对半导体样本中的缺陷进行分类的方法和其系统与流程
当前公开的主题一般涉及样本检查的领域,并且更具体地,涉及能够进行自动缺陷分类的方法和系统。
背景技术:
当前对与制造的器件的超大规模集成相关联的高密度和性能的需求要求亚微米特征、增加的晶体管和电路速度、以及提高的可靠性。此类要求需要形成具有高精度和均匀性的器件特征,这反过来需要仔细监控制造工艺,所述监控包括在器件仍是半导体样本的形式时对器件进行频繁且详细的检查。
本说明书中使用的术语“样本”应广泛地被解释为覆盖任何种类的用于制造半导体集成电路的晶片、掩模和其它结构、上述的组合和/或上述部分、磁头、平板显示器和其它半导体制品。
本说明书中使用的术语“缺陷”应广泛地被解释为覆盖在样本上或样本内形成的任何种类的异常或不期望的特征。
样本的复杂的制造工艺不是无错的,并且此类错误可能导致制造的器件中的故障。故障可能包括可损害器件操作的缺陷,以及滋扰(nuisances),所述滋扰可能是缺陷但不会导致制造的器件的任何损害或故障。通过非限制性示例,缺陷可能是由于原料中的问题、机械、电学或光学错误、人为错误或其它原因而在制造工艺中引起的。另外,缺陷可能是因时间-空间因素引起的,诸如在检查工艺期间的一个或多个制造阶段之后发生的晶片温度变化,这可能会导致晶片的一些变形。检查工艺还可能会引入另外的所谓的错误,例如因检查设备或工艺中的光学、机械或电学问题而造成的错误,这因此提供了不完善的捕获。此类错误可能产生假阳性结果,其看上去可能包含缺陷,但实际上在区域处并无缺陷。
在许多应用中,缺陷的类型或类(class)是重要的。例如,缺陷可以被分类为多个类中的一个,诸如颗粒、划痕、突起或类似的类。
除非另外特别说明,否则本说明书中使用的术语“检查”应广泛地被解释为覆盖对象中的缺陷的任何种类的检测和/或分类。检查是通过在待检查的对象的制造期间或之后使用非破坏性检查工具来提供。通过非限制性示例,检查工艺可以包括使用一个或多个检查工具的关于对象或对象的部分而提供的扫描(在单次扫描的形式或多次扫描的形式)、采样、审查、测量、分类和/或其它操作。同样地,检查可以在制造待检查的对象之前被提供,并且可以包括例如生成(多个)检查方案。将注意,除非另外特别说明,否则本说明书中使用的“检查”或其衍生术语并不限于(多个)检验区域的尺寸、扫描的速度或分辨率,或检查工具的类型。通过非限制性示例,各种非破坏性检查工具包括光学工具、扫描电子显微镜、原子力显微镜等。
检查工艺可以包括多个检查步骤。在制造工艺期间,检查步骤可以执行多次,例如在制造或处理某些层之后或类似的时刻。另外地或替代地,每个检查步骤可以重复多次,例如针对不同的样本位置或针对相同的样本位置并使用不同的检查设定。
通过非限制性示例,执行时的检查可以采用两步过程,例如,检查样本,接着审查采样的缺陷。在检查步骤期间,通常以相对高的速度和/或低的分辨率扫描样本表面或样本表面的一部分(例如,感兴趣的区域、热点等)。分析捕获的检查图像,以便检测缺陷并获得缺陷位置和其它检查属性。在审查步骤处,通常以相对低的速度和/或高的分辨率捕获在检验阶段期间检测到的缺陷的至少部分的图像,从而使得其能够对缺陷的至少部分进行分类并可选地进行其它分析。在一些情况下,两个阶段都可以由相同的检查工具实现,并且在一些其它情况下,这两个阶段由不同的检查工具实现。
技术实现要素:
根据目前公开的主题的某些方面,提供了一种能够将样本中的缺陷分类为多个类的系统,系统包括处理和存储器电路(processingandmemorycircuitry,pmc),pmc经构造以:获得指示针对多个类中的每个类单独地定义的品质要求的数据,并获得指示将多个类中的每个类分配给具有不同的优先级的三个或更多个分类组中的一个分类组的数据。另外,系统经构造以在训练期间:获得包括多个预先分类的训练缺陷和多个训练缺陷的属性值的训练数据;提供至多个类的类中的多个训练缺陷的初始自动分类,以产生初始分类的训练缺陷;处理初始分类的训练缺陷以获得对应于自动分类的最高可能的贡献并同时满足针对多个类中的每个类定义的每类品质要求的最佳工作点;和生成具有对应于最佳工作点的置信度阈值的分类规则,其中置信度阈值对应于优先拒绝区间(bin),并且其中至少“无法决定(cannotdecide,cnd)”拒绝区间对应于三个或更多个分类组。系统还经构造以在对样本中的缺陷进行分类时应用生成的分类规则。
