基于多采样率自回归分布滞后模型的高炉指标预测方法与流程
本发明属于工业过程监控、建模和仿真领域,特别涉及一种改进midas-adl预测高炉炼铁生产技术指标的方法。
背景技术:
钢铁制造流程中,以大型高炉为主的大型炼铁系统是铁素物质流转换的关键工序,也是能耗最大、排放最多、生产成本最高的环节,分别占钢铁综合能耗的65%~75%、钢铁大气污染物排放总量的80%左右、钢铁制造总成本的60%~70%。另外,作为钢铁流程的前端关键工序,炼铁系统的生产质量和效率决定着整个钢铁制造流程的钢材质量和生产效率。由此可见,大型炼铁系统是钢铁流程深度节能降耗减排和提质增效的前沿阵地。
我国多数大型炼铁系统的原燃料禀赋差且成分多变,运行工况频繁波动且规律难以把握。此外,大型炼铁系统的场相耦合与非线性多参数耦合异常复杂,表征运行性能的关键参数难以在线检测,使得以人工经验知识为主的炼铁系统的操作调控不及时,生产长时间处于非最优状态,造成能耗高、效率低以及产品质量的不稳定。因此,亟需在现有炼铁生产自动化与信息化的基础上,深度融合炼铁专家知识、操作经验与智能技术,实现信息深度感知、智慧优化决策和精准协调控制,以提高我国大型炼铁系统生产过程的绿色化与智能化水平。
但现有的数理统计和智能预测方法,如贝叶斯网络、卡尔曼滤波、深度学习、神经网络、支持向量机、随机森林等,基本都是基于相同采样率的数据,对于不同采样率的数据也是先进行加总或是插值使其成为相同时间间隔的数据,这样会导致数据所蕴含的信息损失和人为信息增加,没有办法充分利用现有的高采样率数据信息。
技术实现要素:
为了克服现有技术的不足,本发明的目的在于提供一种基于多采样率自回归分布滞后模型的高炉指标预测方法。
一种基于改进多采样率(midas,mixeddatasampling)自回归分布滞后(adl,autoregressivedistributedlag)模型的高炉生产指标预测方法,在多采样率模型中通过高频解释变量预测低频被解释变量,提出停留时间分布作为权重函数,同时利用自适应遗传算法用于参数估计,最后选取解释变量,根据相关性分析确定模型输入输出变量;
所述的多采样率模型(midas-adl)表达式为:
y为被解释变量,x为解释变量,α为常数项,β为解释变量的总体乘数,γj为延迟系数,μt为随机扰动项,ωi(θ)为权重函数,p、q为x、y的最大滞后阶数,m为高采样率比低采样率的倍数;
所述的权重函数表达式为:
所述的自适应遗传算法用于midas-adl模型中的参数估计:
通过在迭代过程中计算种群个体适应度函数分布并根据其偏度系数式(11)决定种群规模的增减,到达在进化中根据种群性能实时改变种群规模的目的;
种群规模与偏度系数关系如式(12)所示:
其中,sk为偏度系数,zn为种群规模,k为种群变化值。
所述的解释变量包括透气性指数、炉顶温度、煤气利用率、炉腹煤气指数和理论燃烧温度,所述的被解释变量包括铁水产量和能耗焦比。
所述的方法,根据相关性分析确定模型输入输出变量步骤如下:
a.利用主成分分析方法精简解释变量,
b.利用插值法是被解释变量和解释变量的采样率保持一致,
c.通过spearman秩序相关系数计算解释变量与被解释变量秩序的相关性,
d.综合考虑专家经验和相关性分析结果确定模型输入输出变量。
本发明的有益效果:设计的权重函数解决了常规函数缺乏实际意义难于解释的问题,其只包含一个未知变量,减少了变量个数有利于参数估计。改进的自适应遗传算法作为最优参数估计方法具有很好的计算效率及全局收敛性,可以同时估计模型各个参数的最优值。通过相关性分析和专家知识选取典型的解释变量,能够为预测方法提供丰富的信息。作为一个整体,本发明能够利用多采样率系统中各种各样的信息为生产指标的预测做出贡献,有利于生产企业的考核管理和指导生产操作。
