一种融合搜索与计算的大数据分析系统及其分析方法与流程
本发明涉及一种大数据分析方法,具体的说是一种融合搜索与计算的大数据分析系统及其分析方法,属于大数据分析处理技术领域。
背景技术:
随着互联网的高速发展,企业所收集的数据量也呈指数级增长,包括交易数据、位置数据、用户交互数据、物流数据、供应链数据、企业经营数据、硬件监控数据、应用日志数据等,这些数据在短时间内无法通过常规软件进行获取以及处理,是需要全新的处理模式才能从大量数据中发现更有决策力的海量、高增长率和多样化的信息资产。随着现代测量技术和智能设备的发展,数据的形式由传统单一的结构化数据演变为由结构化数据、半结构化数据和非结构化数据组成的复杂的数据形式。互联网的快速发展给了人们以分享这些数据的平台,由此产生的海量数据被人们发现和利用,就产生了新型的大数据概念。ibm给出了大数据的5v特点(ibm提出):volume(大量)、velocity(高速)、variety(多样)、value(低价值密度)、veracity(真实性)。
相比传统的关系数据库,大数据具有数据量巨大、结构复杂、类型众多等特点,这对大数据的存储、处理与分析提出了新的挑战。传统的数据分析处理技术(例如并行数据库、数据仓库)存在的问题有:①传统的数据仓库技术一般只能处理tb级别的数据量,然而大数据往往pb级别甚至eb级别,并行数据库大多支持有限扩展,一般可扩至数百节点的规模,尚未有数千节点规模的应用案例,传统数据分析处理技术无法处理大数据的高扩展性和海量需求;②大数据涵盖了各种类型的数据,包括结构化、半结构化和非结构化数据,不同类型数据的分析不尽相同,传统数据分析处理往往只针对某一种类型数据和比较单一,大数据分析的方法也是多样化,就有数据挖掘、模式识别、数据融合与集成、时间序列分析等,数据类型的增加导致现有数据空间维度增加,极大地增加了大数据分析处理的复杂度;③传统数据库处理能力的提高依赖于cpu/内存/存储/网络的更新升级,而大数据的处理模式是一种基于“scale-out”的模式,它的性能提高依赖于连续的往分布式系统上增加低价的计算和存储节点;④传统的数据处理方法是以处理器为中心,而大数据环境下,需要采取以数据为中心的模式,减少数据移动带来的开销,传统的数据处理方法,已经不能适应大数据的需求。
当前存在的hadoop、storm、spark等大数据分析框架具有广泛的实用性,成为主流的大数据处理技术和分析平台,为大数据分析带来了很多便捷之处。然而它们也都或多或少地存在问题,这些分析平台的使用者往往是it专业人员,而it人员又不懂数据的业务价值,不能很好地解决计算框架与挖掘的数据价值之间的鸿沟。hadoop基于hdfs(分布式文件系统),需要切分输入数据、产生中间数据文件、排序、数据压缩、多份复制等,效率较低。storm基于zeromq这个高性能的消息通讯库,不持久化数据。这些现有的大数据平台只能完成任务的分发与计算后的结果合并,至于挖掘所得到的数据价值具有不确定性。
技术实现要素:
本发明所要解决的技术问题是,克服现有技术的缺点,提供一种融合搜索与计算的大数据分析系统及其分析方法,克服了使用传统大数据平台需要专业程序员进行编程实现的问题,大大提高了大数据分析平台的实用性。
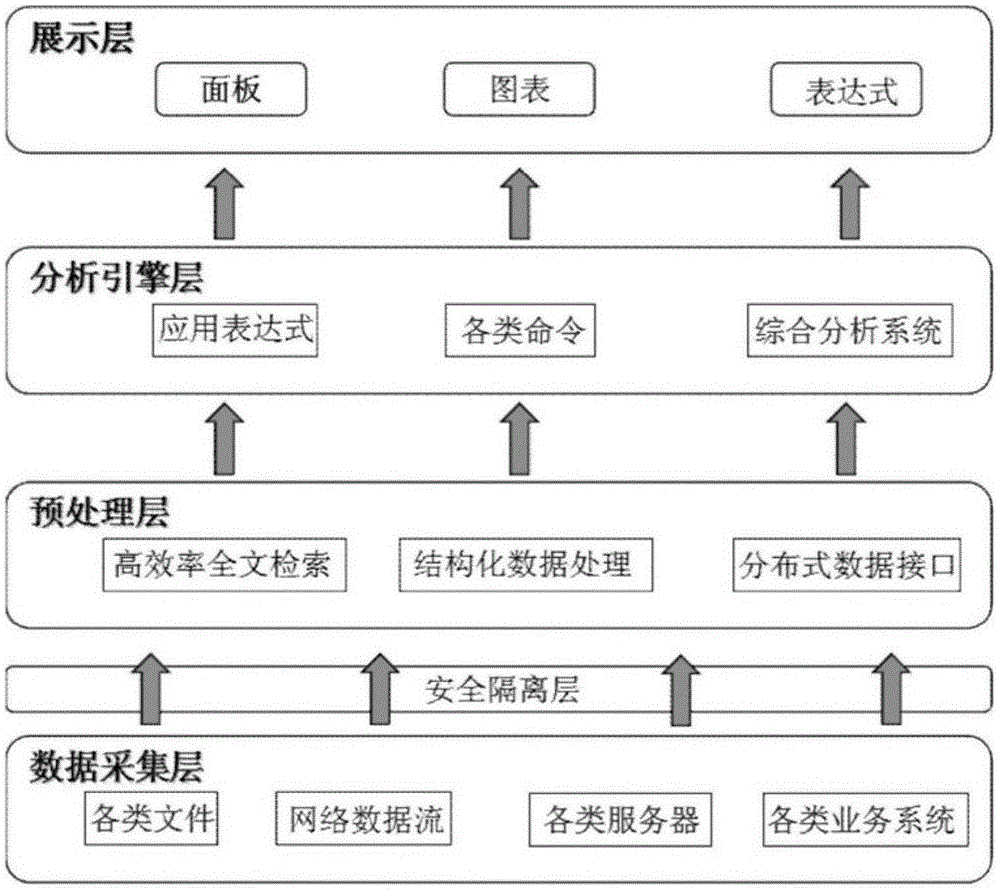