通过非限制性示例,每个类可以被分配给以下分类组中的一个:具有最高的优先级的分类组“感兴趣的关键缺陷(keydefectsofinterest,kdoi)”;“感兴趣的缺陷(defectsofinterest,doi)”;和具有最低的优先级的分类组“假”。优先拒绝区间可相应地由“kdoi”cnd拒绝区间、“doi”cnd拒绝区间、“假”cnd拒绝区间和“未知(unknown,unk)”拒绝区间组成,并且其中cnd拒绝区间的优先级对应于相应的分类组的优先级。
通过另一非限制性示例,每个多数类(majorityclass)可以被分配给以下分类组中的一个:“kdoi”、“doi”和“假”,而少数类(minorityclass)可以被分配给“新(novelty)”分类组,并且组的优先级可以按以下顺序而配置:“kdoi”>“新”>“doi”>“假”。因此,优先拒绝区间可以由“kdoi”cnd拒绝区间、“doi”cnd拒绝区间、“假”cnd拒绝区间和“新”unk拒绝区间组成,并且其中所有拒绝区间的优先级对应于相应的分类组的优先级。
根据目前公开的主题的另一方面,提供了一种将样本中的缺陷自动分类为多个类的方法。方法包括:通过处理和存储器电路(pmc)获得指示针对多个类中的每个类单独地定义的品质要求的数据,并通过pmc获得指示将多个类中的每个类分配给具有不同的优先级的三个或更多个分类组中的某个分类组的数据。方法还包括,在训练期间:通过pmc获得包括多个预先分类的训练缺陷和多个训练缺陷的属性值的训练数据;通过pmc提供至多个类的类中的多个训练缺陷的初始自动分类,以产生初始分类的训练缺陷;通过pmc处理初始分类的训练缺陷以获得对应于自动分类的最高可能的贡献并同时满足针对多个类中的每个类定义的每类品质要求的最佳工作点;和通过pmc生成具有对应于最佳工作点的置信度阈值的分类规则,其中置信度阈值对应于优先拒绝区间,并且其中至少“无法决定(cnd)”拒绝区间对应于三个或更多个分类组。方法还包括在对样本中的缺陷进行分类时通过pmc应用生成的分类规则。
根据另外方面且可选地结合目前公开的主题的其它方面,处理初始分类的训练缺陷以获得最佳工作点的步骤可以包括:针对每个多数类,通过pmc获得有效分类工作点,每个有效分类工作点满足针对相应的类定义的品质要求并表征为对应于优先拒绝区间的置信度阈值;和通过pmc处理有效分类工作点以获得最佳工作点。获得有效类工作点可以包括在优先拒绝区间上分配训练缺陷的至少一部分,其中,取决于相应的分类组的相对优先级和拒绝区间的优先级,根据预定规则提供针对某个缺陷选择拒绝区间。
根据另外方面且可选地结合目前公开的主题的其它方面,可以将分配给相同的分类组的若干类绑定在一起,并且可以将绑定类所述单个类来针对绑定类定义品质要求
根据另外方面且可选地结合目前公开的主题的其它方面,针对给定类定义的品质要求可以包括提取率要求,提取率要求对以下两者进行计数:给定类的正确分类的缺陷,和属于给定类的且已被拒绝到被选定为对给定类的提取率进行计数的一个或多个优先拒绝区间的缺陷。可选地,具有不低于给定类的分类组的优先级的优先级的所有拒绝区间可以被选择以作为针对给定类的提取率的计数。
根据另外方面且可选地结合目前公开的主题的其它方面,自动分类的贡献可以根据分类目的而被不同地计算,并且可以是可由用户配置的。
目前公开的主题的某些实施方式的优点之一是提供满足针对每一类或有界类单独地定义的品质要求的自动分类的能力。
附图说明
为了理解本发明并且理解本发明如何在实践中实施,现在将参考随附附图并仅通过非限制性示例的方式来描述实施方式,其中:
图1示出了根据目前公开的主题的某些实施方式的检查系统的概括框图;
图2示出了根据目前公开的主题的某些实施方式的对缺陷进行分类的概括流程图;
图3示出了根据目前公开的主题的某些实施方式的训练分类器的概括流程图;
图4示意性地示出了根据目前公开的主题的某些实施方式而构造的示例性混淆矩阵;
图5a-5d示意性地示出了根据目前公开的主题的某些实施方式的拒绝过程的非限制性示例;
图6示意性地示出了根据目前公开的主题的某些实施方式获得的示例性混淆矩阵;和
图7示出了处理工作点以获得实现最高可能的adc贡献并同时满足每类品质要求的最佳工作点的概括流程图。
具体实施方式
在以下详述中,阐述许多特定细节,以便提供对本发明的透彻理解。然而,本领域的技术人员将理解,可以在没有这些特定细节的情况下实践目前公开的主题。在其它情况下,未详细描述所熟知的方法、过程、部件和电路,以便不会不必要地模糊目前公开的主题。
