一种信息获取方法、装置及计算机可读存储介质与流程
本发明实施例涉及计算机技术领域,尤其涉及一种信息获取方法、装置及计算机可读存储介质。
背景技术:
数据挖掘是数据库知识发现中的一个步骤,通常是指通过算法从大量的数据中搜索隐藏于其中信息的过程。
相关技术中,基于归属特定字段的信息的实体关系信息挖掘方案已经比较成熟,例如,当数据库设置有姓名字段和公司名称字段,且姓名字段下存储有一定数量的个人姓名信息,公司名称字段下存储有与对应所存储的个人姓名信息的公司名称信息,从而根据这些信息挖掘哪些个人属于一个公司,即挖掘出同事关系。
然而,基于地址信息的实体关系信息挖掘(基于地址的实体关系信息挖掘指的是根据地址信息挖掘地址所属实体之间可能的关系信息,例如,同学关系、同事关系和同小区关系等)却缺乏相应方案。
技术实现要素:
为了解决上述技术问题,本发明实施例提供一种信息获取方法、装置及计算机可读存储介质,能够根据地址信息获取所属实体关系信息,从而提高实体关系信息的获取率。
为了达到本发明实施例目的,本发明实施例提供了一种信息获取方法,包括:
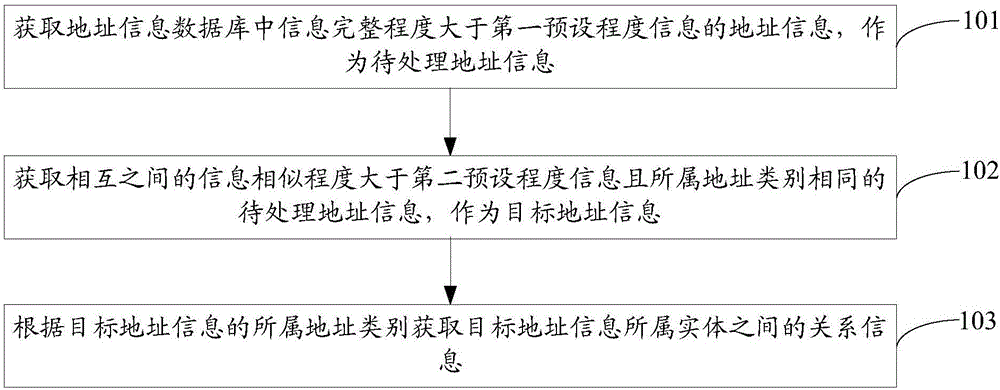
获取地址信息数据库中信息完整程度大于第一预设程度信息的地址信息,作为待处理地址信息;
获取信息相似程度大于第二预设程度信息且所属地址类别相同的待处理地址信息,作为目标地址信息;
根据所述目标地址信息的所属地址类别获取所述目标地址信息所属实体之间的关系信息。
所述获取地址信息数据库中信息完整程度大于第一预设程度信息的地址信息之前,还包括:
根据预先建立的地址分词与地址级别的第一对应关系对所述地址信息数据库中的地址信息进行匹配和切分,针对每个地址信息得到包含至少一个地址分词的地址分词组、与所述第一对应关系匹配成功的地址分词以及对应的地址级别;
判断获得的地址分词组中是否存在与所述第一对应关系匹配失败的地址分词;
如果获得的地址分词组中不存在与所述第一对应关系匹配失败的地址分词;
根据预先建立的地址信息完整程度判定规则和获得的地址级别确定所述地址信息的信息完整程度。
如果获得的地址分词组中存在与所述第一对应关系匹配失败的地址分词,还包括:
判断与所述第一对应关系匹配失败的地址分词是否都是包含地址分词主体和地址分词后缀的标准地址分词;
如果与所述第一对应关系匹配失败的地址分词都是所述标准地址分词;
根据预先建立的地址分词后缀与地址级别的第二对应关系获取所述与第一对应关系匹配失败的地址分词对应的地址级别;
根据所述地址信息完整程度判定规则和获得的地址级别确定所述地址信息的信息完整程度。
如果所述与第一对应关系匹配失败的地址分词不都是所述标准地址分词,还包括:
对所述与第一对应关系匹配失败的地址分词进行标准化处理;
根据所述第二对应关系获取经过标准化处理后的所述与第一对应关系匹配失败的地址分词对应的地址级别;
根据所述地址信息完整程度判定规则和获得的地址级别确定所述地址信息的信息完整程度。
所述对与第一对应关系匹配失败的地址分词进行标准化处理,包括:
根据所述第二对应关系和预先建立的字符序列标注规则对所述与第一对应关系匹配失败的地址分词进行标注,得到标注序列;
根据所述标注序列对所述与第一对应关系匹配失败的地址分词进行合并,得到所述标准地址分词。
所述信息完整程度以数值形式表示,所述地址信息完整程度判定规则为地址级别组合与完整程度的数值的对应关系;
所述根据地址信息完整程度判定规则和获得的地址级别确定地址信息的信息完整程度,包括:
在所述地址级别组合与完整程度的数值的对应关系中查找与获得的地址分词的地址级别相同的地址级别组合;
获取与获得的地址级别组合对应的完整程度的数值,作为所述信息完成程度。
所述获取信息相似程度大于第二预设程度信息且所属地址类别相同的待处理地址信息之前,还包括:
根据预先建立的地址信息相似程度判定规则、所述待处理地址信息对应的待处理地址分词以及所述待处理地址分词的地址级别确定所述待处理地址信息之间的信息相似程度;
根据预先建立的地址类别判定模型获取所述待处理地址信息的所属地址类别。
所述信息相似程度以数值形式表示,所述地址信息相似程度判定规则为地址级别组合与相似程度的数值的对应关系;
所述根据预先建立的地址信息相似程度判定规则、待处理地址信息对应的待处理地址分词以及待处理地址分词的地址级别确定待处理地址信息之间的信息相似程度,包括:
按照地址级别由高到低依次判断所述待处理地址信息对应的同级别待处理地址分词之间是否相同,直到其中一个待处理地址分词判断完毕或者同级别待处理分词之间不相同;
根据所述地址级别组合与相似程度的数值的对应关系查找包含待处理分词相同的地址级别的地址级别组合;
获取与获得的地址级别组合对应的相似程度的数值,作为所述信息相似程度。
所述根据预先建立的地址信息相似程度判定规则、待处理地址信息对应的待处理地址分词以及待处理地址分词的地址级别确定待处理地址信息之间的信息相似程度之前,还包括:
获取所述待处理地址信息的创建时间;