针对存在的技术问题,本发明提出一种融合搜索与计算的大数据分析系统,包含数据采集层、预处理层、分析引擎层和显示层;
所述数据采集层,用于获取待分析数据;其中待分析数据的来源包含各类文件、网络数据流、各类服务器以及各类业务系统;
所述预处理层包含全文检索模块、结构化数据处理模块、分布式数据接口模块,用于对获取的待分析数据进行预处理;
所述分析引擎层,一方面针对预处理之后的数据,根据属性类型,进行分类存储;另一方面采集来自显示层的表达式,进行语法分析并进行执行,将分析执行的计算结果返回给显示层;
所述显示层,用于显示融合搜索与计算的大数据的分析结果,所述显示层采用面板、图表、表达式的方式显示融合搜索与计算的大数据的分析结果。
本发明的进一步限定技术方案,前述的融合搜索与计算的大数据分析系统,所述全文检索模块,用于对获取的待分析数据进行检索;结构化数据处理模块,用于对获取的待分析数据结构化处理;分布式数据接口模块,用于对获取的待分析数据进行数据传输及存储。
前述的融合搜索与计算的大数据分析系统,所述数据采集层和预处理层之间还设有安全隔离层。
前述的融合搜索与计算的大数据分析系统,所述分析引擎层将来自显示层的表达式进行语法分析,分解成一级一级的子命令,再顺序执行各个子命令;每个子命令带有设定计算参数,如sum就是统计求和,max就是求数据集中对应字段的最大值,每个子命令对应一种分析处理;上一级子命令的数据输出就是下一级子命令的数据输入,数据就采用管道机制运作,而第一级子命令直接从数据存储中读取数据;将功能不同的子命令可以灵活的组合在一起,从而实现分析引擎层的计算功能。所述显示层的表达式为来自显示层ui搜索框的搜索语句。
一种基于融合搜索与计算的大数据分析系统的分析方法,包括如下步骤:
步骤1,获取待分析数据;
步骤2,对步骤1获取的待分析数据进行预处理;
步骤3,根据预处理后得到的数据属性进行分类处理后进行存储;再将来自显示层的表达式分解成一级一级的子命令后,顺序执行,并将结果返回给显示层;
步骤4,将步骤3分析后的数据采用面板、图表、表达式的方式显示。
前述的融合搜索与计算的大数据分析系统的分析方法,所述步骤2具体包含如下步骤;
步骤2.1,提取待分析数据的文本;
步骤2.2,从文本和来源数据中按照预设及用户指定的匹配模式抽取字段;
步骤2.3,对抽取字段对应的文本进行分词并建立索引。
进一步的,前述的融合搜索与计算的大数据分析系统的分析方法,所述步骤1包括以下步骤:①添加数据;
②精确设定日期时间提高检索分析效率;
③通过感兴趣字段进行分析;
④在步骤③基础上进一步分析提取有用信息分析;
⑤重复步骤④直到挖掘得到所需信息。
本发明的有益效果是:本发明通过检索与表达式语言进行可视化搜索得到大数据分析结果,大大降低了大数据分析平台使用的专业性要求,降低了企业需要同时聘用it技术人员与业务分析人员的成本,同时表达式语言命令独立、可替代,相比之前使用传统大数据平台的编程方式,扩展性强,大大降低了复杂度,同时提高了大数据分析效率。本发明提出的系统方法全线打通大数据的采集、存储、分析、呈现等关键步骤,让行业用户聚焦于大数据的业务分析,挖掘大数据的价值,传统大数据平台作为计算框架只进行任务的分发与计算结果的合并,因此所得分析结果未必对企业具有价值,本发明跨越了计算框架与数据价值间的鸿沟,保证了挖掘所得数据是有价值的。