一种基于医疗美容场景的客户违约概率预测方法与流程
本发明是基于女性群体在医疗美容分期信贷申请过程填写的个人基础信息、设备信息,结合运营商、第三方平台征信、电商等数据,运用相关性特征挖掘技术,通过xgboost算法提供一种基于医疗美容场景的客户违约概率预测方法。
背景技术:
有医美服务和消费分期需求的丽人群体、力求降低用户使用成本及获客成本的医疗美容机构和依托医美机构推荐来拓展其分期业务的消费金融平台,三者共同构成了医美消费金融产业生态圈。在医疗美容市场远未达到饱和、正处于黄金发展期的同时,医美分期面临的头号难题仍然是反欺诈。而仅基于借款申请用户提交的信息预测违约概率是远远不够的,我们采用更主动的方式,基于多维度数据包括运营商数据、第三方数据、电商报告等梳理用户人群画像,判断每一笔进件为欺诈或逾期风险的可能性。依托高可用分布式大数据集群平台,进行实时的数据采集、处理与计算,快速获取丽人用户各类历史信息,结合机器学习中强大的集成学习算法,精准预判每个丽人用户的信用状况,解决了该群体信用评估难的问题。大数据规模、高维度、实时性与精准评分,成为我们的最大优势。
技术实现要素:
本发明的目的是为解决丽人用户信用评估准确性的问题,提供一种基于医疗美容场景的客户违约概率预测方法。本发明通过采集用户基础信息、运营商信息以及第三方数据信息(包括风险评分、多头借贷、终端使用情况等等),对可能影响其违约的特征进行提取、转换、定性和量化计算,并结合xgboost算法,分步骤构建违约模型并进行实例验证。
本发明解决其技术问题所采用的技术方案包括如下步骤:
步骤1、用户违约因素的确认。
步骤2、构建模型进行迭代及运算。
步骤3、效果验证。
步骤1所述用户违约因素的确认,具体实现如下:
将影响用户逾期的特征分为两大类:基础信息和第三方数据信息;
1.1基础信息
基础信息包括申请人基本数据、申请设备数据以及衍生数据;申请人基本数据是指用户在申请贷款过程中填写的个人信息,包括年龄、申请项目金额、手术项目类型、医疗机构信息、借款金额、借款期限、申请地、户籍地;申请设备数据包括申请设备名称、系统、版本、设备id;衍生数据包括申请人户籍地gdp排名、申请地gpd排名、申请地与户籍地是否一致。
1.2第三方数据信息
①用户在其他借贷平台的申请借贷信息,包括个体在其他多个平台提出的借贷申请或是已借款的相关信息;
②用户常用app活跃度信息;
③用户各类信用评分信息;
基于第三方数据公司获取用户群体在其它多个平台的借贷申请或已借款的相关信息,包括个人信息核查、不良信息扫描、多平台借贷申请、信贷逾期信息和司法不良记录。
基于用户申请时使用的终端设备,借助第三方平台获取终端设备相关信息。
基于用户申请注册用的手机号码,借助第三方平台获取手机号运营商信息。
基于用户申请注册用的姓名、手机和身份证,借助第三方平台获取用户的信用评分信息。
步骤2所述的构建模型进行迭代及运算,具体实现如下:
2-1.特征工程:
①清洗异常数据、异常样本:若采集的数据样本60%以上的特征数据为空,则剔除该样本;获取新的数据集ⅰ;
所述的数据样本是指步骤中采集到的基础信息或通过第三方采集到的数据信息;
②针对数据集ⅰ中的缺失值,采用随机森林插补法填充,获取数据集ⅱ;
③特征筛选:首先将数据集ⅱ中的所有数据进行iv值计算,将其中iv值小于设定值的数据进行删除,获得数据集ⅲ;
④基于随机森林学习模型的特征排序(modelbasedranking),对数据集ⅲ进行排序,获取数据集ⅳ,对数据集ⅳ中特征重要性小于0.01的特征删除,获取数据集ⅴ;
⑤最后利用降噪自编码器对数据集ⅴ中的数据提取隐含特征;
2-2.构建模型
2-2-1.模型训练说明
①.基于原始特征和特征工程步成的隐含特征,采用多种特征组合构建模型,通过模型参数的调整最终选择最优模型;
所述的原始特征包括基础信息和第三方信息中的特征;
②.将所有样本的70%作为模型的训练集,用于模型训练;30%作为模型的测试集,用于评估模型的训练结果;
③.利用xgboost模型对样本进行训练,通过不断的迭代调参,得到模型的roc曲线、auc值和特征重要性;
2-2-2.建模流程:
在booster模型上选择效果更佳的树模型,学习目标上采用二分类的逻辑回归问题,损失函数如下:
公式说明:
yi—表示用户实际是否逾期。