除非另外特别说明,从以下讨论中将显而易见的是,将了解,在整个本说明书讨论中,利用诸如“处理”、“计算”、“表示”、“运算”、“生成”、“分配”、“选择”或类似术语是指操纵数据和/或将数据变换为成其它数据的计算机的(多个)动作和/或(多个)处理,所述数据被表示为物理量(诸如电学量)和/或所述数据表示物理对象。术语“计算机”应广泛地被解释为覆盖具有数据处理能力的任何种类的基于硬件的电子装置,通过非限制性示例,包括本申请中公开的分类器和pmc。
本文使用的术语“非暂时性存储器”和“非暂时性存储介质”应广泛地被解释为覆盖适合于目前公开的主题的任何易失性或非易失性计算机存储器。
本说明书中使用的术语“样本中的缺陷”应广泛地被解释为覆盖在样本上或样本内形成的任何种类的异常或不期望的特征。
本说明书中使用的术语“设计数据”应广泛地被解释为覆盖指示样本的分层物理设计(布局)的任何数据。设计数据可以由相应的设计者提供和/或可以从物理设计导出(例如,通过复杂模拟、简单几何和布尔操作等)。可以以不同的格式提供设计数据,通过非限制性示例,诸如gdsii格式、oasis格式等。设计数据可以以矢量格式、灰度级强度图像格式或以其它方式呈现。
将了解,除非另外特别说明,在单独实施方式的上下文中描述的目前主题的某些特征也可以在单个实施方式中组合提供。相反,在单个实施方式的上下文中描述的目前主题的各种特征也可以单独地提供或以任何合适的子组合的形式提供。在以下详述中,阐述许多特定细节,以便提供对方法和设备的透彻理解。
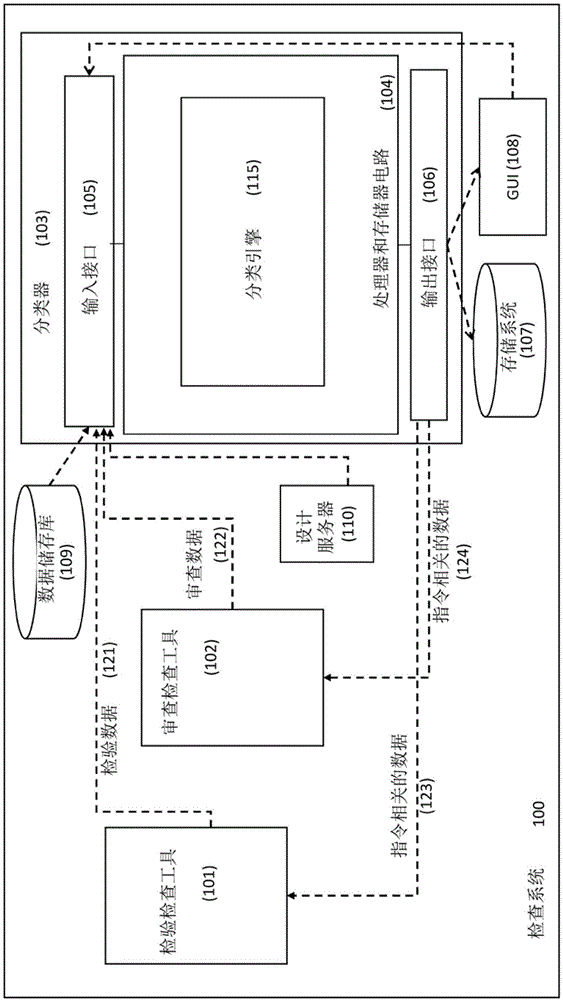
考虑到这一点,注意图1,其示出了根据目前公开的主题的某些实施方式的检查系统的概括框图。图1中所示的检查系统100可以用于检查作为样本制造的一部分的样本(例如,晶片和/或晶片的一部分)检查。检查可以是对象制造的一部分,并且可以在制造对象期间或之后被执行。检查系统可以包括各种检查工具,例如,经构造以捕获检验图像(典型地,以相对高的速度和/或低的分辨率)的一个或多个检验工具101,以及经构造以捕获(典型地,以相对较低的速度和/或较高的分辨率)由检验工具101检测到的缺陷的至少一部分的审查图像的一个或多个审查工具102。所示出的检查系统100还包括基于计算机的自动缺陷分类工具(在下文中也被称为作为分类器)103,分类器103能够根据包括一个或多个子规则的分类规则集(以下称为分类规则)自动地将缺陷分类为多个类。作为非限制性示例,分类可以具有不同的目的,并且分类结果可以用于建立pareto图,以便根据分类目的而识别统计过程控制(statisticalprocesscontrol,spc)中的偏移,从真实缺陷中过滤假缺陷,识别特定的感兴趣的缺陷(defectsofinterest,doi)和/或进行其它操作。
分类器103可以可操作地连接到一个或多个检验工具101和/或一个或多个审查工具102。可选地,分类器103可以与一个或多个审查工具102完全地或部分地集成。分类器103还可可操作地连接到设计服务器110和数据储存库109。
样本可以通过检验工具101(例如,光学检验系统、低分辨率sem等)检查。所得到的图像和/或衍生数据可以被处理(可选地与其它数据一起作为例如设计数据和/或缺陷分类数据)以选择用于审查的潜在缺陷。
被选择用于审查的潜在缺陷位置的子集可以由审查工具102(例如,扫描电子显微镜(scanningelectronmicroscope,sem)或原子力显微镜(atomicforcemicroscopy,afm)等)进行审查。具有审查图像和/或其衍生数据的信息的数据(在下文中称为审查数据122)以及相应关联的元数据可以直接地或经由一个或多个中间系统传输到分类器103。注意,审查数据可以包括由一个或多个中间系统生成的数据以作为审查图像的衍生数据。
分类器103包括可操作地连接到基于硬件的输入接口105和基于硬件的输出接口106的处理器和存储器电路(pmc)104。pmc104经构造以提供操作分类器需要的处理,如参考图2-7更详细描述的,并且包括可操作地连接到存储器(未在pmc内单独示出)的处理器。将参考图2-7更详细地描述分类器103和pmc104的操作。
本领域的技术人员将容易地理解,当前公开的主题的教导不受图1中所示的系统的约束;等效和/或修改的功能可以以另一方式合并或分割并且可以以软件与固件和/或硬件的任何适当的组合来实现。