本发明提出的系统方法能够轻松处理多源异构数据(结构化、半结构化、非结构化数据),尤其擅长超海量的事件型(event)数据分析处理,可以广泛应用各种行业运营相关的大数据分析。本发明采用了管道机制,使用竖线或管道符将命令应用到检索的事件,可以分步骤进行操作,每个步骤的操作结果可以作为下一步骤的操作基础,使得大数据分析能够随行业和客户的需求随心而变。
附图说明
图1是本发明总体结构示意图;
图2是本实施例数据服务引擎的控制流程图;
图3是本实施例数据预处理的数据流图;
图4是本实施例数据服务引擎的数据流图;
图5是本实施例ui呈现的数据流图;
图6是具体案例的数据预处理结果。
具体实施方式
实施例1
本实施例提供一种融合搜索与计算的大数据分析系统,如图1所示,包含数据采集层、预处理层、分析引擎层和显示层;其中,数据采集层,用于获取待分析数据;待分析数据的来源包含各类文件、网络数据流、各类服务器、各类业务系统;预处理层,用于对获取的待分析数据进行预处理;预处理层包含全文检索模块、结构化数据处理模块、分布式数据接口模块;分析引擎层,实现数据的分类处理和存储,并对显示层的搜索表达式进行语法分析、执行和返回数据结果;显示层,用于显示融合搜索与计算的大数据的分析结果,所述显示层采用面板、图表、表达式的方式显示融合搜索与计算的大数据的分析结果。
其中,全文检索模块,用于对获取的待分析数据进行检索;结构化数据处理模块,用于对获取的待分析数据结构化处理;分布式数据接口模块,用于对获取的待分析数据进行数据传输及存储。
本实施例提出的系统方法全线打通数据准备、数据存储与管理、计算处理、数据分析这4个大数据处理主要环节。为了实现上述目的,本实施例所采用融合搜索与计算的大数据分析处理方法,其主要原理如下:本实施例通过检索与表达式语言进行大数据搜索,对于搜索所得结果系统给出“感兴趣字段”给用户以灵感,有助于启发式分析。用户可以在前一次搜索分析的结果之上进一步进行操作、筛选,层层递进,一步一步接近获得隐藏在大数据内部的核心信息。同时命令可以替代以产生不同的分析结果,当某一步的分析未能产生想要的结果或者是前一步分析出错时,只需要简单的删去或者替换前一步命令即可,无需重新实现。这种管道式的机制灵活高效,命令独立,不受之前操作的影响,使用十分方便高效。
如图2所示,来自浏览器,即显示层,本系统的ui采用web方式呈现的请求,发送到后端应用服务器(web是前端),如果请求静态资源如图片等,则直接返回静态资源;如果是某个app,则先由后端的对应的数据应用将请求进行特定转换,再交给表达式解析引擎进行分析拆解成一个个子命令运行,再返回计算结果,而子命令从数据接口获取初级数据;如果请求是极限表达式,指不是由子命令构成的普通搜索命令,则直接访问数据接口再返回数据。
本实施例在通过检索与表达式语言实现大数据搜索分析的基础上,还可以图形化展示数据量、选择时间范围的时间序列、支持多种数据格式和类型的适配以及从数据中提取字段并图形化展示。