所述根据预先建立的地址信息相似程度判定规则、待处理地址信息对应的待处理地址分词以及待处理地址分词的地址级别确定待处理地址信息之间的信息相似程度,包括:
所述根据预先建立的地址信息相似程度判定规则、创建时间符合预设要求的所述待处理地址信息对应的待处理地址分词以及所述待处理地址分词的地址级别确定所述待处理地址信息之间的信息相似程度。
所述根据目标地址信息的所属地址类别建立目标地址信息所属实体之间的关系信息,包括:
如果所述目标地址信息的所属地址类别为学校地址,获取所述目标地址信息所属实体之间的关系信息为同学关系;
如果所述目标地址信息的所属地址类别为商铺地址,获取所述目标地址信息所属实体之间的关系信息为同商区关系;
如果所述目标地址信息的所属地址类别为公司地址,获取所述目标地址信息所属实体之间的关系信息为同事关系。
本发明实施例还提供了一种信息获取装置,包括:
获取模块,用于获取地址信息数据库中信息完整程度大于第一预设程度信息的地址信息,作为待处理地址信息;
所述获取模块,还用于获取信息相似程度大于第二预设程度信息且所属地址类别相同的待处理地址信息,作为目标地址信息;
处理模块,用于根据所述目标地址信息的所属地址类别获取所述目标地址信息所属实体之间的关系信息。
本发明实施例还提供了一种信息获取装置,包括:处理器和存储器,其中,存储器中存储有以下可被处理器执行的指令:
获取地址信息数据库中信息完整程度大于第一预设程度信息的地址信息,作为待处理地址信息;
获取信息相似程度大于第二预设程度信息且所属地址类别相同的待处理地址信息,作为目标地址信息;
根据所述目标地址信息的所属地址类别获取所述目标地址信息所属实体之间的关系信息。
本发明实施例还提供了一种计算机可读存储介质,所述存储介质上存储有计算机可执行指令,所述计算机可执行指令用于执行以下步骤:
获取地址信息数据库中信息完整程度大于第一预设程度信息的地址信息,作为待处理地址信息;
获取信息相似程度大于第二预设程度信息且所属地址类别相同的待处理地址信息,作为目标地址信息;
根据所述目标地址信息的所属地址类别获取所述目标地址信息所属实体之间的关系信息。
本发明实施例至少包括:获取地址信息数据库中信息完整程度大于第一预设程度信息的地址信息,作为待处理地址信息;获取信息相似程度大于第二预设程度信息且所属地址类别相同的待处理地址信息,作为目标地址信息;根据目标地址信息的所属地址类别获取目标地址信息所属实体之间的关系信息。从本发明实施例可见,由于在地址信息不是明确字段的情况下仍然获取到了实体关系信息,从而极大程度地提高了实体关系信息的获取率。
本发明实施例的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本发明实施例而了解。本发明实施例的目的和其他优点可通过在说明书、权利要求书以及附图中所特别指出的结构来实现和获得。
附图说明
附图用来提供对本发明实施例技术方案的进一步理解,并且构成说明书的一部分,与本申请的实施例一起用于解释本发明实施例的技术方案,并不构成对本发明实施例技术方案的限制。
图1为本发明实施例提供的一种信息获取方法的流程示意图;
图2为本发明实施例提供的一种信息获取装置的结构示意图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚明白,下文中将结合附图对本发明实施例的实施例进行详细说明。需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互任意组合。
本发明实施例提供一种信息获取方法,如图1所示,该方法包括:
步骤101、获取地址信息数据库中信息完整程度大于第一预设程度信息的地址信息,作为待处理地址信息。
步骤102、获取信息相似程度大于第二预设程度信息且所属地址类别相同的待处理地址信息,作为目标地址信息。
具体的,获得的信息相似程度大于第二预设程度信息且所属地址类别相同的待处理地址信息(即目标地址信息)可能是一组,也可能是多组,每组待处理信息可能是两个,也可能是多个。具体来说,假设待处理地址信息包括:地址信息a、地址信息b、地址信息c、地址信息d、地址信息e、地址信息f和地址信息g,地址信息a与地址信息b的信息相似程度、地址信息a与地址信息d的信息相似程度、地址信息a与地址信息e的信息相似程度均大于第二预设程度信息信息,且地址信息a、地址信息d和地址信息e所属地址类别相同;地址信息c与地址信息g的信息相似程度均大于第二预设程度信息信息,且地址信息c和地址信息g所属地址类别相同,因此地址信息a、地址信息d和地址信息e为一组目标地址信息,地址信息c和地址信息g为一组目标地址信息。
步骤103、根据目标地址信息的所属地址类别获取目标地址信息所属实体之间的关系信息。
具体的,如果地址信息a、地址信息d和地址信息e为一组目标地址信息,地址信息c和地址信息g为一组目标地址信息,那么根据目标地址信息的所属地址类别获取目标地址信息所属实体之间的关系信息指的是:根据地址信息a、地址信息d和地址信息e的所属地址类别获取地址信息a、地址信息d和地址信息e所属实体之间的关系信息,根据地址信息c和地址信息g的所属地址类别获取地址信息c和地址信息g所属实体之间的关系信息。