2.根据权利要求1所述的一种基于医疗美容场景的客户违约概率预测方法,其特征在于步骤3所述的效果验证,具体实现如下:
3-1.模型采用的评估指标
采用了最常见的auc和ks值作为模型的评估指标;
3-1-1.auc值
auc值其实是roc曲线下的面积,roc曲线横轴是fpr(假阳率),纵轴是tpr(正阳率),这2指标的计算公式如下:
fpr=fp/(fp+tn)
tpr=tp/(tp+fn)
其中:
tp:预测类别是p(正例),真实类别也是p
fn:预测类别是n,真实类别是p
fp:预测类别是p,真实类别是n(反例)
tn:预测类别是n,真实类别也是n
auc值介于0.1和1之间,auc作为数值能够直观的评价分类器的好坏,值越大越好,计算公式参照如下:
公式说明:
m-正类样本的数目n-负类样本的数据
rank-对预测的score从大到小排序,然后令最大score对应的样本的rank为n,第二大score对应的样本的rank为n-1,以此类推;
3-1-2.ks值
ks(洛伦兹曲线)-用于区分预测正负样本分隔程度的评价指标,计算公式如下:ks=max(tpr-fpr);
3-2.模型验证结果
其主要参数设置如下:
1.learning_rate(学习率):0.09,
2.max_depth(最大树深):3,
3.n_estimators(迭代轮数):150,
4.gamma(用于控制是否后剪枝的参数):5,
5.reg_lambda(控制模型l2正则化项参数):5,
6.reg_alpha(控制模型l1正则化项参数):5,
7.subsample(训练模型的子样本占整个样本集合的比例):0.8,
8.colsample_bytree(列采样):0.8
模型表现如下:
本发明有益效果如下:
本发明依托分布式大数据集群平台,进行实时的数据采集、处理与计算,快速获取丽人客户各类历史信息,结合机器学习中强大的集成学习算法,精准预判每个丽人客户的信用状况,解决了该群体信用评估难的问题。本发明中的大数据规模、高维度、实时性与精准评分是本发明最大优势。
附图说明
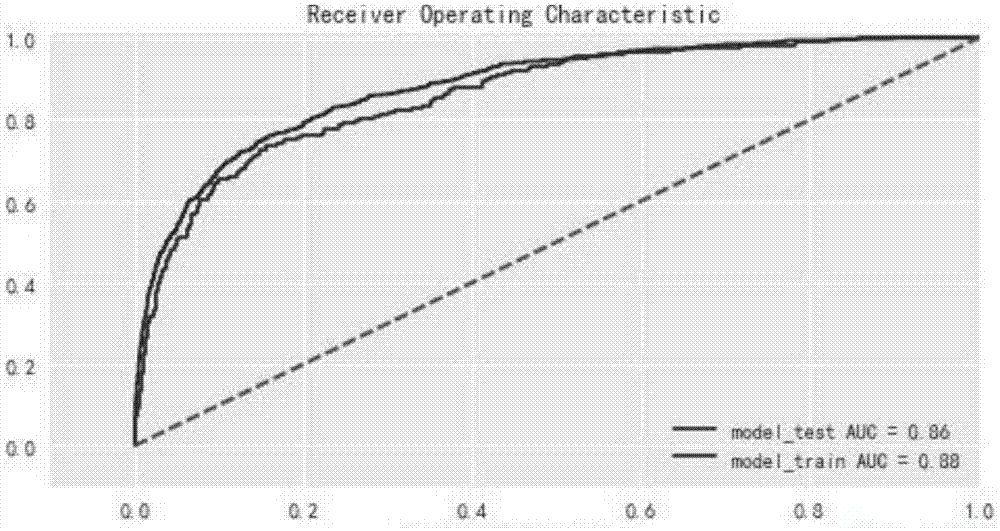
图1为本发明模型roc曲线;
图2为本发明模型分位图;
图3为本发明正负样本分布图;
具体实施方式
下面结合附图和实施例对本发明作进一步说明。
一种基于医疗美容场景的客户违约概率预测方法,包括如下步骤:
步骤1、用户违约因素的确认。
步骤2、构建模型进行迭代及运算。
步骤3、效果验证。
步骤1所述用户违约因素的确认,具体实现如下:
将影响用户逾期的特征大致分为两大类,基础信息和第三方数据信息。
1.1基础信息
基础信息包括申请人基本数据、申请设备数据以及衍生数据;申请人基本数据是指用户在申请贷款过程中填写的个人信息,包括年龄、申请项目金额、手术项目类型、医疗机构信息、借款金额、借款期限、申请地、户籍地等;申请设备数据包括申请设备名称、系统、版本、设备id等;衍生数据包括申请人户籍地gdp排名、申请地gpd排名、申请地与户籍地是否一致数据等,具体参看表1。其中身份证户籍地区、申请地gdp情况是根据该地区于2017年人均gdp的全国排名,将此排名作为特征项加入模型中。
表1基础信息
1.3第三方数据信息
①用户在其他借贷平台的申请借贷信息,包括个体在其他多个平台提出的借贷申请或是已借款的相关信息。
②用户常用app活跃度信息。
③用户的各类信用评分信息。
基于第三方数据公司服务的数千家互联网金融机构,获取到用户群体在其它多个平台的借贷申请或已借款的相关信息,包括个人信息核查、不良信息扫描、多平台借贷申请、信贷逾期信息和司法不良记录等,从而有效甄别高风险人群,其具体内容如表2:
表2第三方借贷信息
基于用户申请时使用的终端设备,借助第三方平台获取终端设备相关信息,具体内容如表3:
表3第三方设备活跃度信息
基于用户申请注册用的手机号码,借助第三方平台获取手机号运营商信息,具体内容如表4:
表4第三方运营商数据信息
基于用户申请注册用的姓名、手机和身份证,借助第三方平台获取的用户的信用信息,具体内容如表5:
表5第三方数据信用信息
第三方信息的获取进一步拓宽了丽人用户的属性维度,提高违约模型的准确度和识别度。
步骤2构建模型进行迭代及运算,具体实现如下:
2-1.特征工程:
①清洗异常数据、异常样本:若采集的数据样本60%以上的特征数据为空,则剔除该样本;获取新的数据集ⅰ;
