一种常规能源和新能源公交车辆的污染气体排放预测方法与流程
本发明属于交通节能减排
技术领域:
,具体涉及一种常规能源和新能源公交车辆的污染气体排放预测方法。
背景技术:
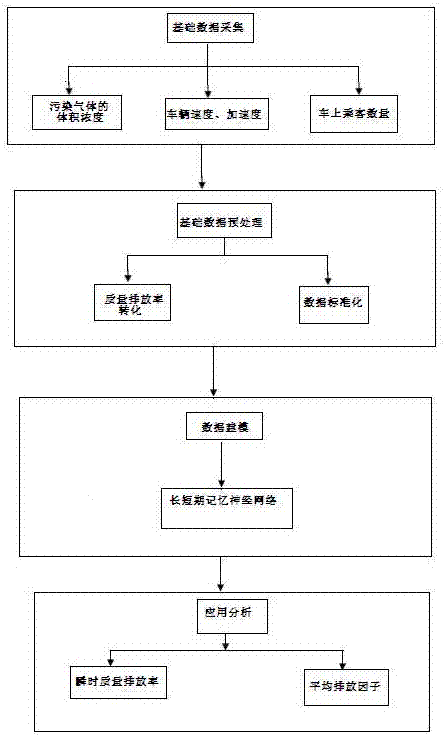
近年来气候变化和空气质量问题已经成为一个世界性问题。许多研究人员已经证实交通产生的排放是空气污染的一个主要来源,微粒、一氧化碳、二氧化碳、碳氢化合物、氮氧化合物等排放物在汽车移动中产生,对空气质量和人体健康产生很大危害。同时,日益增加的交通需求带来了严重的拥堵,这也会增加排放污染。为了解决这些问题,公共交通系统的作用越来越被规划管理者所重视。虽然公交系统目前已被视为解决交通拥堵和污染的一个有效方式,但不得不注意的是,公交车辆的排放量仍然有必要进行测算。如今拥挤的路况加上公交车辆要在线路上的每个站点附近停车、上下乘客、启动,使得车辆开开停停,燃油燃烧不充分,导致碳氢化合物和一氧化碳等排放污染物急剧增加。同时近几年来新能源公共汽车的大量投入使用,这种汽车所能带来的节能减排效果需要被测算与评价。然而,目前对于测算公交车辆排放量的研究还非常少,尤其是新能源公交车辆更是几乎空白。同时,大多数测算公交排放的方法对过去车辆运行状况往往是选取了固定过去时间段内的车辆运行状况参数进行分析,这与实际情况截然不同,事实上,质量排放率受过去车辆运行状况的程度往往会随时间变化,因而现有大部分的测算方法也极不准确。技术实现要素:本发明正是针对现有技术中的问题,提供了一种常规能源和新能源公交车辆的污染气体排放预测方法,克服了现有技术中测算不准确的问题,通过基础数据采集、数据预处理、数据建模和应用分析四个步骤,基于循环神经网络中的长短期记忆神经网络,实现对于常规能源和新能源公交车的排放给出更为准确的预测,能为节能减排政策的制定提供理论指导,为优化公交专用车道的建设提供指导意见,使管理者和设计者能够更好地管理、调整和优化系统运作和系统设计。为了实现上述目的,本发明采用的技术方案是:一种常规能源和新能源公交车辆的污染气体排放预测方法,包括如下步骤:s1,基础数据采集:包括测试车辆排放气体中污染气体的体积浓度、测试车辆速度和加速度,及车上乘客数量,所述三种数据保持时间上的同步;s2,基础数据预处理:包括将污染气体质量排放率转化和数据标准化,所述污染气体质量排放率转化指将步骤s1中采集到的污染气体体积浓度转换成相应单位时间内污染气体排放质量;s3,数据建模:构建基于长短期记忆神经网络的模型,通过sigmoid函数,输入以往的信息和当前的信息,输出一个0-1之间的权重,分别来控制当前单元中以往信息流入的程度、当前信息流入的程度以及输出的程度:s4,应用分析;s41,污染气体瞬时质量排放率的获得:每个时间间隔中输入速度、加速度、坡度、车上乘客数量,通过步骤s3中长短记忆神经网络模型得到当前的质量排放率;s42,平均排放因子的计算:将长短期记忆神经网络模型的估计值进行累加,并除以对应的运行距离,从而得到其单位距离上的排放量。作为本发明的一种改进,所述步骤s1中污染气体的体积浓度数据采集主要包括排放气体中的co、co2、hc和nox的气体体积浓度;所述测试车辆速度的数据采集为测试车辆在排放测量时的实时车辆速度,所述加速度根据速度采集数据计算得出;所述车上乘客数量数据通过记录得出。