本发明实施例所提供的信息获取方法,获取地址信息数据库中信息完整程度大于第一预设程度信息的地址信息,作为待处理地址信息;获取信息相似程度大于第二预设程度信息且所属地址类别相同的待处理地址信息,作为目标地址信息;根据目标地址信息的所属地址类别获取目标地址信息所属实体之间的关系信息。从本发明实施例提供的技术方案可见,由于能够根据地址信息获取所属实体关系信息,从而极大程度地提高了实体关系信息的获取率。
可选地,获取地址信息数据库中信息完整程度大于第一预设程度信息的地址信息之前,还包括:
步骤104、根据预先建立的地址分词与地址级别的第一对应关系对地址信息数据库中的地址信息进行匹配和切分,针对每个地址信息得到包含至少一个地址分词的地址分词组、与第一对应关系匹配成功的地址分词以及对应的地址级别。
具体的,地址分词与地址级别的第一对应关系可以以表的形式进行表示。对地址信息的切分指的是针对地址字符串切分出各级地址片段,即地址分词。其中,在切分过程中涉及地址文本一些问题的处理,例如:地址缺失,地址不规范,地址格式不统一等,像是“北京静淑东里3号楼”,“北京”缺少后缀“市”,并且此地址缺失区级别地址(海淀区)。本发明实施例提供的信息获取方法采用地名词典正向最大匹配进行分词,然后进行地址标准化,并结合地址树进行省市区补充以得到地址分词,其中,地名词典的构建原则如下:
1、第1级地址(省、直辖市),去除结尾的“省、市”(如“北京市”扩充为{“北京市”,“北京”});特殊地址处理(如“内蒙古自治区”扩充为{“内蒙古自治区”,“内蒙古”,“内蒙”})。
2、第2级地址(地级市、地区等),去除结尾的“市、地区”(如“合肥市”扩充为{“合肥市”,“合肥”});特殊地址处理(如“凉山彝族自治州”,扩充为{“凉山彝族自治州”,“凉山”})。
3、第3级地址(区县等),去除结尾的“区、县”(如“海淀区”扩充为{“海淀区”,“海淀”});特殊地址处理(如“浦东新区”,扩充为{“浦东新区”,“浦东”})。
4、第4级地址(乡镇、街道等),去除结尾的“乡、镇”(如“八达岭镇”扩充为{“八达岭镇”,“八达岭”});街道办事处的扩充(如“鼓楼街道办事处”扩充为{“鼓楼街道办事处”,“鼓楼街道”,“鼓楼街”};特殊地址处理(如“东振社区工作委员会”,扩充为{“东振社区工作委员会”,“东振社区”})。
5、第5级地址(村、小区等),抽取村名(如“东风新村居委会”扩充为{“东风新村居委会”,“东风新村”}),根据字数抽取小区名(如“金鳌山社区居委会”扩充为{“金鳌山社区居委会”,“金鳌山社区”,“金鳌山小区”,“金鳌山”})。
步骤105、判断获得的地址分词组中是否存在与第一对应关系匹配失败的地址分词。
步骤106、如果获得的地址分词组中不存在与第一对应关系匹配失败的地址分词。
步骤107、根据预先建立的地址信息完整程度判定规则和获得的地址级别确定地址信息的信息完整程度。
可选地,如果获得的地址分词组中存在与第一对应关系匹配失败的地址分词,还包括:
步骤108、判断与第一对应关系匹配失败的地址分词是否都是包含地址分词主体和地址分词后缀的标准地址分词。
具体的,假设地址信息为:“东风路街道下冯村周家湾小区”,根据第一对应关系匹配切分得到的地址分词为:{“东”,“风”,“路”,“街道”,“下冯村”,“周”,“家”,“湾”,“小区”},其中,地址分词{“东”,“风”,“路”,“街道”,“周”,“家”,“湾”,“小区”}为匹配失败的地址分词,则在该步骤中需要判断这些词是否是标准地址分词,由于“东”、“风”、“路”、“周”、“家”、“湾”都是不包含地址分词后缀的地址分词,而“街道”、“小区”都是不包含地址分词主体的的地址分词,因此这些地址分词都不是标准地址分词。
步骤109、如果与第一对应关系匹配失败的地址分词都是标准地址分词。
步骤110、根据预先建立的地址分词后缀与地址级别的第二对应关系获取与第一对应关系匹配失败的地址分词对应的地址级别。
步骤111、根据地址信息完整程度判定规则和获得的地址级别确定地址信息的信息完整程度。
可选地,如果与第一对应关系匹配失败的地址分词不都是标准地址分词,还包括:
步骤112、对与第一对应关系匹配失败的地址分词进行标准化处理。
具体的,对与第一对应关系匹配失败的地址分词进行标准化处理,包括:
根据第二对应关系和预先建立的字符序列标注规则对与第一对应关系匹配失败的地址分词进行标注,得到标注序列。
根据标注序列对与第一对应关系匹配失败的地址分词进行合并,使得与第一对应关系匹配失败的地址分词成为标准地址分词。
具体的,因为第4级地址、第5级地址、第6级地址以及兴趣点(pointofinterest,poi)等地址元素,通常不易通过地址树匹配得到,但可以根据第4级地址,第5级地址和第6级地址词典,以及地址后缀进行抽取。地址字符序列标注算法的思想是将地址分词标注为不同的类型,得到标记序列,再根据地址排列模式进行地址抽取,识别相应的地址元素。标注方法可以如表1所示:
表1
