用户问句的补词方法和装置与流程
本说明书一个或多个实施例涉及自然语言处理领域,尤其涉及用户问句的补词方法和装置。
背景技术:
在智能客服的应用中,用户在与机器人通过语言进行交互的过程中通常用户语言口语化、简略化。经过对大量的用户问句的统计分析,其中包含字数在10个字以下的用户问句就占到了50%+,这种情况在用户首问中尤其明显,此时单纯依靠用户问句表述的字面信息和传统的自然语言处理(naturallanguageprocessing,nlp)技术难以理解用户意图。
现有技术中,针对这种难以理解用户意图的问句,通常还需要进一步向用户提问,经过与用户的多次交互才能理解用户意图,进而针对用户问句作出符合用户意图的解答。例如,有些用户直接发问“如何还款”,此时至少需再行确认是“信用卡”、“花呗”、“借呗”中的哪个具体业务,经过与用户的多次交互才能最终解决客户问题,增加了交互成本,且用户体验不佳。
因此,希望能有改进的方案,能够在不增加额外交互的情况下明确用户问句的意图,从而提升用户体验。
技术实现要素:
本说明书一个或多个实施例描述了一种用户问句的补词方法和装置,能够在不增加额外交互的情况下明确用户问句的意图,从而提升用户体验。
第一方面,提供了一种用户问句的补词方法,方法包括:
获取用户问句的场景埋点信息和/或所述用户问句的历史问句;
根据所述场景埋点信息和/或所述历史问句,确定对所述用户问句进行补词的候选词集合;
针对所述用户问句中的每个可选的补词位置和所述候选词集合中的每个候选词,生成多个新问句;
使用预先训练的语言模型,确定每个所述新问句的生成概率;
根据每个所述新问句的生成概率,确定所述候选词集合中的最优候选词和所述最优候选词在所述用户问句中的最佳补词位置;
将所述最优候选词按照所述最佳补词位置补入所述用户问句,得到所述用户问句的补词问句。
在一种可能的实施方式中,所述方法还包括:
根据所述补词问句,在问答引擎中挑选知识点作为所述用户问句的解答。
在一种可能的实施方式中,所述获取用户问句的场景埋点信息,包括:
将接收所述用户问句的入口所对应的业务场景作为所述场景埋点信息。
在一种可能的实施方式中,所述获取所述用户问句的历史问句,包括:
获取所述用户问句之前的预定数目个历史问句。
在一种可能的实施方式中,所述根据所述场景埋点信息和/或所述历史问句,确定对所述用户问句进行补词的候选词集合,包括:
确定所述场景埋点信息对应的当前业务场景;
根据预先建立的多个业务场景与多个关联分词的对应关系,确定当前业务场景对应的关联分词;
将所述当前业务场景对应的关联分词添加到对所述用户问句进行补词的候选词集合中。
进一步地,所述多个业务场景与多个关联分词的对应关系通过点互信息(pointwisemutualinformation,pmi)算法预先建立,该预先建立包括:
获取多个用户问句和每个用户问句对应的业务场景;
根据每个业务场景出现的频度计算场景概率,根据多个用户问句中每个分词出现的频度计算分词概率,根据每个业务场景和每个分词一起出现的频度计算业务场景和分词的联合概率;
根据业务场景和分词的联合概率、场景概率和分词概率,计算业务场景和分词的pmi值;
对于每个业务场景,将该业务场景和每个分词的pmi值进行由大到小排序,将排序在前预定数目位的分词作为该业务场景对应的关联分词。
在一种可能的实施方式中,所述根据所述场景埋点信息和/或所述历史问句,确定对所述用户问句进行补词的候选词集合,包括:
对所述历史问句进行分词和去停用词处理,将得到的分词添加到对所述用户问句进行补词的候选词集合中。
