基于Hadoop和ARlMA的和教育趋势预测方法与流程
本发明涉及一种和教育发展趋势预测方法,特别是一种基于hadoop和arlma的和教育趋势预测方法。
背景技术:
“和教育”是中国移动面向中小学师生和家长推出的一款集在线教育学习及家校互动沟通为一体的手机软件,其中整合百万优质学科资源并与近千家名校合作,共同帮助学生提高学习成绩。
随着中国移动和教育业务的发展,教师和家长用户数量稳步增长,相应用户浏览、订阅等互动行为数据急剧增长,需要处理的数据量达到tb级别,原本关系型数据库在存储和计算上都难以满足需求,更重要的是,在原有框架下无法很好的利用已有数据对未来数据发展趋势进行预测。
hadoop实现了一个分布式文件系统(hadoopdistributedfilesystem),简称hdfs。hdfs有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(highthroughput)来访问应用程序的数据,适合那些有着超大数据集(largedataset)的应用程序。hdfs放宽了(relax)posix的要求,可以以流的形式访问(streamingaccess)文件系统中的数据。hadoop的框架最核心的设计就是:hdfs和mapreduce。hdfs为海量的数据提供了存储,则mapreduce为海量的数据提供了计算。
云计算、大数据技术的发展给海量数据的处理提供了很好的解决途径,hadoop框架解决了海量数据的存储和计算问题。虽然大数据平台能够解决存储并利用hive等工具进行统计,但是对于数据增长趋势,发展方向等未能提供直接的解决方案,而在和教育领域这些指标对于运营是至关重要的。
技术实现要素:
本发明所要解决的技术问题是提供一种基于hadoop和arlma的和教育趋势预测方法,对用户数增长和用户活跃进行预测。
为解决上述技术问题,本发明所采用的技术方案是:
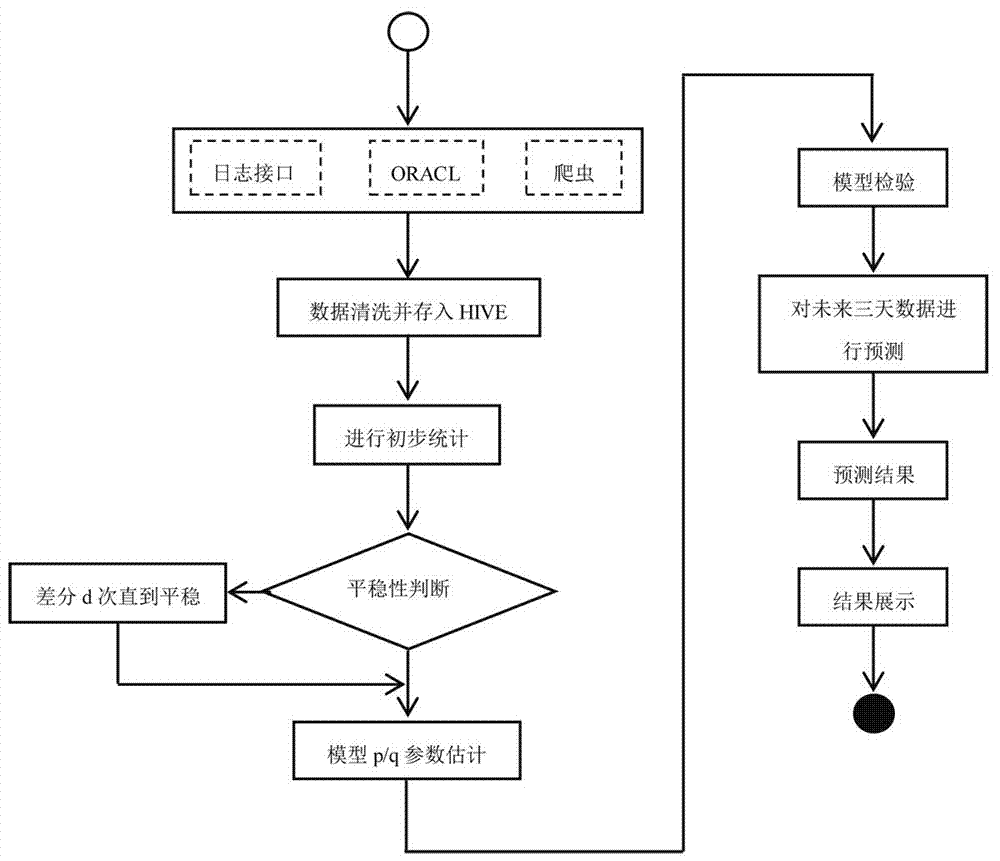
一种基于hadoop和arlma的和教育趋势预测方法,其特征在于包含以下步骤:
步骤一:数据节点接收待存储的数据,对数据进行清洗后存入hive;
步骤二:利用hive对过去日数据进行离线统计,得到已有数据的统计结果;
步骤三:对步骤二数据进行计算得到arima模型;
步骤四:利用arima模型对未来一周和一个月数据进行预测;
步骤五:将预测数据呈现给用户。
进一步地,所述步骤一中过去日数据来源包含埋点获取的日志文件、用户注册上传信息和爬虫获取的信息;多方信息根据各自特征进行清洗和过滤并统一格式后,存入实现设计好的hive表中。
进一步地,所述步骤二中hive中存储的数据为原始数据,需要经过初步统计,统计根据需要细化到适当的粒度;对数据绘图,观测是否为平稳时间序列,若不是需要进行d阶差分运算使得能够满足时间平稳序列,d根据结果是否平稳决定。
进一步地,所述步骤三具体为对平稳时间序列分别求得其自相关系数acf和偏自相关系数pacf,通过对自相关图和偏自相关图的分析,得到最佳的阶层p和阶数q,进而得到arima模型;然后开始对得到的模型进行模型检验,即检验arima模型的残差是否是平均值为0且方差为常数的正态分布。
进一步地,所述步骤四具体为根据当前最新数据,利用步骤三生成的模型对未来一周和一个月进行预测,预测结果写入mysql。
进一步地,所述预测过程为
4.1、由于原始数据粒度均为单个用户,需要对其初步统计,维度根据需要最高可到省份,最细可到学校和代理商,统计时间尺度按天,结果存入hive新表中;
