一种基于稠密网格重组和K2-tree的图数据表示方法与流程
本发明涉及图数据处理技术领域,具体涉及一种基于稠密网格重组和k2-tree的图数据表示方法。
背景技术
万维网是一种能有效描述二元关系的数据结构,可以用有向图表示。通常,在万维网中,每个网页对应于图形节点,并且每个链接对应于图形边缘。这种有向图称为网页图(web图)。通过对网页图的操作,可以确定两个页面之间的连通性,筛选出链接到某个页面的所有网页,并找出哪些页面指向指定的网页等。随着互联网的急速发展以及万维网规模的迅速增长,网页图正以前所未有的方式和速度产生并积累着大量数据,如何对这些数据进行分析并使用,已经成为许多领域面临的关键机遇和严峻挑战。
根据中国互联网络信息中心(cnnic)发布的《第37次中国互联网络发展状况统计报告》,中国网页数量2015年就达到了2123亿个,网页图上的链接数量超过1018个;如果使用邻接矩阵来存储网页图,则需要将近40tb的存储空间。网页图规模的爆炸式增长使得传统的存储结构无法满足存储和计算的需求。在使用邻接矩阵或者邻接表等传统存储结构进行表示和存储时,网页图往往无法完全放入计算机主存进行计算,在很大程度上制约了对网页图进行分析和计算的效率。
k2-tree是一种紧凑的数据结构,用于表示利用网络图的邻接矩阵的大空区域的二元关系。在k2-tree中,主要思想是用k2-叉树表示网络图的邻接矩阵。更确切地说,在k2-tree构造的阶段中,邻接矩阵被分成k2个相等的矩阵。对应于每个矩阵,该方法将为根节点生成子节点。如果矩阵的元素都是0,则k2-tree的对应子节点为0;如果矩阵包含至少一个1,则子节点为1。对于那些包含1的矩阵,该方法将它们递归地划分为k2个相等的部分,直到矩阵的大小为1×1。在此分割过程中,所有子节点都从上到下,从左到右排序。k2-tree是通过两个位向量t和l进行存储的,位向量t存储树中除最底层外所有的节点,存储的顺序是由上到下,从左至右,位向量l存储树中最底层的叶子节点。通过对k2-tree进行自顶向下的遍历不仅可以有效的实现前向和反向的导航,还支持检测单一链接是否存在和范围查询操作。
虽然k2-tree是一种优秀的数据结构,可以紧凑地表示图数据,但它仍然存在一些缺陷:节点之间的紧密耦合可能会被破坏,这将增加图形上操作的时间消耗;矩阵中填充0的大区域可能被划分为不同的矩阵,因此无法完全压缩;k2-tree的高度将严重影响图上操作的时间消耗。由此可见,k2-tree对图数据内在结构特性以及表示大规模图数据时的查询效率方面缺乏必要的考虑,其在紧凑性以及查询效率上仍有较大的改善空间。
技术实现要素:
本发明针对k2-tree对图数据内在结构特性以及表示大规模图数据时的查询效率方面缺乏必要的考虑,其在紧凑性以及查询效率上仍有较大的改善空间的问题,提供一种基于稠密网格重组和k2-tree的图数据表示方法。
为解决上述问题,本发明是通过以下技术方案实现的:
一种基于稠密网格重组和k2-tree的图数据表示方法,具体包括步骤如下:
步骤1,将图数据抽象表示为邻接矩阵,并使用网格聚类算法,采用一大一小两个不同的网格参数对邻接矩阵进行划分;
步骤2,将大网格内包含的所有小网格提取出来并存储为新的重组矩阵;
