一种基于多源信息融合的手语识别方法与流程
本发明属于计算机科学时频信号处理和循环神经网络模型构建技术领域,尤其涉及到一种基于多源信息融合的手语识别方法。
背景技术:
聋哑人是不容争议的需要得到社会关注的弱势群体。如今的聋哑人沟通手段大多数借助手语,这确实为聋哑人与聋哑人,聋哑人与懂得手语的人之间搭起了沟通的桥梁。但大多数普通人并不熟悉手语,也就造成了大多数人无法和聋哑人正常交流,这在一定程度上降低了社会对聋哑人群体的关注程度,甚至造成了对聋哑人群体的歧视。因此我们团队萌生了帮助聋哑人与不懂得手语的多数人沟通的想法。
而目前的一项热点技术:可穿戴技术,吸引了我们的注意。可穿戴技术主要是指探索创造能直接穿在身上、或是整合进用户的衣服或配件的设备的科学技术。利用该技术可以把多媒体、传感器和无线通信等技术嵌入人们的衣着中,大大为人们提供便利。
聋哑人群与不懂得手语的多数人沟通急切的需求与可穿戴技术的无线、便利、益于集成等特性相结合,启发了我们开发一款聋哑人群能够独立使用的、具有完善功能的、且能被市场普遍接受的手语识别系统。
在传统实现手语识别方法中有:基于传感感器的数据手套识别方法、基于摄像头的图像识别方法、基于雷达发射器的雷达波反射识别方法、基于ppg的光线反射识别方法,以上几种手语识别方法存在各种不足,有如下缺陷:
1)数据手套过于笨重,便携性差,同时会引起过多的关注,从而造成失语者的心理压力;
2)手势间的遮挡使得很难精确识别手指变化,佩戴者无法在较暗的场景(夜晚,室内光线不足)使用,对手部的准确检测跟踪切割较为困难,限制了手语识别的实时性;
3)距离太短,变化太小,无论是可移动方式还是不可移动方式识别,均难以精确检测,同时便携性很差;
4)难以保证手指语和手势语识别的完整性,不能兼顾粗粒度和细粒度手语识别的结合。
由此,一种结合多传感器融合、循环神经网络构建、实时手语翻译、兼顾粗粒度和细粒度手语识别方法显得极其重要。
技术实现要素:
本发明针对现有的手语识别方法的不足,提供了一种基于多源信息融合的手语识别方案,该方案目标是通过一种可穿戴设备来实现手语-语音的交互过程。系统应具有良好的可扩展性,能够通过对手语的识别从而实现语音与手势的交互以及信号与手势的交互。
本发明的技术方案为一种基于多源信息融合的手语识别方法,包含以下4个步骤:
一种基于多源信息融合的手语识别方法,其特征在于包含以下步骤:
步骤1,通过8轴表面肌肉电信号传感器semg和9轴惯性测量单元imu来收集手语动作的原始信号,并通过蓝牙传输数据;
步骤2,通过数据预处理算法对原始信号进行去噪和特征提取,并处理成神经网络的输入数据格式;
步骤3,构建双向双层lstm神经网络,并训练保存模型;
步骤4,将模型移植到手机上,实时切割semg数据和imu数据,用开源语言库,将动作翻译成相应声音。
在上述的一种基于多源信息融合的手语识别方法,步骤1收集双手的semg信号数据和imu数据,共计42维数据;
在上述的一种基于多源信息融合的手语识别方法,所述步骤2中,使用emg信号强度有助于在多传感器系统中实现数据分割,包括:
步骤2.1、基于多通道emg信号用于确定活动段的起始点和终点,将8通道semg信号做算术平均,之后再做db12小波变换降噪,具体基于以下公式:
其中c为信道的索引,nc为通道数。
其中a为尺度,τ为平移量,尺度对应于频率(反比),平移量τ对应于时间。
步骤2.2、后设置阈值进行切割,使用两个阈值检测活动段,起始和偏移阈值。并且偏移阈值低于起始阈值。当emg(t)高于起始阈值时,活动段开始,直到规定时间段内的所有样本都低于偏移阈值。
在上述的一种基于多源信息融合的手语识别方法,所述步骤3中,建议以rnn为模型实现手势块的识别,循环神经网络模型包括
inputlayer层:将已经预处理好的数据转换成符合神经网络的输入格式,为512*24的一张图,并输入神经网络;
layer1层:双向rnn,神经网络单元为lstm
layer2层:双向rnn,神经网络单元为lstm;
outputlayer层:为单词lable的输出。
在上述的一种基于多源信息融合的手语识别方法,所述步骤3中,进行训练保存模型的具体方法是:构建双向双层lstm神经网络,将经过数据预处理的数据传进搭建好的神经网络结构,经训练结束后保存ckpt模型到本地,备后续使用。
在上述的一种基于多源信息融合的手语识别方法,步骤4所述的实时识别方法包括:
步骤4.1、实时地获取传感器数据,将8通道semg信号做算术平均,之后再做实时的db12小波变换降噪;
步骤4.2、设置阈值进行活动识别,使用两个阈值检测活动段,起始和偏移阈值。通常,偏移阈值低于起始阈值。当emg(t)高于起始阈值时,活动段开始,直到规定时间段内的所有样本都低于偏移阈值。用semg数据的取值结果同步的取出相应的imu数据,送入手机中存储的训练好的网络,用以输出对应的label的词语;
步骤4.3、根据词语的序号传入构建好的有限状态自动机内,更新自动机状态,最后将其组成为一个完整可行的句子,并调用开源语音库将其翻译成声音。
本发明与现有的技术相比优点在于:通过以上步骤,利用多传感器融合方案可以保证手语识别的精度。其中双手手语识别可以保证日常手语的完整性与可用性,并且,手指语识别和手势语的结合更能保证手语识别的完整性,从而兼顾了细粒度的手语识别和粗粒度的手语识别。相比于数据手套、图像识别、声波识别的实现方式,我们的方案更加轻便、功耗低、移动性强、应用场合不受限、识别率高、适合推广。
附图说明
图1是本发明的总体实现方案图。
图2是本发明的系统架构图。
图3是本发明的循环神经网络模型架构图。
具体实施方式
本发明主要基于多传感器融合技术,时频信号处理技术,循环神经网络技术,考虑到双手手语的完整性问题和细粒度手指语识别与粗粒度手势语识别问题,我们利用多传感器融合技术与神经网络相结合,来提高识别精度,提出的一种基于多源信息融合的多传感器融合手语识别系统。本系统充分考虑了手语的完整性问题,便携性问题,实时问题,将深度学习应用到手语识别系统上来,使得该系统更具现实意义。
1.实现方案:
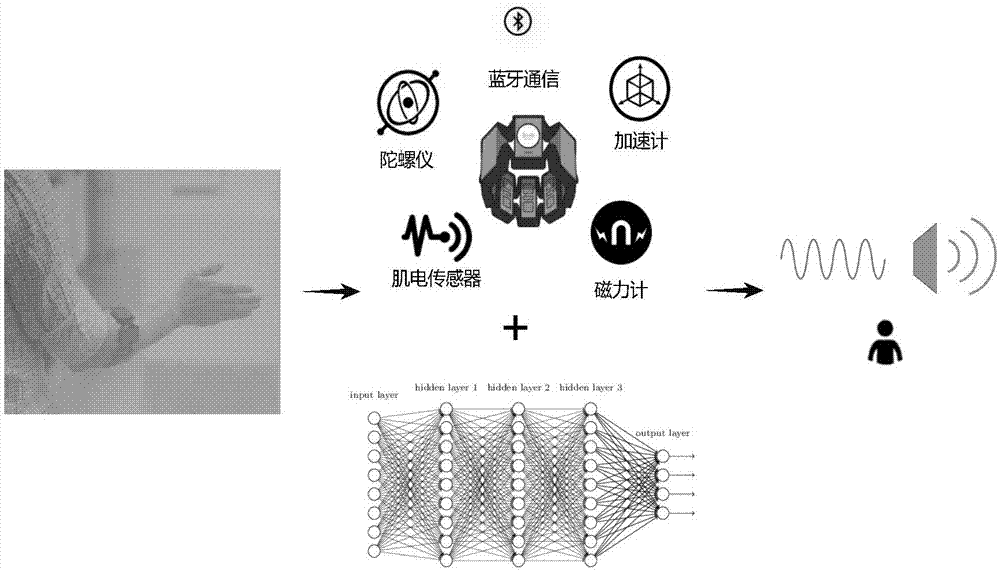
