泄漏气体浓度分布确定方法、装置、设备及可读存储介质与流程
本发明涉及安全保障
技术领域:
,特别是涉及一种泄漏气体浓度分布确定方法、装置、设备及可读存储介质。
背景技术:
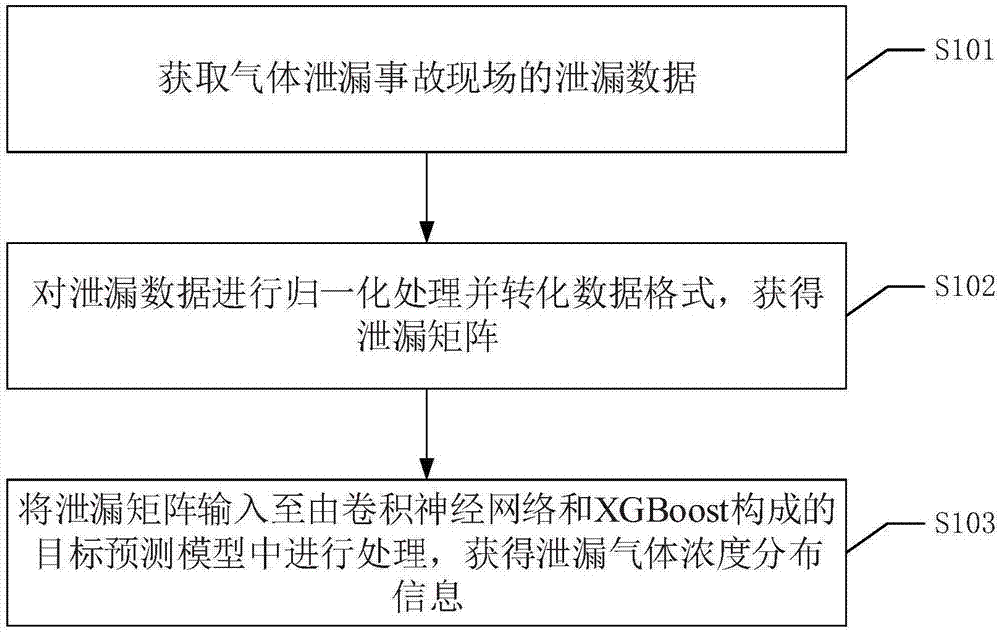
:生物、制药、石化、能源、材料及水厂等行业的生产、运输、储备过程涉及许多气体,而发生气体泄漏往往会破坏环境、或带来人员伤亡、造成较大经济损失。尤其是生物化学危险性重气(气体),一旦发生泄露,会在短时间内迅速扩散,在较大范围导致人员中毒伤亡及环境污染,甚至引发火灾爆炸等一系列的连锁反应。因而,在气体泄露事故发生后,应尽快确定气体泄露波及区域的气体浓度进行确定。为了尽快确定气体浓度波及区域,采用预测方式对气体泄漏波及区域进行预测,以便及时处理。精确的气体扩散浓度实时预测方法对于保障事故波及区域人民生命财产安全和降低环境污染风险都具有重要的意义。但是,目前针对气体泄漏后的浓度预测具有预测精度较低、预测时间长等不利于排除故障的缺陷。综上所述,如何有效地解决在发生气体泄漏时,快速有效地确定浓度分布等问题,是目前本领域技术人员急需解决的技术问题。技术实现要素:本发明的目的是提供一种泄漏气体浓度分布确定方法、装置、设备及可读存储介质,以在发生气体泄漏时,快速有效地确定泄漏气体浓度。为解决上述技术问题,本发明提供如下技术方案:一种泄漏气体浓度分布确定方法,包括:获取气体泄漏事故现场的泄漏数据;其中,所述泄漏数据包括:气象参数、地形参数和释放参数;对所述泄漏数据进行归一化处理并转化数据格式,获得泄漏矩阵;将所述泄漏矩阵输入至由卷积神经网络和xgboost构成的目标预测模型中进行处理,获得泄漏气体浓度分布信息。优选地,将所述泄漏矩阵输入至由卷积神经网络和xgboost构成的目标预测模型中进行处理,获得泄漏气体浓度分布信息,包括:利用卷积神经网络提取所述泄漏矩阵的数据特征;利用所述xgboost对所述数据特征进行回归预测,获得泄漏气体浓度分布信息。优选地,利用所述xgboost对所述数据特征进行回归预测,获得泄漏气体浓度分布信息,包括:利用所述xgboost内部的线性转换,对所述数据特征进行回归预测,获得泄漏气体浓度分布信息。优选地,获得所述目标预测模型的过程,包括:提取卷积神经网络中截止至全连接层的网络结构,并与xgboost相连接,获得初始预设模型;利用预设训练集对所述初始预测模型进行训练,获得目标预测模型。优选地,所述提取卷积神经网络中截止至全连接层的网络结构,并与xgboost相连接,获得初始预设模型,包括:构建卷积神经网络并利用交叉验证法确定所述卷积神经网络结构中的参数值,以及利用预设训练集对所述卷积神经网络进行训练;利用所述交叉验证法确定xgboost的各项参数;提取训练后的卷积神经网络截止至全连接层的网络结构,并与所述xgboost相连接,构成初始预测模型。优选地,所述构建卷积神经网络,包括:构建卷积神经网络,并在所述卷积神经网络中的全连接层与输出之间设置线性回归操作。优选地,在所述利用预设训练集对所述初始预测模型进行训练,获得目标预测模型之前,还包括:获取气体点源释放实验数据;对所述实验数据进行归一化处理,并转换数据格式,获得二维矩阵形式的训练集。