基于苹果原料指标预测果汁混浊度的方法与流程
本发明涉及一种预测果汁混浊度的方法。更具体地说,本发明涉及基于苹果原料指标预测果汁混浊度的方法。
背景技术:
苹果居世界四大水果之首,我国是世界上最大的苹果生产国和消费国,我国苹果种植广泛且品种也较丰富。苹果除用作鲜食外,便是主要榨成汁食用。果汁按照加工方式不同可分为浓缩还原汁和非浓缩还原汁。鲜榨苹果汁,即苹果非浓缩还原汁,未经过繁多的加工程序,其口感新鲜、风味天然、营养丰富,品质更接近新鲜苹果,受到众多消费者的青睐。
鲜榨苹果汁是浊汁果汁,因此稳定性不佳,货架期间易发生沉淀,影响了鲜榨苹果浊汁在货架期、流通环节中的品质。目前,为保持果汁及果汁饮料货架期内的稳定性,可以通过添加稳定剂来缓解,但其没有从源头上解决果汁稳定性问题。现有对制品品质的研究多采用层次分析、灰色关联等方法单独分析,例如吴厚玖等人运用百分法判别甜橙品种加工适宜性的定量评价方法,宋洁等人运用极差变换法处理指标数据,得到猪肉涮食的质量评价结果,此类方法仅可以评价所研究品种的加工特性,无法预测未知样品的加工性能。
混浊度及货架期内混浊度变化是衡量浊汁果汁稳定性的重要指标,如若有一种方法可以预测苹果原料制备成鲜榨浊汁的稳定性指标,进而判定此苹果品种是否适宜鲜榨浊汁加工,从果汁加工的源头,即从原料角度严格筛选高稳定性浊汁加工的苹果品种,那将为产业确定制汁专用化苹果品种提供有效方法,促进加工产业原料标准化和果汁制品品质的提升,推进我国苹果鲜榨果汁产业的发展。
技术实现要素:
本发明的目的是提供基于苹果原料指标预测果汁混浊度的方法,通过运用人工神经网络,快速预测鲜榨浊汁混浊度,进而判定鲜榨浊汁的稳定性,解决了果汁稳定性指标检测较麻烦,用时较长的问题,达到预测果汁产品品质,定向筛选高稳定性浊汁加工的苹果原料品种的目的,满足了鲜榨苹果汁产业快速发展的需求。
为了实现根据本发明的这些目的和其它优点,提供了基于苹果原料指标预测果汁混浊度的方法,包括:
步骤一、选取苹果样本,确定苹果原料指标,并获取苹果原料指标数据和苹果汁混浊度数据;
步骤二、建立所述苹果原料指标数据与所述苹果汁混浊度数据的相关关系;
步骤三、确定与所述苹果汁混浊度数据呈显著相关的苹果原料核心指标数据;
步骤四、从苹果样本中选取训练样本,获取训练样本的苹果原料指标数据,以训练样本的苹果原料核心指标数据为输入层,以苹果汁混浊度为输出层,训练获得神经网络学习模型;
步骤五、利用所述神经网络学习模型和待测苹果的原料核心指标数据,预测待测苹果的果汁混浊度。
优选的是,所述的基于苹果原料指标预测果汁混浊度的方法中,所述苹果原料指标包括物理类指标、感官类指标、加工类指标和营养类指标。
优选的是,所述的基于苹果原料指标预测果汁混浊度的方法中,所述步骤二中,建立所述苹果原料指标数据与所述苹果汁混浊度数据的相关关系的具体方法为:对苹果原料指标数据与所述苹果汁混浊度数据进行相关性分析,以建立所述苹果原料指标数据与所述苹果汁混浊度数据的相关关系。
优选的是,所述的基于苹果原料指标预测果汁混浊度的方法中,所述步骤三中,确定与所述苹果汁混浊度数据呈显著相关的苹果原料核心指标数据的具体方法为:对苹果原料指标数据与所述苹果汁混浊度数据进行相关性分析,选取相关性系数呈显著性相关的原料指标作为苹果原料核心指标,通过苹果原料核心指标确定苹果原料核心指标数据。
优选的是,所述的基于苹果原料指标预测果汁混浊度的方法中,所述步骤四之后,步骤五之前,还包括以下步骤:
选取苹果验证样本,获取验证样本的苹果原料核心指标数据和苹果汁混浊度数据,利用所述神经网络学习模型和验证样本的苹果原料核心指标数据,获取验证样本的果汁混浊度,若通过神经网络学习模型得到的验证样本的果汁混浊度的正确率低于90%,则增加训练样本的数量,并更新神经网络学习模型,或者提高设定值,更新苹果原料核心指标,并重新训练获得神经网络学习模型。
优选的是,所述的基于苹果原料指标预测果汁混浊度的方法中,所述神经网络学习模型的训练参数如下:最大循环次数为1000~20000,学习率为0.1~1,动量因子为0.1~0.5,误差值为0.00005~0.1。
优选的是,所述的基于苹果原料指标预测果汁混浊度的方法中,训练样本的选取个数为25~40个。
优选的是,所述的基于苹果原料指标预测果汁混浊度的方法中,所述苹果原料核心指标数据的数量为4~10个。
本发明至少包括以下有益效果:
本发明运用人工神经网络建立苹果汁混浊度的快速预测模型,可判定苹果汁的混浊稳定性,进而筛选高稳定性浊汁加工的苹果品种,生产出高品质的苹果汁,极大地促进了鲜榨苹果汁产业的发展。
本发明的其它优点、目标和特征将部分通过下面的说明体现,部分还将通过对本发明的研究和实践而为本领域的技术人员所理解。
附图说明
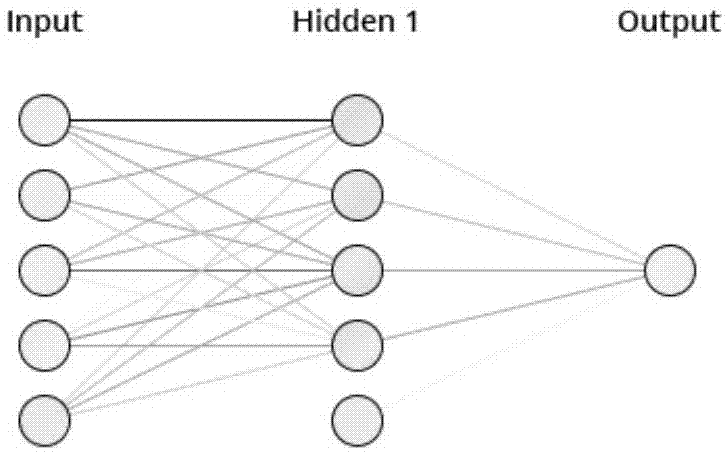
图1是根据本发明实施例1的bp神经网络结构图;
图2是根据本发明实施例2的bp神经网络结构图;
图3是根据本发明实施例3的bp神经网络结构图。
具体实施方式
下面结合附图和实施例对本发明做进一步的详细说明,以令本领域技术人员参照说明书文字能够据以实施。
实施例1
基于苹果原料指标预测果汁混浊度的方法,其具体步骤如下:
(1)选择苹果样本。
选取来自全国各地的41个苹果品种作为实验原料,部分品种名称、产地见表1。果实成熟期取样,取样涵盖早、中、晚熟三种类型苹果,无机械损伤、无病虫害。
表1部分苹果品种名称及产地
(2)确定苹果原料指标,并获取苹果原料指标数据和苹果汁混浊度数据。
(3)筛选苹果原料核心指标。
建立苹果原料指标数据与苹果汁混浊度数据的相关关系,对苹果果汁混浊度数据与苹果原料指标数据进行相关性分析,结果如表2所示。得到果心大小、果肉l*值、果皮a*值和柠檬酸4项指标作为苹果原料的核心指标。
表2苹果原料指标数据与苹果汁混浊度数据的相关关系
(4)构建神经网络学习模型。
本研究从41个苹果样本中随机筛选35个苹果样本作为训练样本来建立学习模型,剩余6个苹果样本作为预测样本进行果汁混浊度预测。如图1所示,其中模型输入层为果心大小、果肉l*值、果皮a*值和柠檬酸4项原料核心指标数据,模型输出层为苹果果实对应的果汁混浊度值,输入层最下层为模型辅助层,由软件自动添加。模型最优隐含层数为5个。其余各训练参数选择如下:最大循环次数4000,学习率0.2,动量因子0.2,误差值0.001。
(5)验证预测样本。
应用神经网络学习模型,对6个品种苹果的果汁混浊度进行预测,结果如表3所示,其中,相对误差=(预测混浊度-实际混浊度)/实际混浊度×100%。
表3神经网络预测结果
由表3可知,对6个品种苹果的果汁混浊度进行预测,预测的相对误差均小于3%,预设的阈值是相对误差绝对值小于8%,6个苹果样本预测准确,预测准确率为100%。
实施例2
一种基于苹果原料指标预测果汁混浊度的方法,其具体步骤如下:
(1)选择苹果样品。
