,当每个像素的数据包含一位(bit,比特)时,表意符号的特征可以是黑色和白色。在每个像素中的数据包含不止一位的情况下,可以显示特征,诸如灰度色度。
使用表意符号的两个或多个层来表示附加特征。在一种实施方式中,表意符号的三个相应基本颜色层(即,红色、绿色和蓝色)共同用于表示表意符号中的不同颜色。二维符号的每个像素中的数据包含k位二进制数。k是正整数或正的整数。在一种实施方案中,k为5。
图3d示出了示例表意符号的三个相应基本颜色层。中文字符的表意符号用红色331、绿色332和蓝色333示出。利用三种基本颜色的不同组合强度,可以表示许多颜色色度。表意符号中可能存在多种颜色色度。
在另一实施方式中,三个相关的表意符号用于表示其他特征,诸如图3e中所示的字典式定义的中文字符。图3e中示例表意符号存在三层:示出中文意音字符的第一层341、示出中文“拼音”发音为“wang”的第二层342以及示出英文含义为“king”的第三层343。
表意符号收集集合包括但不限于象形图、图标、徽标、意音字符、标点符号、数字、特殊字符。意音字符可能包含中文字符、日文字符、韩文字符等中的一种或多种。
为了系统地包括中文字符,可以使用标准中文字符集合(例如,gb18030)作为表意符号收集集合的开始。对于包括日文和韩文字符,可以使用cjk统一表意符号。也可以使用用于意音字符或文字的其他字符集合。
在基于细胞神经网络或细胞非线性网络(cnn)的计算系统中,“超级字符”中包含的表意符号的特定组合含义是使用图像处理技术得到的结果。图像处理技术包括但不限于卷积神经网络、递归神经网络等。
“超级字符”表示最多m×m个表意符号中的至少两个表意符号的组合含义。在一种实施方式中,象形图和中文字符被组合以形成特定含义。在另一实施方式中,组合两个或多个中文字符以形成含义。在又一实施方式中,将一个中文字符和韩文字符组合以形成含义。关于要组合哪两个或多个表意符号,没有限制。
包含在二维符号中的用于形成“超级字符”的表意符号可以任意地定位。不要求在二维符号中的特定顺序。表意符号可以从左到右、从右到左、从上到下、从下到上或对角地布置。
使用书面中文语言作为示例,组合两个或多个中文字符可以产生“超级字符”,包括但不限于短语、成语、谚语、诗歌、句子、段落、书面章节、文章(即书面作品)。在某些情况下,“超级字符”可能位于书面中文语言的特别区域中。特别区域可以包括但不限于某些民间故事、历史时期、特定背景等。
现在参照图4a,图4a示出了一框图,该框图示出了示例基于cnn的计算系统400,该基于cnn的计算系统被配置成用于对二维符号(例如,二维符号100)中包含的多个表意符号的组合含义进行机器学习。
基于cnn的计算系统400可以在集成电路上实现为数字半导体芯片(例如,硅衬底),并且包含控制器410和可操作地耦接到至少一个输入/输出(i/o)数据总线420的多个cnn处理单元402a-402b。控制器410被配置成控制利用时钟偏移电路连接成环路的cnn处理单元402a-402b的各种操作。
在一种实施方式中,cnn处理单元402a-402b中的每一个都被配置用于处理图像数据,例如,图1的二维符号100。
为了存储表意符号收集集合,需要可操作地耦接到基于cnn的计算系统400的一个或多个存储单元。存储单元(未示出)可以基于众所周知的技术位于基于cnn的计算系统400的内部或外部。
在某些情况下,“超级字符”可以包含不止一种含义。“超级字符”可以容忍能够通过错误纠正技术进行纠正的某些错误。换句话说,像素表示表意符号不必是精确的。错误可能有不同的原因,例如,数据损坏、处于数据检索期间等。
在另一实施方式中,基于cnn的计算系统可以是可扩展和可变规模的数字集成电路。例如,数字集成电路的多个副本可以在单个半导体芯片上实现,如图4b所示。