一种泄漏气体浓度分布确定装置,包括:泄漏数据获取模块,用于获取气体泄漏事故现场的泄漏数据;其中,所述泄漏数据包括:气象参数、地形参数和释放参数;泄漏矩阵获取模块,用于对所述泄漏数据进行归一化处理并转化数据格式,获得泄漏矩阵;气体浓度分布预测模块,用于将所述泄漏矩阵输入至由卷积神经网络和xgboost构成的目标预测模型中进行处理,获得泄漏气体浓度分布信息。一种泄漏气体浓度分布确定设备,包括:存储器,用于存储计算机程序;处理器,用于执行所述计算机程序时实现上述泄漏气体浓度分布确定方法的步骤。一种可读存储介质,所述可读存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现上述泄漏气体浓度分布确定方法的步骤。应用本发明实施例所提供的方法,获取气体泄漏事故现场的泄漏数据;其中,泄漏数据包括:气象参数、地形参数和释放参数;对泄漏数据进行归一化处理并转化数据格式,获得泄漏矩阵;将泄漏矩阵输入至由卷积神经网络和xgboost构成的目标预测模型中进行处理,获得泄漏气体浓度分布信息。在发生气体泄漏事故时,获取事故现场包括气象参数、地形参数和释放参数的泄漏数据。然后对泄漏数据进行归一化处理,并将归一化处理后的数据转化为矩阵格式,即可获得泄漏矩阵。然后将该泄漏矩阵输入至由卷积神经网络和xgboost构成的目标预测模型中进行处理,即可获得有助于应急救援的泄漏气体浓度分布信息。在对泄漏数据进行处理时,卷积神经网络能够对影响泄漏气体扩散的泄漏参数进行深层次的分析,从而提取数据间深层次的联系,即提取更具有表现力的数据特征。然后xgboost可合理利用数据特征进行快速回归预测处理,最终可获得泄漏气体浓度分布信息。如此,便可提升气体泄漏后浓度分布信息的预测效率和准确率,进一步加快气体泄漏事故处理速度,降低气体泄漏带来的危害。相应地,本发明实施例还提供了与上述泄漏气体浓度分布确定方法相对应的泄漏气体浓度分布确定装置、设备和可读存储介质,具有上述技术效果,在此不再赘述。附图说明为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。图1为本发明实施例中一种泄漏气体浓度分布确定方法的实施流程图;图2为本发明实施例中的数据格式转换示意图;图3为本发明实施例中获得预测有毒重气泄漏浓度详细的模型的实施流程图;图4为本发明实施例中一种目标预测模型的结构示意图;图5为prairiegrass实验中的实际浓度图;图6为本发明实施例所提供的目标预测模型预测的浓度值;图7为本发明实施例中一种泄漏气体浓度分布确定装置的结构示意图;图8为本发明实施例中一种泄漏气体浓度分布确定设备的结构示意图;图9为本发明实施例中一种泄漏气体浓度分布确定设备的具体结构示意图。具体实施方式为了使本
技术领域:
的人员更好地理解本发明方案,下面结合附图和具体实施方式对本发明作进一步的详细说明。显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。实施例一:请参考图1,图1为本发明实施例中一种泄漏气体浓度分布确定方法的流程图,该方法包括以下步骤:s101、获取气体泄漏事故现场的泄漏数据。其中,泄漏数据包括:气象参数、地形参数和释放参数。当发生气体泄漏时,可通过多个仪器检测出泄漏源的泄漏参数。其中,发生泄漏的气体可以为生物、制药、石化、能源、材料及水厂等行业的生产、运输、储备过程涉及许多生物化学危险性重气、或可燃气体(如天然气、沼气等)、或气体商用或医用气体(如干冰原料二氧化碳、氮气、氧气等)。