一种基于全卷积神经网络的PET与CT图像配准方法与流程
本发明属于医学图像配准领域,具体涉及一种基于全卷积神经网络的pet与ct图像配准方法。
背景技术:
正电子断结构扫描(positronemissioncomputertomography,以下简称pet)利用回旋加速器产生放射性同位素18f、13n,静脉注射后参与人体的新陈代谢。代谢率高的组织或病变,在pet上呈现明确的高代谢亮信号;代谢率低的组织或病变在pet上呈低代谢暗信号。计算机断结构扫描(computedtomography,以下简称ct)是用x线束对人体的某一部分按一定厚度的结构面进行扫描,当x线射向人体组织时,部分射线被组织吸收,部分射线穿过人体被检测器官接收,产生信号,能准确对图像进行定位。
pet/ct可以进行功能与解剖结构的同机图像融合,是影像医学的一个重要进展。多模态图像配准利用各种成像方式的特点,为不同的影像提供互补信息,增加图像信息量,有助于更全面地了解病变的性质及与周围解剖结构的关系,为临床诊断和治疗的定位提供有效的方法。
医学图像配准在许多医学图像处理任务中起着重要的作用。通常将图像配准制定为优化问题以寻求空间变换,该空间变换通过最大化图像之间的空间对应的替代度量(例如配准图像之间的图像强度相关性)来建立一对固定和移动图像之间的像素/体素对应。由于图像配准优化问题通常使用迭代优化算法来解决,所以传统的图像配准算法通常在计算上成本很高。与传统的图像配准算法不同,基于深度学习的图像配准算法将图像配准定义为多输出回归问题,预测来自一对图像的像素/体素之间的空间关系。训练后的预测模型可以应用于像素/体素级别的图像以实现整体图像配准。
目前,基于全卷积网络(fullyconvolutionalnetworks以下简称fcn)的体素到体素的学习是hongmingli等人提出的图像配准方法。通过最大化图像对的相似性度量训练fcn来估计用于配准图像的体素到体素空间变换。为了解决图像之间潜在的较大形变,采用多分辨率策略来联合优化和学习不同分辨率下的空间变换;而以往方法对pet/ct的图像配准存在失真情况,即没有对形变场加以限制导致图像扭曲幅度过大。
技术实现要素:
(一)要解决的技术问题
为了解决现有技术的上述问题,本发明提供一种基于全卷积神经网络的pet与ct图像配准方法。
(二)技术方案
为了达到上述目的,本发明采用的主要技术方案包括:
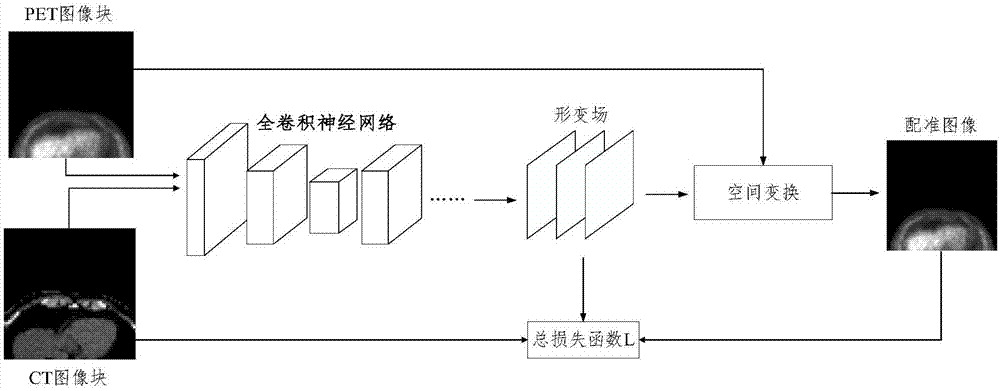
获取待配准的pet与ct二维图像,通过尺寸预处理后获取待配准的pet与ct图像块并输入到预先训练的全卷积神经网络中,获取配准图像;
其中,训练全卷积神经网络包括以下步骤:
101、预先获取多幅pet和ct二维样本图像,进行尺寸预处理,获取用于训练的pet和ct样本图像块;
102、构建全卷积神经网络,初始化网络权重参数,设置迭代次数,将用于训练的pet和ct样本图像块作为全卷积神经网络的输入,通过多次卷积、池化和反卷积生成形变场;
103、通过对形变场和pet图像块进行空间变换获取训练的配准图像;
104、根据训练配准图像和pet图像块获取相似度lsim,根据形变场获取限制形变场平滑度lsmooth,根据公式一和公式二获取总损失函数l,通过总损失函数l更新网络权重参数;
公式一:l=m1*l1+m2*l2......+mn*ln;
式中,m1+m2.....+mn=1,m1、m2……mn均为常数;
公式二:l(f,m,dv)=lsim(f,mdv)+λlsmooth(dv);
