一种基于LE算法的工业监测数据聚类方法与流程
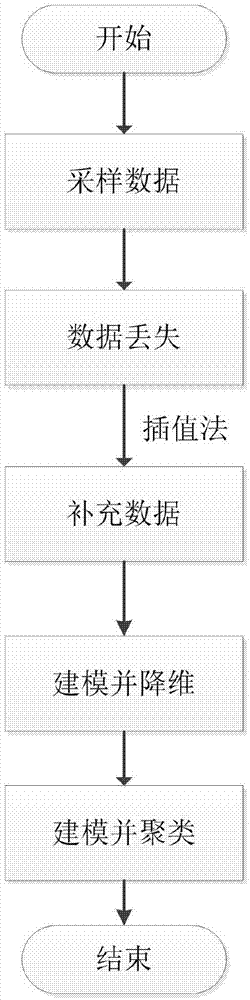
本发明属于工业监测数据聚类的技术领域,具体涉及一种基于le算法的工业监测数据聚类方法。
背景技术:
在信息发展如此迅速的时代,随之产生的数据在快速增长,所以如何从大量增长的数据中挖掘有效信息并进行利用,是机器学习的一个重要研究课题。现实中数据根据是否有标签信息分为有标签数据和无标签数据,当数据的标签信息未知即为无标签数据时,通过肉眼无法对高维数据进行聚类,但是通过常见的聚类算法可以对这些无标签数据进行学习并获取数据的内在信息。如果数据量大,将会给数据分析带来困难。而数据通常包括其行数和列数,分别表示数据的采样个数和变量个数。采样数据的个数与采样时间息息相关,但为保证在提取过程中数据信息的准确性,其采样个数应该予以保证。所以面对数据变量个数也即数据维数大的情况,如果可以对数据的变量其进行压缩,将给后续的数据聚类带来很大的便利。
技术实现要素:
基于以上本发明提出一种基于le(laplacianeigenmaps)算法的工业监测数据聚类方法。该方法首先对多变量数据进行降维,再对降维后数据进行聚类,同时又可以保证计算量,提高了数据聚类的效率,是一种用来有效分析数据内在特点、寻找规律的方法。该方法可对高维的采样数据进行一个压缩,并根据数据的内在特征对数据本身进行聚类,便于发现数据的规律。
本发明采用以下技术方案:
一种基于le算法的工业监测数据聚类方法,包括如下步骤:
步骤1、对工业系统的监测数据进行采集,并进行预处理;
步骤2、基于拉普拉斯特征映射le算法进行建模,将步骤1中的采样数据作为输入数据,通过计算并输出低维数据;
步骤3、基于密度聚类方法dbscan进行建模,步骤2的低维数据作为该模型的输入,对其进行聚类;
步骤4、输出:聚类后的集合c={c1,c2,…,ck},co,o=1,2,...,k为聚类之后的第o个聚类簇。
作为本发明进一步的方案,所述步骤1具体包括如下步骤:
步骤1.1、先对工业系统进行采样,并用x={x1,x2,…,xn}∈rd×n表示,其中d表示数据的变量个数,n表示采样数目,其中第t个采样数据用xt表示,且t=1,2,...,n,xt=[xt1xt2…xtd]t;
步骤1.2、对采样数据x进行检查,如果在x中某个数据xtj出现丢失现象,假设其中xtj为第t个采样数据的第j个变量丢失,则利用公式
作为本发明进一步的方案,所述步骤2具体包括如下步骤:
步骤2.1、将完整的步骤1的采样数据x作为输入,低维数据的维数s<d作为输入参数;
步骤2.2、构建一个邻接图g(v,e):用k最近邻算法knn寻找属于每个数据点xt的k个近邻点,满足k<n;
步骤2.3、确定权值矩阵:如果数据点xt是数据点xi的近邻点,它的权值系数
步骤2.4、计算对角矩阵d,该矩阵的对角线元素dii由步骤2.3构建的权值矩阵的第i列所有元素wti的和,用公式表示为
步骤2.5、计算拉普拉斯矩阵l:根据公式l=d-w计算拉普拉斯矩阵;
步骤2.6、通过解决广义特征值问题,根据公式ly=λdy解决该问题并获得特征值及其特征向量,并提取最小的s个非零特征值及对应的特征向量,对应的低维数据输出用y={y1,y2,…,ym}表示,其中yj为对应的第j个特征向量,j=1,2,…,m;
作为本发明进一步的方案,所述步骤3具体包括如下步骤:
步骤2中产生的降维数据用y={y1,y2,…,ym}表示,其中yj为n维向量,对降维后的n个采样数据进行聚类,聚类的目的是将相似性较大的数据聚成一类,相似性较小的数据分开;
步骤3.1、输入参数ε和minpts,分别为聚类半径和除噪声点数据之外的每类数据中的最小数目;
步骤3.2、寻找核心对象:找出每个数据点在ε半径内的数据点,如果该半径内的数据点的个数大于等于minpts时,标记该点为核心对象,反之,为噪声点数据;
步骤3.3、以步骤2中的所有核心对象为出发点,找出其密度可达样本生成的聚类簇,直到所以核心对象都被访问停止迭代。