所获取的泄漏数据即为对泄漏气体的扩散具有影响的影响因子,如气象参数、地形参数和释放参数。其中,气象参数包括:风速、风向、大气稳定度等,地形参数包括:地表粗糙度等,释放参数包括:泄露速率、泄露源高度等。获取泄漏数据时,可采用气象仪器获取气象参数,地形参数可使用水平仪等工具进行测定,释放参数可通过传感器测量出气体泄漏源的释放参数。当然,还可以基于对气体泄漏源的内部气体压强(如气罐气压)等的记载,推断出泄漏速率。具体的,在发生了气体泄漏时,可通过相关仪器设备分别获得包括:下风向距离、方位角、释放速率、释放高度、地表粗糙度、平均风速、风向、摩擦速度、温度和莫宁·奥布霍夫长度(大气稳定度)10个参数的泄漏数据。s102、对泄漏数据进行归一化处理并转化数据格式,获得泄漏矩阵。得到泄漏数据之后,可将泄漏数据的各个参数按照一定损失进行排列,然后转换数据格式。即将序列格式的泄漏数据,转化为矩阵格式。如此,便可获得泄漏矩阵。s103、将泄漏矩阵输入至由卷积神经网络和xgboost构成的目标预测模型中进行处理,获得泄漏气体浓度分布信息。在本发明实施例中,可以预先设置一个由卷积神经网络(convolutionalneuralnetwork,cnn)和xgboost构成的目标预测模型。其中,卷积神经网络可对输入数据进行特征提取,xgboost具有良好的回归预测效果,结合了卷积神经网络和xgboost的目标预测模型则可以对输入数据进行更为精准的预测。得到泄漏矩阵之后,可将泄漏矩阵输入至由目标预测模型中进行处理,如此便可获得泄漏气体浓度分布信息。其中,泄漏气体浓度分布信息具体可以为泄漏气体扩散波及范围,也可以为气体扩散的具体浓度图。具体的,可通过执行以下步骤获得泄漏气体浓度分布信息:步骤一、利用卷积神经网络提取泄漏矩阵的数据特征;步骤二、利用xgboost对数据特征进行回归预测,获得泄漏气体浓度分布信息。为便于描述,下面将上述两个步骤结合起来进行说明。首先,利用卷积神经网络可对泄漏矩阵进行特征提取,然后,利用xgboost对提取的特征进行回归预测,进而获得泄漏气体浓度分布信息。即,利用目标预测模型对距离泄漏源指定距离和指定方位角的位置进行浓度预测,然后由多个位置的浓度预测得到的浓度预测值,进一步得到泄漏气体浓度分布信息。具体的,即卷积层对数据进行特征提取,池化层进行特征筛选,全连接层将前一层的多维输出变为一维向量,将此一维向量作为xgboost模块的输入,通过内部的线性处理得出浓度预测值。其中,利用xgboost对数据特征进行回归预测,获得泄漏气体浓度分布信息。具体为利用xgboost内部的线性转换,对数据特征进行回归预测,获得泄漏气体浓度分布信息。得到泄漏气体浓度分布信息之后,便可基于该泄漏气体浓度分布信息有针对性的进行人员迁移,设置警戒线等气体泄漏事故处理。应用本发明实施例所提供的方法,获取气体泄漏事故现场的泄漏数据;其中,泄漏数据包括:气象参数、地形参数和释放参数;对泄漏数据进行归一化处理并转化数据格式,获得泄漏矩阵;将泄漏矩阵输入至由卷积神经网络和xgboost构成的目标预测模型中进行处理,获得泄漏气体浓度分布信息。在发生气体泄漏事故时,获取事故现场包括气象参数、地形参数和释放参数的泄漏数据。然后对泄漏数据进行归一化处理,并将归一化处理后的数据转化为矩阵格式,即可获得泄漏矩阵。