一种基于神经网络和Huff模型的数字标牌广告受众人群分类方法与流程
本发明属于数字标牌受众人群分类
技术领域:
,涉及数字标牌受众人群分类方法,具体涉及一种基于神经网络和huff模型的数字标牌受众人群分类方法。
背景技术:
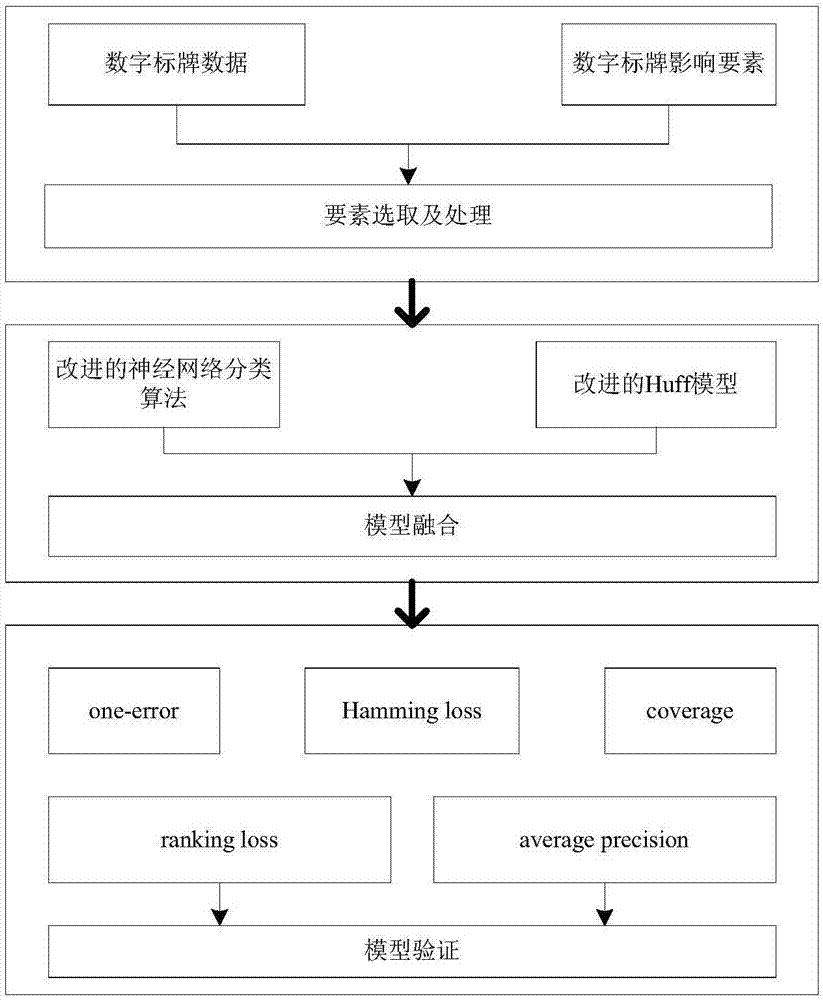
:数字标牌是指在人流会聚的公共场所,通过数字标牌终端显示设备,发布商业、财经和娱乐等信息的多媒体专业视听系统,作为一种新兴的媒体,已成为现代城市实体广告的重要媒介。与传统的电视广告、报纸广告相比,数字标牌更具有灵活性,可以根据不同受众群体,进行个性化、定制化广告投放。数字标牌发展至今仅有20多年的历史,其应用却遍及工作和生活的各个领域,数字标牌的广泛应用给社会带来了不可估量的产业价值。数字标牌的产业链可以包含如下过程:(1)数字标牌供应商负责生产制造数字标牌;(2)数字标牌媒体商购买数字标牌并选择位置与布设;(3)广告代理商按照广告商需求向媒体商购买数字标牌的广告位。近年来国内数字标牌产业发展迅速。数字标牌兴起阶段,这一阶段主要集中在数字标牌生产、研发与制造工作;数字标牌的应用阶段,这一阶段主要是数字标牌的大范围应用,通过不断的推广宣传在机场、酒店、商场等地点开始布设并应用数字标牌,数字标牌的布设数量迅速增加;数字标牌科学化管理阶段,随着数字标牌广泛使用,由于所布设的数字标牌数量急剧增加,数字标牌相关者开始考虑对数字标牌进行科学化、规范化管理工作。在受不同的人口、经济等要素影响的区域中,数字标牌广告的受众人群会存在差异。而目前企业对数字标牌的广告投放是针对所有受众人群进行的,缺乏针对性,使得广告投放效益低,数字标牌影响效果不明显。因此亟需对数字标牌广告受众人群引入精确分类方法进行有针对性的数字标牌广告投放。数字标牌的广告受众人群分类是从机器学习的角度对数字标牌广告受众人群进行分类,包括但不限于利用已布设数字标牌位置的受众人群来预测未布设数字标牌位置的受众人群类型。在一般的分类问题中,每个示例仅仅对应于唯一一个类别标记,然而同一数字标牌上的广告会同时吸引不同的受众人群,即一个数字标牌示例可能并不仅仅由单个广告受众人群标签描述,而是同时拥有多个广告受众人群标签,这种一个数字标牌示例拥有多个广告受众人群标签的分类问题称为多标签分类问题。目前,许多学者致力于研究多标签分类问题,依据不同的解决途径,主要分为问题转换和算法适应两种。spyromitrose等提出了br算法,该算法将多标签分类问题转化为一系列独立的两类问题;zhangml等将knn方法应用于多标签分类,提出了ml-knn算法。但是这些算法的算法复杂度较高、运行时间长,难以解决实际问题,同时,数字标牌广告受众人群是一种空间数据,空间距离对其分类有一定的影响,因此将空间距离引入数字标牌广告受众人群分类能够有效的提高分类准确性。技术实现要素:为了克服上述现有技术的不足,并将空间距离和经济、人口等多源要素融入数字标牌广告受众人群分类,本发明提供一种高效科学的基于神经网络和huff模型的数字标牌广告受众人群分类方法,通过要素处理、模型构建、模型验证,自动地完成对数字标牌广告受众人群的分类,从而实现数字标牌广告的针对性投放。本发明方法综合考虑多源要素与空间距离,分类结果精准性高、数字标牌广告投放效益高、数字标牌影响效果佳。本发明提供的技术方案是:一种基于神经网络和huff模型的数字标牌广告受众人群分类方法,包括以下步骤:(1)要素选取及处理:构造空间化的数字标牌区位因子,得到数字标牌区位因子的标准格网栅格图层,包括其像素值及对应的坐标值;(2)模型构建:采用改进的神经网络模型对经过归一化处理的数字标牌区位因子进行计算,得到每个区位包含各种受众人群的概率;再利用改进的huff模型计算已布设数字标牌区位对未布设数字标牌区位的受众人群影响力;最后将两种模型,即所述改进的神经网络模型和改进的huff模型得到的结果进行融合,完成数字标牌广告受众人群分类。