基于样本组合和深度检测网络的运动目标跟踪方法与流程
本发明属于图像处理技术领域,更进一步涉及运动目标跟踪技术领域中的一种基于样本组合和深度检测网络的运动目标跟踪方法。本发明可用于对剧烈形变、镜头抖动、尺度变化、光照变化等类型的视频进行目标跟踪。
背景技术:
目标跟踪的主要任务是可以实现对输入的视频帧中的目标进行实时的检测,进而实时的确定目标所在位置。随着人们对计算机视觉领域的不断深入认识,目标跟踪在该领域得到广泛应用和发展,目前已经存在大量的跟踪算法来实现运动目标跟踪。但是,由于视频跟踪仅从第一帧图像中完成目标的特征学习,样本特征的匮乏,导致跟踪效果会受到目标遮挡、背景杂乱、外观形变、等客观因素的影响;另外,目标跟踪对准确率和实时性都有较高要求,而现有跟踪方法大多数都是基于图片的检测,虽然能够保证准确率,但检测速度达不到视频检测的需求,准确且实时地实现目标跟踪仍然面临极大挑战。
shaoren,kaiminghe,rossgirshick,jiansun在其发表的论文“fasterr-cnn:towardsreal-timeobjectdetectionwithregionproposalnetwork”(computervisionandpatternrecognition,cvpr,january6,2016)中公开了一种利用卷积神经网络提取图像特征的两阶段的目标检测与定位方法。该方法首先通过区域建议网络(regionproposalnetwork,rpn)生成建议图像区域,其中每张图像生成300个建议区域,把300个建议区域映射在最后一层神经网络中,通过建议区域池化层(roipooling)生成固定尺寸的特征图,利用分类概率(softmax)将特征图进行分类,然后通过边框回归(boundingboxregression)对目标进行定位。该方法虽然实现了对自然图像的定位,但是,该方法仍然存在的不足之处是,将300个建议区域映射在最后一层神经网络中提取特征,消耗大量的时间,导致该方法目标识别速度慢,不能满足实时跟踪运动目标的要求。
中北大学在其申请的专利文献“一种基于深度学习的空中目标跟踪方法”(专利申请号201710676396.5,申请公开号cn107622507a)中公开了一种利用特征网络和判定网络对空中目标进行跟踪的方法。该方法针对目标尺寸变化问题,以图像目标为中心采集不同尺寸的样本训练特征网络;针对目标快速移动造成跟踪失败的问题。该方法存在的不足之处是,该方法通过判定网络对特征网络提取到的目标运动信息进行目标运动轨迹估计,进而预测目标位置,当某一帧图像预测发生偏差时,后续的图像预测会将偏差积累从而导致目标跟踪失败;该方法虽然可以在目标发生尺度变化时实现准确跟踪,但是,该方法仍然存在的不足之处是,由于仅采集不同尺寸的样本训练特征网络,当目标发生剧烈形变时,将会出现判定网络判定错误的现象,使得目标跟踪失败。
技术实现要素:
本发明的目的在于针对上述现有技术的不足,提出一种基于样本组合和深度检测网络的运动目标跟踪方法。
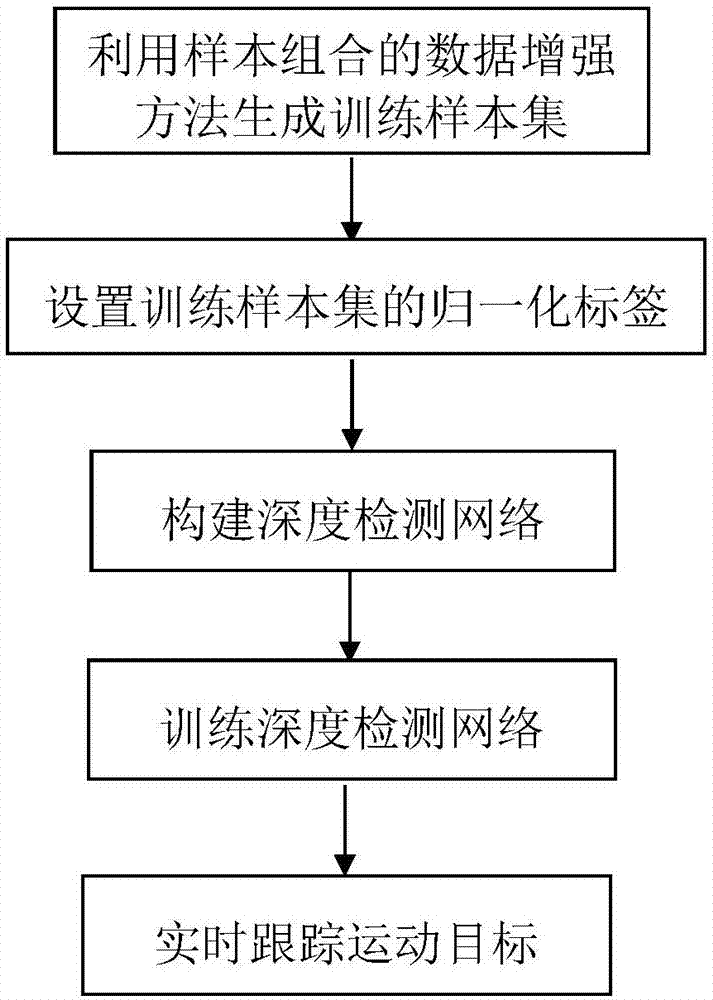
实现本发明目的的思路是:首先,利用样本组合的数据增强方法生成训练样本集,再搭建一个共24层的深度检测网络并设置每层参数,用训练样本集对深度检测网络进行训练,得到训练好的深度检测网络,最后将含运动待跟踪目标的彩色视频图像序列输入到训练好的深度检测网络中,提取目标特征的同时完成对目标位置的检测。
为实现上述目的,本发明的具体步骤如下:
(1)利用样本组合的数据增强方法生成训练样本集:
(1a)输入含有运动待跟踪目标的彩色视频图像序列中的第一帧视频图像;
(1b)在第一帧视频图像的上、下、左、右四个边缘上同时增加零值像素,每次增加5个像素,增加100次生成100幅扩大图像,将扩大后的图像构成小尺度样本集;
