一种无感考勤系统及方法与流程
本发明涉及人脸识别领域,尤其是一种无感考勤系统及方法。
背景技术:
目前已实现考勤系统中,指纹识别因容易被复制而诟病;基于人脸识别的考勤系统,现有技术要求被考勤人员主动配合,并按照不同角度录入模板,在考勤时,要求人员站在指定位置,并在角度范围内配合考勤机来完成考勤。这种技术第一方面需要人员主动配合才能完成考勤,智能化程度低。第二方面,除了人员配合的考勤外,不能完整地呈现人员一整天的考勤情况,比如,有的人员,考勤完成后的外出。又或者不明身份人员擅自闯入,现有的考勤系统并不能很好的解决这些问题。
技术实现要素:
针对现有技术中的缺陷,本发明提供一种无感考勤系统及方法,旨在克服现有技术的不足。
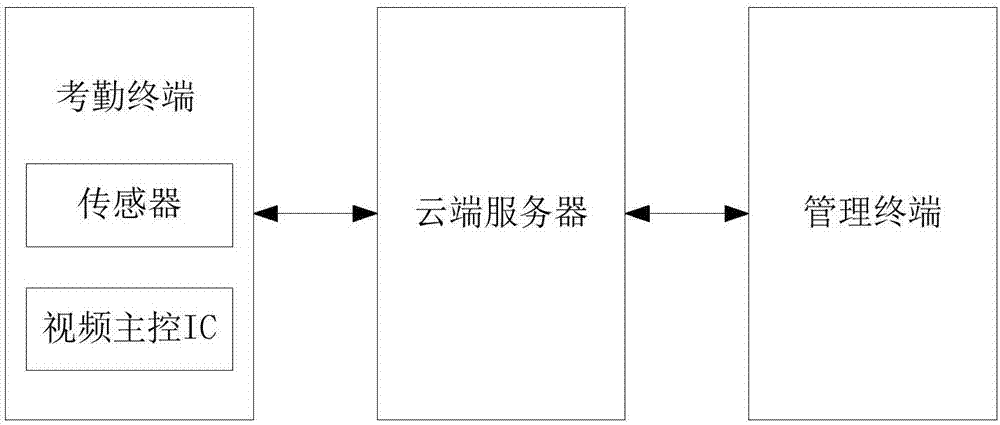
为了实现上述目的,第一方面,本发明提供的一种无感考勤系统,包括考勤终端、云端服务器和管理终端,所述云端服务器分别与所述考勤终端和所述管理终端通信连接;所述云端服务器接收所述考勤终端提取的被考勤者的人脸图像信息;所述云端服务器根据所述人脸图像信息进行人脸识别并生成出入考勤信息;所述云端服务器将所述出入考勤信息反馈给所述管理终端。
第二方面,本发明提供一种无感考勤方法,所述无感考勤方法适用于本发明的第一方面中所述的无感考勤系统,所述无感考勤系统包括考勤终端、云端服务器和管理终端,所述云端服务器分别与所述考勤终端和所述管理终端通信连接,所述无感考勤方法包括如下步骤:所述云端服务器接收所述考勤终端提取的被考勤者的人脸图像信息;所述云端服务器根据所述人脸图像信息进行人脸识别并生成出入考勤信息;所述云端服务器将所述出入考勤信息反馈给所述管理终端。
本发明的有益效果是:本发明提出的一种无感考勤系统及方法,被考勤者不需要再进行配合式考勤,仅仅正常行走通过架设有快速视频采集的考勤终端位置时,即可实现无感实现考勤,云端服务器会根据考勤终端抓拍的视频数据实现人脸识别和比对,并形成出入考勤信息。
附图说明
图1为本发明实施例无感考勤系统的示意图;
图2为本发明实施例人脸形状的示意图;
图3为本发明实施例无感考勤方法的流程图。
具体实施方式
下面将详细描述本发明的具体实施例,应当注意,这里描述的实施例只用于举例说明,并不用于限制本发明。在以下描述中,为了提供对本发明的透彻理解,阐述了大量特定细节。然而,对于本领域普通技术人员显而易见的是:不必采用这些特定细节来实行本发明。在其他实例中,为了避免混淆本发明,未具体描述公知的电路,软件或方法。
在整个说明书中,对“一个实施例”、“实施例”、“一个示例”或“示例”的提及意味着:结合该实施例或示例描述的特定特征、结构或特性被包含在本发明至少一个实施例中。因此,在整个说明书的各个地方出现的短语“在一个实施例中”、“在实施例中”、“一个示例”或“示例”不一定都指同一实施例或示例。此外,可以以任何适当的组合和、或子组合将特定的特征、结构或特性组合在一个或多个实施例或示例中。此外,本领域普通技术人员应当理解,在此提供的示图都是为了说明的目的,并且示图不一定是按比例绘制的。
如图1所示,本发明的第一实施例所示出的无感考勤系统包括考勤终端、云端服务器和管理终端,所述云端服务器分别与所述考勤终端和所述管理终端通信连接;所述云端服务器接收所述考勤终端提取的被考勤者的人脸图像信息;所述云端服务器根据所述人脸图像信息进行人脸识别并生成出入考勤信息;所述云端服务器将所述出入考勤信息反馈给所述管理终端。