需要说明的是,表1中的附加后缀是指特殊的补充后缀,如“云趣园一区”中的“一区”,类似的附加后缀包括“区”,“期”,“条”,“里”,“巷”,“段”。一般来说,数字/方位+附加后缀的地址片段,需要合并到前面的地址元素中。如“一区”要合并到“云趣园”,整体上“云趣园一区”作为一个地址元素。
假设地址字符串“东风路街道下冯村周家湾小区”对应的地址分词为:{“东”,“风”,“路”,“街道”,“下冯村”,“周”,“家”,“湾”,“小区”},根据表1所示,所对应的标记序列为:{“0”,“0”,“5”,“4”,“f”,“0”,“0”,“0”,“6”},根据标注序列地址分词进行合并,得到标准地址分词,即{“东风路街道”,“下冯村”,“周家湾小区”}。具体的,可以根据下述规则对与第一对应关系匹配失败的地址分词进行合并:
匹配到第4级地址分词或第4级地址分词后缀,如果后面没有接第4、5、6或poi级地址分词,或者,数字+第4、5或6级地址分词,或者,方位+第4、5、或6级地址分词,则该地址分词可以作为第4级地址分词。如果后面紧跟第4、5或6级地址分词,或者,数字+第4、5或6级地址分词后缀,或者,方位+第4、5、或6级地址分词后缀,则整体合并,根据后面匹配上的地址分词后缀,作为相应的地址分词,如,后面匹配上第5级地址分词后缀,则整体作为第5级地址分词。
匹配到第5级地址分词或第5级地址分词后缀,如果后面没有接第4、5、6或poi级地址分词,或者,数字+第4、5或6级地址分词,或者,数字+第4、5或6级地址分词后缀,或者,方位+第4、5或6级地址分词,或者,方位+第4、5或6级地址分词后缀,则该地址分词可以作为第5级地址分词。如果后面紧跟第4、5或6级地址分词,或者,数字+第4、5、6或poi级地址分词后缀,或者,数字+附加后缀,或者,方位+第4、5、6或poi级地址分词后缀,或者,方位+附加后缀,则整体合并,根据后面匹配上的地址分词后缀,作为相应的地址分词,若匹配上附加后缀,则作为第6级地址分词。
匹配到第6级地址分词或第6级地址分词后缀,如果后面没有接第5、6或poi级地址分词,或者,数字+第5、6或poi级地址分词,或者,数字+附加后缀,或者,方位+第5、6或poi级地址分词,或者,方位+附加后缀,则该地址分词可以作为第6级地址分词,如果后面紧跟第5或6级地址分词,或者,数字+第5、6或poi级地址后缀,或者,数字+附加后缀,或者,方位+第5、6或poi级地址后缀,或者,方位+附加后缀,则整体合并,根据后面匹配上的地址分词后缀,作为相应的地址分词,若匹配上附加后缀,则作为第6级地址分词。
匹配到poi地址,如果后面没有接poi地址,或者,数字+poi地址分词后缀,或者,方位+poi地址分词后缀,则该地址分词可以作为poi地址分词,如果后面紧跟poi地址,或者,数字+poi地址分词后缀,或者,方位+poi地址分词后缀,则合并作为poi地址分词。
在具体的匹配过程中,第4级地址分词先匹配,然后,处理一种特殊的地址排列,即将第4级地址分词后缀+第5级地址分词的排列,如果匹配上这种模式,则直接抽取出第4级地址分词和第5级地址分词,然后,若第5级地址分词没有匹配上,则模式匹配第5级地址分词,然后,若第6级地址分词没有匹配上,则模式匹配第6级地址分词,然后,若poi地址分词没有匹配上,则模式匹配poi地址分词,最后,将剩余的地址片段作为补充地址,添加到结果中。
具体的,第4、5、6和poi级地址的规则匹配模式如下:
第4级地址模式:
^((.*f|[^4]{1,5}4)([456p]{1,3}|([nd][456p])?))
*特殊地址排列模式:
([^54]+[4](4|d4)*)([^5ndp]+[5](5|d5)*)//匹配到第4级地址在第5级地址之前
*第5级地址模式:
([^5f]*f[nd][56pz]|[^5f]*f[56p]*|[^5p]+[5f][nd][56pz]|[^5p]+[5f][56p]*)
*第6级地址模式:
([^6s]*s[nd][56pz]|[^6s]*s[56pz]*|[^6p]+[6s][nd][56pz]|[^6p]+[6s][56pz]*)
*poi地址模式:
[^p]+p([456p]|([nd]+[456p]))*
更具体的匹配步骤如下面伪代码描述:
/**
*地址字符序列标注算法进行地址标注和规则模式匹配。
*@paramaddrsegments切分出的地址数组
*@paramnormaladdrarr地址标准化结果(将识别出的地址切分结果存储到此arraylist中)
*/
addrseqtagger(list<string>addrsegments,
arraylist<string>normaladdrarr){
forwordinaddrsegmentsdo
ifwordinfourthpostfixdo
taggerstr.append(“4”)
elseifwordinfifthpostfixdo
taggerstr.append(“5”)
......//根据分词的类型填充标记列表.
