社交网络事件时序关系分析方法与流程
本发明属于事件检测与追踪技术领域,具体涉及一种社交网络事件时序关系分析方法。
背景技术:
话题检测与追踪(tdt)技术源自早期的事件检测与追踪(edt)技术。最初的tdt研究将话题定义为事件。事件最初被描述为发生在特定事件和地点的事情。随着tdt技术的发展,话题的定义变得更加广泛。话题不仅仅包含由最初事件引起或导致发生的后续事件,同时还包含了与其相关的其他事件或活动。tdt对话题的定义为:一个话题由一个种子事件或者活动以及与其直接相关的事件或活动组成。tdt的任务包括面向新闻类报道的切分任务、面向已知话题的跟踪任务、面向未知话题的检测任务、对未知话题首次相关报道的检测任务、以及报道见相关性的检测任务。
事件演化分析是话题检测与追踪技术的一个子任务。事件演化分析的目标是对一个话题下事件之间的关系进行刻画,并构建事件关系模型,最终进行演化分析。随着web2.0技术的发展与进步,社交网络变得越来越庞大,信息量也变得越来越丰富。以推特、微博等社交网络平台越来越成为了人们进行互动的重要方式。传统的新闻报道也纷纷通过这些社交网络平台进行新闻发布与消息传递。通过社交平台人们可以发表自己的看法与转发感兴趣的话题,而这些话题中包含了一些重要的信息。因此,对社交网络的信息进行提取与分析是一个很有意义的课题。
在社交网络事件的表达上,学术界尚未有事件的准确定义。事件起初被描述为特定时间特定地点发生的事情。随着研究的深入,事件被描述为特定时间特定地点发生的事情,并且事情发生需要一些必备的先决条件并产生一些无可避免的后果。但事件的准确定义在学术界尚有争议。研究人员在社交网络事件的研究过程中,将事件组织为文本集合,即认为事件是一系列文本构成。这些文本包括了创建时间,文本内容,文本数目等信息。通过事件检测,文本聚类等技术将相似文本聚成一个个簇,然后基于文本簇对事件进行分析。
目前的事件演化分析技术主要有事件关系刻画与事件演化图的构建。事件关系的刻画方法主要包括了事件的时序关系构建、事件的文本内容关系构建,以及事件的空间关系构建。而时序关系的构建基于事件发生的时间先后关系和发生时间的距离。allen对时序关系进行了深入研究,并将时序关系按照时间分布的区间进行分析,定义了8类主要的时序关系。
根据allen定义的时序关系,可以对两个时间区间进行时序分析。但由于社交网络短文本信息本身存在一定的噪声,导致事件检测方法得出的结果有可能不够准确。另外,由于事件是通过短文本的文档创建时间(dct)进行表达的。但由于人们发布短文本的时间可能并不是实时的,也即事件的真正的发生时间同文档创建时间并不完全一致。这使得包含文本信息的事件的开始时间和结束时间本身可能不准确。因此,仅仅根据事件文本集合的开始时间和结束时间分析事件之间的时序关系会产生很大的偏差。
在社交网络事件时序关系的研究中,现有的方法有基于文档创建时间的时序关系分析、基于时间表达式提取时序分析方法,以及基于时间分布模型的时序关系分析方法。
基于文档创建时间的时序关系分析方法主要根据事件发生的时间区间进行比较。该方法直接利用文档创建时间进行比较,根据allen提出的8类主要的时间序列的区间关系,选择时间点基准进行比较。常用的时间点基准有时间区间的第一个时间点,并认为其为事件的开始时间。该方法在事件时间序列同文档创建时间高度一致的情形下是适用的。然而,对于社交网络事件时间序列含噪的情形,该方法得到的结果是不准确的。
