一种基于LSTM和知识图谱的英文期刊推荐方法与流程
本发明涉及智能搜索和推荐技术领域,尤其涉及一种基于lstm和知识图谱的英文期刊推荐方法。
背景技术:
2018年公布的上万本sci期刊数据库中,96%的细分研究领域有超过10本sci期刊,最多期刊的研究领域达到了353本(经济学领域)。面对如此众多的sci期刊,如果没有丰富的论文发表经验,将可能在投稿前选择目标期刊时无从下手。如果不能精准地找到适合自己论文的英文期刊,不仅不会让论文顺利发表,而且长达3-6个月的审稿极大地延误了发表时间。基于以上困难,本专利提供了一种快速准确的英文期刊推荐方法,用户可输入论文题目和摘要进行内容匹配,并可选择审稿时间区间(比如3个月内),中国人录用比例(比如50%以上),影响因子(比如2以上)进行筛选和排序期刊。结果排序输出符合要求的sci期刊。
技术实现要素:
针对现有的技术空白和缺点,本发明提出了一种英文期刊推荐方法。该方法能为用户快速、精准地匹配适合发表篇英文论文的英文期刊,并可以根据不同要求设置不同权重进行推荐期刊的排序,从而优化选择期刊。
一种基于lstm和知识图谱的英文期刊推荐方法,其包括以下步骤:
s1:首先从各个英文期刊所在搜索数据库中获取论文题目和摘要信息并形成论文集存储;同时建立每篇论文与所属期刊之间的论文-期刊映射关系;
s2:对提取到的论文题目和摘要,利用lstm(longshorttermmemory)模型对论文的内容和写作风格进行特征表示,形成每篇论文的特征表示向量,具体包含以下子步骤:
s201:对于论文集中所有论文,利用nltk(naturallanguagetoolkit)工具进行单词分割,剔除掉停用词、特殊字符、出现频率低于频率阈值的词,为论文集构造一个词典d,d中的单词总个数为|d|;
s202:对于词典d中的每个单词,利用one-hot编码构成稀疏特征表示矩阵,生成词编码矩阵x∈r|d|*|d|,词编码矩阵的元素xij表示第i个单词第j列为1,其他为0;
s203:对于词典d中的每个单词,构造词向量矩阵m∈r|d|×k,k为每个单词的低维特征表示长度,每个单词的低维特征用公式xi=xim计算,其中xi为第i个单词的低维特征,xi为第i个单词的词编码向量矩阵,m为词向量矩阵;
s204:对于每一篇论文d={a1,a2,a3,…,an},n为所述论文的单词个数,ai表示所述论文的第i个单词,首先经过词编码矩阵x,提取论文中的每个单词的词编码向量矩阵,然后生成整篇论文的词向量矩阵i∈rn×k,并将其作为lstm模型的输入计算所述论文的特征表示向量;
s205:对论文集中的每篇论文进行步骤s204的操作后,形成论文集中所有论文的特征表示向量o∈rn×l,其中n为论文集中论文的总篇数,l为每篇论文的特征表示向量的长度;
s3:对于用户提交论文q,进行步骤s201-s204的操作,计算得到该论文的特征表示向量vq;对论文集中的所有论文进行聚类,并判断用户提交论文q所属的类别;利用欧式距离计算用户提交论文q与其所属类别下所有论文的相似度,构成1×|ck|的相似向量,|ck|为用户提交论文q所属的第k个类别下的论文数量,取相似度最高的p篇论文,利用论文-期刊映射关系生成候选期刊列表l1;
s4:对论文集构建论文知识图谱,并结合用户提交论文的引用论文数据,提取所属领域的期刊,形成候选期刊列表l2,具体包括以下子步骤:
s401:从论文集中每篇论文的论文摘要和引言中,利用nltk抽取关键词,对每个关键词提取其词特征向量,然后利用回归模型计算每个关键词属于要提取的实体的概率pw,计算过程为:
其中wi为权重向量,x`i为第i个关键词的词特征向量,n1为每篇论文中抽取的关键词的总数;
基于计算得到的概率,通过设定概率阈值后确定抽取到的实体;
s402:提取实体的词特征向量,并利用深度神经网络建立实体间的关系模型,计算过程为:
其中
s403:基于上述s402的计算过程,首先建立实体-实体间的知识图谱,然后融合第一作者、期刊和合作者构建完整的知识图谱,所构造的知识图谱利用rdf文件形式进行存储;
