基于局部属性和拓扑结构的脑网络聚类方法与流程
本发明属于机器学习技术领域,特别是涉及一种基于局部属性和拓扑结构的脑网络聚类方法。
背景技术:
目前,机器学习作为脑网络分析的重要工具,由于能够从数据中学习规律并对未知数据进行预测,已成为近年来脑网络分析领域一个新的研究热点;机器学习按照学习形式的不同分为有监督学习(分类)和无监督学习(聚类)。
目前的研究,大部分都使用有监督学习,即使用带有标签的训练数据训练分类模型,然后用分类模型对测试数据进行分类;但是,由于数据的标签是由专业人员根据一些先验知识进行标注的,带有主观性,并且在标注的过程中可能会出现差错,最终影响分类结果,降低脑网络分类的准确性。
基于此,有必要发明一种脑网络聚类方法,以解决现有脑网络分类中存在的分类出现偏差、分类结果不准确的问题。
技术实现要素:
本发明的目的在于提供一种基于局部属性和拓扑结构的脑网络聚类方法,以克服监督学习中存在的标签标注不准确的问题,使得脑网络相似度聚类结果更加精准。
本发明所采用的技术方案是,基于局部属性和拓扑结构的脑网络聚类方法,具体包括以下步骤:
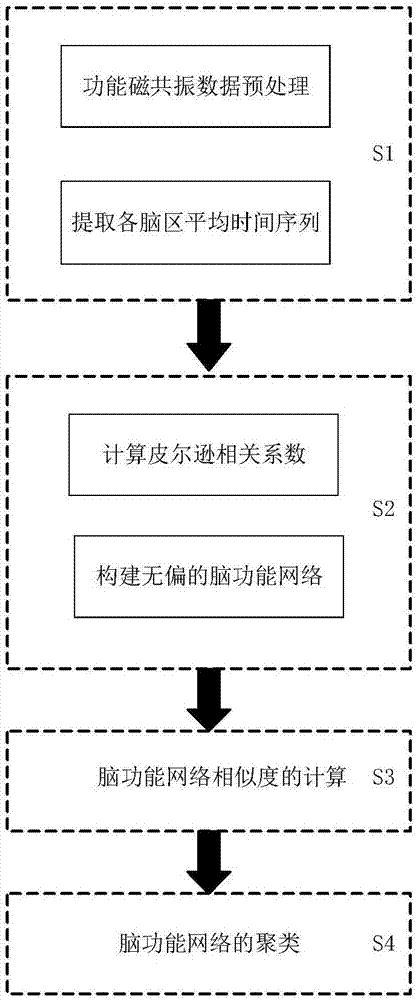
步骤s1:对脑功能磁共振图像进行预处理,然后进行脑区分割,并提取各个脑区的平均时间序列;
步骤s2:计算各个脑区平均时间序列之间的皮尔逊相关系数,得到皮尔逊相关矩阵;利用克鲁斯卡尔算法得到无偏的脑功能网络;
步骤s3:计算无偏脑功能网络的局部属性相似度和拓扑结构相似度,并对局部属性相似度和拓扑结构相似度进行加权融合,得到脑功能网络的相似度;
步骤s4:利用脑功能网络的相似度构建相似矩阵,对相似矩阵使用多路谱聚类算法,实现脑网络的聚类。
进一步的,步骤s1中,使用dparsf软件对脑功能磁共振图像进行预处理,预处理具体包括:移除前10个时间点、时间点校正、头动校正、空间标准化、平滑、去线性漂移和滤波;然后根据选定的标准化脑图谱-aal模板,对预处理后的脑功能磁共振图像进行分割,将大脑分为90个脑区;最后,依据预处理后的脑功能磁共振图像的数据,分别提取并计算每个脑区内部各个体素在不同时间点上的激活值及其平均值,得到每个脑区的平均时间序列;所述激活值是指各个体素在不同时间点上的血氧水平依赖强度。
进一步的,步骤s2中,构建无偏的脑功能网络包括以下步骤:
步骤s21:利用公式(1)计算两个脑区之间的皮尔逊相关系数rxy,
公式(1)中,1≤n≤n,n表示时间点个数,xn表示脑区x在第n个时间点的激活值,
步骤s22:利用克鲁斯卡尔算法按照如下描述构建无偏的脑功能网络:(1)将皮尔逊相关矩阵r中的相关系数进行降序排序;(2)将相关系数最大的节点连接起来,直至所有节点以无环子图的形式连接为止;(3)如果在步骤(2)中添加该连接后,出现了环路,则放弃该连接。
进一步的,步骤s3中,无偏的脑功能网络相似度的计算步骤如下:
步骤s31:使用公式(2)计算网络中每个节点的介数值b,使用公式(3)计算脑网络局部属性的相似度satr(g,h);
公式(2)中,v表示脑网络中节点的个数,v表示所有节点组成的集合,ρad表示节点a和节点d之间的最短路径长度,
公式(3)中,1≤m≤v,bm(g)表示脑网络g中第m个节点的介数,bm(h)表示脑网络h中第m个节点的介数,satr(g,h)表示脑网络g和脑网络h局部属性相似度;
步骤s32:利用weisfeiler-lehman图核计算脑网络在拓扑结构上的相似度;
weisfeiler-lehman图核计算方法如下:①定义脑网络中每个节点的初始标签为节点的度值;②对每个节点的相邻节点的标签进行排序,而后扩充到该节点,并把这个长的标签更新为一个新的未出现标签;③重复步骤②,直到迭代次数达到预定值h;④使用公式(4)计算脑网络g和脑网络h的weisfeiler-lehman子树核,即脑网络g和脑网络h的拓扑结构相似度sstr(g,h):