(1c)在第一帧视频图像中,以运动待跟踪目标的初始位置的中心为中心、运动待跟踪目标的长宽为长宽确定一个矩形框,将该矩形框框内的图像作为初始目标图像;
(1d)利用9宫格方式,将初始目标图像均匀切割成9个小图像,随机打乱9个小图像的排列顺序,得到500幅3*3样本构成组合样本集;
(1e)在初始目标图像的上、下、左、右四个边缘上同时增加图像像素,每次增加5个像素,增加100次生成100幅图像,将100幅新的图像构成大尺度样本集;
(1f)将小尺度样本集、组合样本集、大尺度样本集构成训练样本集;
(2)设置训练样本集的归一化标签:
(2a)利用目标中心坐标归一化公式,计算每个初始目标图像的中心像素坐标值归一化值;
(2b)用初始目标图像的宽度除以训练样本图像的宽度,得到宽度归一化值,用初始目标图像的高度除以训练样本图像的高度,得到高度归一化值;
(2c)将中心像素坐标值归一化值、高度归一化值、宽度归一化值作为训练样本集的归一化标签写入文件;
(3)构建深度检测网络:
搭建一个24层的深度检测网络,并设置每层参数;
(4)训练深度检测网络:
(4a)将训练样本集输入到深度检测网络中,提取每个样本中每个初始目标图像的特征,将所有特征组成图像特征图,深度检测网络最后一层输出5个13×13的特征图;
(4b)以13×13图像特征图的特征点为中心,构建5个宽高比例分别为0.57:0.67、1.87:2.06、3.33:5.47、7.88:3.51、9.77:9.16的备选框,用备选框中心点坐标值除以13作为备选框的中心坐标归一化参数,用备选框宽高比值作为备选框的宽高归一化参数;
(4c)利用置信度公式,计算运动待跟踪目标的中心点落入每个备选框中的置信度值;
(4d)利用误差公式,计算每个备选框的参数值与标签文件中的真实值之间的误差值之和;
(4e)利用随机梯度下降法,更新深度检测网络卷积层的每一个节点的权值,得到训练好的深度检测网络;
(5)实时跟踪运动目标:
将含运动待跟踪目标的彩色视频图像序列依次输入到训练好的深度检测网络中,用置信度值最高的备选框的参数作为跟踪目标的位置输出。
本发明与现有的技术相比具有以下优点:
第一,由于本发明利用样本组合的数据增强方法生成训练样本集,克服了现有技术中训练样本集仅含有运动待跟踪目标发生尺度变化的样本,当运动待跟踪目标产生较大程度形变时,无法准确跟踪目标的问题,使得本发明能够在运动待跟踪目标产生较大形变时,更准确地跟踪目标。
第二,由于本发明使用深度检测网络用于运动目标跟踪,在特征提取的同时直接对跟踪目标的位置进行预测,缩短了目标检测时间,克服了现有技术中将目标特征提取和目标位置预测分步执行消耗大量时间的问题,使得本发明具有目标识别速度快的优点。
附图说明
图1为本发明的流程图;
图2为本发明的仿真图。
具体实施方式
下面结合附图对本发明做进一步的描述。
参照附图1,对本发明的具体步骤做进一步的描述。
步骤1,利用样本组合的数据增强方法生成训练样本集。
输入含有运动待跟踪目标的彩色视频图像序列中的第一帧视频图像。
在第一帧视频图像的上、下、左、右四个边缘上同时增加零值像素,每次增加5个像素,增加100次生成100幅扩大图像,将扩大后的图像构成小尺度样本集。
在第一帧视频图像中,以运动待跟踪目标的初始位置的中心为中心、运动待跟踪目标的长宽为长宽确定一个矩形框,将该矩形框框内的图像作为初始目标图像。
利用9宫格方式,将初始目标图像均匀切割成9个小图像,随机打乱9个小图像的排列顺序,得到500幅3*3样本构成组合样本集。
所述的9宫格方式是指,用四条相互交叉垂直的直线将初始目标图像均匀的分成9等分,得到9个小图像。
在初始目标图像的上、下、左、右四个边缘上同时增加图像像素,每次增加5个像素,增加100次生成100幅图像,将100幅新的图像构成大尺度样本集。
将小尺度样本集、组合样本集、大尺度样本集构成训练样本集。
步骤2,设置训练样本集的归一化标签。