其中,所述考勤终端包括壳体以及集成在所述壳体内的globalshutter传感器和视频主控ic,所述globalshutter传感器的信号输出端与所述视频主控ic的信号输入端相连;所述云端服务器包括服务器或者服务器集群;所述管理终端包括电脑、手机以及其他移动或固定终端。
所述云端服务器接收所述考勤终端抓取的被考勤者的人脸图像信息主要为所述云端服务器接收所述考勤终端根据实时画面提取的被考勤者的人脸图像信息,所述实时画面是由所述考勤终端以每秒240帧的速度对被考勤者进行抓取的实时画面;
本实施例中,考勤终端根据实时画面提取的被考勤者的人脸图像信息具体包括:
获取待检测图像,待检测图像指的是需要检测人脸形状的图像,其中,人脸形状可包括面部轮廓形状和五宫的位置及形状等。人脸形状可由在人脸标记的各个特征点所在的位置进行表示,如图2所示,图2为一个实施例中用特征点组成的人脸形状示意图,图2中各个带有标号的点即为特征点,根据各个特征点的位置即可组成人脸形状,其中,标号1至17的特征点表示面部轮廓形状,标号18至27的特征点表示眉毛位置及形状,标号28至37的特征点表示鼻子位置及形状,标号38至47的特征点表示眼睛位置及形状,标号48至67的特征点表示嘴巴位置及形状。
在一个实施例中,所述视频主控ic获取待检测图像若该待检测图像为彩色图像,可将彩色图像按照对应的转化矩阵转化为灰度图像,其中,灰度图像指的是每个像素只有一个采样颜色的图像。视频主控ic可先根据灰度图像的图像特征粗略检测待检测图像中是否包含人脸,若包含,可从灰度图像中提取检测到的人脸,并将提取的人脸放入预设的单位矩形区域内。若待检测图像中包含多个人脸,可分别将人脸提取放入预设的单位矩形区域内,再逐一进行检测人脸形状。
获取预先构建的概率回归模型中本次回归树的初始形状。概率回归模型包含级联的随机森林,概率回归模型中可包括多级随机森林,每级随机森林下可包括多棵回归树,每级随机森林及每级随机森林下的每棵回归树具备级联关系,上一级随机森林输出的估计形状是相邻的下一级随机森林的初始形状,同级随机森林中上一棵回归树输出的估计形状是相邻的下一棵回归树的初始形状。回归树使用了二叉树将预测空间划分为若干子集,回归树中的每个叶子结点对应划分的不同区域,每个进入回归树的图像最终均会被分配到唯一的叶子结点上。
视频主控ic可获取预先生成的模型文件,并对模型文件进行解析,根据模型文件中包含的信息重新构建级联的概率回归模型,并根据该概率回归模型检测待检测人脸图像中的人脸形状,其中,模型文件包含的信息可包括随机森林的级数、每级随机森林的回归树数量、每棵回归树的深度、回归树中每个结点的结点信息等。
针对于概率回归模型中的每一级随机森林,每级随机森林下的每棵回归树进行迭代计算,最后得到检测到的人脸形状。视频主控ic进行迭代计算时,需获取概率回归模型中本次回归树的初始形状,其中,本次回归树指的是正在进行估计形状计算的回归树。进一步地,视频主控ic解析模型文件,还可获取在根据样本图像集构建概率回归模型时,该样本图像集中各个样本图像的平均形状,并将样本图像集中各个样本图像的平均形状作为概率回归模型第一级随机森林的第一棵回归树的初始形状。