本发明的有益效果是:本发明一种le算法的工业监测数据聚类方法,分别建立了基于拉普拉斯特征映射算法的模型和密度聚类的模型,分别对多变量的采样数据进行压缩之后对其进行聚类,且不用输入聚类数目;密度聚类方法是一种迭代算法,经过反复迭代之后,找出所有密度相连的最大点的集合;对于工业数据而言,本发明可以先对多变量数据进行压缩,压缩后的数据保留了其重要信息,再对其进行聚类,聚类后的每类数据相似度较高,便于找出其中的规律,具有非凡的意义。
附图说明
图1是本发明总体流程图;
图2是本发明方法中步骤2的降维方法的流程图。
图3是本发明方法中步骤3的聚类方法流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整的阐述。
如图1~图3所示,本发明基于一种le算法的工业监测数据聚类方法,具体按照以下步骤实施:
步骤1、对工业系统的监测数据进行采集,并进行预处理:
步骤1.1、先对工业系统进行采样,并用x={x1,x2,…,xn}∈rd×n表示,其中d表示数据的变量个数,n表示采样数目。其中第t个采样数据用xt表示,且t=1,2,...,n,xt=[xt1xt2...xtd]t;
步骤1.2、对采样数据x进行检查,如果在x中某个数据xtj出现丢失现象,假设其中xtj为第t个采样数据的第j个变量丢失,则利用公式
步骤2、基于拉普拉斯特征映射le算法进行建模,将步骤1中的采样数据作为输入数据,通过计算并输出低维数据:
步骤2.1、将完整的步骤1的采样数据x作为输入,低维数据的维数s<d作为输入参数;
步骤2.2、构建一个邻接图g(v,e):用k最近邻算法knn寻找属于每个数据点xt的k个近邻点,满足k<n;
步骤2.3、确定权值矩阵:如果数据点xt是数据点xi的近邻点,它的权值系数
步骤2.4、计算对角矩阵d,该矩阵的对角线元素dii由步骤2.3构建的权值矩阵的第i列所有元素wti的和,用公式表示为
步骤2.5、计算拉普拉斯矩阵l:根据公式l=d-w计算拉普拉斯矩阵;
步骤2.6、通过解决广义特征值问题,根据公式ly=λdy解决该问题并获得特征值及其特征向量,并提取最小的s个非零特征值及对应的特征向量,对应的低维数据输出用y={y1,y2,…,ym}表示,其中yj为对应的第j个特征向量,j=1,2,…,m;
步骤3、基于密度聚类方法dbscan进行建模,步骤2的低维数据作为该模型的输入,对其进行聚类:
步骤2中产生的降维数据用y={y1,y2,…,ym}表示,其中yj为n维向量,对降维后的n个采样数据进行聚类。聚类的目的是将相似性较大的数据聚成一类,相似性较小的数据分开。本专利采用密度聚类dbscan方法进行聚类,该聚类方法根据密度进行聚类,可将密度较大的数据聚成一簇,是一种有效的聚类方法。
步骤3.1、输入参数ε和minpts,分别为聚类半径和除噪声点数据之外的每类数据中的最小数目;
步骤3.2、寻找核心对象:找出每个数据点在ε半径内的数据点,如果该半径内的数据点的个数大于等于minpts时,标记该点为核心对象,反之,为噪声点数据;
步骤3.3、以步骤2中的所有核心对象为出发点,找出其密度可达样本生成的聚类簇,直到所以核心对象都被访问停止迭代。
步骤4、输出:聚类后的集合c={c1,c2,…,ck},co,o=1,2,...,k为聚类之后的第o个聚类簇。
本发明一种le算法的工业监测数据聚类方法,分别建立了基于拉普拉斯特征映射算法的模型和密度聚类的模型,分别对多变量的采样数据进行压缩之后对其进行聚类,且不用输入聚类数目。
密度聚类方法是一种迭代算法,经过反复迭代之后,找出所有密度相连的最大点的集合。对于工业数据而言,本发明可以先对多变量数据进行压缩,压缩后的数据保留了其重要信息,再对其进行聚类,聚类后的每类数据相似度较高,便于找出其中的规律,具有非凡的意义。
以上所述为本发明较佳实施例,对于本领域的普通技术人员而言,根据本发明的教导,在不脱离本发明的原理与精神的情况下,对实施方式所进行的改变、修改、替换和变型仍落入本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!