步骤3,将步骤2中的所有重组矩阵采用k2-tree表示;
步骤4,将需要查询的节点分别在步骤3中建立的多个k2-tree中进行查询,并将查询结果合并得到最终结果;
上述k为设定的正整数。
上述步骤1的具体过程如下:
步骤1.1、将图数据抽象表示为邻接矩阵;
步骤1.2、设定k2-tree和小网格的参数k以及大网格参数size;
步骤1.3、根据设置的小网格参数k,将邻接矩阵划分为多个大小为k×k的矩阵,再将划分后得到的矩阵中包含至少一个1的矩阵提取出来,存储在小网格矩阵集合set1中;
步骤1.4、根据设置的大网格参数size,将邻接矩阵划分为多个大小为size×size的矩阵,再将划分后得到的矩阵中包含至少一个1的矩阵提取出来,存储在大网格矩阵集合set2中。
上述步骤2的具体过程如下:
步骤2.1、选取大网格矩阵集合set2中的任意一个矩阵,将它所包含的小网格矩阵集合set1中的矩阵按顺序提取出来,存储在临时矩阵集合set3中;
步骤2.2、将临时矩阵集合set3中的矩阵按照由左向右、由上向下的顺序依次排列成多行矩阵队列,每一行包含x个矩阵,无数值区域用0填充,重组成一个行数和列数均为k×x的重组矩阵;其中
步骤2.3、将重组矩阵存储到重组矩阵集合set4中,并清空临时矩阵集合set3;
步骤2.4、重复步骤2.1-2.3,直到大网格矩阵集合set2中所有矩阵都完成重组,并存储到重组矩阵集合set4中。
上述步骤3的具体过程如下:
步骤3.1、选取重组矩阵集合set4中的任意一个重组矩阵,当重组矩阵的结点数不为k的幂次方时,先在该重组矩阵的右侧和下侧填充0,将重组矩阵的规模扩充为k的幂次方,再将重组矩阵划分为k2个规模相等,且行数与列数相等的初级划分矩阵;
步骤3.2、对于每个重组矩阵所对应的k2-tree,将划分前的矩阵即重组矩阵作为根节点,k2个划分后的矩阵作为根节点的子节点;如果划分后的某一个矩阵的元素都是0,则k2-tree的对应子节点为0;如果划分后的某一个矩阵包含至少一个1,则k2-tree的对应子节点为1;在此划分过程中,所有k2-tree的子节点都从上到下,从左到右排序;
步骤3.3、将上次划分所得到的矩阵继续划分为k2个规模相等,且行数与列数相等的矩阵;
步骤3.4、将步骤3.3中划分后的矩阵作为划分前的矩阵的子节点;如果划分后的某一个矩阵的元素都是0,则k2-tree的对应子节点为0;如果划分后的某一个矩阵包含至少一个1,则k2-tree的对应子节点为1;在此划分过程中,所有k2-tree的子节点都从上到下,从左到右排序;
步骤3.5、重复步骤3.3-3.4,对上次划分所得到的矩阵进行递归划分,直到划分后的矩阵的大小为1×1;
步骤3.6、当重组矩阵集合set4中所有的重组矩阵都表示为k2-tree后,对于每个k2-tree,分别使用位向量t按照从上到下、从左到右的顺序存储k2-tree中除最底层的所有节点的值,使用位向量l存储k2-tree的最底层叶子节点的值,得到多组包含了位向量t和l的向量组。
上述步骤4的具体过程如下:
步骤4.1、给定一个结点q,筛选出重组矩阵集合set4中包含此结点的重组矩阵,并存储到查询矩阵集合set5中;