然后将该泄漏矩阵输入至由卷积神经网络和xgboost构成的目标预测模型中进行处理,即可获得有助于应急救援的泄漏气体浓度分布信息。在对泄漏数据进行处理时,卷积神经网络能够对影响泄漏气体扩散的泄漏参数进行深层次的分析,从而提取数据间深层次的联系,即提取更具有表现力的数据特征。然后xgboost可合理利用数据特征进行快速回归预测处理,最终可获得泄漏气体浓度分布信息。如此,便可提升气体泄漏后浓度分布信息的预测效率和准确率,进一步加快气体泄漏事故处理速度,降低气体泄漏带来的危害。实施例二:为了便于本领域技术人员更好的理解本发明实施例所描述的技术方案,在本实施例中,重点介绍获得目标预测模型的过程。在获得目标预测模型过程中,需要使用训练集对模型进行训练。因而,可预先设置训练集。通过执行以下步骤可获得训练集:步骤一、获取气体点源释放实验数据;步骤二、对实验数据进行归一化处理,并转换数据格式,获得二维矩阵形式的训练集。为便于描述,将上述两个步骤结合起来进行说明。获得气体点源释放实验数据,然后对实验数据进行归一化处理,并进行格式转换,获得二维矩阵形式的训练集。其中,归一化指计算出实验数据每列的均值及方差,然后将每个特征减去列均值,再除以列标准差,使得数据经过处理后限制在一定范围内,由此可保证模型运行时收敛加快。为了训练卷积神经网络,因而需将实验数据转化为二维矩阵形式,即图片形式。例如,请参见图2,图2为本发明实施例中的数据格式转换示意图,若每条样本是以1*10的形式输入,取其前6个参数衔接在原始样本后,组成1*16的形式,随后重组变为4*4的矩阵。获得目标预测模型的过程,包括:步骤一、提取卷积神经网络中截止至全连接层的网络结构,并与xgboost相连接,获得初始预设模型;步骤二、利用预设训练集对初始预测模型进行训练,获得目标预测模型。为便于说明,下面将上述步骤一和步骤二结合起来进行说明。首先,提取卷积神经网络中截止至全连接层的网络结构,也就是说,剥离卷积神经网络中全连接层的后续处理层。然后,将取出的网络结合与xgboost相连接,连接后得到的模型称之为初始预测模型。其中,获得初始预测模型具体包括:步骤一、构建卷积神经网络并利用交叉验证法确定卷积神经网络结构中的参数值,以及利用预设训练集对卷积神经网络进行训练;步骤二、利用交叉验证法确定xgboost的各项参数;步骤三、提取训练后的卷积神经网络截止至全连接层的网络结构,并与xgboost相连接,构成初始预测模型。为便于描述,下面将上述三个获得初始预测模型的具体步骤结合起来进行说明。其中,在构建卷积神经网络包括构建卷积神经网络,并在卷积神经网络中的全连接层与输出之间设置线性回归操作。使用交叉验证法确定出卷积神经网络结构中的参数值,并利用预先设置的训练集对卷积神经网络进行训练。即,对卷积神经网络中的初始学习率、dropout比例、迭代次数、批梯度的数量进行赋值并寻优。相应地,也可使用交叉验证法来确定xgboost的各项参数,即对树深度、学习率、观测样本生成的子节点的权重最小和、迭代次数进行赋值。对训练后的神经网络模型进行提取,将全连接层的后续处理层去除,将全连接层的输出作为xgboost的输入,提取后的卷积神经网络的全连接层与xgboost相连接,得到初始预测模型。利用预先设置的训练集对初始预测模型进行训练,训练过程即将初始预设模型中的参数进行调整,对训练集进行学习的过程。完成训练之后,即可获得可在气体泄漏时,进行泄漏气体浓度分布信息进行预测处理的目标预测模型。