所有cnn处理引擎都是相同的。为了说明简单,图4b中仅示出了少数(即,cnn处理引擎422a-422h、432a-432h)。本发明对数字半导体芯片上的cnn处理引擎的数量没有限制。
每个cnn处理引擎422a-422h、432a-432h包含cnn处理块424、第一组存储缓冲器426和第二组存储缓冲器428。第一组存储缓冲器426被配置用于接收图像数据,并用于将已接收的图像数据提供给cnn处理块424。第二组存储缓冲器428被配置用于存储滤波器系数,并用于将已接收的滤波器系数提供给cnn处理块424。一般来说,芯片上cnn处理引擎的数量是2n,其中n是整数(即,0、1、2、3......)。如图4b所示,cnn处理引擎422a-422h可操作地耦接到第一输入/输出数据总线430a,而cnn处理引擎432a-432h可操作地耦接到第二输入/输出数据总线430b。每个输入/输出数据总线430a-430b被配置用于独立地传输数据(即,图像数据和滤波器系数)。在一种实施方式中,第一和第二组存储缓冲器包括可以是一种或多种类型的组合的随机存取存储器(ram),例如,磁随机存取存储器、静态随机存取存储器等。第一组和第二组中的每一组都是逻辑上定义的。换句话说,可以重配置第一组和第二组的相应大小以适应图像数据和滤波器系数的相应量。
这里示出第一和第二i/o数据总线430a-430b以顺序方案连接cnn处理引擎422a-422h、432a-432h。在另一实施方式中,至少一个i/o数据总线可以具有到cnn处理引擎的不同的连接方案,以实现并行数据输入和输出的相同目的,从而改善性能。
图5a是示出根据本发明实施方式的使用多层二维符号对书面自然语言进行机器学习的示例过程500的流程图。过程500可以以软件实现为安装在至少一个计算机系统中的应用模块。过程500也可以以硬件(例如,集成电路)实现。图5b是示出根据本发明实施方式的经由多层二维符号利用图像处理技术的示例自然语言处理的示意框图。
过程500在动作502处开始——在其上安装有至少一个应用模块522的第一计算系统520中接收自然语言文本串510。第一计算系统520可以是能够将自然语言文本串510转换为多层二维符号531a-531c(即,多层中的数据的n×n像素矩阵中包含的图像)的通用计算机。
接下来,在动作504,利用第一计算系统520中的至少一个应用模块522,从所接收的串510形成包含m×m个表意符号532的多层二维符号531a-531c(例如,图1的二维符号100)。m是正整数或正的整数。每个二维符号531a-531c是包含“超级字符”的数据的n×n像素矩阵。矩阵被划分成表示相应m×m个表意符号的m×m个子矩阵。“超级字符”表示由多层二维符号531a-531c中包含的多个表意符号的特定组合形成的含义。m和n是正整数或正的整数,并且n优选地是m的倍数。在图6中示出和相应地描述了形成多层二维符号的更多细节。
最后,在动作506,通过使用图像处理技术538对在第一计算系统520中形成并发送到第二计算系统540的多个二维符号531a-531c进行分类,在第二计算系统540中学习多个二维符号531a-531c中包含的“超级字符”的含义。第二计算系统540能够对图像数据诸如多层二维符号531a-531c进行图像处理。
传输多层2-d符号531a-531c可以用许多众所周知的方式执行,例如,通过有线或无线网络。
在一种实施方式中,第一计算系统520和第二计算系统540是相同的计算系统(未示出)。
在又一实施方式中,第一计算系统520是通用计算系统,而第二计算系统540是被实现为在图4a所示的半导体芯片上的集成电路的基于cnn的计算系统400。