公式(4)中,k(g,h)表示脑网络g和脑网络h的图核值,
其中,
公式(5)中,h表示迭代的次数,σ0(g,s01)表示在第0次迭代时标签s01在图g中出现的次数,
公式(6)中,σ0(h,s01)表示在第0次迭代时标签s01在脑网络h中出现的次数,
步骤s33:设定权值δ,δ∈(0,1),将局部属性相似度与拓扑结构相似度结合计算出脑网络g和脑网络h的相似度s(g,h),公式(7)如下所示:
s(g,h)=δsatr(g,h)+(1-δ)sstr(g,h)(7)。
进一步的,步骤s4中,实现脑网络聚类的步骤如下:
步骤s41:利用脑网络的相似度构建脑网络的相似矩阵s,如式(8)所示:
式(8)中,sgh表示脑网络g和脑网络h之间的相似度,u表示脑网络的数量;
步骤s42:利用多路谱聚类算法即njw算法,实现脑网络的聚类,具体算法如下:首先根据相似矩阵s构建邻接矩阵w和度矩阵d,以此计算拉普拉斯矩阵l=d-w;然后对拉普拉斯矩阵标准化得到
步骤s43:使用公式(9)、(10)和(11)分别计算脑网络聚类结果的精准率p,召回率r和f1值;
公式(9)、(10)和(11)中,tp表示真阳性个数,tn表示真阴性个数,fp表示假阳性个数,fn表示假阴性个数。
本发明的有益效果是:⑴通过构建脑网络模型,计算脑网络之间的相似度以及使用谱聚类算法实现了脑网络的自动聚类;⑵充分考虑脑网络在局部属性和全局拓扑结构两方面的相似性,构建了一种计算脑网络相似度的方法,能较准确的计算脑网络之间的相似度,提高脑网络聚类的准确性。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是基于局部属性和拓扑结构的脑网络聚类模型流程图。
图2是本发明与仅考虑局部属性或拓扑相似度的聚类结果对比图。
图3是权值δ的不同取值对聚类结果精准率的影响。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例1
⑴实验数据
以阿尔茨海默症和正常老年人为例,对两类被试的脑网络进行聚类分析;研究数据来自阿尔茨海默病神经成像倡议(adni)数据库,包括28名阿尔茨海默症患者(年龄:72.2±7.5,女性:17名,简易智力状况检查法(mmse):22.8±2.5,临床痴呆评定量表(crd):0.84±0.23),28名正常老年人(年龄:74.3±6.3,女性:17名,mmse:28.9±1.3,crd:0±0);
⑵实验过程
按照图1所示的流程,采用如下步骤对56名被试的脑网络进行聚类:
步骤s1:对脑功能磁共振图像进行预处理,然后进行脑区分割,并提取各个脑区的平均时间序列;
使用dparsf软件对脑功能磁共振图像进行预处理,预处理的步骤具体包括:移除前10个时间点、时间点校正、头动校正、空间标准化、平滑、去线性漂移和滤波;然后根据选定的标准化脑图谱,对预处理后的脑功能磁共振图像进行分割,将大脑分为90个脑区;研究表明,阿尔茨海默症的受损脑区主要集中在默认模式网络(dmn),所以在本实施例中提取被试的默认模式网络进行研究,从90个脑区中提取默认模式网络包含的32个脑区(眶部额上回、额中回、眶部额中回、回直肌、前扣带和旁扣带脑回、后扣带回、楔前叶、海马、海马旁回、顶下缘角回、角回、颞上回、颞极:颞上回、颞中回、颞极:颞中回、颞下回)进行研究;
最后,依据预处理后的脑功能磁共振图像的数据,分别提取并计算每个脑区内部各个体素在不同时间点上激活值的平均值,得到每个脑区的平均时间序列;激活值是指各个体素在不同时间点上的血氧水平依赖强度;
步骤s2:计算各个脑区平均时间序列之间的皮尔逊相关系数,使用克鲁斯卡尔算法,得到无偏的脑功能网络;
使用公式(1)计算两两脑区之间的皮尔逊相关系数rxy:
公式(1)中,1≤n≤n,n表示时间点个数,xn表示脑区x在第n个时间点的激活值,