elsedo
taggerstr.append(“0”)
endif
endfor
boolhasfourth=matchfourthaddr(taggerstr,currentidx);//模式匹配第4级地址
ifhasfourthdo
stringfourthcand=extractfourth(addrsegments,taggerstr)//抽取第4级地址,并调整索引。
addaddr2normaladdr("4",fourthcand,normaladdrarr);//根据标记及是否有值,添加到标准化结果中,
endif
boolisfifthfourthpattern=matchfifthfourth(taggerstr,currentidx);//匹配剩余标记串是否是第5级地址+第4级地址的模式。如:桃杨路永定门外街,其实:永定门外街道第第4级地址。这种表述比较特殊,不太常见。
ifisfifthfourthpatterndo
stringfourthcand=extractfourth(addrsegments,taggerstr);//此时,将匹配结果添加到第4级地址。
addaddr2normaladdr("4",sixthcand,normaladdrarr)
stringfifthcand=extractfifth(addrsegments,taggerstr);//抽取第5级地址。
addaddr2normaladdr("5",fifthcand,normaladdrarr)
endif
boolhasfifth=matchfifthaddr(taggerstr,currentidx)//模式匹配第5级地址
boolisfifthexist=normaladdrarr.get(fifthidx).length>0//检查第5级地址是否已识别
if!fifthexist&&hasfifthdo
stringfifthcand=extractfifth(addrsegments,taggerstr)
addaddr2normaladdr("5",fifthcand,normaladdrarr)
endif
boolhassixth=matchsixthaddr(taggerstr,currentidx)//模式匹配第6级地址
boolissixthexist=normaladdrarr.get(sixthidx).length>0//检查第6级地址是否已识别
if!issixthexist&&hassixthdo
stringsixthcand=extractsixth(addrsegments,taggerstr)
addaddr2normaladdr("6",sixthcand,normaladdrarr)
endif
boolhaspoi=matchpoiaddr(taggerstr,currentidx)//模式匹配poi数据
ifhaspoido
stringpoicand=extractpoi(addrsegments,taggerstr)
addaddr2normaladdr("p",poicand,normaladdrarr)
endif
//剩余地址字符串添加到补充地址
}
步骤113、根据第二对应关系获取经过标准化处理后的与第一对应关系匹配失败的地址分词对应的地址级别。
步骤114、根据地址信息完整程度判定规则和获得的地址级别确定地址信息的信息完整程度。
可选地,信息完整程度以数值形式表示,地址信息完整程度判定规则为地址级别组合与完整程度的数值的对应关系。
根据地址信息完整程度判定规则和获得的地址级别确定地址信息的信息完整程度,包括:
在地址级别组合与完整程度的数值的对应关系中查找与获得的地址分词的地址级别相同的地址级别组合。
获取与获得的地址级别组合对应的完整程度的数值,作为信息完成程度。
具体的,地址信息完整程度判定规则可以如下所示:
1.0:完整包含1-2级地址,可包含第3级地址,并包含第4级地址或第5级地址或第6级地址或poi,并详细到房间门牌号。
0.95:完整包含1-2级地址,可包含第3级地址,并包含第4级地址或第5级地址或第6级地址,并详细到楼号和楼层。
0.9:完整包含1-2级地址,可包含第3级地址,并包含第4级地址或第5级地址或第6级地址,并详细到楼号。
0.85:完整包含1-2级地址,可包含第3级地址,并包含第4级地址或第5级地址或第6级地址,并详细到楼或poi(宾馆、大厦、商场……)。
0.8:完整包含1-2级地址,可包含第3级地址,并包含第4级地址或第5级地址,并详细到第6级地址(道路号、村组、小区、大院……)。
0.7:完整包含1-2级地址,可包含第3级地址或第4级地址,并详细到第5级地址(道路,村,巷等但不包含poi和道路号等)。
0.6:完整包含1-2级地址,可包含第3级地址,并详细到第4级地址(街道办事处,片区)。
0.5:完整包含1-2级地址,并详细到第3级地址(行政区、县)。
0.3:仅包含第1-2级地址(地级市)。
0.1:仅确定到第1级地址(省,自治区)。
0.0:无法确定第1级地址。
根据地址信息完整程度判定规则可知,如果地址信息切分后仅包含第1级地址,则其完整度为0.1,如果包含第1级地址和第2级地址,则其完整度为0.3,依次类推,根据上述的规则进行计算。
可选地,获取信息相似程度大于第二预设程度信息且所属地址类别相同的待处理地址信息之前,还包括:
步骤115、根据预先建立的地址信息相似程度判定规则、待处理地址信息对应的待处理地址分词以及待处理地址分词的地址级别确定待处理地址信息之间的信息相似程度。
步骤116、根据预先建立的地址类别判定模型获取待处理地址信息的所属地址类别。
可选地,信息相似程度以数值形式表示,地址信息相似程度判定规则为地址级别组合与相似程度的数值的对应关系。
根据预先建立的地址信息相似程度判定规则、待处理地址信息对应的待处理地址分词以及待处理地址分词的地址级别确定待处理地址信息之间的信息相似程度,包括:
按照地址级别由高到低依次判断待处理地址信息对应的同级别待处理地址分词之间是否相同,直到其中一个待处理地址分词判断完毕或者同级别待处理分词之间不相同。
根据地址级别组合与相似程度的数值的对应关系查找包含待处理分词相同的地址级别的地址级别组合。
获取与获得的地址级别组合对应的相似程度的数值,作为信息相似程度。
具体的,地址信息相似程度判定规则可以如下所示:
1.0:完全相同:两个地址完全相同,并重合到门牌号。
0.95:相同到同一栋楼的楼层。
0.9:同一栋楼:重合到同一栋楼,即楼栋号相同。
0.85:同一个poi,地址重合到同一个poi,像是大厦、宾馆、饭店等。
0.8:同一个园区:重合到第6级地址或道路号(小区、兴趣点、街道号、村组号,如:广场大道6号、云趣园一区等)。
0.7:同一个道路片区:重合到第5级地址(道路,村,大队)。
0.6:同一个乡镇:重合到第4级地址(镇、乡、苏木等)。
0.5:同一个区县:重合到第3级地址(行政区,如:花都区,江夏区,偃师县等)。
0.3:同一个市:重合到第2级地址(地级市,如:洛阳市、郑州市等)。
0.1:同一个省:重合到第1级地址(省、直辖市,如北京市,安徽省等)。
0.0:地址为空,或不同的省。
可选地,根据预先建立的地址信息相似程度判定规则、待处理地址信息对应的待处理地址分词以及待处理地址分词的地址级别确定待处理地址信息之间的信息相似程度之前,还包括:
获取待处理地址信息的创建时间。
根据预先建立的地址信息相似程度判定规则、待处理地址信息对应的待处理地址分词以及待处理地址分词的地址级别确定待处理地址信息之间的信息相似程度,包括:
根据预先建立的地址信息相似程度判定规则、创建时间符合预设要求的待处理地址信息对应的待处理地址分词以及待处理地址分词的地址级别确定待处理地址信息之间的信息相似程度。
具体的,要进行相似程度比较的地址信息的创建时间不能相差太远,否则可能由于时间变迁而造成地址信息的不准确,从而使获得的实体之间的关系不准确。
可选地,根据目标地址信息的所属地址类别建立目标地址信息所属实体之间的关系信息,包括:
如果目标地址信息的所属地址类别为学校地址,获取目标地址信息所属实体之间的关系信息为同学关系。
如果目标地址信息的所属地址类别为商铺地址,获取目标地址信息所属实体之间的关系信息为同商区关系。
如果目标地址信息的所属地址类别为公司地址,获取目标地址信息所属实体之间的关系信息为同事关系。
本发明实施例还提供一种信息获取装置,如图2所示,该信息获取装置2包括:
获取模块21,用于获取地址信息数据库中信息完整程度大于第一预设程度信息的地址信息,作为待处理地址信息。
获取模块21,还用于获取信息相似程度大于第二预设程度信息且所属地址类别相同的待处理地址信息,作为目标地址信息。
处理模块22,用于根据目标地址信息的所属地址类别获取目标地址信息所属实体之间的关系信息。
可选地,处理模块22还用于:
根据预先建立的地址分词与地址级别的第一对应关系对地址信息数据库中的地址信息进行匹配和切分,针对每个地址信息得到包含至少一个地址分词的地址分词组、与第一对应关系匹配成功的地址分词以及对应的地址级别。
判断获得的地址分词组中是否存在与第一对应关系匹配失败的地址分词。
如果获得的地址分词组中不存在与第一对应关系匹配失败的地址分词。
根据预先建立的地址信息完整程度判定规则和获得的地址级别确定地址信息的信息完整程度。
可选地,如果获得的地址分词组中存在与第一对应关系匹配失败的地址分词,处理模块22还用于:
判断与第一对应关系匹配失败的地址分词是否都是包含地址分词主体和地址分词后缀的标准地址分词。
如果与第一对应关系匹配失败的地址分词都是标准地址分词。
根据预先建立的地址分词后缀与地址级别的第二对应关系获取与第一对应关系匹配失败的地址分词对应的地址级别。
根据地址信息完整程度判定规则和获得的地址级别确定地址信息的信息完整程度。
可选地,如果与第一对应关系匹配失败的地址分词不都是标准地址分词,处理模块22还用于:
对与第一对应关系匹配失败的地址分词进行标准化处理。
根据第二对应关系获取经过标准化处理后的与第一对应关系匹配失败的地址分词对应的地址级别。
根据地址信息完整程度判定规则和获得的地址级别确定地址信息的信息完整程度。
可选地,处理模块22具体用于:
根据第二对应关系和预先建立的字符序列标注规则对与第一对应关系匹配失败的地址分词进行标注,得到标注序列。
根据标注序列对与第一对应关系匹配失败的地址分词进行合并,得到标准地址分词。
可选地,信息完整程度以数值形式表示,地址信息完整程度判定规则为地址级别组合与完整程度的数值的对应关系。处理模块22具体还用于:
在地址级别组合与完整程度的数值的对应关系中查找与获得的地址分词的地址级别相同的地址级别组合。
获取与获得的地址级别组合对应的完整程度的数值,作为信息完成程度。