所述的数据样本是指步骤中采集到的基础信息或通过第三方采集到的数据信息。
②针对数据集ⅰ中的缺失值,采用随机森林插补法填充,获取数据集ⅱ;
③特征筛选:首先将数据集ⅱ中的所有数据进行iv值计算,将其中iv值小于设定值的数据进行删除,获得数据集ⅲ;
④基于随机森林学习模型的特征排序(modelbasedranking),对数据集ⅲ进行排序,获取数据集ⅳ,对数据集ⅳ中特征重要性小于0.01的特征删除,获取数据集ⅴ;
⑤最后利用降噪自编码器对数据集ⅴ中的数据提取隐含特征,隐含特征为20个维度,原始输入为59个维度。
每次用以信用评分模型构建的样本都是基于已经满足之前信用评分审核标准的用户,对于审核不通过的用户,其特征信息都无法获取。自编码器是一种很好的无标签样本特征提取技术,本项目里使用该技术利用全量的申请用户提取共有的模式。降噪自编码器是一种自监督的模型可理解为一个试图去还原其原始输入的系统。
自编码器可以恢复原始信号的表达,但并不是最好的,能够对含有噪声的信息进行编码、解码,并恢复真正的原始数据,这样的特征才是好的,所以我们在原始数据基础上加入高斯噪声,对某些空缺数据直接填充为均值,然后再进行编码、解码,监督训练的误差为:
公式说明:n-每批次训练的样本量
yi-原始输入
2-2.构建模型
2-2-1.模型训练说明
①.基于原始特征和特征工程步成的隐含特征,本项目采用多种特征组合构建模型,通过模型参数的不同的调整最终选择最优模型。
所述的原始特征包括基础信息和第三方信息中的特征;
②.将所有样本的70%作为模型的训练集,用于模型训练;30%作为模型的测试集,用于评估模型的训练结果。
③.利用xgboost模型对样本进行训练,通过不断的迭代调参,得到模型的roc曲线、auc值和特征重要性。
2-2-2.建模流程:
在booster模型上选择效果更佳的树模型(gbtree),学习目标上采用二分类的逻辑回归问题,损失函数如下:
公式说明:
yi—表示用户实际是否逾期
xgboost算法的全称是extremegradientboosting,其在gbdt算法基础上对boosting算法进行改进。xgboost是gradientboosting算法的高效实现。传统gbdt以cart作为基分类器,特指梯度提升决策树算法,而xgboost还支持线性分类器(gblinear),此时xgboost相当于带l1和l2正则化项的logistic回归(分类问题)或者线性回归(回归问题)。本发明预测用户的逾期概率,属于典型的分类问题,学习目标上采用二分类的逻辑回归。
如图1-3所示,步骤3所述的效果验证,具体实现如下:
3-1.模型采用的评估指标
采用了最常见的auc和ks值作为模型的评估指标。
3-1-1.auc值
auc值其实是roc曲线下的面积,roc曲线横轴是fpr(假阳率),纵轴是tpr(正阳率),这2指标的计算公式如下:
fpr=fp/(fp+tn)
tpr=tp/(tp+fn)
其中:
tp:预测类别是p(正例),真实类别也是p
fn:预测类别是n,真实类别是p
fp:预测类别是p,真实类别是n(反例)
tn:预测类别是n,真实类别也是n
auc值介于0.1和1之间,auc作为数值可以直观的评价分类器的好坏,值越大越好,计算公式可以参照如下:
公式说明:
m-正类样本的数目n-负类样本的数据
rank-对预测的score从大到小排序,然后令最大score对应的sample的rank为n,第二大score对应sample的rank为n-1,以此类推
3-1-2.ks值
ks(洛伦兹曲线)-用于区分预测正负样本分隔程度的评价指标,计算公式如下:ks=max(tpr-fpr)。
3-2.模型验证结果
其主要参数设置如下:
1.learning_rate(学习率):0.09,
2.max_depth(最大树深):3,
3.n_estimators(迭代轮数):150,
4.gamma(用于控制是否后剪枝的参数):5,
5.reg_lambda(控制模型l2正则化项参数):5,
6.reg_alpha(控制模型l1正则化项参数):5,
7.subsample(训练模型的子样本占整个样本集合的比例):0.8,
8.colsample_bytree(列采样):0.8
模型表现如下:
- 还没有人留言评论。精彩留言会获得点赞!