本系统的实现方案图1所示,具体结构可以分成三部分:手语信号收集、模型识别、实时翻译。
双手手语信号收集包括:肌电传感器信号,加速计、陀螺仪、磁力计信号,和四元数。
其中模型识别又可以分成两个部分,分别是数据预处理和循环神经网络模型构建。
数据预处理又可以分为降噪和特征提取。
实时翻译可以分为实时降噪,特征提取,实时切割,以及有限状态自动机这四个部分。
2.系统架构:
该系统的系统架构描述如图2所示,本结构可以分为两层,离线模型构建和实时模型识别,其中离线模型构建又可以分成三个部分,分别是数据收集、数据预处理和循环神经网络模型构建。这三部分的作用分别是:
1)数据收集:包括8轴表面肌肉电信号传感器(semg)信号和9轴(包括3轴加速计、3轴陀螺仪、3轴磁力计)惯性测量单元(imu)信号,并构建双手数据集;
2)数据预处理:在手势动作过程中所记录的多通道信号被称为活动段。手势识别的智能处理需要从输入信号的连续流中自动确定活动段的起始点和结束点。手势数据分割的过程由于运动的原因而难以实现。肌电图信号水平直接表示肌肉活动水平。当手部动作从一个动作切换到另一个动作时,相应的肌肉放松一段时间,肌电信号的振幅在运动的过程中暂时非常低。因此,使用emg信号强度有助于在多传感器系统中实现数据分割。在我们的方法中,只有多通道emg信号用于确定活动段的起始点和终点。将8通道semg信号做算术平均,之后再做db12小波变换降噪,具体做法如下:
①
其中c为信道的索引,nc为通道数。
②
其中a为尺度,τ为平移量,尺度对应于频率(反比),平移量τ对
应于时间。
③之后设置阈值进行切割,使用两个阈值检测活动段,起始和偏移阈值。通常,偏移阈值低于起始阈值。当emg(t)高于起始阈值时,活动段开始,直到规定时间段内的所有样本都低于偏移阈值。较高的起始阈值有助于避免错误的手势检测,而较低的偏移阈值是为了防止活动段的碎片化,因为在手势执行过程中,ema(t)可能会在起始阈值附近振动。
3)循环神经网络模型构建:对于手势识别。我们主要是需要一个强健的分类器用于对于特定数据集的分类,且能够实时的向模型中加入新的数据集进行训练,对于手势动作这样一个时序动作,所以我们考虑以rnn为模型实现手势块的识别。
3.循环神经网络模型:
该系统的循环神经网络模型构建如图3所示:
一共分为inputlayer、layer1、layer2、outputlayer四部分,这四部分的作用分别是:
(1)inputlayer:将已经预处理好的数据转换成符合神经网络的输入格式,为512*24的一张图,并输入神经网络;
(2)layer1和layer2均是双向rnn,神经网络单元为lstm;
(3)outputlayer为单词lable的输出。
本文中所描述的具体实施例仅仅是对本发明精神作举例说明。本发明所属技术领域的技术人员可以对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,但并不会偏离本发明的精神或者超越所附权利要求书所定义的范围。
- 还没有人留言评论。精彩留言会获得点赞!