s404:分析用户提交论文的引用论文数据,并利用s401的方法从用户提交论文中抽取实体,然后利用知识推理技术,从知识图谱中提取用户提交论文所属领域的期刊,形成候选期刊列表l2;
s5:获取用户的期刊查询关键内容,所述关键内容包括若干用户对期望投稿期刊的查询关键词,允许用户为不同查询关键词设置不同的重要性权重
s6:将候选期刊列表l1和l2进行合并,利用网络爬虫采集合并列表中每个期刊对应的包括所述查询关键词在内的关键内容向量t;
s7:计算用户查询的关键内容向量r与候选期刊的关键内容向量t的相关度,并基于排序结果返回若干个匹配度最高的期刊进行推荐。
作为优选,s1中的论文题目和摘要信息通过针对不同的英文期刊所在搜索数据库制定网页爬虫规则,进行自动获取。
作为优选,s2中所述的停用词是指使用频率非常高的词。
作为优选,s3中所述的聚类是指对获取的论文集的特征向量进行聚类分析,将相似内容和风格的论文聚成不同的群体,具体计算过程如下:
s301:对于n×l的输入矩阵o,首先随机生成的l个聚类中心ck,k∈[1,l];
s302:计算每篇论文特征向量oi到所有聚类中心ck的欧式距离,将每篇论文归属到聚类最近的类中;
s303:重新计算新的聚类中心点,计算过程为:
其中|ck|为第k个类别下的论文数量,
s304:重复s301-s303,直到聚类中心点的误差小于预设阈值,即
作为优选,s304中所述的预设阈值τ的取值为0.00001。
作为优选,s4中深度神经网络的层数为5,可根据实际情况进行调整。
作为优选,s5中所述的查询关键词包括jcr分区、可接受审稿周期、影响因子、作者所属国籍的投稿人录用比例。
作为优选,s7中利用加权的余弦相似度计算方法计算用户查询的关键内容向量r与候选期刊的关键内容向量t的相关度,其中加权余弦相似度计算方法为:
其中ti和ri分别为t和r中的第i个元素。
与传统的推荐方法相比,本发明的一种基于lstm和知识图谱的英文期刊推荐方法,能够让用户快速、精准地匹配适合发表的英文论文的英文期刊,并可以根据不同要求设置不同权重进行推荐期刊的排序。
附图说明
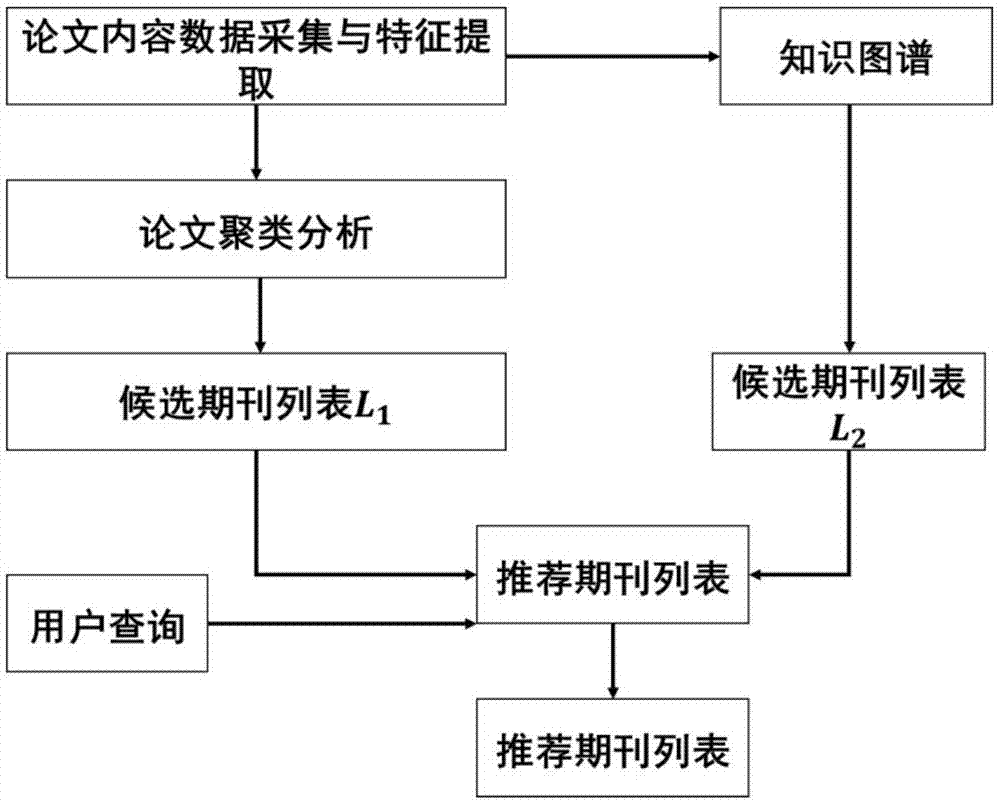
图1是本发明的流程示意图;
具体实施方式
下面结合附图和具体实施例对本发明做进一步阐述。
如图1所示,一种基于lstm和知识图谱的英文期刊推荐方法,包括以下步骤:
s1:首先通过针对不同的英文期刊所在搜索数据库制定网页爬虫规则,自动从各个英文期刊所在搜索数据库中获取论文题目和摘要信息并形成论文集存储;同时建立每篇论文与所属期刊之间的论文-期刊映射关系;
s2:对提取到的论文题目和摘要,利用lstm模型对论文的内容和写作风格进行特征表示,形成每篇论文的特征表示向量<期刊id、论文id、论文特征表示向量>,具体包含以下子步骤s201~s205:
s201:对于论文集中所有论文的论文题目和摘要,利用nltk工具进行单词分割,剔除掉停用词、特殊字符、出现频率低于频率阈值的词后,为论文集构造一个词典d,d中的单词总个数为|d|;停用词是指那些使用频率非常高的词,如the、a、an等;特殊字符是指数学符号、图形文字等;频率阈值可以根据实际进行调整;
s202:对于词典d中的每个单词,利用one-hot编码构成稀疏特征表示矩阵,生成词编码矩阵x∈r|d|*|d|,词编码矩阵的元素xij表示第i个单词第j列为1,其他元素为0;
s203:对于词典中的每个单词,构造词向量矩阵m∈r|d|×k,k为每个单词的低维特征表示长度,每个单词的低维特征用公式xi=xim计算,其中xi为第i个单词的低维特征,xi为第i个单词的词编码向量矩阵,m为词向量矩阵;
s204:对于每一篇论文d={a1,a2,a3,…,an},n为所述论文的单词个数,ai表示所述论文的第i个单词,首先经过词编码矩阵x,提取论文中的每个单词的词编码向量矩阵,然后生成整篇论文的词向量矩阵i∈rn×k,并将其作为lstm模型的输入计算所述论文的特征表示向量;
s205:对论文集中的每篇论文进行步骤s204的操作后,形成论文集中所有论文的特征表示向量o∈rn×l,其中n为论文集中论文的总篇数,l为每篇论文的特征表示向量的长度;