式中,lsim为相似性度量,f为ct图像块,mdv为,lsmooth为形变场的平滑度,dv为位移矢量矩阵,λ为常数;
105、遍历用于训练的pet和ct样本图像块,重复执行步骤103-105,多次迭代训练并更新网络权重参数,直至迭代次数达到预设值,获取预先训练的全卷积神经网络。
可选地,尺寸预处理包括:
b1、针对预处理的图像,根据公式三和公式四,分别计算suv值和hu值,设置hu值窗宽窗位和suv限制范围;
公式三:suv=pixels×lbm×1000/injecteddose;
式中,pixels为pet图像的像素值,lbm为瘦体重,injecteddose为注射示踪剂计量;
公式四:hu=pixels×slopes+intercepts;
式中,pixels为ct图像的像素值,slopes为hu值计算公式中的斜率;intercepts为hu值计算公式中的截距;
b2、调整分辨率至图像尺寸等于预设值生成三维数组;
b3、将三维数组据变换成五维数组,通过剪裁和采样获取预设尺寸的图像块。
可选地,步骤103中构建全卷积神经网络包括:
第一卷积结构、第二卷积结构、第三卷积结构、第四卷积结构、第一反卷积结构、第二反卷积结构、第一池化结构和第二池化结构;
全卷积神经网络的输入作为第一卷积结构的输入;
第一卷积结构、第二卷积结构、第三卷积结构和第四卷积结构依次排列;
第一池化结构设置在第一卷积结构和第二卷积结构之间,第二池化结构设置在第二卷积结构和第三卷积结构之间;
第一反卷积结构设置在第三卷积结构和第四卷积结构之间,第二反卷积结构设置在第四卷积结构之后。
可选地,
第一卷积结构、第二卷积结构、第三卷积结构、第四卷积结构、第一反卷积结构、第二反卷积结构均包括卷积层、批量化归一层和激活层;
第一池化结构和第二池化结构包括卷积层;
其中,卷积层的卷积核为3×3×3,步长为2。
可选地,形变场包括:
第一形变场、第二形变场和三形变场;
将第二反卷积结构的输出进行卷积操作,获取第一形变场;
将第四卷积结构的输出进行卷积操作,获得第二形变场;
将第三卷积结构的输出进行卷积操作,获得第三形变场;
其中,卷积操作的卷核为3×3×3,步长为1。
可选地,
在训练过程中通过上采样调整第一形变场尺寸使得其与pet图像块尺寸相同;
将具有相同尺寸的第一形变场和pet图像块通过空间变换作为训练的配准图像。
可选地,
将pet和ct样本图像块以及待配准的pet与ct图像块输入至全卷积神经网络之前,根据公式四对每个图像块进行归一化;
公式五:
式中,μ为均值,σ为标准差。
可选地,
通过公式六获取lsim,通过公式七获取lsmooth;
公式六:lsim=ncc+emd;
其中,ncc表示归一化互相关,emd为wasserstein距离;
t表示模板,s表示子图,s(r,z)表示模子图的像素值,t(r,z)表示模板图像素值,e(s)表示子图的平均灰度,e(t)表示模板的平均灰度,r和z均为常数,r和z均为坐标索引;
p表示一幅图像的特征,q表示另一幅图像的特征,dij表示两个图之间的距离,fij表示p和q特征权重总和的最小值,m和n均为常数;
wpi表示p的权重,wqj表示q的权重;
公式七:
其中,ω为,p为,dv为位移矢量矩阵,
可选地,其特征在于,
hu值窗宽窗位为[-90,300],suv限制范围为[0,5]。
可选地,
尺寸预处理获取的图像块的大小为64×64×64。
(三)有益效果
本发明的有益效果是:
本发明利用全卷积神经网络实现端到端的的多分辨率的弹性配准,本发明通过多目标优化来进行不同分辨率下的空间变换,即同时结合ct图像和配准图像对之间的相似性度量以及限制形变场平滑度,从而限制图像的过度形变;本发明计算量小,配准效率高。
附图说明
图1为本发明一实施例提供的一种基于全卷积神经网络的pet与ct图像配准方法示意图;
图2为本发明一实施例提供的全卷积神经网络内部结构示意图;
图3为本发明一实施例提供的配准方法模块流程示意图;
图4为本发明一实施例提供的配准发明的具体流程图。
具体实施方式
为了更好的解释本发明,以便于理解,下面结合附图,通过具体实施方式,对本发明作详细描述。
实施例一
本发明提出了一种基于全卷积神经网络的pet与ct图像配准方法,具体的包括:
如图1所示,获取待配准的pet与ct二维图像,通过尺寸预处理后获取待配准的pet与ct图像块并输入到预先训练的全卷积神经网络中,获取配准图像;
其中,训练全卷积神经网络包括以下步骤:
101、预先获取多幅pet和ct二维样本图像,进行尺寸预处理,获取用于训练的pet和ct样本图像块;
特别的,将pet和ct样本图像块以及待配准的pet与ct图像块输入至全卷积神经网络之前,根据公式四对每个图像块进行归一化;
公式五:
式中,μ为均值,σ为标准差。
举例来说,在具体实施过程中,尺寸预处理包括:
b1、针对预处理的图像,根据公式三和公式四,分别计算suv值和hu值,设置hu值窗宽窗位和suv限制范围;
举例来说,hu值窗宽窗位可设置为[-90,300],suv限制范围为可设置为[0,5];
公式三:suv=pixels×lbm×1000/injecteddose;
式中,pixels为pet图像的像素值,lbm为瘦体重,injecteddose为注射示踪剂计量;
公式四:hu=pixels×slopes+intercepts;
式中,pixels为ct图像的像素值,slopes为hu值计算公式中的斜率;intercepts为hu值计算公式中的截距;
b2、调整分辨率至图像尺寸等于预设值生成三维数组;
b3、将三维数组据变换成五维数组,通过剪裁和采样获取预设尺寸的图像块;
举例来说,在具体实施过程中尺寸预处理获取的图像块的大小为64×64×64。
102、构建全卷积神经网络,初始化网络权重参数,设置迭代次数,将用于训练的pet和ct样本图像块作为全卷积神经网络的输入,通过多次卷积、池化和反卷积生成形变场;
举例来说,如图2所示,在本实施例中构建全卷积神经网络包括:
第一卷积结构、第二卷积结构、第三卷积结构、第四卷积结构、第一反卷积结构、第二反卷积结构、第一池化结构和第二池化结构;
全卷积神经网络的输入作为第一卷积结构的输入;
第一卷积结构、第二卷积结构、第三卷积结构和第四卷积结构依次排列;
第一池化结构设置在第一卷积结构和第二卷积结构之间,第二池化结构设置在第二卷积结构和第三卷积结构之间;
第一反卷积结构设置在第三卷积结构和第四卷积结构之间,第二反卷积结构设置在第四卷积结构之后。
可选地,
第一卷积结构、第二卷积结构、第三卷积结构、第四卷积结构、第一反卷积结构、第二反卷积结构均包括卷积层、批量化归一层和激活层;
第一池化结构和第二池化结构包括卷积层;
其中,卷积层的卷积核为3×3×3,步长为2。
进一步的,第一形变场、第二形变场和三形变场;
将第二反卷积结构的输出进行卷积操作,获取第一形变场;
将第四卷积结构的输出进行卷积操作,获得第二形变场;
将第三卷积结构的输出进行卷积操作,获得第三形变场;