基于时间表达式提取时序关系的方法是一种有效的时序关系分析方法,在新闻语料库中的应用很广泛。时间表达式指的是文本中出现的关于时间的词汇,例如英语文本中的before,after等明显的时序关系。这类时序关系词能够在文本层面对时间关系进行刻画。时间表达式还包括文本内容描述特定时间的词汇,例如英语文本中的tuesday等,这类明确描述了文本的发生时间,结合文档创建时间可以进行时序关系分析。基于时序表达式的时序关系提取方法需要对时间表达式进行抽取,抽取方法的好坏直接影响时序关系分析的结果。本质上,时序关系表达式是基于规则制定的抽取方法,即人为的制定一些规则,通过正则表达式、命名实体识别(ner)等技术进行抽取。对于文本中包含时序表达式较多的长文本而言,该方法能够有效的获取事件的发生时间。但由于短文本中的信息较少,可能无法抽取到充足的时间表达式信息。
基于时间分布模型的时序分析方法的思想是对事件的文档分布进行建模,并对模型参数进行拟合,然后得到事件的时间信息的一种方法。该方法主要利用社交网络中事件的文本流、文本量,文本时间间隔等特征进行事件的时间分布建模。研究人员发现一些事件的文本流满足一些随机过程的分布,例如泊松分布。通过模型拟合方式估计事件的持续时间,然后进行时序分析。但该方法需要事先对事件文本流进行分布估计,而实际中,社交网络短文本事件的文本分布特征可能并不明显,这给分布模型的建立带来了很大挑战。
技术实现要素:
本发明的发明目的是:为了解决现有技术中社交网络事件时序分析存在的以上问题,本发明提出了一种基于动态时间规整和分位数-分位数图分析的社交网络事件时序关系分析方法。
本发明的技术方案是:一种社交网络事件时序关系分析方法,包括以下步骤:
a、获取事件检测结果数据,所述事件检测结果数据为事件短文本簇集合;
b、根据事件检测结果数据中短文本单词数和短文本数对事件短文本簇集合进行事件短文本簇时间序列抽取;
c、遍历步骤b抽取的事件短文本簇时间序列集合,采用动态时间规整算法获取所有事件短文本簇之间的时序对应关系;
d、根据步骤c获取的事件短文本簇之间的时序对应关系,构建分位数-分位数图;
e、计算事件短文本簇之间的时序对应关系的时序距离,再根据分位数-分位数图获取事件短文本簇之间的时序先后关系,得到所有事件短文本簇之间的时序关系。
进一步地,所述步骤a中,事件短文本簇集合包括多条短文本,每条短文本包含创建时间、发布数目、以及短文本内容信息。
进一步地,所述步骤b中,根据事件检测结果数据中短文本单词数和短文本数对事件短文本簇集合进行事件短文本簇时间序列抽取,具体为:
设定短文本单词数阈值和短文本数阈值,将事件检测结果数据中短文本单词数小于短文本单词数阈值的短文本、及短文本数小于短文本数阈值的短文本簇进行剔除,抽取得到有效的事件短文本簇时间序列集合。
进一步地,所述步骤c中,遍历步骤b抽取的事件短文本簇时间序列集合,采用动态时间规整算法获取所有事件短文本簇之间的时序对应关系,具体为:
将每个事件短文本簇的文档创建时间序列表示为t={t1,t2,...tn},n为事件的短文本数目,第i个事件短文本簇的文档创建时间序列ti表示为ti={ti1,ti2,...tik,...},ik为事件i的第k个文档创建时间序列,选取两个事件短文本簇时间序列ti={ti1,ti2,...tin}、tj={tj1,tj2,...tjm},其中ti1<ti2<...<tin,tj1<tj2<...<tjm,采用动态时间规整算法对两个事件短文本簇时间序列中的时间点进行匹配,得到两个事件短文本簇之间的时序对应关系,遍历事件短文本簇时间序列集合,得到所有事件短文本簇之间的时序对应关系。
进一步地,所述动态时间规整算法具体包括以下分步骤:
c1、根据两个事件短文本簇时间序列ti={ti1,ti2,...tin}、tj={tj1,tj2,...tjm},构建n×m的二维矩阵,并设置初始化值;
c2、采用绝对值距离作为距离度量方式,计算两个事件短文本簇时间序列之间的最小距离;
c3、根据步骤c2得到的两个事件短文本簇时间序列之间的最小距离及二维矩阵的值,计算两个事件短文本簇时间序列中的时间点之间的最优匹配。