所述步骤(1)具体实现如下:(11)在构造数字标牌区位因子过程中,选取城市常住人口数目、城市交通网络中心性指数、城市建筑物平均房价以及社交网络公众签到(check-in)数量,作为数字标牌区位因子;(12)对数字标牌区位因子进行空间化处理,将选取的数字标牌区位因子经过预处理,删除部分异常数据;然后,经过地理编码匹配、投影转换和数据纠偏,即得到数字标牌区位因子空间数据,通过空间连接操作,将数字标牌区位因子空间数据按照面积权重赋值到设定距离(500米)规则格网中,并且将矢量数据转换成栅格数据,由此得到500m数字标牌区位因子规则格网栅格数据;(13)对数字标牌区位因子进行归一化处理,采用最小最大值标准化方法进行归一化处理,对原始数据进行线性变换,构建模型如下:式1中,max为样本最大值,min为样本最小值;×为原始样本点数据;×*为经过归一化后的样本点数据。所述步骤(2)中,利用改进的神经网络模型具体结构如下:改进的神经网络由输入层、隐藏层、原始输出层、sigmoid层以及最终输出层组成,将f1和f2作为隐层和原始输出层的激活函数,则其中隐藏层的输出为:其中,xi(i=1,2…d)表示输入单元,d表示输入单元个数,hk表示隐层单元,q表示隐层单元个数,wik表示从输入单元i到隐层单元k的连接权,k=1,2…q,原始输出层的输出为:其中,vkj表示从隐层单元k到原始输出单元j的连接权,yj表示原始输出单元,j表示原始输出单元个数;最终输出层的输出为:其中,oj表示最终输出单元;得到最终的输出值后,计算实际输出与期望输出的误差,并利用误差向后传播来修正权重,从而实现实际输出与期望输出误差最小化,最终得到各个区位中每个广告受众人群标签的概率。所述步骤(2)中,利用改进的huff模型具体结构如下:在改进的huff模型中将每种广告受众人群的数量作为模型的影响因素,同时充分考虑一个区位里可能存在多种广告受众人群的情况,未布设数字标牌区位x受周围已布设数字标牌区位受众人群ty_j的影响力fxty_j通过以下计算得到:其中,z表示区位x周围已布设数字标牌的区位,z表示已布设数字标牌的区位个数,d表示距离,h表示区位x周围有类型ty_j的区位,h表示区位x周围有类型ty_j的区位个数,num表示区位x周围已布设数字标牌区位中含有类型ty_j的数量,β表示平滑系数;为了体现不同邻域内的区位对当前区位的受众人群影响力的差异性,将对上述改进的huff模型中的距离进行约束,增加如下的限制条件:dxz<=epsz=1…z(式6)其中,dxz表示区位x和已布设数字标牌的区位z之间的距离,eps表示以区位x为中心的半径。所述步骤(2)中,将两种模型得到的结果按照一定的规则进行融合,从而得到每个区位中包含每种数字标牌广告受众人群的可能性大小,将改进的神经网络分类算法得到的每个区位包含各种受众人群的概率pnn与改进的huff模型计算得到的已布设数字标牌区位对未布设数字标牌区位的受众人群影响力归一化值fhuff通过以下公式进行融合,从而得到每个区位中包含每种数字标牌广告受众人群的可能性大小p:p=αpnn+(1-α)fhuff其中,α取值在0-1之间,表示pnn和fhuff在融合规则中所占的权重比,α越大表示pnn占的比重越大。与现有技术相比,本发明的有益效果是:本发明提供了一种高效科学的基于神经网络和huff模型的数字标牌广告受众人群分类方法,通过要素处理、模型构建、模型验证,自动地完成对数字标牌广告受众人群的分类,从而实现数字标牌广告的针对性投放。本发明方法综合考虑多源要素与空间距离,分类结果精准性高、数字标牌广告投放效益高、数字标牌影响效果佳。