可选地,处理模块22还用于:
根据预先建立的地址信息相似程度判定规则、待处理地址信息对应的待处理地址分词以及待处理地址分词的地址级别确定待处理地址信息之间的信息相似程度。
根据预先建立的地址类别判定模型获取待处理地址信息的所属地址类别。
可选地,信息相似程度以数值形式表示,地址信息相似程度判定规则为地址级别组合与相似程度的数值的对应关系。处理模块22具体还用于:
按照地址级别由高到低依次判断待处理地址信息对应的同级别待处理地址分词之间是否相同,直到其中一个待处理地址分词判断完毕或者同级别待处理分词之间不相同。
根据地址级别组合与相似程度的数值的对应关系查找包含待处理分词相同的地址级别的地址级别组合。
获取与获得的地址级别组合对应的相似程度的数值,作为信息相似程度。
可选地,获取模块21,还用于获取待处理地址信息的创建时间。
处理模块22,具体用于根据预先建立的地址信息相似程度判定规则、创建时间符合预设要求的待处理地址信息对应的待处理地址分词以及待处理地址分词的地址级别确定待处理地址信息之间的信息相似程度。
可选地,处理模块22具体还用于:
如果目标地址信息的所属地址类别为学校地址,获取目标地址信息所属实体之间的关系信息为同学关系。
如果目标地址信息的所属地址类别为商铺地址,获取目标地址信息所属实体之间的关系信息为同商区关系。
如果目标地址信息的所属地址类别为公司地址,获取目标地址信息所属实体之间的关系信息为同事关系。
本发明实施例所提供的信息获取装置,获取地址信息数据库中信息完整程度大于第一预设程度信息的地址信息,作为待处理地址信息;获取信息相似程度大于第二预设程度信息且所属地址类别相同的待处理地址信息,作为目标地址信息;根据目标地址信息的所属地址类别获取目标地址信息所属实体之间的关系信息。从本发明实施例可见,由于能够根据地址信息获取所属实体关系信息,从而极大程度地提高了实体关系信息的获取率。
在实际应用中,所述获取模块21和处理模块22可由位于信息获取装置中的中央处理器(centralprocessingunit,cpu)、微处理器(microprocessorunit,mpu)、数字信号处理器(digitalsignalprocessor,dsp)或现场可编程门阵列(fieldprogrammablegatearray,fpga)等实现。
本发明实施例还提供一种信息获取装置,其特征在于,包括:处理器和存储器,其中,存储器中存储有以下可被处理器执行的指令:
获取地址信息数据库中信息完整程度大于第一预设程度信息的地址信息,作为待处理地址信息。
获取信息相似程度大于第二预设程度信息且所属地址类别相同的待处理地址信息,作为目标地址信息。
根据目标地址信息的所属地址类别获取目标地址信息所属实体之间的关系信息。
可选地,存储器中还存储有以下可被处理器执行的指令:
根据预先建立的地址分词与地址级别的第一对应关系对地址信息数据库中的地址信息进行匹配和切分,针对每个地址信息得到包含至少一个地址分词的地址分词组、与第一对应关系匹配成功的地址分词以及对应的地址级别。
判断获得的地址分词组中是否存在与第一对应关系匹配失败的地址分词。
如果获得的地址分词组中不存在与第一对应关系匹配失败的地址分词。
根据预先建立的地址信息完整程度判定规则和获得的地址级别确定地址信息的信息完整程度。
可选地,如果获得的地址分词组中存在与第一对应关系匹配失败的地址分词,存储器中还存储有以下可被处理器执行的指令:
判断与第一对应关系匹配失败的地址分词是否都是包含地址分词主体和地址分词后缀的标准地址分词。
如果与第一对应关系匹配失败的地址分词都是标准地址分词。
根据预先建立的地址分词后缀与地址级别的第二对应关系获取与第一对应关系匹配失败的地址分词对应的地址级别。
根据地址信息完整程度判定规则和获得的地址级别确定地址信息的信息完整程度。
可选地,如果与第一对应关系匹配失败的地址分词不都是标准地址分词,存储器中还存储有以下可被处理器执行的指令:
对与第一对应关系匹配失败的地址分词进行标准化处理。
根据第二对应关系获取经过标准化处理后的与第一对应关系匹配失败的地址分词对应的地址级别。
根据地址信息完整程度判定规则和获得的地址级别确定地址信息的信息完整程度。
可选地,存储器中具体存储有以下可被处理器执行的指令:
根据第二对应关系和预先建立的字符序列标注规则对与第一对应关系匹配失败的地址分词进行标注,得到标注序列。
根据标注序列对与第一对应关系匹配失败的地址分词进行合并,得到标准地址分词。
可选地,信息完整程度以数值形式表示,地址信息完整程度判定规则为地址级别组合与完整程度的数值的对应关系。存储器中还具体存储有以下可被处理器执行的指令:
在地址级别组合与完整程度的数值的对应关系中查找与获得的地址分词的地址级别相同的地址级别组合。
获取与获得的地址级别组合对应的完整程度的数值,作为信息完成程度。
可选地,存储器中还存储有以下可被处理器执行的指令:
根据预先建立的地址信息相似程度判定规则、待处理地址信息对应的待处理地址分词以及待处理地址分词的地址级别确定待处理地址信息之间的信息相似程度。
根据预先建立的地址类别判定模型获取待处理地址信息的所属地址类别。
可选地,信息相似程度以数值形式表示,地址信息相似程度判定规则为地址级别组合与相似程度的数值的对应关系。存储器中还具体存储有以下可被处理器执行的指令:
按照地址级别由高到低依次判断待处理地址信息对应的同级别待处理地址分词之间是否相同,直到其中一个待处理地址分词判断完毕或者同级别待处理分词之间不相同。
根据地址级别组合与相似程度的数值的对应关系查找包含待处理分词相同的地址级别的地址级别组合。
获取与获得的地址级别组合对应的相似程度的数值,作为信息相似程度。
可选地,存储器中还存储有以下可被处理器执行的指令:
获取待处理地址信息的创建时间。
根据预先建立的地址信息相似程度判定规则、创建时间符合预设要求的待处理地址信息对应的待处理地址分词以及待处理地址分词的地址级别确定待处理地址信息之间的信息相似程度。
可选地,存储器中还具体存储有以下可被处理器执行的指令:
如果目标地址信息的所属地址类别为学校地址,获取目标地址信息所属实体之间的关系信息为同学关系。
如果目标地址信息的所属地址类别为商铺地址,获取目标地址信息所属实体之间的关系信息为同商区关系。
如果目标地址信息的所属地址类别为公司地址,获取目标地址信息所属实体之间的关系信息为同事关系。
本发明实施例还提供一种计算机可读存储介质,存储介质上存储有计算机可执行指令,计算机可执行指令用于执行以下步骤:
获取地址信息数据库中信息完整程度大于第一预设程度信息的地址信息,作为待处理地址信息。
获取信息相似程度大于第二预设程度信息且所属地址类别相同的待处理地址信息,作为目标地址信息。
根据目标地址信息的所属地址类别获取目标地址信息所属实体之间的关系信息。
可选地,计算机可执行指令还用于执行以下步骤:
根据预先建立的地址分词与地址级别的第一对应关系对地址信息数据库中的地址信息进行匹配和切分,针对每个地址信息得到包含至少一个地址分词的地址分词组、与第一对应关系匹配成功的地址分词以及对应的地址级别。
判断获得的地址分词组中是否存在与第一对应关系匹配失败的地址分词。
如果获得的地址分词组中不存在与第一对应关系匹配失败的地址分词。
根据预先建立的地址信息完整程度判定规则和获得的地址级别确定地址信息的信息完整程度。
可选地,如果获得的地址分词组中存在与第一对应关系匹配失败的地址分词,计算机可执行指令还用于执行以下步骤:
判断与第一对应关系匹配失败的地址分词是否都是包含地址分词主体和地址分词后缀的标准地址分词。
如果与第一对应关系匹配失败的地址分词都是标准地址分词。
根据预先建立的地址分词后缀与地址级别的第二对应关系获取与第一对应关系匹配失败的地址分词对应的地址级别。
根据地址信息完整程度判定规则和获得的地址级别确定地址信息的信息完整程度。
可选地,如果与第一对应关系匹配失败的地址分词不都是标准地址分词,计算机可执行指令还用于执行以下步骤:
对与第一对应关系匹配失败的地址分词进行标准化处理。
根据第二对应关系获取经过标准化处理后的与第一对应关系匹配失败的地址分词对应的地址级别。
根据地址信息完整程度判定规则和获得的地址级别确定地址信息的信息完整程度。
可选地,计算机可执行指令具体用于执行以下步骤:
根据第二对应关系和预先建立的字符序列标注规则对与第一对应关系匹配失败的地址分词进行标注,得到标注序列。
根据标注序列对与第一对应关系匹配失败的地址分词进行合并,得到标准地址分词。
可选地,信息完整程度以数值形式表示,地址信息完整程度判定规则为地址级别组合与完整程度的数值的对应关系。计算机可执行指令还具体用于执行以下步骤:
在地址级别组合与完整程度的数值的对应关系中查找与获得的地址分词的地址级别相同的地址级别组合。
获取与获得的地址级别组合对应的完整程度的数值,作为信息完成程度。
可选地,计算机可执行指令还用于执行以下步骤:
根据预先建立的地址信息相似程度判定规则、待处理地址信息对应的待处理地址分词以及待处理地址分词的地址级别确定待处理地址信息之间的信息相似程度。
根据预先建立的地址类别判定模型获取待处理地址信息的所属地址类别。
可选地,信息相似程度以数值形式表示,地址信息相似程度判定规则为地址级别组合与相似程度的数值的对应关系。计算机可执行指令还具体用于执行以下步骤:
按照地址级别由高到低依次判断待处理地址信息对应的同级别待处理地址分词之间是否相同,直到其中一个待处理地址分词判断完毕或者同级别待处理分词之间不相同。
根据地址级别组合与相似程度的数值的对应关系查找包含待处理分词相同的地址级别的地址级别组合。
获取与获得的地址级别组合对应的相似程度的数值,作为信息相似程度。
可选地,计算机可执行指令还用于执行以下步骤:
获取待处理地址信息的创建时间。
根据预先建立的地址信息相似程度判定规则、创建时间符合预设要求的待处理地址信息对应的待处理地址分词以及待处理地址分词的地址级别确定待处理地址信息之间的信息相似程度。
可选地,计算机可执行指令还具体用于执行以下步骤:
如果目标地址信息的所属地址类别为学校地址,获取目标地址信息所属实体之间的关系信息为同学关系。
如果目标地址信息的所属地址类别为商铺地址,获取目标地址信息所属实体之间的关系信息为同商区关系。
如果目标地址信息的所属地址类别为公司地址,获取目标地址信息所属实体之间的关系信息为同事关系。
虽然本发明实施例所揭露的实施方式如上,但所述的内容仅为便于理解本发明实施例而采用的实施方式,并非用以限定本发明实施例。任何本发明实施例所属领域内的技术人员,在不脱离本发明实施例所揭露的精神和范围的前提下,可以在实施的形式及细节上进行任何的修改与变化,但本发明实施例的专利保护范围,仍须以所附的权利要求书所界定的范围为准。
- 还没有人留言评论。精彩留言会获得点赞!