一种基于手机前视摄像头的人脸活体检测方法与流程
本发明涉及人脸识别领域,具体涉及一种基于手机前视摄像头的人脸活体检测方法。
背景技术:
随着人工智能潮流的兴起,人脸识别技术在实际生活中的应用越来越广泛,已经成为个人身份鉴别的重要手段。但伴随着人脸识别的便捷性与友好性,人脸识别系统也存在着用户身份被冒充的风险,不法分子利用包含面部信息的打印纸张、面具,或是通过播放电子照片、视频等手段,可以达到伪造他人身份的目的。因此,基于人脸的活体检测技术越来越重要,成为人脸识别系统的必不可少的模块。现有的人脸活体检测技术按照活体检测流程可分为两类:
(1)配合式活体检测:通过要求用户完成眨眼、张嘴、转头等简单的动作,或者读一段随机数字等方式,达到区分真实人脸和打印照片、视频回放的目的。近年来,随着人脸合成技术的发展,通过一张照片合成任意动作的视频变得相对容易,对此种检测方式带来巨大的威胁。此外,配合式的活体检测也有用户体验不佳,验证时间长等问题。
(2)非配合式活体检测:通过摄像头实时捕捉用户面部图像,并利用机器学习等技术,分析图像的纹理、人脸背景等信息,区分真实的人脸和纸张、面具、视频播放的人脸。此种活体检测方式相对于(1)的用户体验较好,但容易受到使用场景、摄像头硬件性能的影响,在场景光照不理想、摄像头分辨率较低的情况下,真人体验往往不佳;并且随着电子屏幕显示技术的发展,高清播放视频愈发接近真实的人脸的纹理特征,对此类活体检测技术也提出了巨大挑战。
(3)基于结构光的活体检测方法:该方法通过结构光设备发射特定的红外光图案并重建深度图像,在不需用户动作配合的情况才采集用户面部区域的近红外图像、深度图像和可见光图像,通过三个维度的特征提取、融合,和比对,进行活体检测,具有用户体验好,安全性高,场景鲁棒性强等优点。但结构光设备成本较高,体积较大,在目前的手机设备上无法使用。
随着手机支付和各种手机端身份验证功能的需求增加,手机端人脸识别和活体检测算法的使用频率不亚于其他类型的应用。手机端对人脸活体检测系统的要求是:不改变现有硬件,程序空间小,运行效率高,简单易用,不易破解。
技术实现要素:
本发明针对现有技术的不足,提出一种基于手机前视摄像头的人脸活体检测方法,具体技术方案如下:一种基于手机前视摄像头的人脸活体检测方法,其特征在于:
采用以下步骤,
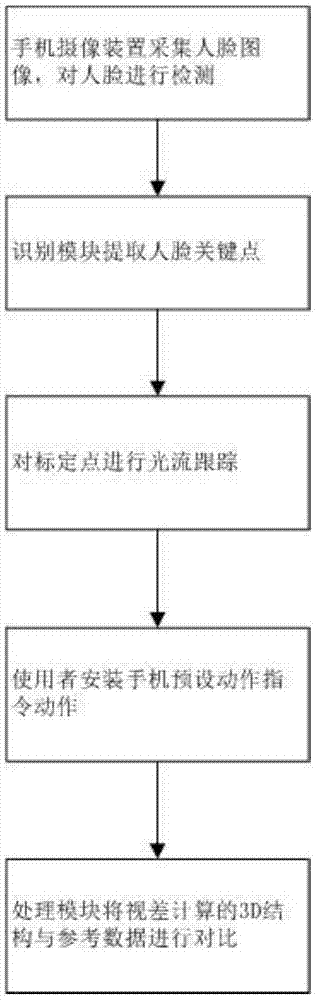
步骤1:通过手机摄像装置采集人脸图像,对人脸进行检测;
步骤2:识别模块从采集的人脸图像中提取人脸关键点;
在人脸关键点中选取符合角点特征的关键点作为标定点,具体为选定六个关键点,分别为四个眼角和两个嘴角;
步骤3:对标定点进行光流跟踪,对光流跟踪失败的标定点通过ransac算法来过滤;
步骤4:在手机上设置有预设动作指令,使用者按照手机上的预设动作指令平移手机,同时保持头部不动,在手机初始化时,手机数据库中保存有使用者预先录入的3d结构参数作为参考数据;
处理模块在手机平移过程中,截取很n帧位于不同视角的人脸照片,n>1,提取n帧图片中每张图片的关键点,利用structurefrommotion算法,利用视差计算出人脸图像的3d结构;
步骤5:处理模块将通过视差计算出来的3d结构与参考数据进行对比,如果,数据吻合,则判定检测为活体,否则,判定为伪造数据。
进一步地:所述步骤3中关键点的整体ransac约束跟踪包括如下方式:
假设t0时刻有关键点{p1,p2,...pn},t1时刻通过光流跟踪到的位置对应为{q1,q2,...qn},设定有参考时间t,则在t1-to<t时;