能够满足众多广告主和媒体商的利益需求,可推广到具有数字标牌广告受众人群分类需求的多种应用领域。附图说明图1是本发明提供的数字标牌广告受众人群分类方法的流程框图;图2是数字标牌区位因子空间化处理流程框图;图3是本发明实施例中数字标牌广告受众人群示意图;图4是本发明实施例中神经网络结构图;图5是本发明实施例中改进的神经网络结构图;图6是本发明实施例中区位受周围广告受众人群的影响力示意图;图7是本发明实施例中不同eps和α下的hamming-loss对比结果图;图8是本发明实施例中不同eps和α下的one-error对比结果图;图9是本发明实施例中不同eps和α下的ranking-loss对比结果图;图10是本发明实施例中不同eps和α下的coverage对比结果图;图11是本发明实施例中不同eps和α下的averageprecision对比结果图;图12是本发明实施例中不同算法的hamming-loss对比结果图;图13是本发明实施例中不同算法的one-error对比结果图;图14是本发明实施例中不同算法的ranking-loss对比结果图;图15是本发明实施例中不同算法的coverage对比结果图;图16是本发明实施例中不同算法的averageprecision对比结果图;图17是本发明实施例中受众人群为生产/营运/采购/物流的结果图;图18是本发明实施例中受众人群为公务员/翻译/其它的结果图;图19是本发明实施例中受众人群为服务业的结果图;图20是本发明实施例中受众人群为会计/金融/银行/保险的结果图;图21是本发明实施例中受众人群为贸易/百货的结果图;图22是本发明实施例中受众人群为销售/客服/技术支持的结果图;图23是本发明实施例中受众人群为广告/市场/媒体/艺术的结果图;图24是本发明实施例中受众人群为建筑/房地产的结果图;图25是本发明实施例中受众人群为咨询/法律/教育/科研的结果图;图26是本发明实施例中受众人群为计算机/互联网/通信/电子的结果图;图27是本发明实施例中受众人群为人事/行政/高级管理的结果图;图28是本发明实施例中受众人群为生物/制药/医疗/护理的结果图。具体实施方式下面结合附图,通过实施例进一步描述本发明,但不以任何方式限制本发明的范围。如图1所示,本发明的一种基于神经网络和huff模型的数字标牌广告受众人群分类方法,包括:要素处理、模型构建、模型验证三个步骤;具体过程包括:1)要素选取及处理:构造空间化的数字标牌区位因子(包括但不限于人口、交通要素、房价、社交网络签到、经济普查要素),得到数字标牌区位因子的标准格网栅格图层,包括其像素值及对应的坐标值;在构造数字标牌区位因子过程中,考虑到资料获取的难易程度以及影响因素难以量化等原因,本发明主要按照基础性、前瞻性、易获取、可定量、区域全覆盖等原则,筛选对城市数字标牌布设产生直接影响、而相互之间独立性和可操作性均较强的要素。故而选取了城市常住人口数目、城市交通网络中心性指数、城市建筑物平均房价以及社交网络公众签到(check-in)数量,作为本发明方法中的数字标牌区位因子。11)对数字标牌区位因子进行空间化处理:将选取的数字标牌区位因子经过预处理,删除部分异常数据。然后,经过地理编码匹配、投影转换和数据纠偏,即得到数字标牌区位因子空间数据。通过空间连接操作,将数字标牌区位因子空间数据按照面积权重赋值到500米规则格网中,并且将矢量数据转换成栅格数据,由此得到500m数字标牌区位因子规则格网栅格数据。12)对数字标牌区位因子进行归一化处理:由于各数字标牌区位因子有着不同的量纲和数量级,若直接对原始数据进行处理,可能会忽略数量级较小的指标,使得分类结果不够准确。