以获得可预测有毒重气发生泄漏事故后,对有毒重气点源泄露浓度预测的模型为例,对上述目标模型的获取方法进行详细说明。请参考图3,图3为本发明实施例中获得预测有毒重气泄漏浓度详细的模型的实施流程图,该过程包括以下步骤:s1:收集并整理国内外有毒重气点源释放实验数据;s2:数据预处理,并将其划分为训练集和测试集;s3:构建基于cnn和xgboost的有毒重气浓度预测模型;步骤s3具体可细分为s3.1和s3.2。其中,s3.1:搭建cnn模块结构,利用交叉验证法确定cnn模块的参数值,利用预处理好的训练集数据对cnn网络进行训练;s3.2:提取已训练好的cnn网络的截止至全连接层的所有网络层,使其与xgboost模块相连,利用交叉验证法确定xgboost模块的各项参数值;s4:利用预处理过得到的数据集对结合后的模型进行训练;s5:利用训练完毕的模型对测试集进行测试,完成模型准确度的指标评估。其中,对模型进行评估包括计算均方误差(meansquarederror,mse):其中,n为样本个数,yi为预测浓度值,为真实浓度值;计算拟合优度(goodnessoffit,r2):其中,yi为预测浓度值,为真实浓度值,为真实浓度值的平均值;计算平均绝对误差(meanabsoluteerror,mae):其中,n为样本个数,yi为预测浓度值,为真实浓度值。此外,还可将模型的计算时间和预测时间记录下来,一同作为评价该模型的预测效率的指标。对结合后的模型进行训练,最终得到的模型包括:cnn,用于接收输入数据,提取输入数据的内在关联和重要特征;xgboost,用于接收cnn模块的输出,进行最终的有毒重气浓度预测;针对s2中数据预处理的具体步骤包括:s21.确定影响气体扩散即释放后的浓度分布的关键参数,例如气象参数:风速、风向、大气稳定度等,地形参数:地表粗糙度等,释放参数:泄露速率、泄露源高度等。s22.对整理好的各条样本进行归一化处理,并将格式转化为二维矩阵形式;针对s3步骤中需要寻优的参数主要有:cnn模块:初始学习率、dropout比例、迭代次数、批梯度的数量;xgboost模块:树深度、学习率、观测样本生成的子节点的权重最小和、迭代次数。获得基于cnn和xgboost的有毒重气点源泄露浓度预测模型的过程中,首先对数据进行预处理,并将其分为训练集和测试集;通过交叉验证法分别确定cnn模块和xgboost模块的各项参数;然后对cnn-xgboost网络进行训练,将带标签的训练样本输入网络对其进行训练,其中cnn模块的卷积层对数据进行特征提取,池化层进行特征筛选,全连接层将前一层的多维输出变为一维向量,将此一维向量作为xgboost模块的输入,通过内部的线性处理得出浓度预测值。如此,便可获得一个有毒重气点源泄露浓度预测模型,即该模型可在发生有毒重气泄漏时,结合本发明实施例一所描述的预测方法,最终获得泄漏的有毒气体的浓度分布信息,以便相关人员有针对性进行事故处理。实施例三:为便于本领域技术人员理解本发明实施例所提供的技术方案,下面以二氧化硫(so2)为预测的目标气体为例,对本发明实施例所提供的技术方案进行详细说明。以1958年进行的prairiegrass实验获得的数据为基础进行案例实施。在prairiegrass实验中,so2被作为释放对象在46厘米的高度上连续释放10分钟,实验测得了在不同气象条件下连续释放10分钟后的so2气体浓度分布。