作为本发明的一种改进,所述步骤s2中污染气体质量排放率转化公式如下:cogk=(mair+mfuel)×mco/mexhaust×co%×10-2hcg/s=(mair+mfuel)×mhc/mexhaust×hcppm×10-2其中,mco为co的分子量;mhc为排放气体中未完全燃烧的hc的分子量,hc为碳氢化合物;为nox的分子量;为co2的分子量;hcppm为排放气体中碳氢化合物的气体体积浓度;co%为排放气体中一氧化碳的体积百分比;为排放气体中氮氧化合物的体积浓度;co2%为排放气体中二氧化碳的体积百分比;mair和mfuel分别为单位时间空气和燃料的消耗质量;mexhaust为尾气的分子量。作为本发明的另一种改进,所述尾气分子量mexhaust为:其中,k为转换系数,所述k的计算公式为:k=[1+0.005×(co%+co2%)×y-0.01×h2%]-1h2%计算公式为:h2%=[0.5×y×co%×(co%+co2%)]/[co%+3×co2%]其中,o2%为排放气体中氧气的体积百分比,h2%为排放气体中氢气的体积百分比。作为本发明的另一种改进,所述步骤s2中数据标准化的公式如下:其中,ei是原始数据;ei′是标准化后的数据;是原始数据的均值;s是原始数据的标准差。作为本发明的另一种改进,所述步骤s3中sigmoid函数公式如下:其中,为隐含层数i的t时刻输入向量;是隐含层数i的t-1时刻隐藏层向量;bf,uf,wf分别是遗忘门的偏置、输入权重和遗忘门的循环权重;是第i个隐含层的偏置;是输入信息里对应第i个隐含层第j个变量的输入权重;是输入信息里对应第i个隐含层第j个变量的循环权重;bg,ug,wg分别是输入门的偏置、输入权重和遗忘门的循环权重;是第i个隐含层的偏置;是输入信息里对应第i个隐含层第j个变量的输入权重;是输入信息里对应第i个隐含层第j个变量的循环权重;bo,uo,wo分别是输出门的偏置、输入权重和遗忘门的循环权重;是第i个隐含层的偏置,;是输入信息里对应第i个隐含层第j个变量的输入权重;是输入信息对应第i个隐含层第j个变量的循环权重;σ(·)表示标准的逻辑s型函数,其计算公式如下:作为本发明的另一种改进,所述步骤s3中长短期记忆神经网络的模型的长短期记忆单元通过以下公式进行更新,其中,表示时刻t-1下的细胞i;bi为隐含层数i所对应的偏置;ui,j输入信息里对应第i个隐含层第j个变量的输入权重;wi,j是输入信息里对应第i个隐含层第j个变量的循环权重。作为本发明的更进一步改进,所述步骤s3中长短期记忆神经网络的模型训练算法采用反向传播算法来最小化价值函数,所述价值函数为:其中,为模型输出值;l(t)为t时刻的损失值;t为总时间;为目标值。与现有技术相比,本发明提出了一种常规能源和新能源公交车辆的污染气体排放预测方法,具有的技术效果:克服了现有技术中测算不准确的问题,通过基础数据采集、数据预处理、数据建模和应用分析四个步骤,基于循环神经网络中的长短期记忆神经网络,实现对于常规能源和新能源公交车的排放给出更为准确的预测,采用较简便易行的测量方法,对公交车辆在路段行驶过程中的运行特征、排放特征进行研究,探究排放规律,相对其他层次模型较为准确,时间相关性的效用也比较大,能为节能减排政策的制定提供理论指导,为优化公交专用车道的建设提供指导意见,使管理者和设计者能够更好地管理、调整和优化系统运作和系统设计,并进一步降低公交车辆的温室气体排放量。