利用克鲁斯卡尔算法按照下列描述构建无偏的脑网络:(1)将皮尔逊相关矩阵的相关系数进行降序排序;(2)将相关系数最大的节点连接起来,直至所有节点以无环子图的形式连接为止;(3)如果在步骤(2)中添加该连接后,出现了环路,则放弃该连接;
步骤s3:计算无偏的脑功能网络之间的相似度;
使用公式(2)计算网络中每个节点的介数值b,使用公式(3)计算脑网络局部属性的相似度satr(g,h);
公式(2)中,v表示脑网络中节点的个数,v表示所有节点组成的集合,ρad表示节点a和节点d之间的最短路径长度,
公式(3)中,1≤m≤v,bm(g)表示图g中第m个节点的介数,bm(h)表示图h中第m个节点的介数,satr(g,h)表示图g和图h局部属性相似度;
利用weisfeiler-lehman子树核计算脑网络在拓扑结构上的相似度,weisfeiler-lehman图核计算方法如下:
①定义脑网络中每个节点的初始标签为节点的度值;②对每个节点的相邻节点的标签进行排序,而后扩充到该节点,并把这个长的标签更新为一个新的未出现标签;③重复步骤②,直到迭代次数达到预定值h;④使用公式(4)计算脑网络g和脑网络h的weisfeiler-lehman子树核,即脑网络g和脑网络h的拓扑结构相似度sstr(g,h):
公式(4)中,k(g,h)表示脑网络g和脑网络h的图核值,
其中,
公式(5)中,h表示迭代的次数,σ0(g,s01)表示在第0次迭代时标签s01在图g中出现的次数,
公式(6)中;σ0(h,s01)表示在第0次迭代时标签s01在图h中出现的次数,
设定权值δ,δ∈(0,1),将局部属性相似度与拓扑相似度结合计算得到脑网络的相似度,公式(7)如下所示:
s(g,h)=δsatr(g,h)+(1-δ)sstr(g,h)(7);
步骤s4:利用脑网络的相似度构建脑网络的相似矩阵s,如式(8)所示:
式(8)中,sgh表示脑网络g和脑网络h之间的相似度,u表示脑网络的数量;
利用多路谱聚类算法即njw算法,实现脑网络的聚类,并使用精准率,召回率和f1评价聚类性能:
首先计算得到相似矩阵s,根据相似矩阵s构建邻接矩阵w和度矩阵d,以此计算拉普拉斯矩阵l=d-w;然后对拉普拉斯矩阵标准化得到
使用公式(9)、(10)和(11)分别计算脑网络聚类结果的精准率p,召回率r和f1值;
公式(9)、(10)和(11)中,tp表示真阳性个数,tn表示真阴性个数,fp表示假阳性个数,fn表示假阴性个数;
⑶实验结果
为了检验权值δ的取值对聚类结果的影响,将步骤3中的权值δ设置为从0.1到0.9,步长为0.1,取得不同的基于局部属性和拓扑结构的脑网络相似度,对各相似度进行聚类分析,聚类结果的精准率如图3所示,由图3可知,按照δ=0.7将局部属性相似度和拓扑结构相似度结合能更准确的描述脑网络之间的相似度。
实施例2
实施例1中步骤3的权值取0.7,对步骤3取得的各相似度:satr(g,h)、sstr(g,h)和s(g,h)使用聚类算法进行聚类,并计算聚类结果的精准率、召回率和f1值,对其进行检验;
各聚类结果的精准率、召回率和f1值如图2所示,由图2可知,将局部属性相似度和拓扑结构相似度加权结合后的脑网络相似度聚类效果最好,精准率为0.64,召回率为0.62,f1为0.63。
本说明书中的各个实施例均采用相关的方式描述,各个实施例之间相同相似的部分互相参见即可,每个实施例重点说明的都是与其他实施例的不同之处。尤其,对于系统实施例而言,由于其基本相似于方法实施例,所以描述的比较简单,相关之处参见方法实施例的部分说明即可。
以上所述仅为本发明的较佳实施例而已,并非用于限定本发明的保护范围。凡在本发明的精神和原则之内所作的任何修改、等同替换、改进等,均包含在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!