选取来自全国各地的30个苹果品种作为实验原料,部分品种名称、产地见表4。果实成熟期取样,取样涵盖早、中、晚熟三种类型苹果,无机械损伤、无病虫害。
表4部分苹果品种名称及产地
(2)确定苹果原料指标,并获取苹果原料指标数据和苹果汁混浊度数据。
(3)筛选苹果原料核心指标。
建立苹果原料指标数据与苹果汁混浊度数据的相关关系,对苹果果汁混浊度数据与苹果原料指标数据进行相关性分析,结果如表5所示。得到果肉b*值、还原糖、总糖、乳酸和组氨酸5项指标作为苹果原料的核心指标。
表5苹果原料指标数据与苹果汁混浊度数据的相关关系
(4)构建学习模型。
本研究从30个苹果样本中随机筛选25个样本建立学习模型,剩余5个样本进行果汁混浊度预测。如图2所示,其中模型输入层为果肉b*值、还原糖、总糖、乳酸和组氨酸5项原料核心指标数据,模型输出层为苹果果实对应的果汁混浊度值,输入层最下层为模型辅助层,由软件自动添加。模型最优隐含层数为5个。其余各训练参数选择如下:最大循环次数6000,学习率0.2,动量因子0.4,误差值0.0001。
(5)验证预测样本。
应用神经网络学习模型,对5个品种苹果的果汁混浊度进行预测,结果如表6所示,其中,相对误差=(预测混浊度-实际混浊度)/实际混浊度×100%。
表6神经网络预测结果
由表6可知,对5个品种苹果的果汁混浊度进行预测,预测的相对误差均小于5%,预设的阈值是相对误差绝对值小于8%,5个苹果样本预测准确,预测准确率为100%。
实施例3
一种基于苹果原料指标预测果汁混浊度的方法,其具体步骤如下:
(1)选择苹果样品。
选取来自全国各地的45个苹果品种作为实验原料,部分品种名称、产地见表7。果实成熟期取样,取样涵盖早、中、晚熟三种类型苹果,无机械损伤、无病虫害。
表7部分苹果品种名称及产地
(2)确定苹果原料指标,并获取苹果原料指标数据和苹果汁混浊度数据。
(3)筛选苹果原料核心指标。
建立苹果原料指标数据与苹果汁混浊度数据的相关关系,对苹果果汁混浊度数据与苹果原料指标数据进行相关性分析,结果如表8所示。得到果心大小、果皮a*值、果皮b*和柠檬酸4项指标作为苹果原料的核心指标。
表8苹果原料指标数据与苹果汁混浊度数据的相关关系
(4)构建学习模型。
本研究从45个苹果样本中随机筛选40个样本建立学习模型,剩余5个样本进行果汁混浊度预测。如图3所示,其中模型输入层为果心大小、果皮a*值、果皮b*和柠檬酸4项原料核心指标数据,模型输出层为苹果果实对应的果汁混浊度值,输入层最下层为模型辅助层,由软件自动添加。模型最优隐含层数为5个。其余各训练参数选择如下:最大循环次数10000,学习率0.4,动量因子0.5,误差值0.00001。
(5)验证预测样本。
应用神经网络学习模型,对5个品种苹果的果汁混浊度进行预测,结果如表9所示,其中,相对误差=(预测混浊度-实际混浊度)/实际混浊度×100%。
表9神经网络预测结果
由表9可知,对5个品种苹果的果汁混浊度进行预测,预测的相对误差均小于7%,预设的阈值是相对误差绝对值小于8%,5个苹果样本预测准确,预测准确率为100%。
尽管本发明的实施方案已公开如上,但其并不仅仅限于说明书和实施方式中所列运用,它完全可以被适用于各种适合本发明的领域,对于熟悉本领域的人员而言,可容易地实现另外的修改,因此在不背离权利要求及等同范围所限定的一般概念下,本发明并不限于特定的细节和这里示出与描述的图例和实施例。
- 还没有人留言评论。精彩留言会获得点赞!