附图说明图1是一种常规能源和新能源公交车辆的污染气体排放预测方法流程图;图2是长短期记忆门神经网络计算结构图;图3是实施例中四种类型公交车辆120秒的co2逐秒质量排放率示例图;图4是实施例中四种类型公交车辆120秒的hc逐秒质量排放率示例图;图5是实施例中四种类型公交车辆120秒的nox逐秒质量排放率示例图;图6是实施例中四种类型公交车辆120秒的co逐秒质量排放率示例图;图7是实施例中四种类型公交车辆co2排放因子示例图;图8是实施例中四种类型公交车辆hc排放因子示例图;图9是实施例中四种类型公交车辆nox排放因子示例图;图10是实施例中四种类型公交车辆co排放因子示例图。具体实施方式以下将结合附图和实施例,对本发明进行较为详细的说明。实施例1一种常规能源和新能源公交车辆的污染气体排放预测方法,如图1所示,包括如下步骤:s1,基础数据采集:包括测试车辆排放气体中污染气体的体积浓度、测试车辆速度和加速度,及车上乘客数量,其中,所述污染气体的体积浓度为排放气体中的co、co2、hc和nox气体的体积浓度;所述速度数据为测试车辆在排放测量时的实时车辆速度,同时根据速度数据计算出加速度数据;所述车上乘客数据为间接获得,通过记录上下车乘客和到站时间;测试车辆排放气体中污染气体的体积浓度及测试车辆速度数据和车上乘客数据要保证三类数据时间上同步。s2,基础数据预处理:包括将污染气体质量排放率转化和数据标准化,所述污染气体质量排放率转化指将步骤s1中采集到的污染气体体积浓度转换成相应单位时间内污染气体排放质量;也就是说,各类污染气体质量排放率转化指将数据采集过程中所得到的co、hc、nox和co2污染气体体积浓度转换成相应的单位时间内污染气体排放质量,对于以汽油为燃料的车辆,各类污染气体质量排放率的计算公式如下:cogk=(mair+mfuel)×mco/mexhaust×co%×10-2hcg/s=(mair+mfuel)×mhc/mexhaust×hcppm×10-2其中,mco为co的分子量;mhc为排放气体中未完全燃烧的hc的分子量,hc为碳氢化合物;为nox的分子量;为co2的分子量;hcppm为排放气体中碳氢化合物的气体体积浓度;co%为排放气体中一氧化碳的体积百分比;为排放气体中氮氧化合物的体积浓度;co2%为排放气体中二氧化碳的体积百分比;mair和mfuel分别为单位时间空气和燃料的消耗质量;mexhaust为尾气的分子量,用下式计算:其中,k为转换系数,所述k的计算公式为:k=[1+0.005×(co%+co2%)×y-0.01×h2%]-1h2%计算公式为:h2%=[0.5×y×co%×(co%+co2%)]/[co%+3×co2%]其中,o2%为排放气体中氧气的体积百分比,h2%为排放气体中氢气的体积百分比。所述步骤s2中数据标准化的公式如下:其中,ei是原始数据;ei′是标准化后的数据;是原始数据的均值;s是原始数据的标准差。s3,数据建模:包括对不同公交车型的不同排放污染气体进行长短期记忆神经网络建模。所述数据建模的方法是长短期记忆神经网络,该网络是循环神经网络中的一种,它的结构较为特殊,首先是它的神经元间存在着自循环结构,从而使得以往的信息能够传递到当前的神经元中;其次是它具有遗忘门、输入门、输出门三个控制单元,这三个控制单元都可以视为是简单神经网络中神经元,通过sigmoid函数,输入以往的信息和当前的信息,输出一个0-1之间的权重,分别来控制当前单元中以往信息流入的程度,当前信息流入的程度以及输出的程度。在应用于排放建模的过程中,每个时间间隔中输入速度、加速度、坡度、车上乘客数量,通过长短记忆门网络结构得到当前的质量排放率。由于其特殊结构,模型能够自动选择过去信息的保留程度,从而解决传统时间相关性排放模型的不足之处。