在一种可能的实施方式中,所述方法还包括:使用预先训练的语言模型,确定所述用户问句的生成概率;所述根据每个所述新问句的生成概率,确定所述候选词集合中的最优候选词和所述最优候选词在所述用户问句中的最佳补词位置,包括:如果一个所述新问句的生成概率最大且该新问句的生成概率与所述用户问句的生成概率的差值大于第一预设阈值,则确定该新问句对应的候选词为所述候选词集合中的最优候选词,以及确定该新问句对应的补词位置为所述最优候选词在所述用户问句中的最佳补词位置。
在一种可能的实施方式中,所述针对所述用户问句中的每个可选的补词位置和所述候选词集合中的每个候选词,生成多个新问句之前,所述方法还包括:
确定所述候选词集合不为空集;和/或
使用预先训练的语言模型,确定所述用户问句的生成概率大于或等于第二预设阈值。
在一种可能的实施方式中,所述语言模型为n-gram语言模型。
进一步地,所述n-gram语言模型用于评估生成一个句子的概率,并将所述概率对该句子中的单词数进行平均后,得到该句子的生成概率。
第二方面,提供了一种用户问句的补词装置,装置包括:
获取单元,用于获取用户问句的场景埋点信息和/或所述用户问句的历史问句;
第一确定单元,用于根据所述获取单元获取的所述场景埋点信息和/或所述历史问句,确定对所述用户问句进行补词的候选词集合;
第二确定单元,用于针对所述用户问句中的每个可选的补词位置和所述候选词集合中的每个候选词,生成多个新问句;使用预先训练的语言模型,确定每个所述新问句的生成概率;根据每个所述新问句的生成概率,确定所述候选词集合中的最优候选词和所述最优候选词在所述用户问句中的最佳补词位置;
补词单元,用于将所述第二确定单元确定的最优候选词按照所述第二确定单元确定的最佳补词位置补入所述用户问句,得到所述用户问句的补词问句。
第三方面,提供了一种计算机可读存储介质,其上存储有计算机程序,当所述计算机程序在计算机中执行时,令计算机执行第一方面的方法。
第四方面,提供了一种计算设备,包括存储器和处理器,所述存储器中存储有可执行代码,所述处理器执行所述可执行代码时,实现第一方面的方法。
通过本说明书实施例提供的方法和装置,首先获取用户问句的场景埋点信息和/或该用户问句的历史问句,然后根据场景埋点信息和/或历史问句,确定对该用户问句进行补词的候选词集合,此过程中无需与用户交互,再针对所述用户问句中的每个可选的补词位置和所述候选词集合中的每个候选词,生成多个新问句,以及使用预先训练的语言模型,确定每个所述新问句的生成概率,并根据每个所述新问句的生成概率,确定所述候选词集合中的最优候选词和所述最优候选词在所述用户问句中的最佳补词位置,最后将最优候选词按照最佳补词位置补入该用户问句,得到该用户问句的补词问句,通过语言模型使补词问句更能符合用户意图,能够在不增加额外交互的情况下明确用户问句的意图,从而提升用户体验。
附图说明
为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其它的附图。
图1为本说明书披露的一个实施例的实施场景示意图;
图2示出根据一个实施例的用户问句的补词方法流程图;
图3示出根据一个实施例的确定候选词集合的方法流程图;
图4示出根据一个实施例的语言模型过滤补词候选集的方法流程图;
图5为本说明书实施例提供的一种用户提问线上效果示意图;
图6为本说明书实施例提供的另一种用户提问线上效果示意图;
图7为本说明书实施例提供的另一种用户提问线上效果示意图;
图8示出根据一个实施例的用户问句的补词装置的示意性框图。
具体实施方式
下面结合附图,对本说明书提供的方案进行描述。