为了使不同的量纲之间也能进行比较,必须先对原始的样本点资料数据矩阵利用无量纲化处理的方法做适当的变换,对筛选得到的要素进行标准化预处理,使得这些要素属性统一在[0,1]区间上。此技术方法中采用最小最大值标准化方法进行归一化处理。通过最小-最大规范化对原始数据进行线性变换,构建模型如下:式1中,max为样本最大值,min为样本最小值;×为原始样本点数据;×*为将经过归一化后的样本点数据。2)模型构建:利用改进的神经网络对经过归一化处理的数字标牌区位因子进行计算,得到每个区位包含各种受众人群的概率;利用改进的huff模型计算已布设数字标牌区位对未布设数字标牌区位的受众人群影响力;最后将这两种模型得到的数字标牌广告受众人群的结果进行融合,完成数字标牌广告受众人群分类。21)利用改进的神经网络计算每个区位包含各种受众人群的概率;神经网络是一种模仿动物神经网络行为特征,进行分布式并行信息处理的数学模型,由于该算法具有较强的非线性映射能力、自学习和自适应能力以及较好的泛化能力和容错能力而得到了广泛的应用,但是传统的神经网络在作为分类器时只能解决多类分类问题,而对于本发明中的多标签分类还尚待研究。因此,本发明将对传统的神经网络进行改进,使其能够解决本发明中的受众人群多标签分类问题。22)利用改进的huff模型计算已布设数字标牌区位对未布设数字标牌区位的受众人群影响力;由于本发明中的数据具有空间特性,而具有空间特性的数据通常会受到空间距离的影响,因此本发明将利用经典的huff模型来计算空间引力,但是传统的huff模型不能解决本发明中的具有多标签特性的受众人群的影响力问题,因此本发明将对huff模型进行改进,从而将其用于计算已布设数字标牌区位对未布设数字标牌区位的受众人群影响力。23)将两种模型得到的结果按照一定的规则进行融合,从而得到每个区位中包含每种数字标牌广告受众人群的可能性大小。将改进的神经网络分类算法得到的每个区位包含各种受众人群的概率与改进的huff模型计算得到的已布设数字标牌区位对未布设数字标牌区位的受众人群影响力归一化值按照一定的规则进行融合,从而得到每个未布设数字标牌区位中包含每种受众人群的可能性大小。3)模型有效性验证;本发明具体实施时,利用hammingloss(汉明损失)、one-error(错误率)、coverage(覆盖率)、rankingloss(排序损失)和averageprecision(平均精度)多标签分类算法评价指标对数字标牌广告受众人群分类模型进行有效性验证。如附图1所示,下面以某市城区环路内为例,对本发明的具体实施方式进一步说明:a.数字标牌区位因子选取并空间化处理考虑到资料获取的难易程度以及影响因素难以量化等原因,本发明主要按照基础性、前瞻性、易获取、可定量、区域全覆盖等原则,筛选对数字标牌产生直接影响、而相互之间独立性和可操作性均较强的影响要素作为本发明的区位因子,然后对因子进行格网化和归一化处理。收集了某市城区环路以内5823块户外数字标牌基础数据以及数字标牌影响要素数据。其中,数字标牌基础数据包括数字标牌地理位置以及数字标牌每15s的平均播放价格;数字标牌影响要素数据主要包括从统计口径获得的该市城区六环路内第三次经济普查中的商业网点期末人口数量和人口普查中的常住人口数量、房天下平均房价数据和新浪微博的社交网络签到数据,以及根据基础道路网络测算的交通网络中心性数据。a1.数字标牌区位因子空间网格化数字标牌区位因子空间化处理如附图2,通过地理信息系统软件空间连接操作,将房天下平均房价数据、社交网络签到数据、经济普查中的商业网点期末人口数量数据、人口普查中的单位人口数量数据、交通网络中心性数据5种数字标牌影响要素数据和数字标牌数据进行500m标准格网的面插值空间化处理,使所有数据都能在统一的尺度上进行可视化以及建模。a2.