附图2所示是长短期记忆神经网络计算结构图,状态单元(时刻t下的细胞i)负责储存任意时间间隔的数据值,历史信息通过记忆单元的递归结构进行传递。遗忘门单元(时刻t下的细胞i)通过控制自循环权重调整单元值,输入门单元(时刻t下的细胞i)控制流入单元的新的数据,输出门(时刻t下的细胞i)控制用于计算长短期记忆单元输出激活的值。每个门可以被看作是简单神经网络中神经元通过sigmoid函数,输入以往的信息和当前的信息,输出一个0-1之间的权重,分别来控制当前单元中以往信息流入的程度,当前信息流入的程度以及输出的程度。sigmoid函数公式如下:其中为隐含层数i的t时刻输入向量,是隐含层数i的t-1时刻隐藏层向量,包括所有长短期记忆单元的输出,bf,uf,wf分别是遗忘门的偏置、输入权重和遗忘门的循环权重,而是第i个隐含层的偏置,是输入信息里对应第i个隐含层第j个变量的输入权重,是输入信息里对应第i个隐含层第j个变量的循环权重;bg,ug,w9分别是输入门的偏置、输入权重和遗忘门的循环权重,是第i个隐含层的偏置,是输入信息里对应第i个隐含层第j个变量的输入权重,是输入信息里对应第i个隐含层第j个变量的循环权重;bo,uo,wo分别是输出门的偏置、输入权重和遗忘门的循环权重,是第i个隐含层的偏置,是输入信息里对应第i个隐含层第j个变量的输入权重,是输入信息对应第i个隐含层第j个变量的循环权重。σ(·)表示标准的逻辑s型函数,其计算公式如下:是输入信息里对应第i个隐含层第j个变量的循环权重,基于这三个门,长短期记忆单元通过以下公式进行更新,其中表示时刻t-1下的细胞i,bi为隐含层数i所对应的偏置,ui,j输入信息里对应第i个隐含层第j个变量的输入权重,wi,j是输入信息里对应第i个隐含层第j个变量的循环权重。模型训练算法可采用反向传播算法等来最小化价值函数,这里价值函数是一系列训练后的总误差:式中这里为模型输出值,l(t)为t时刻的损失值,t为总时间,为目标值。s4,应用分析;s41,污染气体瞬时质量排放率的获得:每个时间间隔中输入速度、加速度、坡度、车上乘客数量,通过步骤s3中长短记忆神经网络模型得到当前的质量排放率,隐藏层的节点数量和迭代训练次数可通过多次试验后得到较优值;s42,平均排放因子的计算:将质量排放率的实测值、长短记忆门网络模型的估计值分别进行累加,并除以对应的运行距离,从而得到其单位距离上的排放量。实施例2以江苏省镇江市的四条公交常规和新能源公交线路为例进行污染气体排放量测算。首先进行基础数据获取,车辆排放气体中co、hc、nox和co2气体的体积浓度采用了autoplus5-2汽车尾气分析仪随车实时进行采集,并采用gps16-hvs仪器实时采集在排放测量时的测试车辆的速度,同时通过人工跟车的方法,记录上下车乘客和到站时间,匹配出车上乘客数据,最终将三部分数据在时间上进行同步。采集数据在2016年4月11日到15日这五个工作日进行,采集时间内天气基本一致。对油电混合动力公交车(gehe)、压缩天然气公交车(cng)、欧标4级(euro4)、欧标5级公交车(euro5)分别采集了三部分数据,表1是这四种公交车辆的线路信息。每种车型采集的数据都大于6000秒,表2是采集到的样本量大小及各车型各个参数的描述性统计指标。注意到本发明提出的测算方法所具有的时间相关性,训练数据集和测算数据集必须是时间上连续的,所以样本分为两部分,每部分时间均为3000s左右,一部分用于建模,一部分用于测算。