一种ModbusTCP协议模糊测试中畸形数据过滤方法与流程
本发明涉及了工业网络安全领域,尤其涉及一种modbustcp协议模糊测试中畸形数据过滤方法。
背景技术:
工业网络控制系统安全问题受到广泛重视,modbus协议是modicon公司1979年提出的一种工业控制协议,具有协议标准开放、支持范围广和实时性好等特点,在工业控制系统中应用十分广泛。modbustcp协议是运行在tcp/ip协议上的modbus协议,modbus协议数据单元作为传输层负载进行传播,因此modbustcp协议也继承了tcp/ip协议的漏洞,此外,modbus协议本身存在如明文传输、缺乏认证机制等问题,以及实现过程中程序存在的不足也会产生一系列安全漏洞。
工业控制网络所使用的通信协议由于在其设计之初未充分考虑外来攻击和入侵等情况,其在安全性上有许多不足。modbus协议存在缺乏加密,缺乏认证和缺乏授权等问题。又由于modbustcp是运行于tcp/ip协议之上的modbus协议,tcp/ip协议中的存在的安全性问题也会影响到工业控制网络安全。如在modbustcp协议中,由于modbus协议数据单元以传输层负载的形式进行传播,通信双方可能受到中间人、拒绝服务、ip欺骗等互联网中常用攻击手段的攻击。同时由于工程师在实现工业控制网络通信协议的过程中可能存在经验不足等问题,最后实现的通信协议中也有可能存在漏洞。
针对工业控制网络攻击的种类和数量不断增多,在卡巴斯基实验室解决方案保护的能源组织工业控制系统中,有近40%在2017年下半年遭受过一次恶意攻击。恶意攻击者利用工业控制网络协议中的不足和漏洞可以对攻击对象造成严重的危害。在攻击者进行攻击之前发现不足和漏洞,以便于提前进行防范和修补具有重大意义。
模糊测试通过向待测目标输入大量的畸形数据来发现待测目标中存在的缺陷和漏洞。模糊测试常用来检测网络协议中存在的缺陷,输入文件是否合法,其测试的自动化程度较高,适用范围较广。模糊测试方法的一个评价指标是使用单位测试用例寻找到的待测目标的缺陷和漏洞的个数,个数越多则模糊测试的命中率越高。模糊测试可以被用于发现modbustcp协议中的漏洞。
由于运行modbustcp协议的工业设备通信能力不如商业it设备,因此对此类设备进行模糊测试时会因其可承受负载低而无法拥有可观的数据吞吐速率,进而降低了测试的速度。通过建立判定机制实现对畸形数据的实时过滤,在输入序列中保留发现待测目标漏洞可能性较高的畸形数据,舍弃可能性较低的畸形数据,一种在数据吞吐速率受限的情况下提高模糊测试的效率和速率的方法。
在处理训练判定机制的样本数据中,由于数据写入过长导致的缓冲区溢出是70%的漏洞的起因,因此样本数据的原始长度信息必须保留,且不能在后续处理中丢失,以使最终的判定机制获得对缓冲区溢出的判断能力,增加判定畸形数据能否发现漏洞的准确率。通过将在原始的样本数据格式中增加新的字段,其值为样本数据的实际长度,构造出一个改进的应用数据单元(iadu),从而防止在后续处理中因样本数据长度发生变化导致长度信息丢失。
训练数据中字段和字段之间的重复信息会给判定机制的训练和工作带来额外的计算量,从而影响判定的实时性。因此在保留样本数据原始长度信息的前提下,通过对样本数据的降维,舍弃冗余的字段,实现保证判定的准确性的同时降低计算量,从而保证了判定实时性。判定机制必须具有在保证实时判定的前提下,根据新的漏洞信息,迅速地更新判定规则的能力。概率神经网络由于准确率高,训练迅速的特点,可以用于构建判定机制。
技术实现要素:
本发明的目的在于,针对已有技术中待测modbustcp设备数据吞吐速率受限导致的模糊测试测试效率低的问题,提出一种modbustcp协议模糊测试中畸形数据过滤方法,通过保留待输入畸形数据队列中发现待测设备漏洞可能性较高的数据,舍弃可能性较低的畸形数据,实现了对待输入畸形数据的过滤,减少了无效测试数据的输入带来的额外通信负载,在待测目标数据吞吐速率受限的情况下,提升了模糊测试的速度和效率。