使用本实施例的系统进行大数据分析的步骤如下:①添加数据(本实施例可以索引任何计算机数据,数据来源包含结构化数据(csv,xml,json),数据库服务(oracle,mysql,microsoftsqlserver),web服务(apache,iis)等。)②精确设定日期时间提高检索分析效率③通过感兴趣字段进行分析④在步骤③基础上进一步分析提取有用信息分析⑤重复步骤④直到挖掘得到所需信息;本实施例的总体结构分为数据采集层、预处理层、分析引擎层和展示层。导入数据后,系统从不同类型的文件、通道、日志、数据流中抽取出文本,去除其他无关内容。接着提取字段,从文本和来源元数据中按照预设及用户指定的匹配模式抽取字段如图6所示。该字段是对原文件、通道、日志、数据流的一个描述。对所抽取的文本进行分词并建立索引,各字段以及文本自身成为被索引的结果集合。此外,字段自身也具有一定的被检索性质。
预处理过程如图3所示,从临时文件中提取文本,并根据配置,提取每条事件型数据的时间字段,如果没有时间字段使用内部时间戳代替。然后依据配置文件的字段配置,从每条数据提取各种字段,最后将提取的字段和原始文本进行分类索引存储,放入索引数据库。管道命令、极限表达式提供了一个统一的,相对高级的对所生成事件型数据和其他经过处理的数据访问接口。以某公司发现某员工访问非法网站为例。首先将近期网络访问日志导入到本系统,然后在界面的搜索输入框输入“searchtype=weblog|unusualdomain”,其中searchtype=weblog代表从网络访问日志中搜索数据,而unusualdomain代表从数据中过滤出非正常网站域名的日志。这样就可以得到包含访问非法网站的日志记录。然后再观察返回的分析结果,挑选其中的非法网站访问日志。进一步根据这一域名访问记录来排查访问者的ip(client_ip)和该ip地址所对应的计算机终端等信息,一步一步确认,最终完成大数据的分析找到结果即“谁在什么时候访问了哪一个非法网站”。
综上所述,本实施例通过检索与表达式语言进行可视化搜索得到大数据分析结果,大大降低了大数据分析平台使用的专业性要求,降低了企业需要同时聘用it技术人员与业务分析人员的成本,同时表达式语言命令独立、可替代,相比之前使用传统大数据平台的编程方式,扩展性强,大大降低了复杂度,同时提高了大数据分析效率;本实施例提出的系统方法全线打通大数据的采集、存储、分析、呈现等关键步骤,让行业用户聚焦于大数据的业务分析,挖掘大数据的价值,传统大数据平台作为计算框架只进行任务的分发与计算结果的合并,因此所得分析结果未必对企业具有价值。本实施例跨越了计算框架与数据价值间的鸿沟,保证了挖掘所得数据是有价值的;本实施例提出的系统方法能够轻松处理多源异构数据(结构化、半结构化、非结构化数据),尤其擅长超海量的事件型(event)数据分析处理,可以广泛应用各种行业运营相关的大数据分析;本实施例采用了管道机制,使用竖线或管道符将命令应用到检索的事件,可以分步骤进行操作,每个步骤的操作结果可以作为下一步骤的操作基础,这使得大数据分析能够随行业和客户的需求随心而变。同时本实施例采用启发式分析,面对大数据无计可施,不知如何挖掘其中数据价值时,可以激发用户灵感,帮助用户逐步发现数据价值。
除上述实施例外,本发明还可以有其他实施方式。凡采用等同替换或等效变换形成的技术方案,均落在本发明要求的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!