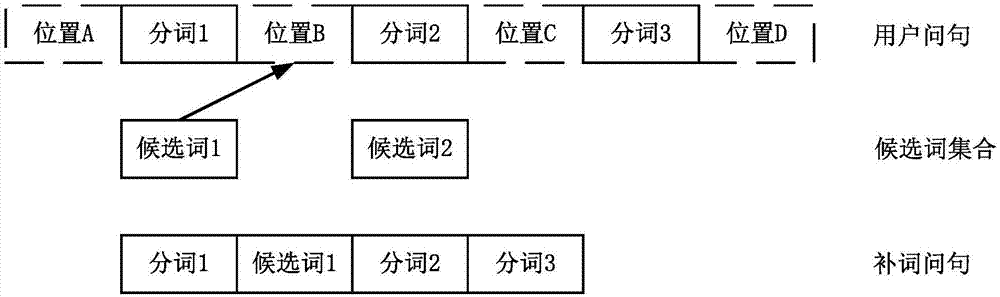
图1为本说明书披露的一个实施例的实施场景示意图。该实施场景涉及机器人客服应用中对用户问句进行补词处理,针对用户语言口语化、简略化无法明确用户意图的情况,本说明书实施例中提供了一种用户问句的补词方法,也就是说,将用户问句进行分词处理后,在首个分词前,相邻两个分词之间,以及最后一个分词之后均可以作为一个候选补词位置,本说明书实施例的目的就是寻找最优候选词以及最佳补词位置,以便将最优候选词按照最佳补词位置补入该用户问句,得到该用户问句的补词问句。
参照图1,一个用户问句经过分词处理后,得到该用户问句对应的分词依次为分词1、分词2和分词3,这三个分词对应四个候选补词位置,这四个候选补词位置分别记为位置a、位置b、位置c和位置d,如果根据场景埋点信息和/或历史问句(也可称为上文信息),确定出对该用户问句进行补词的候选词集合包括候选词1和候选词2,使用预先训练的语言模型,确定候选词集合中的最优候选词为候选词1,确定最佳补词位置为位置b,则将候选词1按照位置b补入该用户问句,得到该用户问句的补词问句包括的分词依次为分词1、候选词1、分词2和分词3,通过补词问句能够在不增加额外交互的情况下明确用户问句的意图,从而提升用户体验。
需要说明的是,上述机器人客服应用可以但不限于为电子商务平台的机器人客服应用,在一个典型的应用场景中,该电子商务平台包括多个业务场景,每个业务场景均有用于访问上述机器人客服应用的入口,在该场景下本说明书实施例提供的用户问句的补词方法可以根据场景埋点信息和/或历史问句确定出对该用户问句进行补词的候选词集合。
图2示出根据一个实施例的用户问句的补词方法流程图。如图2所示,该实施例中用户问句的补词方法包括以下步骤:步骤21,获取用户问句的场景埋点信息和/或所述用户问句的历史问句;步骤22,根据所述场景埋点信息和/或所述历史问句,确定对所述用户问句进行补词的候选词集合;步骤23,使用预先训练的语言模型,确定所述候选词集合中的最优候选词和所述最优候选词在所述用户问句中的最佳补词位置;步骤24,将所述最优候选词按照所述最佳补词位置补入所述用户问句,得到所述用户问句的补词问句。下面描述以上各个步骤的具体执行方式。
首先在步骤21,获取用户问句的场景埋点信息和/或所述用户问句的历史问句。可以理解的是,场景埋点信息用于指示用户问句基于的业务场景,并不是每个用户问句都具有场景埋点信息,例如,用户先进入机器人客服应用,然后通过机器人客服应用输入用户问句,其中,如果用户通过通用入口进入机器人客服应用时,就不具有用户问句的场景埋点信息。用户问句的历史问句即用户问句的上文信息,并不是每个用户问句都具有用户问句的历史问句,例如,用户先进入机器人客服应用,然后通过机器人客服应用输入用户问句,当用户问句为通过机器人客服应用首次输入的用户问句时,该用户问句就不具有历史问句。
在一个示例中,将接收所述用户问句的入口所对应的业务场景作为所述场景埋点信息。例如,用户从“我的客服”通用入口输入所述用户问句,则该入口没有对应的业务场景,用户从“借呗”入口输入所述用户问句,则该入口对应的业务场景为“借呗”场景。
在一个示例中,获取所述用户问句之前的预定数目个历史问句。后续可以针对每个历史问句确定候选词集合。
此外,本说明书实施例中,在获取用户问句的历史问句时还可以考虑时间因素,即预先设定获取用户问句的历史问句的有效时间,例如,设定上述有效时间为1个月或1天或1个小时或10分钟等,对于超出该有效时间的历史问句不进行获取。也就是说,对于与该用户问句间隔时间较长的历史问句不用来确定对该用户问句进行补词的候选词集合。
