一种人脸活体检测方法与流程
本发明属于图像处理领域,尤其涉及到一种人脸活体检测方法。
背景技术:
随着大数据时代的到来和深度学习的发展,人脸识别技术取得了重大突破。人脸识别已经被广泛地应用于公共安防、银行金融、公安刑侦、社交媒体等领域,特别是近来将人脸识别技术应用到手机屏幕解锁。然而,基于人脸识别缺陷的假冒手段也层出不穷,其中主要以人脸照片和视频影像作为冒充手段。提高人脸识别的安全性,可靠性,利用活体检测技术有效的防范冒充手段,这是亟待解决的问题。
技术实现要素:
本发明的目的在于提高活体检测技术用于人脸识别系统的可靠性,提出了一种人脸活体检测方法。
本发明采用的技术方案是:
一种人脸活体检测方法,包括以下步骤:
步骤1:人脸检测与关键点定位:
利用mtcnn开源目标检测算法训练人脸检测模型和预测13个关键点位置,所述mtcnn算法是基于深度学习的目标检测算法,利用训练的模型检测人脸框位置信息(χf,yf,wf,hf),输出13个关键点位置信息((x1,y1),(x2,y2)…(x13,y13));
步骤2:基于眨眼动作的活体检测:
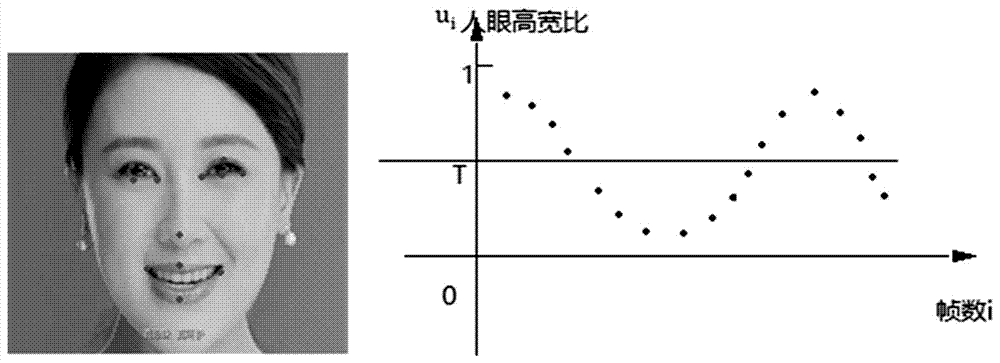
由步骤1得到的13个关键点中的第1点为左眼的左眼角点,第2点为左眼上眼皮的点,第3点为左眼右眼角点,第4点为左眼角下眼皮的关键点,第5点为右眼的左眼角点,第6点为右眼上眼皮的点,第7点为右眼的右边眼角点,第8点为右眼角下眼皮的关键点。利用欧氏距离计算视频中第i帧人眼高
判断眨眼动作发生的条件:在第i+m帧时比值ui+m>t>ui+m+1且随后r帧出现ui+m+r<t<ui+m+r+1或者在第i+r帧时ui+r<t<ui+r+1且随后m帧出现ui+r+m>t>ui+r+m+1,其中m为睁眼后到闭眼前时间间隔内的帧数,r为闭眼后到睁眼前时间间隔的帧数;
其中wi和
所述阈值t的取值步骤为:
①统计数据集中n张图片人眼的宽和高,求取宽高的均值
②计算阈值t:
步骤3:基于边框检测的活体检测:
采用深度学习训练一个检测照片框、视频边框与手机边框的边框检测卷积神经网络模型,在视频第i帧检测到人脸框位置信息为(χfi,yfi,wfi,hfi),如果边框检测模型检测到有边框,其位置信息为(χbi,ybi,wbi,hbi),只要人脸框包含在模型检测到的边框内,则不认为是活体,反之,则认为是活体;
判断人脸框包含在检测到边框内的公式为:
χfi>χbi;yfi>ybi(7)
χfi+wfi<χbi+wbi(8)
yfi+hfi<ybi+hbi(9)
(3a)训练与测试数据准备:通过相机拍摄打印的图片、录制播放着的手机视频以及录制包含照片的视频,总计n张图片,标注边框的位置信息,标注框略大于边框;
(3b)对图像数据进行数据增强:将n张图片通过平移、旋转图像(0°,90°,180°,270°)来增加数据,使数据变为原来的16倍;将数据集按照8:1:1的比例分成训练集,验证集和测试集;
(3c)对图像数据进行处理:将图像缩放到m×m的尺寸,再转换成灰度图片,把处理好的图片数据存为hdf5(hierarchicaldataformat)文件;
(3d)网络结构:所述的卷积神经网络层包含3个卷积层,1个bn层和2个全连接层,它的输出层节点数4个,选定损失函数
(3f)训练:将处理完的数据送入卷积神经网络,网络输入批量大小(batchsize)设置为64,随机初始化各层的连接权值w和偏置b,给定学习速率η;
(3e)测试:将测试集数据输入训练好边框检测模型,检测有无边,如果有,输出边框位置信息(χb,yb,wb,hb);
步骤4:结合边框检测与人眼眨眼判断的活体检测:
由步骤2与步骤3所述的两种方法进行联合活体检测。首先对摄像头采集的视频进行人脸检测,如果检测到人脸,就开始进行边框检测,如果检测到视频中带有边框,且边框内包含检测到的人脸框,则不让其通过,认为他是非活体;若未检测到边框或检测到的边框内不包含人脸,则通过对视频中人眼是否有眨眼进行判断,如果有眨眼,判断为活体,否则判断为非活体。