从待检测图像提取图像特征,并根据图像特征分别计算本次回归树各个叶子结点的概率。视频主控ic可根据本次回归树中各个结点包含的对应的结点信息,从待检测图像中提取图像特征,其中,结点信息用于表示对应结点的划分规则。进-步地,结点信息可包括划分像素对的坐标信息,视频主控ic可根据划分像素对的坐标信息,从放有提取的人脸的预设单位矩形区域内对应的位置处提取图像特征。视频主控ic可根据从待检测图像提取的与本次回归树各个结点对应的图像特征,分别计算各个叶子结点的概率,其中,叶子结点指的是度为0的结点,叶子结点没有子结点,也可称为终端结点。
从本次回归树中提取各个叶子结点的误差。视频主控ic可从模型文件中读取本次回归树中各个叶子结点的误差,其中,各个叶子结点的误差指的是对应叶子结点计算得到的估计形状与待检测图像的真实形状之间的差异值,各个叶子结点的误差可为建立概率回归模型时根据样本图像集中大量的样本图像计算得到。
根据各个叶子结点的概率及误差确定本次回归树的形状误差。视频主控ic可根据本次回归树各个叶子结点的概率及对应的误差进行加权和计算,分别计算各个叶子结点的概率及对应的误差的乘积,并将计算得到的乘积进行累加,得到本次回归树的形状误差。本次回归树的形状误差即为本次回归树计算的估计形状与待检测图像的真实形状之间的差异值。
根据初始形状及形状误差计算得到本次回归树的估计形状。视频主控ic可将本次回归树的初始形状与形状误差进行累加,即可得到本次回归树的估计形状,假设本次回归树的估计形状为sk,初始形状为sk-1,计算得到的形状误差为δsk,则δsk=sk-1+δsk,其中,sk-1可为本次回归树相邻的上一棵回归树计算得到的估计形状。
将估计形状作为相邻的下一回归树的初始形状进行迭代计算,直至概率回归模型中的最后一棵回归树,得到最后一棵回归树的估计形状,作为检测到的人脸形状。计算得到本次回归树的估计形状后,可将本次回归树的估计形状作为相邻的下一回归树的初始形状,重复上述步骤,得到该下一回归树的估计形状,再将该下一回归树的估计形状作为相邻的再下一棵回归树的初始形状,以此类推,在概率回归模型中进行迭代计算,直至概率回归模型的最后一级随机森林的最后一棵回归树,计算得到最后一级随机森林的最后一棵回归树的估计形状,即为检测到的人脸形状。概率回归模型中的每级随机森林,每级随机森林下的每棵回归树,均是对待检测图像的真实形状的逼近。在概率模型中按照上述方式进行迭代计算,可逐步从最初样本图像集中各个样本图像的平均形状逐步逼近待检测图像的真实形状,从而实现提取被考勤者的人脸图像信息。
本实施例中,所述云端服务器根据所述人脸图像信息进行人脸识别具体包括:
云端服务器根据所述人脸图像信息进行特征提取得到特征;云端服务器根据所述人脸图像信息将人脸图像划分为多个子领域;优选的,可将图像划分为3*3个子领域;需要进行说明的是,子领域划分的个数可根据实际情况进行选择,在另外的一个或一些实施例中,也可将所述人脸图像划分为其他数目的子领域。云端服务器将所述子领域与k个算子卷积,得到相应k个方向上的边缘响应;进一步地,所述算子为8个kirsch算子,通过与8个kirsch算子卷积,即可得到相应8个方向的边缘响应即mi=i*mi;其中i=0,1,2,3,4,5,6,7。将所述边缘响应按照预设顺序作差并取其绝对值得到k个方向上的k个人脸灰度响应差值;具体的,将近临边缘响应mi之间按照一定顺序作差取绝对值,得到8个人脸灰度响应差值即:
云端服务器将所述人脸图像划分为m*n个子块;进一步地,所述n为13,所述m为13,需要进行说明的是,m和n的取值可以根据实际情况进行调整,在其他一个或一些实施例中也可以采用其的值,在此就不一一进行列举;其中,每一个子块可表示为i*(x,y);其中x∈[1,13],y∈[1,13]。