接着在步骤22,根据所述场景埋点信息和/或所述历史问句,确定对所述用户问句进行补词的候选词集合。可以理解的是,本说明书实施例中,可以仅根据所述场景埋点信息,确定对所述用户问句进行补词的候选词集合;或者,可以仅根据所述历史问句,确定对所述用户问句进行补词的候选词集合;或者,可以根据所述场景埋点信息和所述历史问句,确定对所述用户问句进行补词的候选词集合。其中,当有多个历史问句时,还可以分别根据每个历史问句,确定对所述用户问句进行补词的候选词集合,最终的候选词集合为分别确定的候选词集合的并集。
在一个示例中,在根据所述场景埋点信息,确定对所述用户问句进行补词的候选词集合时,首先根据先确定所述场景埋点信息对应的当前业务场景,然后根据预先建立的多个业务场景与多个关联分词的对应关系,确定当前业务场景对应的关联分词,再将所述当前业务场景对应的关联分词添加到对所述用户问句进行补词的候选词集合中。
其中,所述多个业务场景与多个关联分词的对应关系通过点互信息(pointwisemutualinformation,pmi)算法预先建立,该预先建立的过程包括:获取多个用户问句和每个用户问句对应的业务场景;根据每个业务场景出现的频度计算场景概率,根据多个用户问句中每个分词出现的频度计算分词概率,根据每个业务场景和每个分词一起出现的频度计算业务场景和分词的联合概率;根据业务场景和分词的联合概率、场景概率和分词概率,计算业务场景和分词的pmi值;对于每个业务场景,将该业务场景和每个分词的pmi值进行由大到小排序,将排序在前预定数目位的分词作为该业务场景对应的关联分词。
在一个示例中,在根据所述历史问句,确定对所述用户问句进行补词的候选词集合时,首先对所述历史问句进行分词和去停用词处理,然后将得到的分词添加到对所述用户问句进行补词的候选词集合中。
然后在步骤23,使用预先训练的语言模型,确定所述候选词集合中的最优候选词和所述最优候选词在所述用户问句中的最佳补词位置。可以理解的是,不同候选词或者同一候选词在用户问句中的不同位置,所形成的补词问句均不同,该步骤用于在确定候选词集合后寻找补词的最佳方案。
具体地,针对所述用户问句中的每个可选的补词位置和所述候选词集合中的每个候选词,生成多个新问句;使用预先训练的语言模型,确定每个所述新问句的生成概率;根据每个所述新问句的生成概率,确定所述候选词集合中的最优候选词和所述最优候选词在所述用户问句中的最佳补词位置。
在一个示例中,针对所述用户问句中的每个可选的补词位置和所述候选词集合中的每个候选词,生成多个新问句;使用预先训练的语言模型,确定每个所述新问句的生成概率和所述用户问句的生成概率;如果一个所述新问句的生成概率最大且该新问句的生成概率与所述用户问句的生成概率的差值大于第一预设阈值,则确定该新问句对应的候选词为所述候选词集合中的最优候选词,以及确定该新问句对应的补词位置为所述最优候选词在所述用户问句中的最佳补词位置。
其中,所述针对所述用户问句中的每个可选的补词位置和所述候选词集合中的每个候选词,生成多个新问句之前,所述方法还可以包括:确定所述候选词集合不为空集;和/或使用预先训练的语言模型,确定所述用户问句的生成概率大于或等于第二预设阈值。
在一个示例中,所述语言模型为n-gram语言模型。
进一步地,所述n-gram语言模型用于评估生成一个句子的概率,并将所述概率对该句子中的单词数进行平均后,得到该句子的生成概率。
最后在步骤24,将所述最优候选词按照所述最佳补词位置补入所述用户问句,得到所述用户问句的补词问句。
可选地,所述方法还包括:
根据所述补词问句,在问答引擎中挑选知识点作为所述用户问句的解答。