将注意,图1中所示的检查系统可以在分布式计算环境中实施,其中图1中所示的前述功能模块可以被分布在若干本地和/或远程装置上,并且可以通过通信网络链接。还应注意,在其它实施方式中,检查工具101和/或102、数据储存库109、存储系统107和/或gui108的至少一部分可以在检查系统100外,并且经由输入接口105和输出接口106与分类器103进行数据通信操作。分类器103可以被实现为独立的(多个)计算机,以与一个或多个检查工具结合地使用。可选地,分类器可以对存储在数据储存库109和/或存储系统107中的预先获取的审查数据进行操作。替代地或另外地,分类器的相应功能可以至少部分地与一个或多个检查工具、工艺控制工具、方案生成工具、用于自动缺陷审查和/或分类的系统,和/或与检查相关的其它系统集成。
参考图2,其示出了根据目前公开的主题的某些实施方式的操作自动缺陷分类器的概括流程图。pmc104经构造以根据在非暂时性计算机可读存储介质上实施的计算机可读指令来执行下文详述的相应操作。
如上指出,分类器103能够根据分类规则而自动地将缺陷分类为多个类。分类规则包括分类引擎(例如,支持矢量机(supportvectormachine,svm)、随机森林分类引擎、神经网络等)和可针对不同类别而不同的多个置信度阈值。分类器103还经构造以针对每个给定缺陷定义指示缺陷属于特定类别的概率的置信度水平,并且如果置信度水平满足相应的置信度阈值,那么将给定缺陷分配给某个类。
仅出于说明的目的,提供以下描述以用于多类svm(支持矢量机)分类器。本领域的技术人员将容易地了解,目前公开的主题的教导同样地适用于适于对缺陷进行分类的任何其它分类器和/或分类器的组合。
作为说明,每个类可以在属性超空间(attributehyperspace)中被呈现为体积,并且阈值置信度水平可以用于绘制类体积(classvolum)的边界(类体积的边界可以更大或更小并且边界的形状可以基于阈值置信度水平而不同)。根据给定缺陷的属性,分类规则确定受置信度阈值影响的给定缺陷所属的属性超空间中的体积(即,类),或如果给定缺陷不属于体积(类)中的一个,那么拒绝给定缺陷。当被拒绝的缺陷落入属性超空间中的可能是多于一个类的一部分的位置时,缺陷可以被标记为“无法决定(cnd)”;并且当被拒绝的缺陷落入属性超空间中的不属于任何类的一部分的位置时,缺陷可以被标记为“未知(unk)”。通过非限制性示例,缺陷属性值可以代表形状、纹理、材料、背景、形貌和/或与缺陷相关的其它特征。
在操作之前,使用一组训练数据(201)训练分类器(202),训练数据(201)包括已经被预先分类到预定类中的缺陷的集合(例如,通过人类专家和/或另一分类器和/或先前的分类器的版本)和所述缺陷的属性值。在训练时,分类器使用训练数据设定分类规则(203)。分类规则包括在训练期间获得的并可用于在被识别为属于给定类的缺陷和不属于给定类的缺陷之间进行区别的多个置信度阈值。因此,训练的分类器103能够根据置信度阈值定义给定缺陷的类,以作为与多维属性空间(以下称为属性超空间)中的每个预定缺陷类相关联的缺陷属性值的函数。
在训练时,分类器接收(205)与待被分类的具有缺陷的信息的缺陷相关数据,并且应用分类规则以相应地对缺陷进行分类(204)。将注意,本文使用的术语“缺陷相关数据”应广泛地被解释为覆盖缺陷分类所要求的任何属性的值。缺陷属性的值可以作为审查数据的一部分而被分类器接收。替代地或另外地,缺陷属性值的至少部分可以由分类器从接收到的审查数据(可选地,使用附加数据作为例如设计数据)导出和/或可以从一个或多个其它源(包括检验工具)接收。
受(多个)置信度阈值的影响,分类器在预定缺陷类中划分属性超空间,并且根据每个缺陷在属性超空间内的位置而将每个缺陷分配给类中的一个来产生分类的缺陷(206)。在划分时,当缺陷中的一些属于类之间的重叠区域(即,属于某个类的概率低于置信度阈值定义的概率)时,分类器拒绝(207)这种缺陷以作为cnd(无法决定)的缺陷,因为分类器无法决定要选择哪个类。同样,当缺陷中的一些位于类的外边界外时,分类器拒绝这种缺陷以作为未知(unk)缺陷的缺陷。被拒绝的缺陷或这些被拒绝的缺陷的一部分可以被传递给人类检验员以进行分类,或被传递给添加了先前的分类器不可用的新的知识的任何模态以进行分类。
给定缺陷可以属于多数类或少数类。当分类规则被应用于训练数据集时,被预先分类为多数类的大多数的训练缺陷也将被自动地分类为多数类,而预先分类为少数类的大多数的训练缺陷将不会被自动地分类为属于相应的少数类,并且将被拒绝或被分类到多数类。