云端服务器计算每个子块中各个像素点的局部信息熵;由于在人脸图像中各个部位所代表的特征信息是不同的,因此需要计算出所述人脸图像的各个子块中各个像素点的局部信息熵即:
云端服务器根据所述局部信息熵的熵值得到每个所述子块的贡献度,并绘制统计直方图;所述每个所述子块的贡献度的计算方式具体为:
云端服务器将所有子块的统计直方图串接融合成一个直方图;进一步,在进行直方图串接融合时具体为:
本实施例中,云端服务器生成出入考勤信息具体包括:
当人脸识别成功,所述云端服务器即可生成出入考勤信息,所述出入考勤信息包括但不限于出入考勤人员的姓名、岗位、工号、所属部门、出入时间。当人脸识别失败,可根据在所述实时画面重新提取被考勤者的人脸图像信息重重复人脸识别步骤,若重复识别失败的次数达到预设值,则认定该人员并非为本公司员工,所述云端服务器可生成出入考勤信息,所述出入考勤信息包括出入人员的照片、出入的时间等信息。
本实施例中,云端服务器将所述出入考勤信息反馈给所述管理终端具体包括:
当服务器进行人脸识别输入的人员为本公司的人员,可将所述出入考勤信息发送给所述管理终端,通过上述方式可以对考勤考人员进行精确考勤,当中途有人员缺勤,也可以一目了然。此外,针对于并非为本公司员工,所述云端服务器在将出入人员的出入考勤信息反馈给所述管理终端的同时还可以推送疑似非法侵入的提醒,通过上述方式可以有效杜绝不明身份人员擅自闯入。
本发明的第二实施例所示出的无感考勤方法,所述无感考勤方法适用于本发明的第一实施中所述的无感考勤系统,所述无感考勤系统包括考勤终端、云端服务器和管理终端,所述云端服务器分别与所述考勤终端和所述管理终端通信连接,所述无感考勤方法包括如下步骤:
s1,云端服务器接收所述考勤终端提取的被考勤者的人脸图像信息。
其中,所述考勤终端包括壳体以及集成在所述壳体内的globalshutter传感器和视频主控ic,所述globalshutter传感器的信号输出端与所述视频主控ic的信号输入端相连;所述云端服务器包括服务器或者服务器集群;所述管理终端包括电脑、手机以及其他移动或固定终端。
所述云端服务器接收所述考勤终端抓取的被考勤者的人脸图像信息主要为所述云端服务器接收所述考勤终端根据实时画面提取的被考勤者的人脸图像信息,所述实时画面是由所述考勤终端以每秒240帧的速度对被考勤者进行抓取的实时画面;
本实施例中,考勤终端根据实时画面提取的被考勤者的人脸图像信息具体包括:
获取待检测图像,待检测图像指的是需要检测人脸形状的图像,其中,人脸形状可包括面部轮廓形状和五宫的位置及形状等。人脸形状可由在人脸标记的各个特征点所在的位置进行表示,如图2所示,图2为一个实施例中用特征点组成的人脸形状示意图,图2中各个带有标号的点即为特征点,根据各个特征点的位置即可组成人脸形状,其中,标号1至17的特征点表示面部轮廓形状,标号18至27的特征点表示眉毛位置及形状,标号28至37的特征点表示鼻子位置及形状,标号38至47的特征点表示眼睛位置及形状,标号48至67的特征点表示嘴巴位置及形状。
在一个实施例中,所述视频主控ic获取待检测图像若该待检测图像为彩色图像,可将彩色图像按照对应的转化矩阵转化为灰度图像,其中,灰度图像指的是每个像素只有一个采样颜色的图像。视频主控ic可先根据灰度图像的图像特征粗略检测待检测图像中是否包含人脸,若包含,可从灰度图像中提取检测到的人脸,并将提取的人脸放入预设的单位矩形区域内。若待检测图像中包含多个人脸,可分别将人脸提取放入预设的单位矩形区域内,再逐一进行检测人脸形状。