附图说明
以下结合附图,对本发明的具体实施方式做进一步的详细描述。
图1为本发明的一种人脸活体检测方法所述人眼眨眼动作判断示意图;
图2为本发明的一种人脸活体检测方法所述照片、视频和手机边框检测网络图;
图3为本发明的一种活体检测主要流程图。
具体实施方式
本发明公开了一种人脸活体检测方法,下面结合附图对本发明的具体实施方式做详细的说明。
步骤1:人脸检测与关键点定位:
利用mtcnn开源目标检测算法训练人脸检测模型和预测13个关键点位置,所述mtcnn算法是基于深度学习的目标检测算法,利用训练的模型检测人脸框位置信息(χf,yf,wf,hf),输出13个关键点位置信息((x1,y1),(x2,y2)…(x13,y13));
步骤2:基于眨眼动作的活体检测:
由步骤1得到的13个关键点中的第1点为左眼的左眼角点,第2点为左眼上眼皮的点,第3点为左眼右眼角点,第4点为左眼角下眼皮的关键点,第5点为右眼的左眼角点,第6点为右眼上眼皮的点,第7点为右眼的右边眼角点,第8点为右眼角下眼皮的关键点。利用欧氏距离计算视频中第i帧人眼高
判断眨眼动作发生的条件:在第i+m帧时比值ui+m>t>ui+m+1且随后r帧出现ui+m+r<t<ui+m+r+1或者在第i+r帧时ui+r<t<ui+r+1且随后m帧出现ui+r+m>t>ui+r+m+1,其中m为睁眼后到闭眼前时间间隔内的帧数,r为闭眼后到睁眼前时间间隔的帧数;
其中wi和
所述阈值t的取值步骤为:
①统计数据集中n张图片人眼的宽和高,求取宽高的均值
②计算阈值t:
步骤3:基于边框检测的活体检测:
采用深度学习训练一个检测照片框、视频边框与手机边框的边框检测卷积神经网络模型,在视频第i帧检测到人脸框位置信息为(χfi,yfi,wfi,hfi),如果边框检测模型检测到有边框,其位置信息为(χbi,ybi,wbi,hbi),只要人脸框包含在模型检测到的边框内,则不认为是活体,反之,则认为是活体;
判断人脸框包含在检测到边框内的公式为:
χfi>χbi;yfi>ybi(7)
χfi+wfi<χbi+wbi(8)
yfi+hfi<ybi+hbi(9)
(3a)训练与测试数据准备:通过相机拍摄打印的图片、录制播放着的手机视频以及录制包含照片的视频,总计n张图片,标注边框的位置信息,标注框略大于边框;
(3b)对图像数据进行数据增强:将n张图片通过平移、旋转图像(0°,90°,180°,270°)来增加数据,使数据变为原来的16倍;将数据集按照8:1:1的比例分成训练集,验证集和测试集;
(3c)对图像数据进行处理:将图像缩放到m×m的尺寸,再转换成灰度图片,把处理好的图片数据存为hdf5(hierarchicaldataformat)文件;
(3d)网络结构:所述的卷积神经网络层包含3个卷积层,1个bn层和2个全连接层,它的输出层节点数4个,选定损失函数
(3f)训练:将处理完的数据送入卷积神经网络,网络输入批量大小(batchsize)设置为64,随机初始化各层的连接权值w和偏置b,给定学习速率η;
(3e)测试:将测试集数据输入训练好边框检测模型,检测有无边,如果有,输出边框位置信息(χb,yb,wb,hb);
步骤4:结合边框检测与人眼眨眼判断的活体检测:
由步骤2与步骤3所述的两种方法进行联合活体检测。首先对摄像头采集的视频进行人脸检测,如果检测到人脸,就开始进行边框检测,如果检测到视频中带有边框,且边框内包含检测到的人脸框,则不让其通过,认为他是非活体;若未检测到边框或检测到的边框内不包含人脸,则通过对视频中人眼是否有眨眼进行判断,如果有眨眼,判断为活体,否则判断为非活体。
- 还没有人留言评论。精彩留言会获得点赞!