一种基于超级计算机的流体机械仿真程序优化方法与流程
本发明属于计算流体力学与计算机交叉领域,特别涉及一种基于超级计算机的流体机械仿真程序优化方法。
背景技术
神威·太湖之光超级计算机是由国家并行计算机工程技术研究中心自主研发,现安装在国家超级计算无锡中心的超级计算机,峰值性能为125.4pflops,从2016年6月20日至2017年11月31日连续5次获得全球超级计算机500强(top500)榜单第一名。其基于申威sw26010处理器构建,共包含40960块sw26010处理器,每个处理器包含4个核组,每个核组包含1个mpe(managementprocessingelement,简称主核)和64个cpes(computingprocessingelements,简称从核),从核分布在8×8的阵列中。其中主核上的编译器支持c,c++和fortran3种编程语言,而从核上的编译器只支持c与fortran两种编程语言。编译器的不兼容问题使得传统流体机械仿真程序无法直接在从核上运行,无法有效利用神威太湖之光强大的计算能力。
计算流体力学(computationalfluiddynamics,cfd)是一个借助数值计算和计算机科学来求解流体力学的控制方程,模拟客观世界中流体的真实流动,对流体力学问题进行实验分析,介于数学、流体力学和计算机科学之间的交叉学科,在航空、航天、船舶、流体机械等有着重要的应用。作为一个仿真程序,它依据流体流动的基本定律,利用计算机的高速计算能力,刻画流体在空间中的真实流动规律,具有计算密集、控制逻辑复杂、数据量大、大量非线性偏微分方程组求解、仿真花费时间过长等特点。
如何结合神威·太湖之光体系架构与编程特点使流体机械仿真程序充分发挥神威·太湖之光超算平台及其sw26010处理器强大的计算能力一直是高性能研究的主要挑战之一,该优化方法的提出对流体机械仿真程序在国产高性能计算平台高效应用有一定的指导意义。
技术实现要素:
本发明的目的在于提供一种基于超级计算机的流体机械仿真程序优化方法,以解决上述问题。
为实现上述目的,本发明采用以下技术方案:
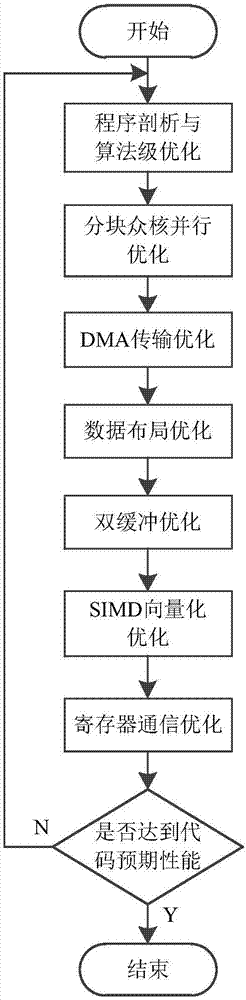
一种基于超级计算机的流体机械仿真程序优化方法,包括以下步骤:
步骤1,利用超级计算机神威·太湖之光超算平台gprof对流体机械仿真程序算法进行剖分,寻找程序算法中符合神威·太湖之光体系结构加速的计算密集型算法部分,并将该部分算法改写为针对神威·太湖之光编程平台的算法;
步骤2,对完成步骤1的流体机械仿真程序中计算密集型部分进行分块众核并行优化,根据基于空间限制、传输效率限制、映射限制、数据量限制四个条件限制的分块规则,将数据根据跨步读取规则与映射规则分发至mpe从核阵列进行计算;
步骤3,对完成步骤2的分块众核并行优化进行dma传输优化:依据步骤2中从核所需的数据,使用dma-intrinsic接口编写dma传输控制程序;
步骤4,对完成步骤3的程序进行数据布局优化,对流体机械仿真程序核心段程序进行变量依赖关系分析,将数据进行拼接或整合;
步骤5,对完成步骤4的程序进行双缓冲优化,将通信与计算重合;
步骤6,对完成步骤5的程序使用神威·太湖之光的向量化部件进行simd向量化优化;
步骤7,对完成步骤6的程序进行寄存器通信优化,同时对程序进行性能分析和代码整理分析,若分析结果低于程序预期性能,或程序经过迭代修改后在设计上有进一步提升的空间,则重复进行步骤1至7,若结果满足预期性能且程序设计,则基于神威·太湖之光体系结构的流体机械仿真程序优化结束。
进一步的,在步骤1中,神威·太湖之光体系结构为基于sw26010处理器构建的超算平台,共包含40960块sw26010处理器,每个处理器包含4个核组,每个核组包含1个mpe和64个cpes,从核分布在8×8的阵列中;神威·太湖之光体系结构的算法为利用sw26010mpe与cpes计算能力的流体机械算法;
基于神威·太湖之光编程平台指神威·太湖之光的编程特点:mpe主核的编译器支持c,c++和fortran3种编程语言,使用时需要引入“athread.h”头文件,cpes从核上的编译器只支持c与fortran两种编程语言,使用时需要引入“slave.h”头文件。