对空间格网化数字标牌区位因子数据进行归一化处理将经过空间化处理后的数字标牌区位因子作为样本点的属性数据,剔除无效因子,组成样本点资料矩阵x={x1,x2,…,xn},n为区位的个数,每个区位又有m个指标来表征数字标牌区位因子属性,即表示为式2:xi={xi1,xi2,…,xim}(式2)得到样本点资料矩阵表示为式3:其中,xnm表示第n个区位的第m个区位因子的原始数据值。通过最小-最大规范化对原始数据进行线性变换,构建模型表示如式4:式4中,hij为归一化处理后的第j个数字标牌区位因子数据,xij为原始第j个数字标牌区位因子数据,xj(max)为全部区位样本点中第j个区位因子的最大值,xj(min)为全部区位样点中第j个区位因子的最小值。b.数字标牌广告受众人群分类模型构建。将数字标牌的广告受众人群按行业分布进行分类,可以分为如表1所示的12个类型。附图3为某市城区环路数字标牌广告受众人群示意图,不同的颜色代表不同的受众人群类型,从图中可以看出一个区位里每种广告受众人群的数量有多个,且一个区位里存在多种广告受众人群类型,针对这种数据特点,本发明将利用改进的神经网络来计算每个区位包含各种受众人群的概率,同时考虑已布设数字标牌区位对未布设数字标牌区位的受众人群具有一定的影响力,因此,发明将利用改进的huff模型计算数字标牌广告受众人群受周围区位广告受众人群的影响力,最后将两种模型得到的结果按照一定的规则进行融合,从而得到每个区位中包含每种数字标牌广告受众人群的可能性大小。表1受众人群分类符号受众人群符号受众人群type1生产/营运/采购/物流type7广告/市场/媒体/艺术type2公务员/翻译/其它type8建筑/房地产type3服务业type9咨询/法律/教育/科研type4会计/金融/银行/保险type10计算机/互联网/通信/电子type5贸易/百货type11人事/行政/高级管理type6销售/客服/技术支持type12生物/制药/医疗/护理b1.利用改进的神经网络计算每个区位包含各种受众人群的概率。神经网络是一种模仿生物神经网络的结构和功能的计算模型,当将其作为分类器时通常由输入层、隐藏层和输出层和分类器组成。附图4是一个用作多类分类的五层神经网络,包括输入层、隐藏层、原始输出层、softmax层以及最终输出层。其中,softmax一个优化分类结果的学习算法,它将神经网络的输出变成了一个概率分布,每个类别的概率都在0和1之间,且各个类别的概率和为1。将f1和f2作为隐层和原始输出层的激活函数,则其中隐藏层的输出为:其中,xi(i=1,2…d)表示输入单元,d表示输入单元个数,hk(k=1,2…q)表示隐层单元,q表示隐层单元个数,wik表示从输入单元i到隐层单元k的连接权。原始输出层的输出为:其中,yj(j=1,2,…j)表示原始输出单元,j表示原始输出单元的个数,vkj表示从隐层单元k到原始输出单元j的连接权。最终输出层的输出为:其中,oj(j=1,2,…j)表示最终输出单元,j表示最终输出单元的个数。得到最终的输出值后,计算实际输出与期望输出的误差,并利用误差向后传播来修正权重,从而实现算法的实际输出与期望输出误差最小化。以上的神经网络用作分类时,分类得到的所有标签的概率之和为1,所以只适用于多类分类情况(即从多个标签中选择概率最大的一个标签作为输入样本的最终标签)。而本发明中一个数字标牌示例可能同时拥有多个广告受众人群标签,因此将对上述神经网络进行改进,从而使其能够有效的解决数字标牌广告受众人群分类问题。附图5是本发明改进的神经网络结构图,发明利用sigmoid层替换了原始的softmax层,在每个原始输出单元后加了一个sigmoid函数作为分类器,sigmoid函数可以将任何输入映射到[0,1]空间,其函数值恰好可以解释该标签属于/不属于输入示例的概率(概率的取值范围是0~1)。