进一步地,所述步骤e中,计算事件短文本簇之间的时序对应关系的时序距离,具体为:
根据两个事件短文本簇时间序列之间的时序对应关系,分别计算事件短文本簇时间序列ti中每个时间点与事件短文本簇时间序列tj中时间点进行匹配的时序距离,将所有时间匹配的时序距离进行求和后再求平均,得到两个事件短文本簇时间序列之间的时序对应关系的时序距离。
进一步地,所述两个事件短文本簇时间序列之间的时序对应关系的时序距离表示为
其中,d(ti,tj)表示事件短文本簇时间序列ti和tj之间的时序距离,pl表示第l个时间匹配的时序距离,nr表示第r个时间匹配包含的时间对的个数。
本发明的有益效果是:本发明首先对事件短文本簇集合进行事件短文本簇时间序列抽取,并采用动态时间规整算法对事件的时间序列进行匹配,然后根据匹配的结果定量计算事件短文本簇之间的时序对应关系的时序距离,并通过分位数-分位数图可视化的方法定性分析得到事件短文本簇之间的时序关系,能够显著提升社交网络中事件时间序列关系的识别精度。
附图说明
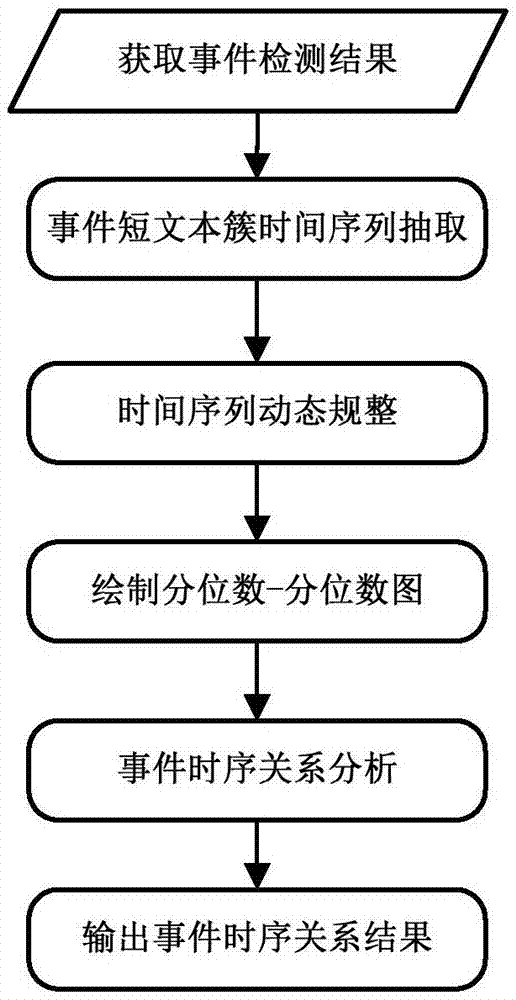
图1是本发明的社交网络事件时序关系分析方法的流程示意图;
图2是本发明的动态时间规整算法的流程示意图;
图3是本发明中两个离散时间序列的动态时间规整匹配示意图;
图4是本发明中两个时间序列的分位数-分位数示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
图1是本发明的社交网络事件时序关系分析方法的流程示意图。一种社交网络事件时序关系分析方法,包括以下步骤:
a、获取事件检测结果数据,所述事件检测结果数据为事件短文本簇集合;
b、根据事件检测结果数据中短文本单词数和短文本数对事件短文本簇集合进行事件短文本簇时间序列抽取;
c、遍历步骤b抽取的事件短文本簇时间序列集合,采用动态时间规整算法获取所有事件短文本簇之间的时序对应关系;
d、根据步骤c获取的事件短文本簇之间的时序对应关系,构建分位数-分位数图;
e、计算事件短文本簇之间的时序对应关系的时序距离,再根据分位数-分位数图获取事件短文本簇之间的时序先后关系,得到所有事件短文本簇之间的时序关系。
在本发明的一个可选实施例中,上述步骤a首先获取事件检测得到的结果数据,事件检测结果数据为事件短文本簇集合,事件短文本簇集合中的每个事件都由一系列短文本构成,每条短文本包含了创建时间、发布数目、以及文本内容等信息。
在本发明的一个可选实施例中,上述步骤b中根据事件检测结果数据中短文本单词数和短文本数对事件短文本簇集合进行事件短文本簇时间序列抽取,具体为:
设定短文本单词数阈值和短文本数阈值,将事件检测结果数据中短文本单词数小于短文本单词数阈值的短文本、及短文本数小于短文本数阈值的短文本簇进行剔除,抽取得到有效的事件短文本簇时间序列集合。
事件检测的结果是事件集合,每个事件是一个短文本簇,每个事件短文本簇中包含的每条文本是一条社交网络短文本。事件检测输出的文本已经进行了预处理,例如分词,去标点,命名实体识别等。
如表1所示为达拉斯枪击案事件短文本簇的部分短文本,包括文档创建时间、数目、以及短文本内容等信息。
表1、达拉斯枪击案事件短文本簇
由于事件检测的结果中每个短文本簇包含的数目不同,有的短文本簇中的短文本数目很多,而有的短文本簇中的短文本数目很少。对于短文本数多的事件而言,事件信息较为丰富,便于有效的进行时序分析;而对于短文本数较少的事件而言,事件信息不够充足,无法有效利用其中的事件信息。因此,对于短文本数较少、不足以反映事件信息的事件短文本簇进行剔除,对于部分短文本存在文本内容描述过于简短进行剔除。从两方面进行考虑,一方面,对短文本中单词数少于5的短文本进行剔除;另一方面,将短文本数少于20的事件短文本簇进行剔除,最终得到若干有效的事件短文本簇集合。