进一步的,在步骤2中,分块众核并行优化包括三个部分:
1)基于空间限制、传输效率、映射限制、数据量限制四个条件的分块规则,空间限制指可配置为ldm(localdatamemory,局部数据存储器)的从核spm(scratchpadmemory,便笺式存储器)空间只有64kb,即ldmsize≤60kb;传输效率限制指当传输数据主存地址为128b对界,且传输量为128b倍数的时候达到dma传输的峰值性能,即在保证主存地址对界的前提下保证blocksize%128==0;映射限制与数据量限制指每次传输的数据量必须保证一次流体机械计算的全部完成;基于数据量限制的从核分配方法如下所示,避免从核无效的满负荷运行,有效降低系统能耗:
其中,datablock表示数据块的总数,core_number表示所需从核数量,core_numberx表示所有可能的数量取值且core_numberx≤64。
分块规则如以下公式表示,其中totalsize表示所需传递的所有数据,slave_number表示所有计算核的核心数目,block表示所需分块的总块数:
2)主存跨步读写规则:跨步的长度为:stride=boundarysize×8byte,其中stride表示跨步的长度,boundarysize表示流体机械仿真程序中三维数组中边界数据层数;每次读写的数据量为
3)从核循环展开的映射规则:在每次从主存向ldm传输数据的时候需要将主存地址映射成为访存映射,使用循环展开的分法,使同一时间步内执行连续的数据块,如以下公式所示,其中bias表示主存地址的偏移量,blockindex表示当前数据块的索引,threadindex表示当前计算从核的线程号;
bias=blockindex×64+threadindex。
进一步的,在步骤3中,dma传输优化使用神威·太湖之光的dma-intrinsic接口单独设置操作属性、传输模式、传输量、跨步大小的dma描述符。
进一步的,在步骤4中,数据布局优化包括对核心段程序变量依赖关系的分析,对相同形式的数组拼接或者合并。
进一步的,在步骤5中,双缓冲优化指在从核64kb的spm中开辟2倍于所传递数据大小的空间用于存放互为缓冲的数据,在通信过程中除了第一轮次的读入与最后一轮次的写出之外,当计算从核核心进行本轮次计算的同时进行上一轮次的读入与下一轮次的写回。
进一步的,在步骤6中,simd向量化优化包括数组对界填充、处理不对界数组、扩展变量替换与循环分裂。
进一步的,在步骤7中,寄存器通信优化指使用寄存器通信的汇编命令,利用c语言的内联汇编语言在sw26010处理器的计算核心上通过阵列中同行/同列核心间的通信。
与现有技术相比,本发明有以下技术效果:
本发明其依次包括了分块众核并行优化、dma传输优化、数据布局优化、双缓冲优化、simd向量化优化、寄存器通信优化,该方法为针对神威·太湖之光超算平台开发、移植或优化流体机械仿真程序的开发人员提供了一种通用的优化方法;分块众核并行优化使用dma-intrinsic接口编写dma传输控制程序,减少dma描述符的冗余设置,提高从核dma传输效率;数据布局优化减少dma通信次数,提高带宽利用效率,缓解多从核多次发起通信请求所导致的竞争;双缓冲优化,将通信与计算重合,提高从核访存效率;使用神威·太湖之光的向量化部件提高流体机械仿真程序的运行效率;实现对神威·太湖之光计算资源的充分利用,提升程序计算性能,缩短仿真花费时间。
附图说明
图1为本发明的流程图。
具体实施方式
以下结合附图对本发明进一步说明:
本发明提出的一种基于超级计算机的流体机械仿真程序优化方法,针对神威·太湖之光超算平台体系结构及其编程特性,结合流体机械仿真程序特点,提出了一套系统可行的优化方案。
请参阅图1,一种基于神威·太湖之光的流体机械仿真程序优化方法,包括以下步骤:步骤1,利用神威·太湖之光国产超算平台提供的gporf等工具对流体机械仿真程序算法进行剖分,寻找程序算法中适合神威·太湖之光体系结构加速的计算密集型算法部分。然后按照神威·太湖之光编程平台的特点,在mpe主核程序中引入“athread.h”头文件,用c语言编写mpe从核计算程序,同时引入“slave.h”头文件,将该计算密集型算法部分改写为基于神威·太湖之光编程平台的算法;