表1实施例中四种公交车辆线路信息线路名称站点数燃油类型始发站终点站线路长度122油电混合动力(gehe)科技新城东迎江桥12.5km5128压缩天然气(cng)科技新城东行政中心14.4km10526欧标4级(euro4)火车站双汇12.6km22133欧标5级(euro5)宗泽路江科大西16.5km表2实施例中采集到的样本量大小及各车型各个参数的描述性统计指标其次进行基础数据预处理工作,其中包括了各类污染气体质量排放率转化和数据标准化两大部分。各类污染气体质量排放率转化指将数据采集过程中所得到的co、hc、nox和co2污染气体体积浓度转换成相应的单位时间内污染气体排放质量,对于以汽油为燃料的车辆,各类污染气体质量排放率的计算公式如下:cogk=(mair+mfuel)×mco/mexhaust×co%×10-2hcg/s=(mair+mfuel)×mhc/mexhaust×hcppm×10-2其中,mco为co的分子量;mhc为排放气体中未完全燃烧的hc的分子量,hc为碳氢化合物;为nox的分子量;为co2的分子量;hcppm为排放气体中碳氢化合物的气体体积浓度;co%为排放气体中一氧化碳的体积百分比;为排放气体中氮氧化合物的体积浓度;co2%为排放气体中二氧化碳的体积百分比;mair和mfuel分别为单位时间空气和燃料的消耗质量;mexhaust为尾气的分子量,用下式计算:其中,k为转换系数,所述k的计算公式为:k=[1+0.005×(co%+co2%)×y-0.01×h2%]-1h2%计算公式为:h2%=[0.5×y×co%×(co%+co2%)]/[co%+3×co2%]其中,o2%为排放气体中氧气的体积百分比,h2%为排放气体中氢气的体积百分比。数据标准化的目标是将有量纲的变量调整为大小相近的无量纲变量,从而来加快排放测算模型训练过程中的收敛速度和准确性。z-score标准化方法和将非标准的正态分布转化为均值为0,方差为1的标准正态分布的过程比较相似,主要是将原始数据减去均值后除以标准差,从而使数据围绕0上下波动,公式如下:其中,ei是原始数据;ei′是标准化后的数据;是原始数据的均值;s是原始数据的标准差。值得注意的是,这里实施例中还运用双样本t检验方法来检验新能源公交车与传统能源公交车,新能源公交车之间,传统能源公交车之间四类污染物是否有显著的差别,公式如下:h0:μ1-μ2=0ha:μ1-μ2≠0假设h0可以拒绝,当时,其中μ1和μ2为总体的均值,和为样本的均值,n1和n2为样本容量,和为两样本,α是置信水平,tα/2是100(1-α/2)置信度下的标准t分布值。表3实施例中双样本t检验结果表中给出的是各个t检验最后得到的p值,所有的p值均小于0.05,从中可以得出结论,不同车型间的各类气体质量排放率具有显著性差异,因此对于不同车型的各类排放气体分别建立模型具有必要性。接着是数据建模工作,包括基于长短期记忆神经网络的模型构建。实施例中将输入层节点数设置为4,对应速度、加速度、坡度、车上乘客数四个输入变量,输出层节点数设置为1,对应输出的气体的质量排放率,隐藏层的节点数量设置为8,并经过1000次迭代训练后得到不同车型的不同排放气体的模型。最后需要进行应用分析工作,包括污染气体质量排放率的获得和平均排放因子的计算,另外,实施例中将此发明方法与传统排放预测方法进行了比较。这里传统的预测方法指的是比功率排放测算模型。