分类结果可以由参考图3-6进一步详细地描述的一个或多个品质测量(例如,纯度、准确度、提取率)和性能(例如,adc贡献)进行表征。设定较低的置信度要求可能导致分类器拒绝更少缺陷,但是可能导致更多的分类错误,或丢失一些感兴趣的缺陷。另一方面,增加置信度要求可以提高分类品质,但是代价是更高的拒绝率或误报率。
可选地,在操作期间,分类器可以监控(208)性能/品质参数,并且根据结果而可以重新训练以相应地改善分类规则(例如,使用错误分类的缺陷的后分类结果)。
训练和操作分类器的非限制性示例在us2016/0189055号美国专利申请、us8,315,453号美国专利、9,607,233号美国专利和9,715,723号美国专利中公开,以上申请被转让给本申请的受让人并且以引用的方式将其全部内容并入本文以获得附加或替代的细节、特征和/或技术背景的适当教导。
如将参考图3-6更详细描述的,根据当前公开的主题的某些实施方式,分类器103经构造以使得其能够将每个类分配给具有不同的优先级的三个或更多个分类组中的某个分类组。分配给给定分类组的所有的一个或多个类具有相同的优先级,此优先级对应于给定分类组的优先级,并且不同于分配给另一分类组的所有的一个或多个类的优先级。分类器103还被构造以使得其能够定义分类组的优先级。在gui108的帮助下,用户可以定义组的优先级,定义用于自动分类的类,并且将这些类分配给相应的分类组。或者,这些定义的至少一部分可以由分类器103根据预定规则而提供,或经由输入接口105从外部系统(例如,fab管理系统)接收。
另外,分类器103经构造以使得用户(和/或管理系统)能够针对每个类单独地设定纯度、准确度和/或提取率要求,并且根据每类要求来优化分类结果。如将参考图3-6更详细描述的,分类器103可以经构造以使得其能够将来自相同的分类组的若干类绑定在一起,并且将绑定类作为单一类来对绑定类设定品质要求。
参考图3,其示出了根据目前公开的主题的某些实施方式的训练自动缺陷分类器的概括流程图。pmc104经构造以根据在非暂时性计算机可读存储介质上实施的计算机可读指令来执行以下详述的相应操作。
在训练之前,分类器103获得(301)指示将类分配给三个或更多个优先分类组的数据。此类数据可以经由gui108而作为用户输入接收,可以由分类器103根据预定规则生成和/或可以经由输入接口105从外部系统(例如,fab管理系统)接收。通过非限制性示例,类(多数和少数两者)可以被分配到以下分类组(按优先级顺序):关键感兴趣的缺陷(kdoi)、感兴趣的缺陷(doi)和假。作为另一非限制性示例,多数类可以被分配给kdoi、doi和假分类组,而少数类可以被分配给“新”分类组,并且组的优先级可以按以下顺序而配置:kdoi>新类>doi>假。
另外,在训练之前,分类器获得(303)指示每类品质要求的数据。此类数据可以经由gui108作为用户输入接收和/或可以经由输入接口105从外部系统(例如,fab管理系统)接收。可选地,但非必需地,被分配给同一组的类可以具有类似的分类目的,并且因此具有类似的品质要求。通过非限制性示例,分类器103可以经构造以实现针对kdoi组中的类的高提取率和/或高纯度,以实现针对doi组中的类的中提取率和/或中纯度,并且实现针对假组中的某些类的低提取率和/或低纯度。
在接收(302)包括预先分类的缺陷和这些缺陷的属性值的集合的训练数据时,分类器将分类引擎应用于训练缺陷以接收将训练缺陷分到各类的训练缺陷的初始分离。初始分离(虽然这不是强制性的)可以设有置信度阈值,所述置信度阈值被设定为使得其能够进行分离并没有拒绝的值。通过非限制性示例,分类引擎可以是多类支持矢量机(svm)、随机森林分类引擎或其它合适的分类引擎或其组合。
图4示出了呈现初始分离的结果的示例性混淆矩阵。本说明书中使用的术语“混淆矩阵”应广泛地被解释为覆盖允许使分类规则的品质和性能可视化的表格布局。列401-405表示通过应用分类规则的训练缺陷的自动分类的结果。列406表示被预先分类(例如,通过人类操作员)的每个类中的缺陷的实际数量。行415表示由分类器103分类(正确地或错误地)到由相应的列呈现的每个类中的缺陷的总数。
如通过非限制性示例所示,在多数类中,类a被分配给组doi,类b被分配给组kdoi,并且类c被分配给组“假”。另外,少数类d被分配给组“新类”。