通过事件短文本簇时间序列抽取,能够对事件短文本簇进行过滤,保留事件信息丰富的短文本簇,便于后续时序分析。
在本发明的一个可选实施例中,上述步骤c在得到有效的事件短文本簇集合后,对事件之间的时序关系进行建模分析。
实际中事件短文本簇的时序特征,存在如下情形:
(1)实际事件短文本簇含有噪声短文本;
(2)实际事件短文本簇中的短文本发布时间同文档创建时间不一致。
对于情形1事件本身存在噪声点的问题选取的典型事件短文本簇示例如下表所示。
表2、达拉斯枪击案事件短文本簇1
表2中选取的事件短文本簇1中主要描述的事件为:达拉斯发生警察枪击事件,部分嫌疑人被拘留,警方正在追逐其他嫌犯,并同嫌犯进行了交火。该事件的时间序列中,开始时间为2018年04月24日16时10分32秒,而根据文本描述内容,该短文本的文本内容描述的是另一个枪击事件,该时间点为噪声。并且,该事件短文本簇开始的几个时间点均为噪声点,事件短文本簇的实际开始的时间要更晚。因此,将事件短文本簇的开始时间做为时序比较依据是不合理的。
对于情形2事件短文本的发布时间和事件实际发生的时间不匹配的示例如下表所示。
表3、达拉斯枪击案事件短文本簇2
表3中的事件短文本簇2主要描述的事件为:达拉斯枪击案中警察被射击并受重伤,警方搜寻嫌犯,嫌犯被抓捕的一系列事件。该事件短文本簇中存在大量关于达拉斯警察被枪击受重伤的短文本,对于同一个事件的报道,有的短文本创建时间较晚,有的短文本创建时间较早。因此,仅仅通过文档创建时间来进行时序分析是不够合理的。
对于时间序列的时序关系估计,存在如下两种情形:
(1)两事件时间序列不存在交叠;
(2)两事件的时间序列存在交叠。
对于第一种情形,由于事件之间的时序界限很明显,时序关系很容易判别;对于第二种情形,仅仅通过事件时间序列的开始时刻作为时间先后关系的判别依据将导致较大误差。因此需要从事件的整个时间序列进行考虑。
本发明采用了统计的方法,将一个事件的时间特征由该事件下的所有时间序列共同表达,即将事件的时间序列进行对照,通过比较事件的时间序列得到整体的事件时序关系。
本发明通过遍历步骤b抽取的事件短文本簇时间序列集合,采用动态时间规整算法获取所有事件短文本簇之间的时序对应关系,具体为:
将每个事件短文本簇的文档创建时间序列表示为t={t1,t2,...tn},n为事件的短文本数目,第i个事件短文本簇的文档创建时间序列ti表示为ti={ti1,ti2,...tik,...},ik为事件i的第k个文档创建时间序列,选取两个事件短文本簇时间序列ti={ti1,ti2,...tin}、tj={tj1,tj2,...tjm},其中ti1<ti2<...<tin,tj1<tj2<...<tjm,采用动态时间规整算法对两个事件短文本簇时间序列中的时间点进行匹配,得到两个事件短文本簇之间的时序对应关系,遍历事件短文本簇时间序列集合,得到所有事件短文本簇之间的时序对应关系。
如图2所示,为本发明的动态时间规整算法的流程示意图,本发明采用的动态时间规整算法具体包括以下分步骤:
c1、根据两个长度分别为n和m的事件短文本簇时间序列ti={ti1,ti2,...tin}、tj={tj1,tj2,...tjm},构建n×m的二维矩阵,并设置初始化值;
c2、采用绝对值距离作为距离度量方式,计算两个事件短文本簇时间序列之间的最小距离;其中绝对值距离计算的是两个时间点之间的绝对距离;
c3、根据步骤c2得到的两个事件短文本簇时间序列之间的最小距离及二维矩阵的值,计算两个事件短文本簇时间序列中的时间点之间的最优匹配。
通过动态时间规整算法,可以得到两个不等长的时间序列之间的一个最优匹配。事件时间序列ti的一个时间点可能跟事件时间序列tj的一个或者多个时间点进行匹配,对于事件时间序列tj来说亦如此,通过动态时间规整算法能够得出两个时间序列的对应关系。