通过本说明书实施例提供的方法,首先获取用户问句的场景埋点信息和/或该用户问句的历史问句,然后根据场景埋点信息和/或历史问句,确定对该用户问句进行补词的候选词集合,此过程中无需与用户交互,再使用预先训练的语言模型,确定候选词集合中的最优候选词和最优候选词在该用户问句中的最佳补词位置,最后将最优候选词按照最佳补词位置补入该用户问句,得到该用户问句的补词问句,通过语言模型使补词问句更能符合用户意图,能够在不增加额外交互的情况下明确用户问句的意图,从而提升用户体验。
下面对步骤22确定候选词集合的过程进行举例说明。
图3示出根据一个实施例的确定候选词集合的方法流程图。如图3所示,该方法包括:
步骤31,判断是否有场景埋点;
如果判断出有场景埋点,则执行步骤32;如果判断出没有场景埋点,则执行步骤34。
目前对于用户问句的信息补充来源有两个,一个是用户问句所在的业务场景,一个是用户问句的上文信息(即历史问句)。对于基于业务场景的补词,首先判断当前用户问句是否有业务场景埋点,比如用户从“我的客服”通用入口进来输入用户问句,该用户问句就没有对应的业务场景,没有办法对用户问句进行信息补充,又如用户从“借呗”场景进来输入用户问句,则该用户问句就有对应的业务场景。
步骤32,提取场景埋点。
例如,提取场景埋点为“借呗”场景。
步骤33,取埋点对应候选词加入候选词列表(也可以称为候选词表)s。
在一个示例中,场景埋点为“借呗”场景。那么用户很有可能询问跟“借呗”、“还款”等很相关的问题,这两个词语要加入用于补词的候选词集合s中。业务场景与候选词的对应关系可以由基于pmi的算法离线生成。
pmi算法是一种常见的计算词语间相似度的方法,本说明书实施例中将pmi算法用来统计业务场景与业务词间的关联程度,可以包括如下处理过程:提取用户问句q1,q2,…,qn和对应的场景s1,s2,…,sm;对用户问句分词、去停用词;根据频度计算场景概率p(si),分词概率p(wj),场景和分词一起出现的概率p(si,wj),并计算该场景和分词的点互信息(pmi)值pmi(si,wj)=log(p(si,wj)/(p(si)*p(wj)));对于每一个业务场景si,其对应的所有分词pmi(si,wj)进行由大到小排序,取前预定数目个(例如前5个)进行审核,即得到业务场景对应的关联分词。
步骤34,判断是否有上文。
如果判断出有上文,则执行步骤35;如果判断出没有上文,则执行步骤37。
步骤35,提取上文分词。
步骤36,将上文分词加入候选词列表s。
其中,上述步骤34至步骤36为根据用户的上文信息确定候选词列表s,例如,针对于用户的当前会话,取当前问句之前预定数目句(例如5句)的历史问句,经过分词、去停用词后加入候选词列表s。
步骤37,使用词表对候选词列表s进行过滤。
本说明书实施例中经过步骤31至步骤36生成的候选词列表s,会经过词表进一步过滤,踢除一些被认为没有语义信息的词,例如“怎么办”(没有补充的语义信息),“支付宝”(用户问的都是支付宝的问题补充无意义)等,最后生成候选词列表s。
步骤38,输出候选词列表s。
本说明书实施例中,可以先根据业务场景确定候选词列表,然后再根据上文信息确定候选词列表;或者,也可以先根据上文信息确定候选词列表,然后再根据业务场景确定候选词列表。由于最终确定的候选词列表是上述分别确定的候选词列表的并集,因此执行顺序对最终结果无影响。
下面对步骤23使用语言模型,确定最优候选词和最佳补词位置的过程进行举例说明。
图4示出根据一个实施例的语言模型过滤补词候选集的方法流程图。如图4所示,该方法包括:
步骤41,提取补词候选集s。
步骤42,判断s是否是空集。
如果判断出s是空集,则执行步骤47;如果判断出s不是空集,则执行步骤43。
步骤43,判断原句的生成概率pavg是否小于预设阈值th1。
如果判断出pavg小于th1,则执行步骤47;如果判断出pavg大于或等于th1,则执行步骤44。
其中,原句的生成概率pavg基于语言模型得出。
步骤44,对s中的每一个词,尝试在用户问句query每一个位置进行补词,计算pavg值。
其中,新句的生成概率pavg基于语言模型得出。
步骤45,验证符合条件,新句pavg与原句pavg的差值大于预设阈值th2。
步骤46,输出补词结果和补词位置。
下面对本说明书实施例中采用的语言模型进行说明。语言模型广泛应用于各种自然语言处理问题,如语音识别、机器翻译、分词、词性标注等等。简单来说,语言模型就是计算一个句子概率的模型,即给定一个句子的词语(即分词)序列q=w1,w2,…,wk,它的概率可以表示为:
p(q)=p(w1,w2,...,wk)=p(w1)p(w2|w1)...p(wk|w1,w2,...,wk-1)
当假设当前词出现的概率仅仅与前面n-1个词相关时,就得到了n-gram语言模型:
使用词频来表示计算模型中的概率参数表示:
p(wi|wi-n+1,...,wi-1)=c(wi-n+1,...,wi-1,wi)/c(wi-n+1,...,wi-1)
其中,c(wi)表示wi在语料中的频次,训练语料越大,参数估计结果越可靠。本说明书实施例中,使用客服机器人历史用户问句与答案作为训练语料,并使用一些平滑算法对低频词频进行平滑处理,最后训练出关于用户问句的语言模型。
本说明书实施例中,使用语言模型来计算评估生成一个句子的概率,为了消除不同句子长度对结果的影响,对句子中的单词数进行平均,即,对于句子的词语序列q=w1,w2,…,wk,其平均概率为:
pavg越大,说明该句子生成的概率越高,句子就越通顺。对于补词模型,认为用户问句中缺少了一些业务关键词,而在适当位置把关键词补充上,会使句子变的更加通顺,基于语言模型的句子概率会变的更高。
在补词算法中引入语言模型主要解决了补词的两个基本问题:1、当用户的历史问句包含多个不同词语或者场景埋点对应多个业务词时,究竟哪些词语能够补全当前问句缺失的语义,也就是说确定最优候选词。2、假如当前问句包含n个词语,就有n+1个位置可以插入词语,那么候选词语究竟要补充到当前问句的哪个位置,也就是说确定最佳补词位置。
基于前述步骤41至步骤46。对于当前用户问句q=w1,w2,…,wk,有候选词集合s,候选词ci∈s,通过步骤41至步骤46确定需要补充的词wtarget和补词位置:
其中,在步骤42,如果s=空集,候选词集合为空,不进行补词;
在步骤43,对于问句q,计算pavg(q),如果pavg(q)<th1,说明原始问句不合文法,超出语言模型处理能力,该问句不进行补词。
在步骤45,对于问句q=w1,w2,…,wk和ci∈s,有k+1个可以补词的位置,将ci分别放入每一个位置,生成新问句qj,j=1,…,k+1,如果pavg(qj)-pavg(q)>th2,则补充后的问句的生成概率更高,记录qj为补词候选方案。
在步骤46,对于所有补词方法,取pavg(qj)最大的方案,即问句补词后生成概率最高的方案,输出补词位置和结果qj即为wtarget。
在一个示例中,经过语义补充后的用户问句会进入接下来的问答引擎中处理,得出最相关的用户问题解决知识点。