图像处理技术538包括预定义一组类别542(例如,图5b中所示的“类别-1”、“类别-2”、“类别-x”)。作为执行图像处理技术538的结果,类别的相应概率544被确定,以用于将每个预定义类别542与“超级字符”的含义相关联。在图5b所示的示例中,示出“类别-2”的概率最高,为88.08%。换句话说,多层二维符号531a-531c包含的“超级字符”的含义与在所有预定义类别544中的“类别-2”相关联的概率为88.08%。
在另一实施方式中,预定义类别包含可激活智能电子设备(例如,计算设备、智能电话、智能电器等)上的顺序指令的命令。例如,多层二维符号由16个意音中文字符的串形成。因此,多层2-d符号中的“超级字符”包含三种颜色(即,红色、绿色和蓝色)的16个表意符号。在将图像处理技术应用于2-d符号的图像数据之后,通过用一组预定义命令对图像数据进行分类来获得用于智能电子设备的一系列命令。在该特别示例中,16个意音中文字符的含义是“打开在线地图,找到至快餐店最近路线”。该系列的命令可以如下:
1)打开“在线地图”
2)搜索“我附近的快餐店”
3)进入
4)点击“开始”
在一种实施方式中,图像处理技术538包括图7中所示的示例卷积神经网络。在另一实施方式中,图像处理技术538包括对特定组意音字符(例如,中文字符)的图像进行手动特征构建(engineering)的支持向量机(svm)。
图6a至图6c共同地是示出根据本发明实施方式的由自然语言文本串形成包含多个表意符号的二维(2-d)符号的示例过程600的流程图。过程600可以以软件实现为安装在计算机系统中的应用模块。过程600也可以在硬件(例如,集成电路)中实现。
过程600在动作602处开始——在其上安装有至少一个应用模块的计算系统中接收自然语言文本串。示例应用模块是包含用于计算系统执行过程600中阐述的动作和判定的指令的软件。该自然语言文本串可以包括但不必限于意音字符、数字、特殊字符、基于拉丁字母的西方语言等。该自然语言文本串可以通过各种众所周知的方式例如键盘、鼠标、语音到文本等输入到计算系统。
接下来,在动作604,确定所接收的自然语言文本串的大小。然后在判定610处,确定大小是否大于m×m(即,二维符号中的表意符号的最大数量)。在一种实施方案中,m为4,因此m×m为16。在另一实施方案中,m为8,则m×m为64。
当判定610为真时,所接收的串太大而不能适配到2-d符号,并且必须首先根据下面描述的至少一种语言文本缩减方案进行缩减。
过程600在“是”分支后到达动作611。过程600尝试根据至少一种基于相关语法的规则识别串中的不重要文本。基于相关语法的规则与所接收的自然语言文本串相关联。例如,当自然语言是中文时,相关语法就是中文语法。接下来,在判定612处,确定是否识别出不重要的文本。如果“是”,则在动作613处,从串中删除所识别的不重要文本,因此串的大小缩减一。在判定614处,确定串的大小是否等于m×m。如果否,则过程600返回以重复动作611、判定612、动作613和判定614的环路。如果判定614为真,则过程600在执行动作618之后结束,在动作618中,通过转换处于其当前状态的串(即,可能已删除了一个或多个不重要的文本)来形成多层2-d符号。
在上述环路611-614期间,如果接收到的串中不再有不重要的文本,则判定612变为“否”。过程600移至动作616以另外通过可以是截短或任意选择的随机文本缩减方案将串的大小缩减到m×m。在动作618处,通过转换处于其当前状态的串来形成多层2-d符号。过程600此后结束。
随机文本缩减方案和上述删除不重要文本的方案被称为上述的至少一种语言文本缩减方案。
返回参照判定610,如果其为假,则过程600在“否”分支后到达判定620。如果接收到的串的大小等于m×m,则判定620为真。过程600移至其中通过转换所接收的串来形成多层2-d符号的动作622。过程600此后结束。