步骤2,对完成步骤1的流体机械仿真程序中计算密集型部分进行分块众核并行优化,首先根据空间限制、传输效率、映射限制、数据量限制四个条件的分块规则计算每次计算所需传递的数据块block,空间限制指可配置为ldm(localdatamemory,局部数据存储器)的从核spm(scratchpadmemory,便笺式存储器)空间只有64kb,即ldmsize≤60k;b传输效率限制指当传输数据主存地址为128b对界,且传输量为128b倍数的时候达到dma传输的峰值性能,即在保证主存地址对界的前提下保证blocksize%128==0;映射限制与数据量限制指每次传输的数据量必须保证一次流体机械计算的全部完成;基于数据量限制的从核分配方法如下所示,避免从核无效的满负荷运行,有效降低系统能耗:
其中,datablock表示数据块的总数,core_number表示所需从核数量,core_numberx表示所有可能的数量取值且core_numberx≤64。
分块规则如一下公式表示,其中totalsize表示所需传递的所有数据,slave_number表示所有计算核的核心数目,block表示所需分块的总块数:
接着,根据主存跨步读写规则算出每次跨步的距离stride,与每次操作dma传递的数据量carrysize:由于在流体机械仿真程序中并行使用了区域分解方法,网格块都存在边界通信的虚拟网格,而计算核函数只需要对网格块的内部数据进行迭代求解,造成输入数据的不连续。但是冗余读入会造成spm的浪费,多次读入会发起过多请求造成带宽争用,因此采用跨步读取的方式进行访存。跨步的长度为:stride=boundarysize×8byte,其中boundarysize表示流体机械仿真程序中三维数组中边界数据层数;每次读写的数据量为
最后,根据从核循环展开的映射规则将计算量展开在cpes从核上:在每次从主存向ldm传输数据的时候需要将主存地址映射成为访存映射,使用循环展开的分法,使同一时间步内执行连续的数据块,如以下公式所示,其中bias表示主存地址的偏移量,blockindex表示当前数据块的索引,threadindex表示当前计算从核的线程号。
bias=blockindex×64+threadindex
充分利用神威·太湖之光计算核心强大的计算能力,提升程序计算性能;
步骤3,对完成步骤2的分块众核并行优化方法进行dma传输优化:依据步骤2中cpes从核所需的数据,使用神威·太湖之光的dma-intrinsic接口单独设置操作属性、传输模式、传输量、跨步大小等dma描述符。减少dma描述符的冗余设置,提高从核dma传输效率;
步骤4,对完成步骤3的程序进行数据布局优化,对流体机械仿真程序核心段程序进行变量依赖关系分析,将数据进行拼接或整合,减少dma通信次数,提高带宽利用效率,缓解多从核多次发起通信请求所导致的竞争。
步骤5,对完成步骤4的程序进行双缓冲优化,在从核64kb的spm中开辟2倍于所传递数据大小的空间用于存放互为缓冲的数据,在通信过程中除了第一轮次的读入与最后一轮次的写出之外,当计算核心(从核)进行本轮次计算的同时可以同时进行上一轮次的读入与下一轮次的写回。将通信与计算重合,提高从核访存效率。
步骤6,对完成步骤5的程序进行simd向量化优化,使用数组对界填充、处理不对界数组、扩展变量替换与循环分裂。使用神威·太湖之光的向量化部件提高流体机械仿真程序的运行效率。
步骤7,对完成步骤6的程序进行寄存器通信优化,使用寄存器通信的汇编命令,利用c语言的内联汇编语言在sw26010处理器的计算核心上通过阵列中同行/同列核心间的通信,减少了从核的冗余访存操作。
完成以上步骤后对程序进行性能分析和代码整理分析,若分析结果低于程序预期性能,或程序经过迭代修改后在设计上有进一步可提升的空间,则重复进行步骤1-7,若结果满足预期性能且程序设计,则基于神威·太湖之光体系结构的流体机械仿真程序优化结束。
- 还没有人留言评论。精彩留言会获得点赞!