针对此次实验,确定模型的输入,分别为:下风向距离、方位角、释放速率、释放高度、地表粗糙度、平均风速、风向、摩擦速度、温度和莫宁·奥布霍夫长度(大气稳定度)共计10个参数。基于cnn及xgboost构建有毒重气点源泄露浓度预测的模型,具体的:基于cnn及xgboost的特点,根据上述10个参数的数据,以so2为预测的目标气体,构建有毒重气点源泄露浓度预测的模型,模型以cnn为基础模块,分析输入数据之间的深层关联并提取重要特征;其结果作为高层模块xgboost的输入,产生最终预测结果。模型结构请参考图4所示,图4为本发明实施例中一种目标预测模型的结构示意图。该模型包括:cnn模块,用于接收输入数据,分析并提取数据间的深层关联和重要特征;xgboost,用于接收cnn全连接层的输出,通过内部的线性转换产生最终预测结果。根据构建的预测模型的特点,对prairiegrass实验的数据进行归一化操作并进行数据划分,从68组实验中抽取4组不同气象条件下的实验作为测试集,余下的数据作为训练集。最后对所有样本进行如图2的形式转换完成整个的数据预处理操作。搭建cnn模块,并通过交叉验证法寻找此模块的最优参数。cnn模块卷积层和池化层各有两层,卷积核尺寸为2*2,各有128个滤波通道,卷积步长为2,全连接层的输出为具有1024个元素的一维数组。全连接层与输出之间设置线性回归操作。整个网络的激励函数为relu,以网络的输出与真实浓度值之间的mse作为损失函数,用可以自适应调节学习率的adam算法进行梯度下降操作。cnn模块的初始学习速率在0.001-0.1之间取值,最大迭代次数在50-100之间取值,批梯度的数量在10-50之间取值,以mse为损失函数。搭建xgboost模块,并将cnn截止至全连接层的所有网络层与xgboost模块相连,通过交叉验证法进一步确定xgboost模块的各项参数。xgboost模块的学习率在0.1-0.5之间取值,树深度在5-7之间取值,观测样本生成的子节点的权重最小和在1-2之间取值,迭代次数在200-500之间取值,其余参数按照默认值设定。以预测值与真实浓度值之间的均方根误差(rootmeansquarederror,rmse)为损失函数不断调整模型。rmse计算式如下:其中,n为样本个数,yi为预测浓度值,为真实浓度值。利用预处理过的带标签的训练集数据对最终模型进行训练。利用训练完毕的模型对测试集数据进行测试并评价测试结果的准确性及预测速度。请参考图5和图6,其中,图5为prairiegrass实验中的实际浓度图;图6为本发明实施例所提供的目标预测模型预测的浓度值。下面以具体的测试用例和测试结果,对本发明实施例所提供的技术方案进行下面说明。cnn模块经过交叉验证寻优后,确定参数:初始学习率为0.001;dropout比例为0.33;迭代次数为50次;梯度批的数量为16。xgboost模块经过交叉验证寻优后,确定参数:树深度为7、学习率为0.15、观测样本生成的子节点的权重最小和为1、迭代次数为300。以测试集中的27号实验为展示对象,最终得到的气体浓度的预测值与真实值之间的mse为155.815,mae为7.594,r2为0.929。整个模型的计算时间为513.65s,预测时间为0.025s。为便于本领域技术人员了解本发明实施例所提供的技术方案的优越性,以相同的实验数据为基础,构建了bp网络模型,并对27号实验进行预测。