如果判定620为假(即,所接收的串的大小小于m×m),则过程600移至其中确定是否期望2-d符号的补填操作的另一判定630。如果“是”,则在动作632处,根据至少一种语言文本增加方案,用至少一个文本补填该串以将串的大小增加到m×m。换句话说,将至少一个文本添加到串,使得串的大小等于m×m。在一种实施方式中,语言文本增加方案要求首先从接收的串中识别一个或多个关键文本。然后,将一个或多个识别的关键文本重复地附加至接收的串。在另一实施方式中,语言文本增加方案要求将来自接收串的一个或多个文本重复地附加至串。接下来,执行动作622以通过转换经补填的串(即,接收的串加上至少一个附加文本)来形成多层2-d符号。过程600此后结束。
如果判定630为假,则过程600在执行动作634之后结束。通过对大小小于m×m的接收串进行转换来形成多层2-d符号。结果,2-d符号包含至少一个空白空间。在一种实施方式中,多层二维符号531a-531c包含红色、绿色和蓝色色调的三个层。二维符号的每层中的每个像素包含k位。在一种实施方式中,k=8以用于支持包含红色、绿色和蓝色的256种色度的全彩色。在另一实施方式中,k=5以用于具有红色、绿色和蓝色的32种色度的缩减彩色图。
图7是示出根据本发明实施方式的基于卷积神经网络的示例图像处理技术的示意框图。
基于卷积神经网络,利用卷积使用第一组滤波器或权重720处理作为输入图像数据的多层二维符号711a-711c。由于2-d符号711a-711c的图像数据大于滤波器720。处理图像数据的每个对应的重叠子区域715。在获得卷积结果之后,可以在第一池化操作730之前进行激活。在一种实施方式中,通过在整流线性单元(relu)中执行整流来实现激活。作为第一池化操作730的结果,图像数据被缩减为图像数据的缩减集合731a-731c。对于2×2池化,图像数据的缩减集合缩减为先前集合的1/4倍。
重复先前的卷积到池化程序。然后利用卷积使用第二组滤波器740处理图像数据的缩减集合731a-731c。类似地,处理每个重叠的子区域735。可以在第二池化操作740之前进行另一激活。卷积到池化程序对若干层重复并最终连接到完全连接(fc)层760。在图像分类中,预定义类别542的相应概率544可以在fc层760中计算。
使用已知的数据集或数据库训练该重复的卷积到池化程序。对于图像分类,数据集包含预定义的类别。滤波器、激活和池化的特别集合可以在用于分类图像数据,例如滤波器类型的特定组合、滤波器的数量、滤波器的顺序、池化类型和/或何时执行激活之前进行调整和获得。在一种实施方式中,图像数据是由自然语言文本串形成的多层二维符号711a-711c。
在一种实施方式中,卷积神经网络基于视觉几何组(vgg16)架构神经网。
图8中示出了基于cnn的集成电路中的cnn处理引擎802的更多细节。cnn处理块804包含数字电路,该数字电路通过使用(z+2)像素乘(z+2)像素区域的图像数据和来自相应的存储缓冲器的对应滤波器系数在z×z像素位置处执行3×3卷积来同时获得z×z卷积运算结果。(z+2)像素乘(z+2)像素区域被形成为z×z像素位置作为z像素乘z像素中心部分,加上一个像素边界围绕该中心部分。z是正整数。在一种实施方式中,z等于14,因此,(z+2)等于16,z×z等于14×14=196,并且z/2等于7。
图9是示出一框图,表示应用在cnn处理引擎802中的以z×z像素位置920为中心部分的(z+2)像素乘(z+2)像素区域910。
为了实现更快的计算,在cnn处理块804中使用并实现了少数计算性能改进技术。在一种实施方式中,图像数据的表示使用实际上尽可能少的位(例如,5位表示)。在另一实施方式中,每个滤波器系数表示为具有小数点的整数。类似地,表示滤波器系数的整数实际上使用尽可能少的位(例如,12位表示)。结果,然后可以使用定点算法执行3×3卷积,以更快地计算。
基于以下公式,每个3×3卷积产生一个卷积运算结果out(m,n):
其中:
m、n是对应的行数和列数,用于识别(z+2)像素乘(z+2)像素区域内的哪个图像数据(像素)在被执行卷积;
in(m,n,i,j)是在区域内以像素位置(m,n)为中心的3像素乘3像素区;
c(i,j)表示九个权重系数c(3×3)中的一个,每个权重系数对应于3像素乘3像素区中的一个;
b表示偏移或偏置系数;以及
i、j是权重系数c(i,j)的索引。
每个cnn处理块804同时产生z×z卷积运算结果,并且所有cnn处理引擎执行同时运算。在一种实施方式中,3×3权重或滤波器系数分别为12位,而偏移或偏置系数为16位或18位。
图10a至图10c示出了z×z像素位置的三个不同示例。图10a中所示的第一像素位置1031是(z+2)像素乘(z+2)像素区域内左上角3像素乘3像素区的中心。图10b所示的第二像素位置1032是第一像素位置1031向右侧移位一个像素数据。图10c所示出的第三像素位置1033是典型的示例像素位置。z×z像素位置包含(z+2)像素乘(z+2)像素区域内的多个重叠的3像素乘3像素区域。
为了在每个采样位置执行3×3卷积,图11中示出了示例数据布置。图像数据(即,in(3×3))和滤波器系数(即,权重系数c(3×3)和偏移系数b)被馈送到示例性cnn3×3电路1100中。在按照公式(1)进行3×3卷积运算之后,产生一个输出结果(即out(1×1))。在每个采样位置处,图像数据in(3×3)以像素坐标(m,n)1105为中心,具有八个直接相邻像素1101-1104、1106-1109。
图像数据存储在第一组存储缓冲器806中,而滤波器系数存储在第二组存储缓冲器808中。图像数据和滤波器系数两者在数字集成电路的每个时钟处被馈送到cnn块804。滤波器系数(即,c(3×3)和b)直接从第二组存储缓冲器808馈送入cnn处理块804。然而,图像数据经由多路复用器mux805从第一组存储缓冲器806馈送到cnn处理块804。多路复用器805基于时钟信号(例如,脉冲812)从第一组存储缓冲器选择图像数据。
否则,多路复用器mux805通过时钟偏移电路820从第一邻居cnn处理引擎(从图8的左侧,未示出)选择图像数据。
同时,经由时钟偏移电路820将馈送到cnn处理块804的图像数据的副本发送到第二邻居cnn处理引擎(图8的右侧,未示出)。时钟偏移电路820可以用已知技术(例如,d触发器822)实现。
在针对预定数量的滤波器系数执行针对每组图像数据的3×3卷积之后,基于另一时钟信号(例如,脉冲811)经由另一多路复用mux807将卷积运算结果out(m,n)发送到第一组存储缓冲器。绘制示例时钟周期810以用于展示脉冲811和脉冲812之间的时间关系。如所示,脉冲811是脉冲812之前的一个时钟,结果,在特别的图像数据块已经由所有cnn处理引擎通过时钟偏移电路820处理之后,3×3卷积运算结果被存储到第一组存储缓冲器中。
在根据公式(1)获得卷积运算结果out(m,n)之后,可以执行激活程序。小于零(即负值)的任何卷积运算结果out(m,n)被设置为零。换句话说,只保留输出结果中的正值。例如,正输出值10.5保持为10.5,而-2.3变为0。激活导致基于cnn的集成电路的非线性。
如果需要2×2池化操作,则z×z输出结果缩减到(z/2)×(z/2)。为了将(z/2)×(z/2)输出结果存储在第一组存储缓冲器中的对应位置,需要附加簿记(bookkeeping)技术来跟踪正确的存储器地址,使得四个(z/2)×(z)/2)输出结果可以在一个cnn处理引擎中处理。
为了展示2×2池化操作,图12a是以图形方式示出将2像素乘2像素块的第一示例输出结果被缩减到单个值10.5的框图,该单个值是四个输出结果中的最大值。图12a中所示的技术称为“最大池化”。当四个输出结果的平均值4.6用于图12b中所示的单个值时,将其称为“平均池化”。还有其他池化操作,例如,组合“最大池化”和“平均池化”的“混合最大平均池化”。池化操作的主要目标是缩减正在处理的图像数据的大小。图13是示出z×z像素位置通过2×2池化操作被缩减为最初大小的四分之一的(z/2)×(z/2)位置的框图。