附图说明
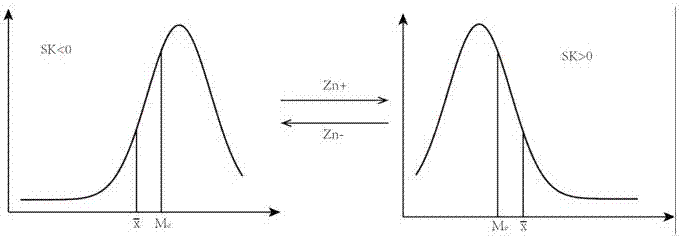
图1所示为种群规模与适应度函数偏度的变化关系;
图2所示为铁水产量预测结果与实际数据对比;
图3所示为能耗焦比预测结果与实际数据对比。
具体实施方式
本发明的目的在于提供一种基于改进多采样率自回归分布滞后模型的高炉生产指标预测模型,可以在多采样率系统中实现通过高频解释变量预测低频被解释变量。
本发明提供的多采样率(midas)模型中的权重函数部分,主要包含两大系统:权重函数的设计与最优参数的估计。通过类比反应器中物料的停留时间分布设计权重函数,是midas模型中是核心部分。并且摒弃了传统的数值优化算法,选择智能优化算法——遗传算法作为权重函数参数的最优估计方法,并通过改进遗传算法进一步提升算法的计算效率和收敛性能。最后,midas模型中的高采样率解释变量、低采样率被解释变量通过数学分析和专家知识选取,完全符合理论分析与实际情况。
midas-adl模型表达式为:
其中,y为被解释变量,x为解释变量,α为常数项,β为解释变量的总体乘数,γj为延迟系数,μt为随机扰动项,ωi(θ)为权重函数,p、q为x、y的最大滞后阶数,m为高采样率比低采样率的倍数。
一、midas模型中权重函数的设计
所述midas模型权重函数的停留时间分布形式,从化学反应工程中得到启发:在一个稳定的连续流动的反应器中,某一瞬间同时进入的反应物料,将经历不同的停留时间依次从反应器中流出,形成停留时间分布,因此提出一种全新的midas模型权重函数。
i、反应器中的非理想流动及其产生的停留时间分布
物料在反应器中的流动和混合随着情况的不同而各不相同。对于平推流反应器,所有物料颗粒的停留时间相同;对于全混流反应器,内部各处物料浓度相等且等于出口处反应物浓度,颗粒物料在反应器中有一定的停留时间分布。工业过程中,化学反应与停留时间和物料浓度直接相关,因此,反应结果直接受流动状况的影响。通常,非理想流动由两方面因素引起:一是反应器内反应物料粒子搅拌、分子扩散等运动产生的与主体流动不同方向的运动,二是反应器内各处流动速度不一致。反应物料的停留时间分布是一个随机过程,因此可以从概率统计角度定量的描述流动系统中物料停留时间分布情况。
平推流和全混流是两种极端的理想模型,全混流串联形成的多级混合模型可以模拟各种各样的流动模型,事实上无限多个全混流串联即为平推流模型,以下通过全混流多级混合模型推导物料颗粒停留时间分布密度函数e(t)。
对于n个串联反应釜,各反应釜对物料b作物料衡算得:
c0为初始反应物浓度,c1、…、cn分别为从第1到n个反应釜中出来的反应物浓度,τs为单个反应釜中平均停留时间。
方程组(2)的初始边界条件为:
t=0,c0(0)=1,c1(0)=c2(0)=l=cn(0)=0(3)
解方程组(2)可得:
进一步可得:
其中τ=nτs表示系统内的整体平均停留时间,e(t)为停留时间分布密度函数,f(t)为停留时间分布函数,将公式(5)转换为无量纲表达式,可知停留时间分布密度函数为:
ii、根据停留时间分布密度函数设计midas权重函数
式(6)是多级混合模型的停留时间分布表达式,可以用来表示高炉中炉料下行过程中的变化,通过适当变换可以用来作为midas模型的权重函数。借助于gamma函数:
由函数可知其具有如下性质:
γ(x+1)=xγ(x)(8)
因此,gamma函数具有将数学概念从整数域推广到实数域的能力,将式(8)代入式(6)中可得:
用