步骤4.2、选取查询矩阵集合set5中的任意一个查询矩阵,找出查询矩阵中所有包含结点q,且包含于小网格矩阵集合set1中的矩阵,并根据这些矩阵在重组矩阵位置信息计算出结点q在查询矩阵中的新行号q’、需要查询的k个列号和列偏移量t;
步骤4.3、对于步骤4.2中算出的其中一个新行号q’,按照k2-tree的遍历规则进行自顶向下的遍历,查询该新行号q’对应的需要查询的k个列号位置处的值:
若该列号处的值为1,且此列号为偶数,则将该新行号对应的列偏移量t赋值给真正的邻居结点列号p,并将邻居结点列号p存储到邻居集合set6中;
若该列号处的值为1,且此列号为奇数,则将该新行号对应的列偏移量t加1后赋值给真正的邻居结点列号p,并将邻居结点列号p存储到邻居集合set6中;
若该列号处的值为0,则不做处理;
步骤4.4、重复步骤4.3,直到查询出结点q在查询矩阵内的所有邻居结点;
步骤4.5、重复步骤4.2-4.4,直到查询出结点q的所有邻居结点,此时邻居集合set6中存储的即为结点q的所有邻居结点。
与现有技术相比,本发明先将图数据抽象成邻接矩阵表示形式,再在邻接矩阵的基础上进行网格划分和重组,从而大大增加矩阵中1值的密度,提高了存储效率。相比于原始邻接矩阵,每个簇所对应的矩阵的规模将大大减小,缩减k2-tree中进行自顶向下的遍历到叶子层所需要的时间,有利于提高查询的效率。
附图说明
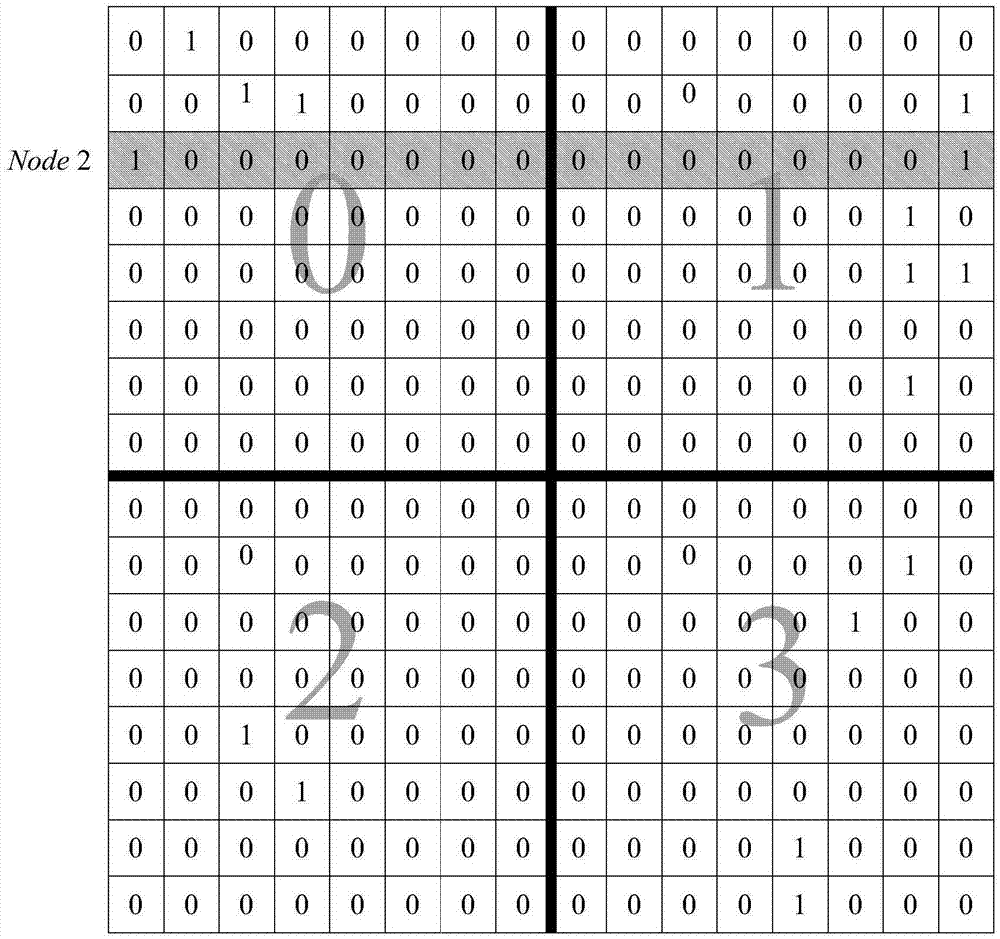
图1是将含有16个结点的图的邻接矩阵划分后得到的邻接矩阵表示。
图2是邻接矩阵的k2-tree表示。
图3是将邻接矩阵划分重组后得到的重组矩阵及对应的k2-tree表示;(a-1)和(a-2)分别为0号重组矩阵及其k2-tree;(b-1)和(b-2)分别为1号重组矩阵及其k2-tree;(c-1)和(c-2)分别为2号重组矩阵及其k2-tree;(d-1)和(d-2)分别为3号重组矩阵及其k2-tree。
图4是查询给定结点2的邻居结点时需要访问的重组矩阵和对应k2-tree表示;(a-1)和(a-2)分别为0号重组矩阵及其k2-tree,其中(a-1)中的两个灰色元素为查询时邻接矩阵中需要访问的结点,(a-2)中的虚线及相应结点为查询时k2-tree中需要访问的结点及步骤;(b-1)和(b-2)分别为1号重组矩阵及其k2-tree,其中(b-1)中的两个灰色元素为查询时邻接矩阵中需要访问的结点,(b-2)中的虚线及相应结点为查询时k2-tree中需要访问的结点及步骤。
具体实施方式
为了进一步挖掘和利用图数据本身所固有的结构特性,以及进一步提高k2-tree表示大规模图数据时的查询效率,本发明提出了一种基于稠密网格重组和k2-tree的图数据表示方法,其基于图的邻接矩阵表示形式上对图数据进行高效、紧凑的表示和压缩,并且提供针对图数据中节点的直接邻居查询操作。该方法具体包括步骤如下:
步骤1,使用网格聚类算法,采用一大一小两个不同的参数对邻接矩阵进行划分,每次划分形成一种相同规模的网格;
步骤1.1、首先将图数据抽象表示为邻接矩阵,
步骤1.2、设置小网格参数为k,将邻接矩阵划分为多个k×k的矩阵,然后对包含至少一个1的矩阵进行标记,标记的方式为将这些矩阵在原始矩阵中的位置作为编码,即,某一矩阵按照由上向下的顺序为第m个矩阵,按照由左向右的顺序为第n个矩阵,则这个矩阵的编码为(m,n),之后将这些编码存储到名为set1的集合中。