作为具有低阈值的初始分离,分类器没有将缺陷分类为cnd或unk。如图所示,在预先分类为类a的60个缺陷中,52个缺陷被分类器103正确地分类,而类b的4个缺陷被错误地分类到类a,类c的3个缺陷被错误地分类到类a,类d的11个缺陷被错误地分类到类a。同样,在预先分类到类b的44个缺陷中,38个缺陷被分类器103正确地分类,而类a的4个缺陷被错误地分类到b类,还有类c的6个缺陷和类d的12个缺陷;在预先分类到类c的119个缺陷中,110个缺陷被分类器103正确地分类,而类a的4个缺陷被错误地分类到c类,类b的2个缺陷被错误地分类到c类,并且类d的4个缺陷被错误地分类到类c。
每个多数类可以由品质测量,诸如纯度来表征,其指示了分类器关于类的决定的正确性。纯度可以被计算为正确地分类到给定类的缺陷的数量和由分类器分类到此给定类的缺陷的总数之间的比率。因此,在由图4中的行416所示的示例中,类a的纯度为52/70=74.2%;类b的纯度为38/60=63.33%,类c纯度为110/120=91.66%。
另外,每个类可以由诸如准确度的品质测量来表征,准确度被计算为正确地分类到给定类的缺陷与预先分类到给定类的缺陷(由列408示出)之间的比率。
分类器的性能可以由贡献来表征,贡献被计算为尚未被发送以用于通过另一模态(例如,已经用令人满意的类纯度来分类)来进一步分类的缺陷与分类的缺陷的总数的比率。
纯度可以通过增加置信度阈值提高,并且因此拒绝一些缺陷以作为unk缺陷或cnd缺陷。然而,虽然某个置信度阈值提高特定品质和/或性能测量,但是它可能会导致不同的性能测量劣化而作为诸如贡献。
返回参考图3,根据目前公开的主题的某些实施方式,训练还包括将拒绝缺陷的规则设定(305)为对应于优先分类组的多个的三个或更多个优先拒绝区间(bin)。拒绝区间的优先级经构造以对应于分类组的优先级。分类器103根据预定规则而选择某个缺陷的拒绝区间,所述预定规则可以针对不同的区间而不同并取决于相应的类的优先级和区间的优先级。
因此,通过将类分配给优先分类组的非限制性示例,可以将多数类和少数类中的每一个分配给kdoi、doi和假分类组中的一个。cnd缺陷可以被拒绝(按优先级顺序)到kdoicnd区间、doicnd区间和假cnd区间中。未知缺陷可以被拒绝到一个或多个unk区间中。
通过将类分配给优先分类组的另一非限制性示例,多数类中的每一个可以被分配给kdoi、doi和假分类组中的一个,而少数类可以被分配给新类组。cnd缺陷可以被拒绝到kdoicnd区间、doicnd区间和假cnd区间中。unk区间对应于新类拒绝,并且拒绝区间的优先级经构造以与分类组的优先级相对应,即,kdoicnd区间>新类unk区间>doicnd区间>假cnd区间。
me-others划分可实施以使得针对每个区间,“others”仅包括相应区间优先级的类。被错误地分类到给定kdoi类的kdoi缺陷被拒绝到kdoi拒绝区间;被错误地分类到给定doi类的doi缺陷被拒绝到doi拒绝区间;被错误地分类到给定假类的假缺陷被拒绝到假拒绝区间。关键-doi与doi\假之间的cnd进入kdoicnd区间(假\doi缺陷将不会被kdoi类拒绝)。被分类为假类的doi缺陷将被拒绝到doicnd区间;被分类为doi类的假缺陷将被拒绝到假cnd区间;少数类将被拒绝到新类unk区间。
表1概括了取决于类和拒绝区间的相对优先级的示例性拒绝规则(“me”是指在初始分离期间正确地分类的缺陷(304)):
表1
可选地,分类组中的两个或更多个类可以被构造为绑定类,并且分类器103可以经构造以在绑定类之间混淆的情况下不提供拒绝。同样地,分类器103可以经构造以实现被视为单个类的绑定类的品质要求。将注意,为这种绑定类计算的品质测量在下文中称为“选择性纯度”和“选择性提取率”。
根据当前公开的主题的某些实施方式,除了纯度之外,品质要求可以包括提取率要求(作为准确度要求的补充或替代准确度要求)。针对每个类,提取率对以下两者进行计数:i)该类的被正确地分类的缺陷,和ii)属于该类并且被拒绝到针对该类的提取率进行计数的拒绝区间的缺陷。因此,提取率的概念比准确度的概念更广泛。针对给定类的提取率进行计数的拒绝区间的选择取决于类的分类组和已经被拒绝的拒绝区间的相应的优先级。根据目前公开的主题的某些实施方式,对应于类优先级或更高的优先级的拒绝区间可以始终被技术以用于提取率。将注意,一些拒绝区间可能不是为用户审查而存在,因此可以被计数以用于贡献(例如,假cnd区间)。
在设定具有多个cnd区间和一个或多个unk区间的拒绝规则时,分类器103处理具有训练缺陷信息的数据,以针对每个多数类生成(306)类工作点,每个类工作点由对应于优先拒绝区间的可能的置信度阈值集表征。在kdoicnd区间、新类unk区间、doicnd区间和假cnd区间的以上非限制性示例中,每个类工作点由四个置信度阈值表征,每个置信度阈值对应于相应的区间。