为达到上述目的,在本发明的一种modbustcp协议模糊测试中畸形数据过滤方法采用技术方案如下:
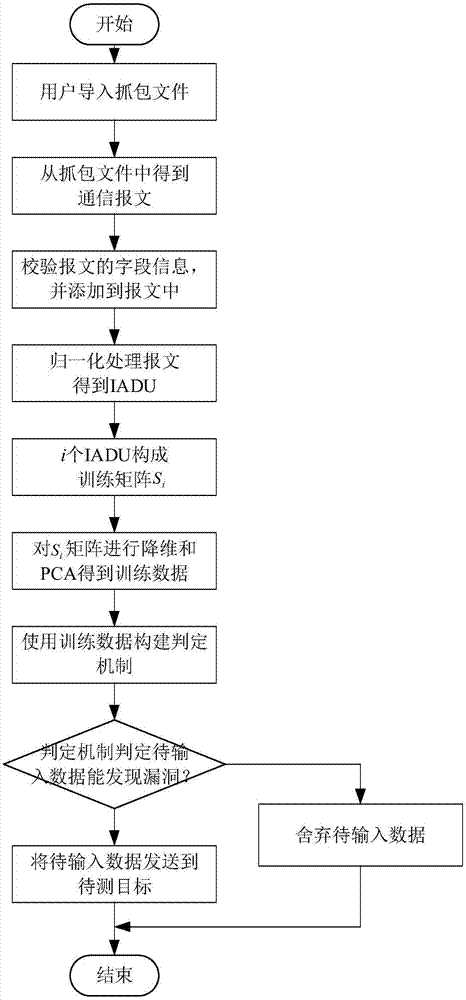
(1)用户导入抓包文件:用户使用数据输入部分中的训练数据导入模块导入抓包文件。
(2)获取通信报文:数据处理部分中的报文预处理模块从抓包文件中获得通信报文。
(3)检验通信报文的特定字段信息,并将该字段信息加入保温之中:为防止训练数据的长度信息在后续处理中因数据长度发生变化发生丢失,对通信报文的特定字段如长度字段进行重新校验,并将重新得到的字段信息添加入报文中,得到新的训练数据。
(4)对报文进行归一化处理得到iadu。各个字段归一化的基准是各自能取到的最大值。
(5)使用i个iadu构成训练数据矩阵si。
(6)对训练矩阵进行降维操作得到训练数据:为减小计算复杂度和降低最终的判定机制的结构复杂度,提取训练数据矩阵si的前j列得到矩阵sij。并对sij进行pca处理。将pca处理中的协方差矩阵c的所有特征值进行降序,取前m个特征值λ1,λ2,…,λm,使用其对应的特征向量p1,p2,…,pm构成矩阵t=(p1,p2,…,pm)。将sij投影到特征向量构成的矩阵上即可得到pnn构造样本的数据集
(7)使用训练数据构建判定机制:根据是否引发测试目标异常和异常的类型,可以将样本中的报文分为y-1种异常类型报文和1种正常类型的报文,将正常报文类型记为第1种类型。此处将第t类报文包含的报文总数记为nt。记rtw为
(8)判定机制判定输入数据,对之进行舍弃和保留:使用pnn判定待输入畸形数据的iadu。若判定结果为1,则舍弃该数据,若不为1,则将数据发送到待测设备。
本发明与现有技术相比较,具有显而易见的突出实质性特点和显著技术进步:(1)保留了训练数据的长度信息,使最终得到的判定机制能准确判定待输入数据的实际长度过长能否发现待测目标漏洞。(2)对训练数据矩阵si进行截取并进行pca能有效降低得到的pnn的结构复杂度,降低判定的计算量,保证判定的实时性。(3)随着测试过程的进行,由于pnn具有重训练迅速的特点,判定机制能实时地进行更新,从而增强判定能力。
附图说明
图1为本发明的具体操作程序框图。
图2是本发明的一种modbustcp协议模糊测试中畸形数据过滤方法被运用在对modbustcp协议进行模糊测试中的原理示意图。
图3是实施例中经过改进的modbustcp应用数据单元的格式。
图4是实施中所建立的pnn示意图。
图5是实施例中所使用的pnn工作流程图。
具体实施方式
为使本发明的技术方案和优点更加清晰明确,下面将结合本发明中优选实施例中的附图,对本发明实施例中的技术方案进行详细阐述,显然,所阐述的实例仅仅是本发明的一部分实例,并不是全部实例。基于本发明中的实施例,本领域的普通技术人员在没有做出创造性工作前提下所获得的所有其他实例,都属于本发明保护的范围。
参看图2,所有实施例基于本发明提出了一种modbustcp协议模糊测试中畸形数据过滤方法。
实施例一:
参见图1,实施例一中的modbustcp协议模糊测试中畸形数据过滤方法,操作步骤如下:
(1)用户导入抓包文件;
(2)从抓包文件中得到通信报文;
(3)校验通信报文的特定字段信息,并将该字段信息加入到报文之中;
(4)对报文归一化处理得到iadu;
(5)将i个iadu构造训练矩阵,i为除0和1的自然数;
(6)对训练矩阵进行降维得到训练数据;
(7)使用训练数据构建判定机制;
(8)判定机制判定待输入数据,对之进行舍弃和保留。
实施例二:
本实施例与实施例一基本相同,特征值之处如下:
所述步骤(3)中涉及的特定字段是用来反映报文长度信息的字段。
所述步骤(4)中涉及的归一化处理中所采用的基准为各个字段能取到的实际最大值。
所述步骤(5)中使用多个iadu构造训练矩阵时,每个iadu对应训练矩阵的行。