4.2、编写map/reduce程序直接读取4.1的结果表,对表中数据进行时间序列平稳性判断;用户的行为数据如pv和uv正常情况均符合时间序列平稳性,即满足在特定常数上下浮动;而用户总数和收入等则随时间有明显的增长,不满足,需要进行差分计算直到平稳,最后进行平稳性检测;
4.3、在4.2的基础上进行arima建模,首先计算该序列的自相关系数和偏相关系数,模型识别即模型定阶,根据系数从ar(p)模型和ma(q)模型,arma(p,q)模型,arima(p,d,q)模型中选取合适模型,其中p为自回归项,d为差分阶数,q为移动平均项数,所有相关计算方式均以map/reduce的方式实现,根据算法设计map和reduce类,多个map/reduce任务由shell脚本串联进行;
4.4、利用得到的模型计算未来一周和一个月的用户数、pv/uv和收入情况,并将结果存入mysql供前端页面调用。
进一步地,所述步骤五具体为使用前端可视化工具展示截止当前的统计结果,并重点用虚线和红色展示预测结果。
本发明与现有技术相比,具有以下优点和效果:本发明基于hadoop和arlma的和教育趋势预测方法,利用hadoop的存储、计算能力解决了传统关系型数据库存储和计算能力的不足;更重要的是,利用arima模型的预测能力,对和教育用户数、用户活跃和收入等重要指标进行预测,为运营提供指导。传统arima模型的实现都基于单机,在数据量大的情况下效率很低,为此本发明中根据arima模型原理并结合和教育业务以分布式(map/reduce)方式实现,大大提高了处理大数据量的效率。
附图说明
图1是本发明的基于hadoop和arlma的和教育趋势预测方法的流程图。
具体实施方式
下面通过实施例对本发明作进一步的详细说明,以下实施例是对本发明的解释而本发明并不局限于以下实施例。
如图1所示,本发明的一种基于hadoop和arlma的和教育趋势预测方法,其特征在于包含以下步骤:
步骤一:数据节点接收待存储的数据,对数据进行清洗后存入hive(一种基于hdfs分布式存储的数据仓库);
过去日数据来源包含埋点获取的日志文件、用户注册上传信息和爬虫获取的信息;多方信息根据各自特征进行清洗和过滤并统一格式后,存入实现设计好的hive表中。
本发明中使用的hadoop为cdh5.14,cdh包含的服务比较多,本发明必须的服务有hdfs,yarn,hive,zookeeper,kafka和sqoop2。其中hdfs提供了存储功能,yarn是一种分布式计算框架,zookeeper协调服务,kafka流处理平台用于接入日志等数据,sqoop2数据接入工具。
数据来源:1.页面埋点,通过埋点采集用户的浏览数据,包括停留时长,通过kafka接入;2.用户资料数据,大部分由代理商上传至oracle,本发明通过sqoop2接入;3.网络爬虫,定期爬取页面信息,作为用户行为分析是参考用。三方数据获取后通过java编写的数据清理服务进行清理:1.格式化,去掉数据中符号表情等非表述性信息,统一编码等;2.去掉无用信息,如残缺数据,异常和错误数据。该模块处理完后将数据存入模块一中的hive(一种基于hdfs的数据仓库)中。
步骤二:利用hive对过去日数据进行离线统计,得到已有数据的统计结果;
hive中存储的数据为原始数据,需要经过初步统计,统计根据需要细化到适当的粒度;通常情况下各统计指标符合平稳时间序列,但仍需要检测。对数据绘图,观测是否为平稳时间序列,若不是需要进行d阶差分运算使得能够满足时间平稳序列,d根据结果是否平稳决定。
步骤三:对步骤二数据进行计算得到arima模型;