车辆比功率(vehiclespecificpower,以下简写为vsp)是用来表征车辆运行过程中动力学特性的指标,对于实施例中的情景,vsp的计算公式可简化成:其中,m为测试车辆质量,v为测试车辆实时速度,a为测试车辆实时加速度,ε为质量因数;为垂直高度与斜坡的长度比,g为重力加速度,cr为滚动摩阻系数(无量纲),cd为阻力系数;a为车辆的最大截面面积,ρa环境空气的密度。vsp多项式回归模型是在车辆比功率基础上,对车辆vsp,vsp的二次方、三次方进行线性回归来预测车辆的即时质量排放率。er=a×vsp3+b×vsp2+c×vsp+d其中,er是各种污染气体的排放率,a,b,c,d是系数。长短期记忆神经网络模型和比功率多项式回归模型的训练过程都是基于选取的一系列连续的训练集数据上进行的,在训练之后将得到模型同样运用于连续的测试数据集。另外,两类模型的预测结果中小于0的数值不符合质量排放率的物理含义,所以这些数据被调整成0。图3至图6为四种类型公交车辆的四类排放气体120秒的逐秒质量排放率实测数据、对应的长短期记忆神经网络模型预测数据、比功率多项式回归模型预测数据的拟合图。从中可以得出结论:长短期记忆神经网络预测模型具有更好的预测效果。另一方面,由于其考虑了排放的时间相关性,预测模型相较于比功率回归模型的曲线更加光滑,这个特性也比较符合实际情况。同时,为了更准确的预测模型,实施例中引入了模型预测准确性评价指标均方根误差rmse和标准化均方根误差nrmse,其计算公式如下:其中n是样本总数,和yi分别是预测排放量和测量排放量,ymax和ymin分别是测量的最大排放量和最小排放量。表4是计算结果。表4实施例中rmse和nrmse的计算从指标上也可以发现对于不同车型的各类污染气体,长短期记忆神经网络模型都有着更好的预测效果,其标准化均方根误差约在vsp回归模型的一半左右。为了更进一步从统计的角度说明长短期记忆神经网络模型相比vsp模型具有显著优势,这里实施例还对两类模型的预测误差进行了t检验。由于误差具有对应性,因此使用的是配对样本t检验。其公式如下:h0:μ=μ0ha:μ≠μ0假设h0可以拒绝,当时,其中μ为样本均值,为配对样本差值的平均数,为配对样本差值的标准偏差,n为配对样本数,α是置信水平,tα/2是100(1-α/2)置信度下的标准t分布值。表5实施例中配对样本t检验从t检验的结果来看,两类模型的误差在5%显著度下显著不同,可以说明长短期记忆神经网络模型质量排放率上的预测效果显著优于vsp回归模型。除了在微观层面的比较之外,本实施例最后对两类模型宏观层面上的预测效果运用平均排放因子进行比较分析。平均排放因子的计算是将质量排放率的实测值、长短期记忆神经网络模型的估计值、vsp回归模型的估计值分别进行累加,并除以对应的运行距离,从而得到其单位距离上的排放量。图7至图10的柱状图表现的是不同车型各类污染气体的平均排放因子实测值和两类模型估计值的平均排放因子。要注意的是平均排放因子的大小往往受到车辆在运行过程中的状态影响,图中的平均排放因子大小无法表征不同车型不同气体排放因子的普遍情况。从这些图中可以发现长短期记忆神经网络模型在平均排放因子的预测上相较vsp模型更加准确。以上显示和描述了本发明的基本原理、主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实例的限制,上述实例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等同物界定。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1