s3:对于用户提交论文q,进行步骤s201-s204的操作,计算得到该论文的特征表示向量vq;对论文集中的所有论文进行聚类,并判断用户提交论文q所属的类别;利用欧式距离计算用户提交论文q与其所属类别下所有论文的相似度,构成1×|ck|的相似向量,|ck|为用户提交论文q所属的第k个类别下的论文数量,取相似度最高的p篇论文,利用论文-期刊映射关系生成候选期刊列表l1;p的具体取值可以根据实际进行调整;
本步骤中的聚类是指对获取的论文集的特征表示向量进行聚类分析,将相似内容和风格的论文聚成不同的群体,本发明采用k-mean聚类算法进行聚类。具体计算过程如下s301~s304:
s301:对于n×l的输入矩阵o,首先随机生成的l个聚类中心ck,k∈[1,l];
s302:计算每篇论文特征向量oi到所有聚类中心ck的欧式距离,将每篇论文归属到聚类最近的类中;
s303:重新计算新的聚类中心点,计算过程为:
其中|ck|为第k个类别下的论文数量,
s304:重复s301-s303,直到聚类中心点的误差小于预设阈值,即
s4:对论文集构建论文知识图谱,并结合用户提交论文的引用论文数据,提取所属领域的主要期刊,形成候选期刊列表l2,具体包括以下子步骤s401~s404:
s401:从论文集中每篇论文的论文摘要和引言中,利用nltk抽取关键词,对每个关键词提取其词特征向量,然后利用回归模型计算每个关键词属于要提取的实体的概率pw,计算过程为:
其中wi为权重向量,x`i为第i个关键词的词特征向量,n1为每篇论文中抽取的关键词的总数;
基于计算得到的概率,通过设定概率阈值后确定抽取到的实体;概率阈值也可以根据实际调整;
s402:提取实体的词特征向量,并利用深度神经网络建立实体间的关系模型,计算过程为:
其中
s403:基于上述s402的计算过程,首先建立实体-实体间的知识图谱,然后融合第一作者、期刊和合作者构建完整的知识图谱,所构造的知识图谱利用rdf文件形式进行存储;
s404:分析用户提交论文的引用论文数据,并利用s401的方法从用户提交论文中抽取实体,然后利用知识推理技术,从知识图谱中提取用户提交论文所属领域的期刊,形成候选期刊列表l2;
s5:获取用户的期刊查询关键内容,所述关键内容包括若干用户对期望投稿期刊的查询关键词,本发明中允许用户为不同查询关键词设置不同的重要性权重
s6:将候选期刊列表l1和l2进行合并形成初步的推荐期刊列表,利用网络爬虫采集合并列表中每个期刊对应的包括上述查询关键词在内的关键内容向量t;
s7:计算用户查询的关键内容向量r与候选期刊的关键内容向量t的相关度,并基于排序结果返回若干个匹配度最高的期刊进行推荐。相关度的计算可利用加权的余弦相似度计算方法,具体方法为:
其中ti和ri分别为t和r中的第i个元素。
下面将上述方法应用于具体实施例中,以便本领域技术人员能够更好地理解本发明的效果。
实施例
下面基于上述方法进行实验,本实施例的实现方法如前所述,不再详细阐述具体的步骤。下面仅以一个案例为例,展示其应用本发明方法得到的推荐结果。
本实施例按照s1的方式抓取了7千万篇论文题目和摘要组成大数据库,按照本发明的上述s1~s7方法进行步骤执行。
其中用户提交的论文题目为:
adual-functionalretrofittingmethodforcorrodedreinforcedconcretebeams
论文摘要为:
corrosionofsteelre-barsinreinforcedconcrete(rc)structuresisasignificantfactorinstructuredeterioration.impressedcurrentcathodicprotection(iccp)isanefficientmethodtopreventfurthercorrosionofthere-bars,whilebondingcfrptothercstructurescanhelpimprovetheloadingcapacityofthedamagedstructures.thisstudyproposesanewdual-functionalmethodtoretrofitthercstructuresbyusingthecarbon-fiberreinforcedcementitiousmatrix(c-frcm).thec-frcmcomposite,comprisedofcfrpmeshandinorganiccementitiousmaterial,isboththeanodicmaterialintheiccpprocessaswellasthestructuralstrengtheningmaterial.thispaperpresentsanexperimentalprogramconsistingof11simplysupportedbeams,10ofthemsubjectedtoacceleratedcorrosionprocessfor130days.thecorrodedspecimenswereafterwardsbondedwithc-frcmcomposite,protectedbyiccpfor130days,andfinallytested.inthisstudy,theflexurestrengthofthebeams,thedeflectionandcurvatureofthespecimens,thestrainofre-bars,themasslossofthere-bars,andtheopencircuitpotentialofre-barsareobtainedandusedtoassesstheperformanceoftherepairedspecimens.theproposedtechniquehasbeenshowntobeeffectiveinretardingthecorrosionofsteelandrecoveringtheloadingcapacityofthecorrodedspecimens.inaddition,thispaperalsopresentsacomparisonoftheexperimentalresultsandthecapacitypredictionsbytheinternationaldesignguidelineaci440.2r-08.theexistingdesignmethodhasbeenshowntobeonlyslightlyconservativefortheflexuraldesignofretrofittedbeams.theproposedrepairmethodwillbebeneficialforthedurabilityofrcstructures,especiallythosewithcontaminatedchloridesorthoselocatedinamarineenvironment,whereasmoreinvestigationsontherationaldesignapproachesareneededinordertopromotetheuseofthisinnovativeretrofittingmethod.
选择的查询关键词为期刊影响因子、中国人发文比例、发表难度、审稿时间(月)、录用时间(月),得到最终的推荐结果如下:
表1最终推荐结果(按中国人发文比例排序)
综上所述,本发明方法能取得较理想的效果,让科研人员快速、精准地匹配适合发表篇英文论文的英文期刊,并可以根据不同要求设置不同权重进行推荐期刊的排序,对精准发表科研成果具有重要意义。
以上所述的实施例只是本发明的一种较佳的方案,然其并非用以限制本发明。有关技术领域的普通技术人员,在不脱离本发明的精神和范围的情况下,还可以做出各种变化和变型。因此凡采取等同替换或等效变换的方式所获得的技术方案,均落在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!