获取预先构建的概率回归模型中本次回归树的初始形状。概率回归模型包含级联的随机森林,概率回归模型中可包括多级随机森林,每级随机森林下可包括多棵回归树,每级随机森林及每级随机森林下的每棵回归树具备级联关系,上一级随机森林输出的估计形状是相邻的下一级随机森林的初始形状,同级随机森林中上一棵回归树输出的估计形状是相邻的下一棵回归树的初始形状。回归树使用了二叉树将预测空间划分为若干子集,回归树中的每个叶子结点对应划分的不同区域,每个进入回归树的图像最终均会被分配到唯一的叶子结点上。
视频主控ic可获取预先生成的模型文件,并对模型文件进行解析,根据模型文件中包含的信息重新构建级联的概率回归模型,并根据该概率回归模型检测待检测人脸图像中的人脸形状,其中,模型文件包含的信息可包括随机森林的级数、每级随机森林的回归树数量、每棵回归树的深度、回归树中每个结点的结点信息等。
针对于概率回归模型中的每一级随机森林,每级随机森林下的每棵回归树进行迭代计算,最后得到检测到的人脸形状。视频主控ic进行迭代计算时,需获取概率回归模型中本次回归树的初始形状,其中,本次回归树指的是正在进行估计形状计算的回归树。进一步地,视频主控ic解析模型文件,还可获取在根据样本图像集构建概率回归模型时,该样本图像集中各个样本图像的平均形状,并将样本图像集中各个样本图像的平均形状作为概率回归模型第一级随机森林的第一棵回归树的初始形状。
从待检测图像提取图像特征,并根据图像特征分别计算本次回归树各个叶子结点的概率。视频主控ic可根据本次回归树中各个结点包含的对应的结点信息,从待检测图像中提取图像特征,其中,结点信息用于表示对应结点的划分规则。进-步地,结点信息可包括划分像素对的坐标信息,视频主控ic可根据划分像素对的坐标信息,从放有提取的人脸的预设单位矩形区域内对应的位置处提取图像特征。视频主控ic可根据从待检测图像提取的与本次回归树各个结点对应的图像特征,分别计算各个叶子结点的概率,其中,叶子结点指的是度为0的结点,叶子结点没有子结点,也可称为终端结点。
从本次回归树中提取各个叶子结点的误差。视频主控ic可从模型文件中读取本次回归树中各个叶子结点的误差,其中,各个叶子结点的误差指的是对应叶子结点计算得到的估计形状与待检测图像的真实形状之间的差异值,各个叶子结点的误差可为建立概率回归模型时根据样本图像集中大量的样本图像计算得到。
根据各个叶子结点的概率及误差确定本次回归树的形状误差。视频主控ic可根据本次回归树各个叶子结点的概率及对应的误差进行加权和计算,分别计算各个叶子结点的概率及对应的误差的乘积,并将计算得到的乘积进行累加,得到本次回归树的形状误差。本次回归树的形状误差即为本次回归树计算的估计形状与待检测图像的真实形状之间的差异值。
根据初始形状及形状误差计算得到本次回归树的估计形状。视频主控ic可将本次回归树的初始形状与形状误差进行累加,即可得到本次回归树的估计形状,假设本次回归树的估计形状为sk,初始形状为sk-1,计算得到的形状误差为δsk,则δsk=sk-1+δsk,其中,sk-1可为本次回归树相邻的上一棵回归树计算得到的估计形状。