需要说明的是,本说明书实施例中语言模型用于计算句子词语序列的生成概率,本说明书实施例中仅以基于n-gram的语言模型举例说明,可以理解的是上述语言模型也可以是基于最大熵、条件随机场(conditionalrandomfield,crf)、决策树、神经网络等算法的语言模型;此外,本说明书实施例中,场景埋点与分词的关联关系由pmi算法得出,也可以由其他模型如卡方检测、逆文本频率指数(inversedocumentfrequency,idf)等算法得出。
下面通过具体的示例对本说明书实施例提供的用户问句的补词方法进行算法投放效果说明。
通过实际应用结果进行统计,该方法可以覆盖30%会话,单引擎解决率提升1.8%,说明用户的模糊问题,借助补词信息可以帮助更好定位用户问句意图。
图5为本说明书实施例提供的一种用户提问线上效果示意图。用户提问“那怎么还款呢”,通用场景进入,有上文“花呗怎么开通”。采用本说明书实施例提供的用户问句的补词方法,用户从通用场景进来,所以从业务场景维度,并没有多余的信息,但是用户有上文信息,在用户提问“那怎么还款呢”的时候,不知道用户是想问花呗、借呗、还是信用卡或者其他业务的还款,但是用户前文历史问句中已经问过“花呗怎么开通”,所以通过上文历史问句信息,“花呗”这个业务词就通过语言模型补充到当前问句中,辅助理解用户意图。
图6为本说明书实施例提供的另一种用户提问线上效果示意图。用户提问“怎么提前还款”,借呗场景进入,无上文。采用本说明书实施例提供的用户问句的补词方法,用户问句“怎么提前还款”根据问句字面无法确定是花呗、借呗、信用卡还是其他业务的提前还款,而用户提问是从借呗场景进入,所以“借呗”就通过语言模型补充到问句中来。
图7为本说明书实施例提供的另一种用户提问线上效果示意图。用户提问“利息多少”,余额宝场景进入,无上文。采用本说明书实施例提供的用户问句的补词方法,“利息多少”也有很多歧义,有可能是花呗、借呗或者定期理财的利率,根据用户“余额宝”的场景,将“余额宝”补充至用户问句中,辅助理解,提升机器人问答匹配的精确度。
根据另一方面的实施例,还提供一种用户问句的补词装置。图8示出根据一个实施例的用户问句的补词装置的示意性框图。如图8所示,该装置800包括:
获取单元81,用于获取用户问句的场景埋点信息和/或所述用户问句的历史问句;
第一确定单元82,用于根据所述获取单元81获取的所述场景埋点信息和/或所述历史问句,确定对所述用户问句进行补词的候选词集合;
第二确定单元83,用于针对所述用户问句中的每个可选的补词位置和所述候选词集合中的每个候选词,生成多个新问句;使用预先训练的语言模型,确定每个所述新问句的生成概率;根据每个所述新问句的生成概率,确定所述候选词集合中的最优候选词和所述最优候选词在所述用户问句中的最佳补词位置;
补词单元84,用于将所述第二确定单元83确定的最优候选词按照所述第二确定单元83确定的最佳补词位置补入所述用户问句,得到所述用户问句的补词问句。
可选地,作为一个实施例,所述装置还包括:
解答单元,用于根据所述补词单元84得到的补词问句,在问答引擎中挑选知识点作为所述用户问句的解答。
可选地,作为一个实施例,所述获取单元81,具体用于将接收所述用户问句的入口所对应的业务场景作为所述场景埋点信息。
可选地,作为一个实施例,所述获取单元81,具体用于获取所述用户问句之前的预定数目个历史问句。
可选地,作为一个实施例,所述第一确定单元82,具体用于:
确定所述获取单元81获取的场景埋点信息对应的当前业务场景;
根据预先建立的多个业务场景与多个关联分词的对应关系,确定当前业务场景对应的关联分词;
将所述当前业务场景对应的关联分词添加到对所述用户问句进行补词的候选词集合中。