arima模型全称为自回归积分滑动平均模型(autoregressiveintegratedmovingaveragemodel,简记arima),是由博克思(box)和詹金斯(jenkins)于70年代初提出一著名时间序列(time-seriesapproach)预测方法[1],所以又称为box-jenkins模型、博克思-詹金斯法。其中arima(p,d,q)称为差分自回归移动平均模型,ar是自回归,p为自回归项;ma为移动平均,q为移动平均项数,d为时间序列成为平稳时所做的差分次数。所谓arima模型,是指将非平稳时间序列转化为平稳时间序列,然后将因变量仅对它的滞后值以及随机误差项的现值和滞后值进行回归所建立的模型。arima模型根据原序列是否平稳以及回归中所含部分的不同,包括移动平均过程(ma)、自回归过程(ar)、自回归移动平均过程(arma)以及arima过程。
对平稳时间序列分别求得其自相关系数acf和偏自相关系数pacf,通过对自相关图和偏自相关图的分析,得到最佳的阶层p和阶数q,进而得到arima模型;然后开始对得到的模型进行模型检验,即检验arima模型的残差是否是平均值为0且方差为常数的正态分布。
步骤四:利用arima模型对未来一周和一个月数据进行预测;
根据当前最新数据,利用步骤三生成的模型对未来一周和一个月进行预测,预测结果写入mysql。
预测过程为
4.1、由于原始数据粒度均为单个用户,需要对其初步统计,维度根据需要最高可到省份,最细可到学校和代理商,统计时间尺度按天,结果存入hive新表中;
4.2、编写map/reduce程序直接读取4.1的结果表,对表中数据进行时间序列平稳性判断;用户的行为数据如pv和uv正常情况均符合时间序列平稳性,即满足在特定常数上下浮动;而用户总数和收入等则随时间有明显的增长,不满足,需要进行差分计算直到平稳,最后进行平稳性检测;
4.3、在4.2的基础上进行arima建模,首先计算该序列的自相关系数(acf)和偏相关系数(pacf),模型识别即模型定阶,根据系数从ar(p)模型和ma(q)模型,arma(p,q)模型,arima(p,d,q)模型中选取合适模型,其中p为自回归项,d为差分阶数,q为移动平均项数,所有相关计算方式均以map/reduce的方式实现,根据算法设计map和reduce类,多个map/reduce任务由shell脚本串联进行;
4.4、利用得到的模型计算未来一周和一个月的用户数、pv/uv和收入情况,并将结果存入mysql供前端页面调用。
步骤五:将预测数据呈现给用户。
使用前端可视化工具展示截止当前的统计结果,并重点用虚线和红色展示预测结果。
本发明基于hadoop和arlma的和教育趋势预测方法,利用hadoop的存储、计算能力解决了传统关系型数据库存储和计算能力的不足;更重要的是,利用arima模型的预测能力,对和教育用户数、用户活跃和收入等重要指标进行预测,为运营提供指导。传统arima模型的实现都基于单机,在数据量大的情况下效率很低,为此本发明中根据arima模型原理并结合和教育业务以分布式(map/reduce)方式实现,大大提高了处理大数据量的效率。
本说明书中所描述的以上内容仅仅是对本发明所作的举例说明。本发明所属技术领域的技术人员可以对所描述的具体实施例做各种修改或补充或采用类似的方式替代,只要不偏离本发明说明书的内容或者超越本权利要求书所定义的范围,均应属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!