对于每个给定多数类,分类器103进一步在针对给定类生成的类工作点中选择(307)满足(至少在优化之前)针对给定类接收且在考虑到针对其它类的品质要求的情况下计数的品质要求的有效工作点。因此,分类器103对于每个给定多数类产生多个有效类工作点。
有效类工作点的选择可以针对每个类独立地提供,并且可以针对给定类包括:
-移除不符合给定类的纯度要求的工作点;
-在考虑到其它类的情况下移除临时地不满足给定类的提取率要求的工作点,以产生对该类有效的多个工作点(在此步骤临时地满足提取率要求的工作点不一定需要满足在另一优化处理期间的总体类提取率要求);
-为每个有效工作点计算潜在类贡献(即,由相应的类提供的总贡献的一部分);
-根据计算出的类贡献对有效点进行排序,并且保存结果以供进一步处理。
将注意,可选地,可以通过直接搜索或本领域的技术人员已知的任何其它合适的优化方法来获得有效类工作点,而不是在可能的工作点中进行选择。
如参考图7更详细描述的,分类器103处理(308)多个有效类工作点(每个有效类工作点相对于相应的多数类是有效的),以获得最佳工作点,最佳工作点实现最高可能的adc贡献,同时满足所有类的每类品质要求。当类工作点由对应于拒绝区间的k个阈值(例如,如在所提供的非限制性示例中的4个阈值)表征时,最佳工作点由(k*多数类的数量)阈值表征。将注意,虽然仅针对多数类来计算优化阈值,但是可以在考虑到少数类的提取要求的情况下提供优化处理(308)。
将注意,根据目前公开的主题的某些实施方式,可取决于分类目的和/或分类器的配置而不同地计算分类器103的贡献(即,优化目标)。分类器可以经构造以使得用户能够定义(例如,经由gui108)混淆矩阵中的贡献列。通过非限制性示例,当分类结果用于统计过程控制(statisticalprocesscontrol,spc)时,为贡献计数的列可以包括已经被分类为具有令人满意的类纯度和假cnd区间的所有类。通过另一非限制性示例,当分类结果用于doi搜索时,为贡献计数的列可以包括已经被分类为具有令人满意的类纯度、doicnd区间和假cnd区间的所有类。通常,贡献可以被计算为被定义为为贡献计数的列中的缺陷的数量除以分类的缺陷的总数。可选地,贡献可以被定义为过滤率、假过滤率或任何其它性能测量。
在获得最佳工作点时,分类器生成(309)分类规则,所述分类规则包括用于初始分离的分类引擎和用于每个拒绝区间和多数类的多个置信度阈值,置信度阈值对应于最佳工作点。可以根据用户要求来进一步调整分类规则中的阈值(例如,以便通过降低品质要求来提高性能)。将注意,在一些情况下,将所生成的分类规则应用于要分类的缺陷可能造成拒绝区间之间的冲突(即,受置信度阈值的影响,给定缺陷可能被拒绝到若干区间)。对于这种情况,分类器103可以经构造以将缺陷拒绝到在可能区间中的具有最高的优先级的区间。
将注意,当前公开的主题的教导不受如非限制性示例中所示的分类组和优先拒绝区间的约束,并且同样地适用于其它类型、数量和/或优先级的分类组和对应的拒绝区间。
参见图5a-5d中,其示意性地示出了根据当前公开的主题的某些实施方式的拒绝过程的非限制性示例。图5a示出了在初始分离之后获得的混淆矩阵。图5b示出了在分类器103已经拒绝缺陷以便于满足针对kdoi类定义的每类纯度/提取率要求之后的混淆矩阵。图5c示出了在分类器103已进一步拒绝缺陷以便于满足新类提取要求之后的混淆矩阵。图5d示出了在分类器103已进一步拒绝缺陷以便于满足针对doi和假分类组中的类定义的每类要求之后的混淆矩阵。将注意,在所示的示例中,类e与类f绑定,并且纯度和提取率根据正确地分类到这些类中的任何类的缺陷而被计算以作为选定的纯度和选定的提取率。在所有示出的拒绝时,缺陷的分布对应于所有每类品质要求,并且相应的置信度阈值对应于有效类工作点。将注意,所示的获得每类工作点可以与两个或更多个类并行地提供。
图6示出了示例性混淆矩阵,其呈现了图4中所示的缺陷的优化分布的结果。如图所示,kdoi类满足80%的示例性预定纯度要求和100%的示例性预定提取率要求,doi类满足93%的示例性预定纯度要求和91%的示例性预定提取率要求为;新类提取满足63%的示例性预定要求。将注意,在所示的示例中,与kdoi类或在kdoi类内混淆的缺陷已经被拒绝到kdoicnd区间;在doi类内混淆的缺陷和被分类为假的doi缺陷被拒绝到doicnd区间,而在doi类和假类之间混淆的缺陷被拒绝到假cnd区间,并且在doi类与少数类之间混淆的缺陷已经被拒绝到新类unk区间。