将估计形状作为相邻的下一回归树的初始形状进行迭代计算,直至概率回归模型中的最后一棵回归树,得到最后一棵回归树的估计形状,作为检测到的人脸形状。计算得到本次回归树的估计形状后,可将本次回归树的估计形状作为相邻的下一回归树的初始形状,重复上述步骤,得到该下一回归树的估计形状,再将该下一回归树的估计形状作为相邻的再下一棵回归树的初始形状,以此类推,在概率回归模型中进行迭代计算,直至概率回归模型的最后一级随机森林的最后一棵回归树,计算得到最后一级随机森林的最后一棵回归树的估计形状,即为检测到的人脸形状。概率回归模型中的每级随机森林,每级随机森林下的每棵回归树,均是对待检测图像的真实形状的逼近。在概率模型中按照上述方式进行迭代计算,可逐步从最初样本图像集中各个样本图像的平均形状逐步逼近待检测图像的真实形状,从而实现提取被考勤者的人脸图像信息。
s2,云端服务器根据所述人脸图像信息进行人脸识别并生成出入考勤信息。
云端服务器根据所述人脸图像信息进行特征提取得到特征;云端服务器根据所述人脸图像信息将人脸图像划分为多个子领域;优选的,可将图像划分为3*3个子领域;需要进行说明的是,子领域划分的个数可根据实际情况进行选择,在另外的一个或一些实施例中,也可将所述人脸图像划分为其他数目的子领域。云端服务器将所述子领域与k个算子卷积,得到相应k个方向上的边缘响应;进一步地,所述算子为8个kirsch算子,通过与8个kirsch算子卷积,即可得到相应8个方向的边缘响应即mi=i*mi;其中i=0,1,2,3,4,5,6,7。将所述边缘响应按照预设顺序作差并取其绝对值得到k个方向上的k个人脸灰度响应差值;具体的,将近临边缘响应mi之间按照一定顺序作差取绝对值,得到8个人脸灰度响应差值即:
云端服务器将所述人脸图像划分为m*n个子块;进一步地,所述n为13,所述m为13,需要进行说明的是,m和n的取值可以根据实际情况进行调整,在其他一个或一些实施例中也可以采用其的值,在此就不一一进行列举;其中,每一个子块可表示为i*(x,y);其中x∈[1,13],y∈[1,13]。
云端服务器计算每个子块中各个像素点的局部信息熵;由于在人脸图像中各个部位所代表的特征信息是不同的,因此需要计算出所述人脸图像的各个子块中各个像素点的局部信息熵即:
云端服务器根据所述局部信息熵的熵值得到每个所述子块的贡献度,并绘制统计直方图;所述每个所述子块的贡献度的计算方式具体为:
云端服务器将所有子块的统计直方图串接融合成一个直方图;进一步,在进行直方图串接融合时具体为:
云端服务器生成出入考勤信息具体包括:
当人脸识别成功,所述云端服务器即可生成出入考勤信息,所述出入考勤信息包括但不限于出入考勤人员的姓名、岗位、工号、所属部门、出入时间。当人脸识别失败,可根据在所述实时画面重新提取被考勤者的人脸图像信息重重复人脸识别步骤,若重复识别失败的次数达到预设值,则认定该人员并非为本公司员工,所述云端服务器可生成出入考勤信息,所述出入考勤信息包括出入人员的照片、出入的时间等信息。
s3,云端服务器将所述出入考勤信息反馈给所述管理终端。
当服务器进行人脸识别输入的人员为本公司的人员,可将所述出入考勤信息发送给所述管理终端,通过上述方式可以对考勤考人员进行精确考勤,当中途有人员缺勤,也可以一目了然。此外,针对于并非为本公司员工,所述云端服务器在将出入人员的出入考勤信息反馈给所述管理终端的同时还可以推送疑似非法侵入的提醒,通过上述方式可以有效杜绝不明身份人员擅自闯入。
最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围,其均应涵盖在本发明的权利要求和说明书的范围当中。
- 还没有人留言评论。精彩留言会获得点赞!