bp模型实验预测值与真实浓度值之间的mse为815.35,mae为17.507,r2为0.427,整个模型的计算时间为4764.43s,预测时间为0.0081s。具体的数据比对可参考表1,由此可知,基于cnn和xgboost的有毒重气点源泄露浓度预测方法(表1中的cnn-xgboost)在保证了计算及预测时间的前提下,精度较现有的机器学习方法有较大的提高。本发明实施例所提供的技术方案可为今后的有毒重气泄露应急救援工作提供较为可靠的技术保证。模型mser2mae预测时间计算时间cnn-xgboost155.8150.9297.5940.025s513.65sbp815.350.42717.5070.0081s4764.43s表1实施例四:相应于上面的方法实施例,本发明实施例还提供了一种泄漏气体浓度分布确定装置,下文描述的泄漏气体浓度分布确定装置与上文描述的泄漏气体浓度分布确定方法可相互对应参照。参见图7所示,该装置包括以下模块:泄漏数据获取模块101,用于获取气体泄漏事故现场的泄漏数据;其中,泄漏数据包括:气象参数、地形参数和释放参数;泄漏矩阵获取模块102,用于对泄漏数据进行归一化处理并转化数据格式,获得泄漏矩阵;气体浓度分布预测模块103,用于将泄漏矩阵输入至由卷积神经网络和xgboost构成的目标预测模型中进行处理,获得泄漏气体浓度分布信息。应用本发明实施例所提供的装置,获取气体泄漏事故现场的泄漏数据;其中,泄漏数据包括:气象参数、地形参数和释放参数;对泄漏数据进行归一化处理并转化数据格式,获得泄漏矩阵;将泄漏矩阵输入至由卷积神经网络和xgboost构成的目标预测模型中进行处理,获得泄漏气体浓度分布信息。在发生气体泄漏事故时,获取事故现场包括气象参数、地形参数和释放参数的泄漏数据。然后对泄漏数据进行归一化处理,并将归一化处理后的数据转化为矩阵格式,即可获得泄漏矩阵。然后将该泄漏矩阵输入至由卷积神经网络和xgboost构成的目标预测模型中进行处理,即可获得有助于应急救援的泄漏气体浓度分布信息。在对泄漏数据进行处理时,卷积神经网络能够对影响泄漏气体扩散的泄漏参数进行深层次的分析,从而提取数据间深层次的联系,即提取更具有表现力的数据特征。然后xgboost可合理利用数据特征进行快速回归预测处理,最终可获得泄漏气体浓度分布信息。如此,便可提升气体泄漏后浓度分布信息的预测效率和准确率,进一步加快气体泄漏事故处理速度,降低气体泄漏带来的危害。在本发明的一种具体实施方式中,气体浓度分布预测模块103,包括:数据特征获取单元,用于利用卷积神经网络提取泄漏矩阵的数据特征;气体浓度分布信息获取单元,用于利用xgboost对数据特征进行回归预测,获得泄漏气体浓度分布信息。在本发明的一种具体实施方式中,气体浓度分布信息获取单元,具体用于利用xgboost内部的线性转换,对数据特征进行回归预测,获得泄漏气体浓度分布信息。在本发明的一种具体实施方式中,还包括:目标预测模型创建模块;目标预测模型创建模块,包括:初始预设模型创建单元,用于提取卷积神经网络中截止至全连接层的网络结构,并与xgboost相连接,获得初始预设模型;初始预设模型训练单元,用于利用预设训练集对初始预测模型进行训练,获得目标预测模型。在本发明的一种具体实施方式中,初始预设模型创建单元,具体用于构建卷积神经网络并利用交叉验证法确定卷积神经网络结构中的参数值,以及利用预设训练集对卷积神经网络进行训练;利用交叉验证法确定xgboost的各项参数;提取训练后的卷积神经网络截止至全连接层的网络结构,并与xgboost相连接,构成初始预测模型。