如图3所示,为两个离散时间序列的动态时间规整匹配示意图。它对两个离散时间序列1和2进行了匹配,其中横坐标为两时间序列按照递增排列的离散点,为每个匹配关系进行连线,最终绘制出两时间序列的匹配关系。
通过时间序列动态规整,能够对两事件的时序建立关系。该方法利用了事件时间序列的统计信息,从事件短文本的实际时间序列出发,提高了时序分析的抗噪能力。
在本发明的一个可选实施例中,上述步骤d根据步骤c获取的事件短文本簇之间的时序对应关系,构建分位数-分位数图;对于某序数或数值属性x,设xi(i=1,2,...n)是按递增排序的数据,使得x1为最小的观测值,而xn是最大的。对于每个观测值xi,与一个百分数fi配对,指出大约fi×100%的数据小于值xi。百分比0.25对应于四分位数q1,百分比0.5对应于中位数,而百分比0.75对应于q3。
令
这些数从
对于两个不同的离散数据x=x1,x2,...xn和y=y1,y2,...ym,每组数据按递增顺序进行了排列;如果n=m,就可以对着画,其中和分别对应x和y的第个分位数。如果n≠m,则可能只有m个点在分位数-分位数图中,对于这种情形,本发明采用插值、采样方法或时间对齐方法进行处理。
如图4所示,为两个时间序列的分位数-分位数(q-q)示意图。其中横坐标为第一个时间序列离散点,纵坐标为第二个时间序列离散点。根据匹配关系描每个分位数的离散点,并绘制一条45°的直线,通过对比离散点同45°直线的偏离关系能够定性分析两离散时间序列的时序关系。
在本发明的一个可选实施例中,上述步骤e计算事件短文本簇之间的时序对应关系的时序距离,具体为:
根据两个事件短文本簇时间序列之间的时序对应关系,分别计算事件短文本簇时间序列ti中每个时间点与事件短文本簇时间序列tj中时间点进行匹配的时序距离,将所有时间匹配的时序距离进行求和后再求平均,得到两个事件短文本簇时间序列之间的时序对应关系的时序距离。
假设时间序列ti={ti1,ti2,...tin}同时间序列tj={tj1,tj2,...tjm}进行了时间对齐。用时间匹配p来表示每一对时间对齐关系,设ti和tj的时间匹配为p1,p2,...ps,那么两事件之间存在s对时间关系。注意到时间匹配的构成有三种情形,分别是:一对一、多对一、以及一对多。不失一般性,对于两事件ti和tj组成的匹配pm,假设ti有c个时间点,时间序列为ti1,ti2,...tic。同时tj只有一个时间点tj1,那么第m个时间匹配pm的时序距离计算公式表示为
计算出所有的时间匹配之间的距离之后,对其进行求和,然后第所有的时间匹配距离求平均,得出两个时间序列的距离的估计值,表示为
其中,d(ti,tj)表示事件短文本簇时间序列ti和tj之间的时序距离,pl表示第l个时间匹配的时序距离,nr表示第r个时间匹配包含的时间对的个数。
并根据时间序列的对应关系,通过分位数-分位数图进行直观的定性分析。
本发明采用的是基于动态时间规整技术对两事件的时间序列进行对齐,根据匹配关系定量计算时间序列的先后关系并基于q-q图时间序列定性分析的方式来进行事件时序分析。对于事件时序分析,有针对的根据事件时间序列不匹配的情形,运用动态时间规整算法建立时间序列的对应关系,为社交网络事件时间序列估计提供一种新的解决方法。对于事件时序关系估计,有针对的提出了一种时间序列先后关系的计算方法,使得事件时序关系估计的精度大大提高。
本领域的普通技术人员将会意识到,这里所述的实施例是为了帮助读者理解本发明的原理,应被理解为本发明的保护范围并不局限于这样的特别陈述和实施例。本领域的普通技术人员可以根据本发明公开的这些技术启示做出各种不脱离本发明实质的其它各种具体变形和组合,这些变形和组合仍然在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!