输入图像通常包含大量图像数据。为了执行图像处理操作,示例输入图像1400(例如,图1的二维符号100)被分区为如图14a所示的z像素乘z像素块1411-1412。然后将与这些z像素乘z像素块中的每块相关联的图像数据馈送到相应的cnn处理引擎中。在特别的z像素乘z像素块的每个z×z像素位置处,在相应的cnn处理块中同时执行3×3卷积。
尽管本发明不需要输入图像的特定特征尺寸,但是输入图像可能需要调整大小以适合某一图像处理程序的预定义特征尺寸。在一实施方式中,需要具有(2l×z)像素乘(2l×z)像素的方形形状。l是正整数(例如,1、2、3、4等)。当z等于14且l等于4时,特征尺寸为224。在另一实施方式中,输入图像是尺寸为(2i×z)像素和(2j×z)像素的矩形形状,其中i和j是正整数。
为了在z像素乘z像素块的边界周围的像素位置处适当地执行3×3卷积,需要来自相邻块的附加图像数据。图14b示出了在(z+2)像素乘(z+2)像素区域1430内的典型z像素乘z像素块1420(用虚线界定)。(z+2)像素乘(z+2)像素区域由来自当前块的z像素乘z像素的中心部分和来自对应的相邻块的四个边缘(即,顶部、右侧、底部和左侧)和四个角(即,左上部、右上部、右下部以及左下部)形成。
图14c示出了两个示例z像素乘z像素块1422-1424和相应的相关联的(z+2)像素乘(z+2)像素区域1432-1434。这两个示例块1422-1424沿着输入图像的边界定位。第一示例z像素乘z像素块1422位于左上角,因此,第一示例性块1422的两个边缘和一个角有邻居。值“0”用于在相关联的(z+2)像素乘(z+2)像素区域1432中没有邻居的两个边缘和三个角(显示为阴影区域),以用于形成图像数据。类似地,第二示例块1424的相关联的(z+2)像素乘(z+2)像素区域1434需要将“0”用于顶部边缘和两个顶部角。沿着输入图像的边界的其他块被类似地处理。换句话说,为了在输入图像的每个像素处执行3×3卷积,在输入图像的边界之外添加一层零(“0”)。这可以通过许多众所周知的技术来实现。例如,第一组存储缓冲器的默认值设置为零。如果没有从相邻块充填图像数据,则那些边缘和角将包含零。
当在集成电路上配置不止一个cnn处理引擎时。cnn处理引擎经由时钟偏移电路连接到第一和第二邻居cnn处理引擎。为简化说明,仅示出了cnn处理块和用于图像数据的存储缓冲器。图15中示出了用于一组示例cnn处理引擎的示例时钟偏移电路1540。
经由第二示例时钟偏移电路1540连接的cnn处理引擎形成环路。换句话说,每个cnn处理引擎将其自己的图像数据发送到第一邻居,并且同时接收第二邻居的图像数据。时钟偏移电路1540可以用众所周知的方式实现。例如,每个cnn处理引擎与d触发器1542连接。
现在参照图16,图16是示出使用基于细胞神经网络或基于细胞非线性网络(cnn)的集成电路的自然语言处理的示例过程1600的流程图。
过程1600在动作1602处开始——在计算系统(例如,具有多个处理单元的计算机)中接收书面自然语言文本串。在动作1604处,根据一组2-d符号创建规则从接收的串形成多层二维(2-d)符号。2-d符号包含“超级字符”,该“超级字符”表示由2-d符号中包含的多个表意符号的特定组合形成的含义。
图1和图2a至图2b中描述并示出了示例多层2-d符号100的细节。为了容纳基于cnn的集成电路(例如,图4a至图4b中所示的示例基于cnn的集成电路400),n×n像素中的每个都包含k位数据,其中k是正整数或正的整数。在一种实施方案中,k为5。