二、基于改进遗传算法的最优参数估计方法
midas构建了一个模型系统,包含总体均值函数和权重函数这两部分,由于多采样率导致数据的不平衡性、非线性,增加了权重参数的识别难度。以往,最优权重参数、最优高频解释变量滞后阶数的选择都是依靠最小二乘法和极大似然估计确定,但这两种方法面临计算复杂和可能陷入局部极值的问题,新型智能式的启发优化算法在某种程度上可以解决这些问题,能够同时估计参数α,β,θ,γ,μ。从进化论——自然选择中总结而来的遗传算法具有优异的全局搜索能力,通过适当改进可以兼具效率与准确性。遗传算法实现的六个主要因素:参数的编码、初始群体的设置、适应度函数的设计、遗传操作、算法控制参数的设定、约束条件。基于此,我们设计了一种种群规模自适应的遗传算法(sapga),通过在迭代过程中计算种群个体适应度函数分布并根据其偏度系数(11)决定种群规模的增减,达到在进化过程中根据种群性能实时改变种群规模的目的。
当偏度系数sk增加时,说明适应度较大的个体数有增加趋势,因此应该增加个体数目,新增的个体随机产生,以增大种群基因多样性,提高搜索到全局最优解的可能性。当偏度系数sk减小时,说明适应度较小的个体数有增加趋势,应该减少种群个数,特别是去除适应度较小的个体,因此适应度较小的个体被剔除的概率要加大,实现的方法是轮盘赌方法。在赌轮选择规则中,适应度越小的个体被选中遗传到下一代的概率越小,因此减小下一代种群规模即可增加小适应度个体被去除的概率。综上,当偏度增加时扩大种群规模以丰富基因多样性,当偏度减小时减少种群大小以节省计算时间,种群规模与偏度系数关系如(12)所示:
sk为偏度系数,zn为种群规模,k为种群变化值。
种群规模与适应度函数偏度变化关系如图1所示。sk>0,有少数变量值很大;sk<0,有少数变量值很小。正偏态向负偏态转变的过程,即数值大的个体数减少、数值小的个体数增加的过程。我们希望将遗传过程中种群适应度函数分布控制在正态分布,以具有最优的全局搜索能力。
三、预测模型输入输出的选择方法
高炉从上到下分为炉喉、炉身、炉腰、炉腹、炉缸五部分,焦炭、矿石和熔剂在下降的过程中会炉内不同部位经历不同变化,直到到达炉缸底部完全转化为铁水和炉渣。通过和高炉操作人员交流,初步确定了透气性指数、炉顶温度、煤气利用率、炉腹煤气指数和理论燃烧温度这5个指标作为解释变量,包含了全炉整体以及上、中、下各部位影响炉内反应情况的高采样率变量,而被解释变量则是生产指标如铁水产量、焦比、铁水质量等。专家经验只是从实际生产过程中提出了影响被解释变量的最大可能因素,实际的情况还学要详细的数学证明。因此,我们通过相关性检验验证了高炉操作人员提出的解释变量,步骤如下:
a.利用主成分分析方法精简解释变量;
b.利用插值法是被解释变量和解释变量的采样率保持一致;
c.通过spearman秩序相关系数计算解释变量与被解释变量秩序的相关性;
d.综合考虑专家经验和相关性分析结果确定模型输入输出变量。
四、代入工业实际数据进行验证
透气性指数、煤气利用率、炉腹煤气指数、理论燃烧温度、炉顶温度这5个变量的采样间隔为1小时,而产量和焦比的采样时间间隔为1天,因此解释变量的采样频率是被解释变量的24倍。我们取某炼铁厂容积为2650m3的2#高炉477天的数据作为样本,其中包含477组被解释变量和11448组解释变量。将数据进行预处理后,通过上述所建改进midas-adl模型进行生产指标的预测,铁水产量的预测结果如图2,能耗指标焦比的预测结果如图3。
从预测结果可以看出模型效果很好,能够准确地预测出被解释变量的值,表明其能充分挖掘高采样率解释变量所蕴含的信息。
- 还没有人留言评论。精彩留言会获得点赞!