在本发明的一种具体实施方式中,初始预设模型创建单元,具体用于构建卷积神经网络,并在卷积神经网络中的全连接层与输出之间设置线性回归操作。在本发明的一种具体实施方式中,还包括:训练集获得模块,用于在利用预设训练集对初始预测模型进行训练,获得目标预测模型之前,获取气体点源释放实验数据;对实验数据进行归一化处理,并转换数据格式,获得二维矩阵形式的训练集。实施例五:相应于上面的方法实施例,本发明实施例还提供了一种泄漏气体浓度分布确定设备,下文描述的一种泄漏气体浓度分布确定设备与上文描述的一种泄漏气体浓度分布确定方法可相互对应参照。参见图8所示,该事务处理设备包括:存储器d1,用于存储计算机程序;处理器d2,用于执行计算机程序时实现上述方法实施例的事务处理方法的步骤。具体的,请参考图9,为本实施例提供的泄漏气体浓度分布确定设备的具体结构示意图。该泄漏气体浓度分布确定设备可因配置或性能不同而产生比较大的差异,可以包括一个或一个以上处理器(centralprocessingunits,cpu)322(例如,一个或一个以上处理器)和存储器332,一个或一个以上存储应用程序342或数据344的存储介质330(例如一个或一个以上海量存储设备)。其中,存储器332和存储介质330可以是短暂存储或持久存储。存储在存储介质330的程序可以包括一个或一个以上模块(图示没标出),每个模块可以包括对数据处理设备中的一系列指令操作。更进一步地,中央处理器322可以设置为与存储介质330通信,在泄漏气体浓度分布确定设备301上执行存储介质330中的一系列指令操作。泄漏气体浓度分布确定设备301还可以包括一个或一个以上电源326,一个或一个以上有线或无线网络接口350,一个或一个以上输入输出接口358,和/或,一个或一个以上操作系统341。例如,windowsservertm,macosxtm,unixtm,linuxtm,freebsdtm等。上面所描述的泄漏气体浓度分布确定方法中的步骤可以由泄漏气体浓度分布确定设备的结构实现。实施例六:相应于上面的方法实施例,本发明实施例还提供了一种可读存储介质,下文描述的一种可读存储介质与上文描述的一种泄漏气体浓度分布确定方法可相互对应参照。一种可读存储介质,可读存储介质上存储有计算机程序,计算机程序被处理器执行时实现上述方法实施例的泄漏气体浓度分布确定方法的步骤。该可读存储介质具体可以为u盘、移动硬盘、只读存储器(read-onlymemory,rom)、随机存取存储器(randomaccessmemory,ram)、磁碟或者光盘等各种可存储程序代码的可读存储介质。专业人员还可以进一步意识到,结合本文中所公开的实施例描述的各示例的单元及算法步骤,能够以电子硬件、计算机软件或者二者的结合来实现,为了清楚地说明硬件和软件的可互换性,在上述说明中已经按照功能一般性地描述了各示例的组成及步骤。这些功能究竟以硬件还是软件方式来执行,取决于技术方案的特定应用和设计约束条件。专业技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本发明的范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1