其中,隐藏层和原始输出层的输出计算方式如式(5)和式(6)所示,最终输出层的计算如下:其中,yj(j=1,2,…j)表示原始输出单元,oj(j=1,2,…j)表示最终输出单元,j表示输出单元的个数。利用改进的神经网络进行数字标牌广告受众人群分类时,可以得到各个区位中每个广告受众人群标签的概率。b2.利用改进的huff模型计算已布设数字标牌区位对未布设数字标牌区位的受众人群影响力。huff模型最初被用于测算特定地点的某个消费者到某个零售店购物的可能性,其概率表示为:其中,pij表示地点i的顾客到商店j购物的概率,k表示周围商店,n表示周围商店的总个数,s表示商店的面积,d表示距离,β表示摩擦系数。本发明中利用huff模型来计算已布设数字标牌区位对未布设数字标牌区位的受众人群影响力。由于在本发明中,一个区位里每种广告受众人群的数量可能有多个,且一个区位里可能存在多种广告受众人群类型,所以为了更加准确的计算已布设数字标牌区位中的受众人群对未布设数字标牌区位的受众人群的影响力,本发明对huff模型进行改进。将每种广告受众人群的数量作为模型的影响因素,同时,在构建模型中充分考虑一个区位里可能存在多种广告受众人群的情况,已布设数字标牌区位对未布设数字标牌区位x的受众人群影响力示意图如附图6所示,未布设数字标牌区位x受周围已布设数字标牌区位受众人群ty_j的影响力fxty_j可通过式10计算得到。其中,z表示已布设数字标牌的区位,z表示已布设数字标牌的区位个数,d表示距离,h表示x周围有类型ty_j的区位,h表示区位x周围有类型ty_j的区位个数,num表示区位x周围已布设数字标牌区位中含有类型ty_j的数量,β表示平滑系数;为了体现不同邻域内的区位对当前区位的受众人群影响力的差异性,将对公式(10)中的距离进行约束,增加如下的限制条件:dxz<=epsz=1…z(式11)其中,dxz表示区位x和已布设数字标牌的区位z之间的距离,eps表示以区位x为中心的半径,表示经过公式(11)的约束,在公式(10)中将只考虑一定邻域范围内的已布设数字标牌区位对未布设数字标牌区位的受众人群影响力。b3.将改进的神经网络算法和改进的huff模型融合,完成数字标牌广告受众人群分类。将改进的神经网络分类算法得到的每个区位包含各种受众人群的概率(pnn)与改进的huff模型计算得到的已布设数字标牌区位对未布设数字标牌区位的受众人群影响力归一化值(fhuff)通过公式(12)进行融合,从而得到每个区位中包含每种数字标牌广告受众人群的可能性大小(p)。p=αpnn+(1-α)fhuff(式12)其中,α取值在0-1之间,表示pnn和fhuff在融合规则中所占的权重比,α越大表示pnn占的比重越大。c.数字标牌广告受众人群类型分类模型结果验证为了验证数字标牌广告受众人群分类模型的性能,并使模型的分类结果更为准确可靠,本发明采用十折交叉验证法进行分类实验,即将数据集平均分成十分,每次将其中9份作为训练数据,另1份作为测试数据,进行10次试验后将其结果加权求平均作为最终的训练结果,采用如下指标来评估模型性能。a.hamming-loss该评价指标用于考察样本在单个标记上的误分类情况,例如,一个标签不属于一个示例而被预测为输入该示例或者一个标签属于一个示例而没被预测为属于该示例。hamming-loss数值在0和1之间,其数值越小,算法效果越好。其中,l表示样本个数,n表示标签个数,h(xl)表示第l个样本对应的预测标签,yl表示第l个样本对应的真实标签,算子δ用于表示两个集合之间的对称差,|·|为返回集合大小。b.one-error该评价指标用于考察在样本的类别标记排序序列中序列最前端的标记不属于相关标记集合的情况,该指标取值越小,性能越好。