步骤1.3、设置大网格参数为size,将邻接矩阵划分为多个size×size的矩阵,然后对包含至少一个1的矩阵进行标记,标记的方式为将这些矩阵在原始矩阵中的位置作为编码,即,某一矩阵按照由上向下的顺序为第m个矩阵,按照由左向右的顺序为第n个矩阵,则这个矩阵的编码为(m,n),之后将这些编码存储到名为set2的集合中。
步骤2,将大网格内包含的所有小网格提取出来并存储为新的重组矩阵;
步骤2.1、选取set2中的任意一个矩阵r,将它包含的set1中的矩阵按顺序提取出来,存储在名为set3的集合中。
步骤2.2、set3中的矩阵个数为a,取
步骤2.3、将rs存储到名为set4的集合中并清空set3。
步骤2.4、重复步骤2.1、2.2和2.3,直到set2中所有矩阵都重组为新矩阵。
步骤3,将步骤2中的所有重组矩阵采用k2-tree表示;
步骤3.1、设定k2-tree的参数k;
步骤3.2、选取set4中的任意一个矩阵rs,当rs的结点数不为k的幂次方时,在矩阵的右侧和下侧填充0,将rs的规模扩充为k的幂次方阶。然后将rs划分为规模相等且行数与列数相等的k2个矩阵。
步骤3.3、对于每个矩阵对应的k2-tree,划分前的矩阵作为根节点,划分后的k2个矩阵作为根节点的子节点,为根节点生成子节点。如果矩阵的元素都是0,则k2-tree的对应子节点为0;如果矩阵包含至少一个1,则子节点为1。
步骤3.4、对于包含1的矩阵,继续将它们递归地划分为k2个规模相等且行数与列数相等的矩阵,直到矩阵的大小为1×1。在此划分过程中,所有子节点都从上到下,从左到右排序。
步骤3.5、重复步骤3.2、3.3和3.4,直到set4中所有矩阵都表示为k2-tree。
步骤3.6、对于上述步骤构造的k2-tree,使用位向量t按照从上到下、从左到右的顺序存储k2-tree中除最底层的所有节点的值,使用位向量l存储k2-tree的最底层叶子节点的值。
步骤4,将需要查询的节点分别在步骤3中建立的多个k2-tree中进行查询,并将查询结果合并得到最终结果。
步骤4.1、给定一个结点q,筛选出set4中包含此结点的矩阵,并存储到set5中。
步骤4.2、选取set4中的任意一个矩阵rq,找出rq中包含结点q的且包含于set1中的矩阵,根据这些矩阵的位置信息计算出结点q在rq中的新的行号q’、需要查询的列号p1、p2以及列偏移量t。
步骤4.3、对于步骤4.2中算出的其中一个新行号q’,按照k2-tree的遍历规则进行自顶向下的遍历,查询该新行号对应的需要查询的列号p1、p2位置处的值。若该列号处的值为1且此列号为偶数,则将列偏移量t赋值给真正的邻居结点列号p,并将p存储到set5中;若该列号处的值为1且此列号为奇数,则将列偏移量t加1后赋值给真正的邻居结点列号p,并将p存储到set5中。
步骤4.4、重复步骤4.3,直到查询出结点q在矩阵rq内的所有邻居结点。
步骤4.5、重复步骤4.2、4.3和4.4,直到查询出结点q的所有邻居结点。set5中存储的即为结点q的所有邻居结点。