利用目标中心坐标归一化公式,计算每个初始目标图像的中心像素坐标值归一化值。
所述的目标中心坐标归一化公式如下:
x=(a+0.5×w)/m
y=(b+0.5×h)/n
其中,x表示初始目标图像的中心像素坐标值归一化后的横坐标值,a表示初始目标图像左上角第一个像素的横坐标值,w表示初始目标图像第一行像素的个数,m表示训练样本图像第一行像素的个数,y表示初始目标图像的中心像素坐标值归一化后的纵坐标值,b表示初始目标图像左上角第一个像素的纵坐标值,h表示初始目标图像第一列像素的个数,n表示训练样本图像第一列像素的个数。
用初始目标图像的宽度除以训练样本图像的宽度,得到宽度归一化值,用初始目标图像的高度除以训练样本图像的高度,得到高度归一化值。
将中心像素坐标值归一化值、高度归一化值、宽度归一化值作为训练样本集的归一化标签写入文件。
步骤3,构建深度检测网络。
搭建一个24层的深度检测网络,并设置每层参数。
所述的24层深度检测网络中各层的内核参数如下:
将深度检测网络的第1层卷积层的特征映射图的总数设置为32个,卷积核的尺度设置为3×3个节点,步长为1,激活函数为relu函数。
将深度检测网络的第3层卷积层的特征映射图的总数设置为64个,卷积核的尺度设置为3×3个节点,步长为1,激活函数为relu函数。
将深度检测网络的第5,7层卷积层的特征映射图的总数设置为128个,卷积核的尺度设置为3×3个节点,步长为1,激活函数为relu函数。
将深度检测网络的第9,11层卷积层的特征映射图的总数设置为256个,卷积核的尺度设置为3×3个节点,步长为1,激活函数为relu函数。
将深度检测网络的第10层卷积层的特征映射图的总数设置为128个,卷积核的尺度设置为1×1个节点,步长为1,激活函数为relu函数。
将深度检测网络的第13,15,17层卷积层的特征映射图的总数设置为512个,卷积核的尺度设置为3×3个节点,步长为1,激活函数为relu函数。
将深度检测网络的第14,16层卷积层的特征映射图的总数设置为256个,卷积核的尺度设置为1×1个节点,步长为1,激活函数为relu函数。
将深度检测网络的第19,21,23层卷积层的特征映射图的总数设置为1024个,卷积核的尺度设置为3×3个节点,步长为1,激活函数为relu函数。
将深度检测网络的第20,22层卷积层的特征映射图的总数设置为512个,卷积核的尺度设置为1×1个节点,步长为1,激活函数为relu函数。
将深度检测网络的第24层卷积层的特征映射图的总数设置为845个,卷积核的尺度设置为1×1个节点,步长为1,激活函数为softmax函数。
步骤4,训练深度检测网络。
将训练样本集输入到深度检测网络中,通过深度检测网络搭建的19层卷积层,对输入的训练样本集进行19次卷积操作,提取每个样本中每个初始目标图像的特征,将所有特征构成图像特征图。
通过深度检测网络搭建的5层池化层,对图像特征图进行5次池化操作得到13×13的特征图,深度检测网络最后一层含有5个卷积核的卷积层输出5个13×13的特征图。
以13×13图像特征图的特征点为中心,构建5个宽高比例分别为0.57:0.67、1.87:2.06、3.33:5.47、7.88:3.51、9.77:9.16的备选框,用备选框中心点坐标值除以13作为备选框的中心坐标归一化参数,用备选框宽高比值作为备选框的宽高归一化参数。
利用置信度公式,计算运动待跟踪目标的中心点落入每个备选框中的置信度值。
所述的置信度公式如下:
其中,cv表示运动待跟踪目标的中心点落入第v个备选框中的置信度值,e表示以自然常数为底的指数操作,zr表示图像特征图中第r个特征值,∑表示求和操作,ares表示求面积操作,b表示运动待跟踪目标矩形框的面积,∩表示交集符号,a表示备选框的面积,∪表示并集符号。
利用误差公式,计算每个备选框的参数值与标签文件中的真实值之间的误差值之和。