其中,l表示样本个数,表示样本xl对应的类别标签排序序列中序列最前端的标签,yl表示第l个样本对应真实标签。c.coverage该评价指标用于考察在样本的类别标记排序序列中覆盖所有相关标记所需的捜索深度情况。该指标取值越小,系统的性能越好。其中,l表示样本个数,rank(xl,y)表示y标签在预测序列中的排序,越大表示排序越低。d.ranking-loss该指标用于考察在样本的类别标记排序序列中出现排序错误的情况,即无关标记在排序序列中位于相关标记之前。该指标取值越小,系统的性能越好。其中,l表示样本个数,yl表示第l个样本对应的真实标签,代表集合yl中的补集,f为预测函数。e.averageprecision该指标用于考察在样本的类别标记排序序列中排在相关标记之前的标记仍为相关标记的情况。averageprecision数值越大,说明该多标记学习算法学习效果越好。其中,l表示样本个数,yl表示第l个样本对应的真实标签,rank(xl,y)表示样本xl的标签集合排序序列中标签y的排名。c1.本发明将两种模型得到的权重系数α设为0~1,步长为0.1,特别地,当α=0时表示改进的神经网络的比重为0,此时只有改进的huff模型作用,而当α=1时表示改进的huff模型的比重为0,此时只有改进的神经网络模型作用;将公式(11)中的领域eps设为{2,4,6,8,10},从而得到不同领域范围内已布设数字标牌区位对未布设数字标牌区位的受众人群影响力。通过α和eps的设置,得到了不同领域中不同的模型融合权重比的对比结果。其中,hamming-loss结果见附图7:当eps为{2,4,8}时,模型的hamming-loss随着α的增加而减小,当eps为{6,10}时,模型的hamming-loss随着α的增加先减小然后基本保持不变,且在α=0.3时hamming-loss的值达到最小。one-error结果见附图8:当eps为{2,4}且α为0-0.8时,模型的one-error随着α的增大而减小,在α为0.9和1时,模型的one-error随着α的增大而缓慢增加;当eps为{6,8,10}时,模型的one-error随着α的增大先减小而后有着小范围的上下波动,在eps=6且α=0.3时达到最小值。ranking-loss结果见附图9:模型的ranking-loss随着α的增大先减小而后不断的上下波动,在eps=6且α=0.3时达到最小值。coverage结果见附图10:模型的coverage随着α的增大先减小而后不断的上下波动,在eps=6且α=0.3时达到最小值。averageprecision结果见附图11:模型的averageprecision随着α的增大先增加再减小而后基本保持不变,且在eps=6且α=0.3时达到最大值。从以上的五个多标签的评价指标可以看出:(1)当只考虑利用改进的huff模型计算得到的数字标牌广告受众人群受周围区位中数字标牌广告受众人群的影响力时,分类结果中各个分类指标都相对其它情况较差,但是各个指标都表现得良好,该结果表明空间中的影响力对数字标牌广告受众人群分类结果有一定的影响,进一步验证了本发明将空间影响力引入数字标牌广告受众人群分类模型具有可行性;(2)当只利用改进的神经网络分类模型对数字标牌广告受众人群进行分类时,分类结果中各个指标都取得了非常满意的值,表明将神经网络进行改进后用于本发明中这种数字标牌广告受众人群的多标签分类是可行的;(3)当将两种模型进行融合时,在不同的eps和不同的α值下,各个指标的值都相对只有改进的huff模型作用时要好,在相同的α下,各个指标的值在eps=6时好于其他eps下的值,同时在α=0.3时,各个指标都取得了最好的值,说明只考虑邻域范围为6的已布设数字标牌区位对未布设数字标牌区位的受众人群影响力时分类效果最好,同时将两种模型按照权重系数为0.3进行融合时分类效果最好,因此,本发明将最终的分类模型中的受众人群影响力范围领域设为6并将模型融合规则中的权重系数设为0.3进行受众人群分类。