下面结合图1-4和一个具体实例对本发明进行进一步详细说明:
1、邻接矩阵的划分和重组
使用小网格参数2将邻接矩阵划分为64个2×2的矩阵,然后对包含至少一个1的矩阵进行标记,标记的方式为将这些矩阵在原始矩阵中的位置作为编码,之后将这些编码存储到名为set1的集合中,set1={(1,1),(1,2),(1,8),(2,1),(2,8),(3,8),(4,8),(5,8),(6,7),(7,2),(8,7)}。
设置大网格参数为8,将邻接矩阵划分为4个8×8的矩阵,然后对包含至少一个1的矩阵进行标记,标记的方式为将这些矩阵在原始矩阵中的位置作为编码,之后将这些编码存储到名为set2的集合中,set2={(1,1),(1,2),(2,1),(2,2)}。
将这四个大矩阵中包含的小矩阵提取出来,存储到set3中,这四个矩阵对应的set3分别为set30={(1,1),(1,2),(2,1)},set31={(1,8),(2,8),(3,8),(4,8)},set32={(7,2)},set33={(5,8),(6,7),(8,7)}。然后分别将set3中的矩阵进行重组得到新的矩阵。set30中的矩阵的个数是3,则对应的重组矩阵中,每一行应该有
2、重组矩阵的k2-tree表示
将上述步骤中获取到的重组矩阵表示为k2-tree,如图2所示,得到相应的位向量t和l。以0号重组矩阵为例,首先设定k值为2,并将其划分为4个规模相等的矩阵。若矩阵中的元素包含1,则对应的k2-tree的结点处的值为1;若矩阵中的元素全为0,则对应的k2-tree的结点处的值为0。得到对应的k2-tree后,k2-tree的除最后一层外所有结点按照由上到下、由左到右的顺序存储到位向量t中,最后一层的叶子结点存储到位向量l中。按此方法将四个重组矩阵表示为k2-tree并得到相应的位向量组。图3是将邻接矩阵划分重组后得到的重组矩阵及对应的k2-tree表示。
3、查询给定结点的邻居结点
指定结点2为需要查询的结点。首先筛选出set4中包含结点2的重组矩阵。在本例中0和1号重组矩阵包含此结点。对于0号重组矩阵,计算出结点2在此矩阵中对应的新的行号q’=2、需要查询的列号p1=0、p2=1以及列偏移量t=0。然后访问对应的k2-tree中相应位置的值。q’的p1邻居处的值为1,p2邻居处的值为0,因此列偏移量即为真实的邻居结点号0。
对于1号重组矩阵,计算出结点2在此矩阵中对应的新的行号q’=0、需要查询的列号p1=2、p2=3以及列偏移量t=14。然后访问对应的k2-tree中相应位置的值。q’的p1邻居处的值为0,p2邻居处的值为1,因此偏移量加1后,得到真实的邻居结点号15。最终得到了结点2的所有邻居结点{0,15}。图4是查询给定结点2的邻居结点时需要访问的重组矩阵和对应k2-tree中的元素。图4是查询给定结点2的邻居结点时需要访问的重组矩阵和对应k2-tree表示。
需要说明的是,尽管以上本发明所述的实施例是说明性的,但这并非是对本发明的限制,因此本发明并不局限于上述具体实施方式中。在不脱离本发明原理的情况下,凡是本领域技术人员在本发明的启示下获得的其它实施方式,均视为在本发明的保护之内。
- 还没有人留言评论。精彩留言会获得点赞!