进一步地,所述装置还包括:
对应关系建立单元,用于所述多个业务场景与多个关联分词的对应关系通过点互信息pmi算法预先建立,该预先建立包括:
获取多个用户问句和每个用户问句对应的业务场景;
根据每个业务场景出现的频度计算场景概率,根据多个用户问句中每个分词出现的频度计算分词概率,根据每个业务场景和每个分词一起出现的频度计算业务场景和分词的联合概率;
根据业务场景和分词的联合概率、场景概率和分词概率,计算业务场景和分词的pmi值;
对于每个业务场景,将该业务场景和每个分词的pmi值进行由大到小排序,将排序在前预定数目位的分词作为该业务场景对应的关联分词。
可选地,作为一个实施例,所述第一确定单元82,具体用于对所述获取单元81获取的历史问句进行分词和去停用词处理,将得到的分词添加到对所述用户问句进行补词的候选词集合中。
可选地,作为一个实施例,所述第二确定单元83,具体用于:
针对所述用户问句中的每个可选的补词位置和所述第一确定单元82确定的候选词集合中的每个候选词,生成多个新问句;
使用预先训练的语言模型,确定每个所述新问句的生成概率和所述用户问句的生成概率;
如果一个所述新问句的生成概率最大且该新问句的生成概率与所述用户问句的生成概率的差值大于第一预设阈值,则确定该新问句对应的候选词为所述候选词集合中的最优候选词,以及确定该新问句对应的补词位置为所述最优候选词在所述用户问句中的最佳补词位置。
进一步地,所述第二确定单元83,还用于在所述针对所述用户问句中的每个可选的补词位置和所述候选词集合中的每个候选词,生成多个新问句之前,确定所述候选词集合不为空集;和/或使用预先训练的语言模型,确定所述用户问句的生成概率大于或等于第二预设阈值。
可选地,作为一个实施例,所述语言模型为n-gram语言模型。
进一步地,所述n-gram语言模型用于评估生成一个句子的概率,并将所述概率对该句子中的单词数进行平均后,得到该句子的生成概率。
通过本说明书实施例提供的装置,首先由获取单元81获取用户问句的场景埋点信息和/或该用户问句的历史问句,然后由第一确定单元82根据场景埋点信息和/或历史问句,确定对该用户问句进行补词的候选词集合,此过程中无需与用户交互,再由第二确定单元83使用预先训练的语言模型,确定候选词集合中的最优候选词和最优候选词在该用户问句中的最佳补词位置,最后由补词单元84将最优候选词按照最佳补词位置补入该用户问句,得到该用户问句的补词问句,通过语言模型使补词问句更能符合用户意图,能够在不增加额外交互的情况下明确用户问句的意图,从而提升用户体验。
根据另一方面的实施例,还提供一种计算机可读存储介质,其上存储有计算机程序,当所述计算机程序在计算机中执行时,令计算机执行结合图1至图7所描述的方法。
根据再一方面的实施例,还提供一种计算设备,包括存储器和处理器,所述存储器中存储有可执行代码,所述处理器执行所述可执行代码时,实现结合图1至图7所述的方法。
本领域技术人员应该可以意识到,在上述一个或多个示例中,本发明所描述的功能可以用硬件、软件、固件或它们的任意组合来实现。当使用软件实现时,可以将这些功能存储在计算机可读介质中或者作为计算机可读介质上的一个或多个指令或代码进行传输。
以上所述的具体实施方式,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施方式而已,并不用于限定本发明的保护范围,凡在本发明的技术方案的基础之上,所做的任何修改、等同替换、改进等,均应包括在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!