在所示的示例中,类b(分配给kdoi分类组)的纯度和提取率可以如下计算:
类b纯度=32(正确地自动分类到类b的缺陷的数量)/40(自动分类到类b的缺陷的总数)=80%。
类b提取率=(32(超过纯度阈值的类b缺陷的数量)+12(类bkdoicnd区间中的缺陷的数量))/44(手动地分类到类b的缺陷的数量)=100%。
在所示的示例中,类a(分配给doi分类组)的纯度和提取率可以如下计算:
类a纯度=43(正确地自动分类到类a的缺陷的数量)/43(自动分类到类a的缺陷的总数)=93%。
类a提取率=(43(超过纯度阈值的类a缺陷的数量)+2+4+6(类akdoicnd区间+doicnd区间+未知cnd区间中的缺陷的数量)/60(手动地分类到类b的缺陷的数量)=91%。
如上指出,贡献计算取决于分类目的和/或用户要求。通过非限制性示例,用户可能有兴趣地手动地审查所有kdoi缺陷,而不管自动分类结果如何。在这种情况下,贡献列是列401、402、405-2和405-3,并且贡献等于(46+104+14+5)/250=67%。通过另一非限制性示例,贡献列可以由用户定义为高于纯度阈值的kdoi类和doi类、高于选择性纯度阈值的假类、doicnd区间(除非需要进行审查)、假cnd区间和unk区间。在所示的示例中,这种定义对应于列401、402、403、405-2、405-3和404-1,并且贡献等于(46+40+104+14+5+15)/250=90%。
参考图7,其示出了根据目前公开的主题的某些实施方式的示例性处理(308)工作点的概括流程图。
在针对每一训练缺陷获得(701):预先分类的结果、自动分类的结果和关于每个优先拒绝区间的置信度水平时,分类器103计算(702)每个多数类的有效类工作点。
在有效类工作点中,分类器103选择具有最大类贡献的有效工作点,并且在考虑到所有类的情况下,校验(703)此工作点是否满足提取率要求。如果确实如此,那么这一点是全局最大化点,所述全局最大化点实现最高可能的adc贡献而同时满足每类品质要求。
如果在考虑到所有类的情况下工作点不满足提取率要求,那么分类器103估计(704)指示能够传递缺失的提取的有效类工作点的数量的间隙。如果间隙低于性能阈值(performancethreshold,pths),那么分类器103提供(705)遍历有效类工作点的所有组合的穷举计算以找到具有最佳贡献的工作点。这样的工作点对应于最佳工作点,所述最佳工作点实现最高可能的adc贡献,同时满足所有类的每类品质要求。如果间隙超过性能阈值,那么分类器103使用(706)直接(贪婪)算法提供计算,可选地接着进行黑盒优化(例如,粒子群优化)。注意,性能阈值取决于pmc104的处理能力。
作为非限制性示例,可如下提供直接计算:
在针对每个多数类获得有效类工作点、部分提取和相应的类贡献时,分类器103按相应优先级的顺序提供针对每个分类组的优化。针对给定分类组中的每个多数类,分类器103计算有效性,所述有效性被定义为提取增益与贡献损失的比率,贪婪地选择给定分类组内的用于缺陷提取的最佳多数类,并且进行重复,直到在考虑到给定组中的所有类的情况下满足提取要求为止。在完成针对每个分类组的这种循环时,分类器103获得贪婪优化的工作点。
本领域的技术人员将容易地理解,目前公开的主题的教导不受图7中所示的处理的约束。可以实现其它适当的算法和其组合,以便获得实现最高可能的adc贡献而同时满足每类品质要求的最佳工作点。
将理解,本发明的应用不限于本文包含的或附图示出的描述中阐述的细节。本发明能够具有其它实施方式并且能够以各种方式来实践或实施。因此,将理解,本文使用的措辞和术语是出于描述的目的,并且并不应被视为是限制性的。因此,本领域的技术人员将了解,本公开所基于的概念可容易地用作设计用于实现当前公开的主题的若干目的的其它结构、方法和系统的基础。
还将理解,根据本发明的系统可以至少部分地在适当编程的计算机上实现。同样地,本发明预期了一种计算机程序,计算机程序可由计算机读取以执行本发明的方法。本发明还预期一种非暂时性计算机可读存储器,其有形地体现可由计算机执行的用于执行本发明的方法的指令程序。
本领域的技术人员将容易地理解,在不脱离本发明的在随附权利要求书中定义的保护范围的情况下,可以对如上所述的本发明的实施方式应用各种修改和变化。
- 还没有人留言评论。精彩留言会获得点赞!