可以用一个仿射变换来描述从p到q的变换关系:wi*(f*pi+b=qi),f(2*2),b(2*1),i=1,2,...n,wi是第i个关键点的权值,初始化为1;
共有6个未知数,只要关键点的个数n大于6,此方程组就可以用最小二乘法求得均方误差最小解,进而再计算它们的预测值{g1,g2,...gn};
如果1到n个关键点中有少量光流跟踪失败,假设是第k个,则qk与gk差值比较大,于是调小k的权值wk,然后再重复上面的过程,直至点k的权重小于设定值。
进一步地:对前视摄像头内参标定,确定使用者脸部关键点3d结构确定,具体为,
设置有距离阈值,如果使用者为初次录入人脸信息,则使用者用手机对着脸部做多方位多角度的移动,structurefrommotion算法提取每一帧的关键点坐标,任意两帧之间同一关键点之间的距离为关键点距离,任意两帧所有关键点距离之和为整体距离;
设置有关键帧集合,如果选择的任意一帧与关键帧集合的每个元素之间的整体距离均大于阈值,则将该帧添加到关键帧集合中,structurefrommotion算法利用关键帧集合对关键点3d结构进行恢复后,完成对关键点3d结构规整;
关键点3d结构规整具体为,
structurefrommotion算法恢复的3d结构为无量纲,这里需要将它的尺寸固定,调整量纲参数λ,左眼的左眼角和右眼的右眼角之间的距离为1分米;
以眼的左眼角和右眼的右眼角连线中心位置为原点,从左眼角到右眼角的方向为x轴方向,两嘴角中心点到原点的方向为y轴方向,再按右手坐标系原则确定z轴方向,构造rt变换将关键点3d位置信息对齐到所述右手的坐标系中,然后存储到数据库中,得到规整化后的关键点3d结构。
本发明的有益效果为:本发明基于结构光设备对人脸进行无感知的活体检测,检测速度快且准确率高。能够应用于各种亮暗环境以及对实时性要求较高的场景。相较于其他的活体检测技术,本发明提升了针对各类攻击道具的防守能力,安全性更高,特别是对于高清打印纸张、面具或者高清屏幕照片的检出率极高,大大降低了人脸识别系统的风险。
附图说明
图1为本发明的工作流程图。
具体实施方式
下面结合附图对本发明的较佳实施例进行详细阐述,以使本发明的优点和特征能更易于被本领域技术人员理解,从而对本发明的保护范围做出更为清楚明确的界定。
如图1所示:一种基于手机前视摄像头的人脸活体检测方法,其特征在于:
采用以下步骤,
步骤1:通过手机摄像装置采集人脸图像,对人脸进行检测;
步骤2:识别模块从采集的人脸图像中提取人脸关键点;
在人脸关键点中选取符合角点特征的关键点作为标定点,具体为选定六个关键点,分别为四个眼角和两个嘴角;
步骤3:对标定点进行光流跟踪,对光流跟踪失败的标定点通过ransac算法来过滤;
步骤4:在手机上设置有预设动作指令,使用者按照手机上的预设动作指令平移手机,同时保持头部不动,在手机初始化时,手机数据库中保存有使用者预先录入的3d结构参数作为参考数据;
处理模块在手机平移过程中,截取很n帧位于不同视角的人脸照片,n>1,提取n帧图片中每张图片的关键点,利用structurefrommotion算法,利用视差计算出人脸图像的3d结构;
步骤5:处理模块将通过视差计算出来的3d结构与参考数据进行对比,如果,数据吻合,则判定检测为活体,否则,判定为伪造数据。