所述步骤(6)中,降维处理主要包括提取前列和pca处理。
所述步骤(7)中所涉及的判定机制为pnn。
所述步骤(8)中判定机制将保留发现漏洞可能性较高的畸形数据,舍弃可能性较低的畸形数据。
实施例三:
本实例中所采用的实施例分为数据输入部分、数据处理部分和测试记录分类部分。
数据输入部分由模糊数据输入模块和训练报文导入模块组成。用户经训练报文导入模块选择需要使用的训练报文,本实例中用户导入的训练数据是为使用wireshark抓取的待测目标的modbustcp通信数据,格式为pcap文件。pcap文件中包含引发待测目标漏洞的通信数据。模糊数据输入模块在本实例中使用本机通讯的方法,使用套接字通信将第三方模糊数据产生器peach产生的模糊数据发送至pnn判定模块。
数据处理部分的modbus报文预处理模块使用python的scapy模块对用户导入的pcap文件进行解析,获得原始通信数据和每次通信对应的结果。
数据处理部分中的modbus报文预处理模块对原始通信数据进行重新校验。参看图3。对modbustcp的应用数据单元(adu)中的长度、单元标识符、功能码和数据的实际长度进行重新校验得到新的字段
对于每个iadu可以由一个向量来表示:
其中data[n]表示数据字段第n+1个字节的值。
对于每个iadu向量,根据每个字段能取到的最大值,进行归一化处理。得到向量a,
其中mss为tcp/ip握手过程中通信双方协商的应用数据段最大长度。
对于i个报文,可以构造一个iadu矩阵si=(a1,a2,…,ai)t,构造过程中,若向量ak的维数d(ak)小于max(d(am)),(1≤m≤i),则对ak向量不足的维数补零。
为进一步减少计算量,对与矩阵si选取前j列得到新的矩阵sij,记sij=(s1,s2,…,sj)t。
计算sij的协方差矩阵c:
求c的特征值和特征向量,对特征值进行降序排序,选择前第1到m(m<j)个特征值λ1,λ2,…,λm,对应的特征向量p1,p2,…,pm组成特征向量矩阵t=(p1,p2,…,pm)。
将sij投影到特征向量构成的矩阵上即可得到pnn构造样本的数据集
对于样本中的i个报文可以得到训练数据集
根据是否引发测试目标异常和异常的类型,可以将样本中的报文分为y-1种异常类型报文和1种正常类型的报文,将正常报文类型记为第1种类型。此处将第t类报文包含的报文总数记为nt。记rtw为
在本实例中,正常类型的报文的编号为1。
设计pnn如图4所示,从左至右分别为输入层、模式层、求和层和输出层。其中输入层中输入向量的元素数目为m,即输入向量有m个特征。求和层中的神经元是训练数据集
pnn的工作原理如图5所示。pnn在收到模糊数据输入模块输入的一个数据后,先进行数据预处理。具体操作为将输入数据重新计算,校验,归一化处理后得到的向量投影到由训练样本得到的矩阵t上,得到向量x=(x1,x2,…,xm)。
将x=(x1,x2,…,xm)输入pnn判定模块。
pnn中输入层和模式层之间的连接是通过一个高斯函数,求得模式层中每个神经元和输入层中每个神经元的相似程度值。
求和层中对每个类中各自的所有神经元相似程度加权求平均。
输入向量x对第t类漏洞的相似程度可以表示为:
其中σ为表示平滑参数,为唯一可以调整的量,通常σ∈(0,1)。
输出层输出匹配相似度最大的类别,若判定为1,则表示原始的模糊数据很有可能无法引发待测目标异常,进而无法有效发现待测目标的漏洞,判定该数据为冗余测试数据,并舍弃之。判定不为1,则将数据发送到modbus测试模块。
在本实例中,异常监测模块通过定时向待测目标发送icmp报文来检测待测目标是否正常工作。若正常回复,则待测目标工作正常,反之则为不正常。
在检测到待测目标工作发生异常后,异常分类模块将读取待测目标的工作日志,并对产生的异常进行分类,并记录相应的漏洞信息和测试数据。
- 还没有人留言评论。精彩留言会获得点赞!