所述的误差公式如下:
其中,l表示每个备选框的参数值与标签文件中的真实值之间的误差值之和,ci表示置信度值大于0.8的第i个备选框的置信度值,dj表示置信度值小于0.8的第j个备选框的置信度值,xα表示置信度值大于0.8的第α个备选框中心点的横坐标值,x′表示初始目标图像的中心像素的横坐标值,yε表示置信度值大于0.8的第ε个备选框中心点的纵坐标值,y′表示初始目标图像的中心像素的纵坐标值,
利用随机梯度下降法,更新深度检测网络卷积层的每一个节点的权值,得到训练好的深度检测网络。
所述的随机梯度下降法步骤如下:
第1步,在(0,0.1)范围内随机选一个数,用该数作为深度检测网络中每个节点的初始权值。
第2步,将每个节点的初始权值作为第一次迭代过程中深度检测网络中每个节点的当前权值。
第3步,从训练样本集中,随机选取2n个样本图像在深度检测网络中正向传播,其中3≤n≤7,深度检测网络的输出层输出样本图像的备选框的参数值。
第4步,用每个备选框的参数值与标签文件中的真实值之间的误差值之和,对深度检测网络中每一个节点的当前权值求偏导,得到深度检测网络中每个节点当前权值的梯度值。
第5步,按照下式,计算深度检测网络中每个节点更新后的权值。
其中,
第6步,判断每个备选框的参数值与标签文件中的真实值之间的误差值之和是否小于0.5,若是,则得到训练好的深度检测网络中,否则,将每个节点更新后的权值作为当前权值后执行第三步。
步骤5,实时跟踪运动目标。
将含运动待跟踪目标的彩色视频图像序列依次输入到训练好的深度检测网络中,用置信度值最高的备选框的参数作为跟踪目标的位置输出。
下面结合仿真实验对本发明的效果做进一步说明。
1.仿真实验条件:
本发明仿真实验的硬件测试平台是:cpu为intelcorei5-6500,主频为3.2ghz,内存8gb,gpu为nvidiatitanxp;软件平台是:ubuntu16.04lts,64位操作系统,python2.7.1。
2.仿真内容仿真结果分析:
本发明的仿真实验是使用本发明的方法,对从objecttrackingbenchmark2015数据库中采集的一段两名女子一起走过人行道的视频图像序列进行仿真实验,该视频图像序列共有140帧视频图像,本发明的仿真实验的结果如图(2)所示。
图2(a)为本发明仿真实验采集的视频图像序列的第1帧图像,图2(a)中实线矩形框表示待跟踪目标的初始位置。
图2(b)为本发明仿真实验中,对采集的视频图像序列,进行目标跟踪的一帧待跟踪目标,发生外观形变时的视频图像的跟踪结果图。该图中两名女子为待跟踪目标与图2(a)中的待跟踪目标相比,发生了外观形变。利用深度检测网络对该视频图像提取特征并构建备选框,计算待跟踪目标落入备选框的置信度值,基于置信度值的最大值对待跟踪目标的位置进行预测,将预测后的位置作为当前帧视频图像中待跟踪目标的位置。图2(b)中实线矩形框标注的是待跟踪目标的位置,该图像的目标检测消耗时间为0.08秒。
图2(c)为本发明仿真实验中,对采集的视频图像序列,进行目标跟踪的一帧待跟踪目标,发生外观形变和光照变化时的视频图像的跟踪结果图。该图中两名女子为待跟踪目标与图2(a)中的待跟踪目标相比,发生了外观形变和光照增强。利用深度检测网络对该视频图像提取特征并构建备选框,计算待跟踪目标落入备选框的置信度值,基于置信度值的最大值对待跟踪目标的位置进行预测,将预测后的位置作为当前帧视频图像中待跟踪目标的位置。图2(c)中实线矩形框标注的是待跟踪目标的位置,该图像的目标检测消耗时间为0.086秒。
整个仿真实验目标跟踪消耗时间2秒,目标检测速度为70帧/秒。由图2(b)和图2(c)可以看出,图中的实线矩形框标注的目标与图2(a)中实线矩形框标注的目标一致,说明本发明能够在视频图像中待跟踪目标产生外观形变、光照变化时,快速、准确地跟踪目标。
- 还没有人留言评论。精彩留言会获得点赞!