人脸关键点中有些点的位置比较精确,如眼角,嘴角,眉尖,鼻孔。有些点的位置不太精确,如鼻梁上的某些点没有明显的灰度特征作为依据,只是插值的结果,去掉此类点。只保留那些通常符合角点特征的关键点。另外,上眼睑上的点也要去掉,以避免眨眼造成的干扰。以四个眼角和两个嘴角这六个关键点为例,如果戴眼镜的话,眼角会发生光学畸变,可以用眼镜上的点来代替眼角点,也可以用眉毛上的点来代替。
算法在平移过程中可以截取很多帧不同视角的人脸照片,由于手机与人脸距离比较近,所以不需要平移很大的幅度,也足以产生能够分辨关键点3d结构的视差。对采集到的多张图片的关键点,利用structurefrommotion算法,计算出其3d结构。用户可以在初始化软件,录入人脸信息时,通过鲁邦和冗余的算法,得到他本人的稳定的3d结构参数,下次只要将本次的恢复结果与录入信息进行比较就可以了。这种策略可以有效避免对着静止照片或不匹配的视频移动手机的伪造行为,因为通过视差计算出来的3d结构将不相符。
采用头部不动手机动的方案,而不是手机不动头部扭动的方案,因为后者容易伪造,如果事先录制好用户的一段扭动头部的视频,可能从对方的朋友圈,活动视频中获得,然后只要将手机对着屏幕摆放到一个恰当的位置,就有可能形成虚假但合格的3d效果。但采用头部不动手机动的方案,恰恰利用了手机可以自由移动,并且内置六轴陀螺仪的特点。陀螺仪会记录下手机的加速度和角加速度参数,算法通过对人脸关键点的跟踪,可以知悉其运动状态,进而反推出手机的运动状态,这个状态必须跟陀螺仪检测到的状态相匹配,否则认为有伪造视频的欺骗嫌疑。用户本人在进行真实合规操作时,只要自己的头部保持静止,就可以确保通过率接近100%。而伪造的运动却很难跟视频上预先录制好的运动保持完全一致,尤其是在手机移动的速度较快,或者采用更加复杂的平移方式,如圆圈,8字型,十字型运动时,伪造行为很难得逞。同时,本发明可以增加一个运动模式的识别,通过系统随机指定运动模式,或用户设定的运动模式,来增加系统安全性。
可通过自由移动和内置陀螺仪,来设计了专门针对手机端的人脸活体校验方案。利用平移手机所带来的两个联动效应,平移产生视差用来计算人脸关键点的3d结构,平移动作本身与手机陀螺仪运动参数相匹配,分别解决了目标伪造行为和动作伪造行为。普通人很难将这两种伪造行为结合起来实施得毫无破绽,所以该方案具有很高的抗破解能力。
针对关键点的整体ransac约束跟踪:
假设t0时刻有关键点{p1,p2,...pn},t1时刻通过光流跟踪到的位置对应为{q1,q2,...qn},则在时间差不是很大的情况下,可以用一个仿射变换来描述从p到q的变换关系:wi*(f*pi+b=qi),f(2*2),b(2*1),i=1,2,...n,wi是第i个关键点的权值,初始化为1。共有6个未知数,只要关键点的个数n大于6,此方程组就可以用最小二乘法求得均方误差最小解,进而再计算它们的预测值{g1,g2,...gn}。如果1到n个关键点中有少量光流跟踪失败,假设是第k个,则qk与gk差值比较大,于是调小k的权值wk,然后再重复上面的过程。几轮迭代下来,跟踪失败的点k的权重会越来越小,对整体的影响越来越小,而其预测位置gk也来越准确,在gk的周围检测关键点,就可以缩小搜索范围,提高检测速度了。另外,如果出现明显的前后帧衔接不畅,光流跟踪会变得非常混乱而无法成功匹配,由此初步验证目标的连续性和真实性。
针对structurefrommotion算法:
前视摄像头内参标定。这一步可以在手机出厂时配置好,也可以在软件初始化的时候通过structurefrommotion算法来做。此处并不是本专利的核心技术,且目前大部分手机前视摄像头都是非畸变的,内参比较简单。
用户脸部关键点3d结构确定:
这一步也是structurefrommotion算法的核心。一般在用户录入人脸,初始化软件的时候做,以提高现场活体验证时的速度。初次录入人脸信息时,用手机对着脸部做多方位多角度的滑动。算法会自动提取出每一帧的关键点二维图像坐标,然后挑选那些在整体距离比较大的若干帧高质量关键点信息。方法就是新选入的某一帧,必须与历史选入的其他帧的关键点的点点匹配距离平均值大于阈值,这样一段时间后,就会累积到足够数目的优质关键点帧。
关键点3d结构规整。由于structurefrommotion算法恢复的3d结构是无量纲的,这里需要将它的尺寸固定,调整量纲参数λ,使左眼的左眼角,右眼和右眼角之间的距离为1分米。然后以两外眼角连线中心位置为原点,从左眼角到右眼角的方向为x轴方向,两嘴角中心点到原点的方向为y轴方向,再按正常右手坐标系原则确定z轴方向,该z轴方向是朝向后脑勺的,构造合适的rt变换将关键点3d位置信息对齐到如上所述的坐标系中,然后存储起来。此坐标系称为人脸规整坐标系。
现场关键点3d结构比对。在活体检测应用现场时,用上面同样的方法来确定现场人脸的3d结构,只是关键点帧的数量可以少一点,算法迭代次数可以少一点,并随机地多恢复几次3d结构,同样对它们做规整化变换,然后与库中已经录入的规整3d结构进行比对。选择合适的阈值以接受或者拒绝匹配。
陀螺仪运动参数匹配方法为:
摄像头内参和人脸关键点3d结构已经在人脸录入时确定了,现场活体检测时,将标准关键点3d结构,图像上的关键点2d位置,以及摄像头内参作为输入,使用opencv中的solvepnp()函数,就可以恢复出每一帧摄像头相对于人脸规整坐标系的姿态,用r,t表示,r是旋转矩阵,t是平移量。下面描述一种相对简单的运动参数比对方案:
现场活体检测时尽量保证头部垂直,手机平移时尽量保持手机竖直且角度不变,于是手机自身的角速度分量可以忽略不计,r的变化很小,只考虑t的变化。通过连续三帧的t值变化,计算手机在每一帧的三维加速度a,由a组成的序列再进行适当的卡尔曼滤波,降低观测噪声。
手机陀螺仪同步检测到手机的三维加速度信息b。由于平移过程中手机的角度尽量保持不变,因此通过对整个期间段的低通滤波成分,可以估算出重力方向。通过适当的坐标变换,将重力方向变换到与人脸规整坐标系的y轴负方向对齐,将该坐标变换作用于b,然后再减去重力加速度分量,得到b’,b’与a在y轴方向大致对齐了,匹配难度有所降低,在y分量上对它们先行比对。先计算b’与a在y分量的均值方差,然后分别减去均值,除以标准差,归一化对齐,然后对归一化后的一维序列进行匹配,设计合适的阈值接受或者拒绝。
如果上一步通过,再比对x方向的加速度序列。将b’与a的y分量去掉,剩下的两维计算协方差,对协方差做主成分分析,确定主方向和次方向。主成分分析的两个成分是相互正交的,由于平移手机时主要的平移成分集中在x和y方向,z轴方向很小,所以主成分大致在x轴上,次成分大致在z轴上。取主成分分量的序列,同样做归一化对齐,必要时可能还需要翻转,然后进行比对,设计合适的阈值接受或者拒绝。
序列比对时,每一帧的权重与该帧的加速度的绝对值成正比,取两者最大的那个,增加加速度大的时间点的权重,提高匹配准确性。
同时,可以放开对r不变的限制,首先,和t一样,要对r序列做适当的卡尔曼滤波或平滑滤波。其次,陀螺仪检测到的加速度信息,不能直接用来估算重力方向,要先做一次r逆变换,b=rt*b,然后再跟前面的步骤一样,计算重力方向,减去重力加速度。
- 还没有人留言评论。精彩留言会获得点赞!