c2.为了进一步验证本发明提出的数字标牌广告受众人群分类模型的有效性,本发明将改进的huff模型(ml-huff)、改进的神经网络模型(ml-nn)以及eps=6、α=0.8时的融合模型(ml-hnn)与已有的多标签算法:bp-mll、ml-knn、rank-svm进行对比。hamming-loss结果见附图12:ml-knn算法对应的hamming-loss值低于其它几种算法。one-error结果见附图13:几种算法的one-error值差距比较大,其中ml-hnn算法最低,bp-mll算法最高。ranking-loss结果见附图14:ml-hnn算法对应的ranking-loss值明显低于其它几种算法。coverage结果见附图15:ml-knn算法对应的coverage值低于其它几种算法。averageprecision结果见附图16:ml-knn算法对应的averageprecision值高于其它几种算法。从以上五个多标签的对比结果可以看出:提出的融合模型的分类结果优于单独用于分类的改进的神经网络模型与改进的huff模型以及已有的多标签分类算法,该结果一方面表明本发明提出的融合模型具有良好的分类结果,另一方面也说明将地理空间中的模型与机器学习算法相结合可以更好的解决这种具有空间影响力的分类问题。c3.数字标牌广告受众人群的分类可能性结果如附图17-附图28所示。受众人群为生产/营运/采购/物流的分类结果如附图17::该受众人群主要分布在五环外的西部以及东北方向;受众人群为公务员/翻译/其它的分类结果如附图18所示:该受众人群主要分布在交通干路周围;受众人群为服务业的分类结果如图19所示:该受众人群主要分布在四环以内的商圈密集地区;受众人群为会计/金融/银行/保险的分类结果如图20所示:该受众人群主要分布在四环以内的商圈密集地区;受众人群为贸易/百货的分类结果如附图21所示:该受众人群主要分布在五环以内的商圈密集地区;受众人群为销售/客服/技术支持的分类结果如附图22所示:该受众人群主要分布在城四环和城五环的西北方向;受众人群为广告/市场/媒体/艺术的分类结果如附图23所示:该受众人群主要分布在城四环和城五环的正北和西北方向;受众人群为建筑/房地产的分类结果如附图24所示:该受众人群主要分布在环路周围;受众人群为咨询/法律/教育/科研的分类结果如图25所示:该受众人群主要分布在城四环和城五环的正北和西北方向;受众人群为计算机/互联网/通信/电子的分类结果如图26所示:该受众人群主要分布在城五环的正北和西北方向;受众人群为人事/行政/高级管理的分类结果如图27所示:该受众人群主要分布在城三环和城四环的正北和西北方向;受众人群为生物/制药/医疗/护理的分类结果如图28所示:该受众人群零散的分布在五环内。本发明的方法实现了广告受众人群的分类,方法检验结果表明:利用本发明提出的方法进行数字标牌广告受众人群具有较好的分类结果,从而使得数字标牌广告投放更具有针对性,进一步提高数字标牌产品竞争力,使广告投放效益最大化、数字标牌资源配置最优化,具有更高的商业价值和经济效益。需要注意的是,公布实施例的目的在于帮助进一步理解本发明,但是本领域的技术人员可以理解:在不脱离本发明及所附权利要求的精神和范围内,各种替换和修改都是可能的。因此,本发明不应局限于实施例所公开的内容,本发明要求保护的范围以权利要求书界定的范围为准。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1