图18是示出用于将图像数据(例如,2-d符号)从每像素8位[0-255]转换为5位[0-31]的示例数据转换方案的框图。例如,位0-7变为0,位8-15变为1等。
接下来,在动作1606处,在基于cnn的集成电路中通过经由具有双值3×3滤波器内核的经训练的卷积神经网络模型对2-d符号进行分类来学习“超级字符”的含义。
使用图17中所示的一组示例操作1700来实现经训练的卷积神经网络模型。在动作1702处,首先通过基于包含足够大量的多层2-d符号的标记数据集的图像分类对卷积神经网络模型进行训练来获得卷积神经网络模型。例如,每个类别有至少4,000个2-d符号。换句话说,标记数据集中的每个2-d符号与要分类的类别相关联。卷积神经网络模型包括多个有序滤波器组(例如,每个滤波器组对应于卷积神经网络模型中的卷积层)。多个有序滤波器组中的每个滤波器都包含标准3×3滤波器内核(即,浮点数格式的九个系数(例如,图18中的标准3×3滤波器内核1810))。九个系数中的每个可以是任何负实数或正实数(即,具有分数的数字)。最初的卷积神经网络模型可以从许多不同的框架中获得,包括但不限于mxnet、caffe、tensorflow等。
然后,在动作1704处,通过基于一组内核转换方案将多个有序滤波器组中的当前被处理的滤波器组的相应的标准3×3滤波器内核1810转换为对应双值3×3滤波器内核1820来修改卷积神经网络模型。在一种实施方式中,对应的双值3×3滤波器内核1820中的九个系数c(i,j)中的每个都被赋于值‘a’,该值等于标准3×3滤波器内核1810中绝对系数值的平均值乘以对应系数的标号(sign,符号、正负号),如下式所示:
以多个有序滤波器组中定义的顺序一次一个地转换滤波器组。在某些情况下,可选地组合两个连续的滤波器组,使得卷积神经网络模型的训练更有效。
接下来,在动作1706处,再训练修改的卷积神经网络模型,直到达到或实现期望的收敛标准。存在许多众所周知的收敛标准,包括但不限于完成预定数量的再训练操作,由于滤波器内核转换而引起的精度损失的收敛等。在一种实施方式中,所有滤波器组,包括在先前的再训练操作中已经转换的,可以被更改或改变以进行微调。在另一实施方式中,在当前被处理的滤波器组的再训练操作期间,已经转换的滤波器组被冻结或未改变。
过程1700移至判定1708,确定是否存在另一未转换的滤波器组。如果“是”,则过程1700返回以重复动作1704-1706,直到已经转换了所有滤波器组。此后判定1708变为“否”。在动作1710,所有滤波器组中的双值3×3滤波器内核的系数从浮点数格式转变为定点数格式,以适应基于cnn的集成电路中所需的数据结构。此外,在基于cnn的集成电路中,定点数被实现为可重配置的电路。在一种实施方式中,使用12位定点数格式来实现系数。
尽管已经参照本发明的特定实施方式描述了本发明,但是这些实施方式仅仅是说明性的,而不是限制本发明。本领域技术人员将被暗示具体公开的示例实施例的各种修改或改变。例如,虽然已经用224×224像素矩阵的具体示例描述和示出二维符号,但是可以使用其他大小来实现本发明的基本相似的目的。另外,虽然已经描述和示出两个示例分区方案,但是可以使用划分二维符号的其他合适的分区方案来实现本发明的基本相似的目的。此外,已经示出和描述了少数示例表意符号,其他表意符号可以用于实现本发明的基本相似的目的。此外,虽然中文、日文和韩文的意音字符已被描述并示出作为表意符号,但其他的意音字符可以表示例如埃及象形文字、楔形文字等。最后,虽然已经示出和描述一种类型的双值3×3滤波器内核,但是可以使用其他类型来实现本发明的基本相似的目的。总之,本发明的范围不应受限于本文公开的具体示例实施方式,并且本领域普通技术人员容易被暗示的所有修改都应包括在该申请的精神和权限以及所附权利要求的范围内。
- 还没有人留言评论。精彩留言会获得点赞!