其中,卷积操作的卷核为3×3×3,步长为1。
103、通过对形变场和pet图像块进行空间变换获取训练配准图像;
具体地,举例来说,在具体实施过程中,通过上采样调整第一形变场尺寸使得其与pet图像块尺寸相同;
同理对第二形变场和第三形变场进行相同的操作获取参考的获取参考的两个配准图像,特殊说明,本实施例仅用获取三个形变场举例说明,本发明还可包括多个形变场;
在本实施例中,训练网络时,每一次训练过程中多个形变场都能与pet图像块进行空间变换获得多个参考的配准图,其中只有与第四反卷积连接生成的第一形变场与pet图像块生成的匹配图像作为一次训练的输出,并作为此次训练的配准结果即,其他参考配准图用于计算损失函数数值,进一步的可以获取总损失函数的数值。
104、根据训练配准图像和pet图像块获取相似度lsim,根据形变场获取限制形变场平滑度lsmooth,根据公式一和公式二获取总损失函数l,通过总损失函数l更新网络权重参数;
公式一:l=m1*l1+m2*l2......+mn*l2;
式中,m1+m2.....+mn=1,m1、m2……mn均为常数;
公式二:l(f,m,dv)=lsim(f,mdv)+λlsmooth(dv);
式中,lsim为相似性度量,f为ct图像块,mdv为,lsmooth为形变场的平滑度,dv为位移矢量矩阵,λ为常数;
通过公式五获取lsim,通过公式六获取lsmooth;
公式六:lsim=ncc+emd;
其中,ncc表示归一化互相关,emd为wasserstein距离;
t表示模板,s表示子图,s(r,z)表示模子图的像素值,t(r,z)表示模板图像素值,e(s)表示子图的平均灰度,e(t)表示模板的平均灰度,r和z均为常数,r和z均为坐标索引;
p表示一幅图像的特征,q表示另一幅图像的特征,dij表示两个图之间的距离,fij表示p和q特征权重总和的最小值,m和n均为常数;
wpi表示p的权重,wqj表示q的权重;
公式七:
其中,ω为位移矢量矩阵空间,p为当前位移矢量矩阵,dv为位移矢量矩阵,
举例来说,在本实施例中,n=3,m1=0.7,m2=0.2,m3=0.1即分别获取第一形变场、第二形变场和第三形变场与当前输入的pet图像块的相似度lsim1、lsim2和lsim3,获取第一形变场、第二形变场和第三形变场的限制形变场平滑度lsmooth1、lsmooth2和lsmooth3;
相应的可知,l1=lsim1+λlsmooth1,l2=lsim2+λlsmooth2,l3=lsim3+λlsmooth3;
举例来说,总损失函数l=0.7*l1+0.2*l2......+0.1*l3,利用总损失函数对当前网络的权重比进行修正,并在下一次训练时使用更新后的网络的权重比。
105、遍历用于训练的pet和ct样本图像块,重复执行步骤103-105,多次迭代训练并更新网络权重参数,直至迭代次数达到预设值,获取预先训练的全卷积神经网络。
实施例二
s1、读取每个患者的每一幅二维pet、ct图像,分别计算出suv值和hu值,调整suv值和hu值显示范围,并且调整图像分辨率,以上操作能够增强对比度。
具体地,如图3所示,举例来说,在本实施例中s1还包括:
s11、遍历读取全部91个患者的pet、ct二维图像,根据公式分别计算出suv值和hu值;
s12、增强图像对比度,调整hu值窗宽窗位,suv值限制在[0,5]范围内;
s13、调整512×512大ct图像分辨率至pet图像相同大小,即128×128。
s2、对于pe和ct经过尺寸预处理后的图像分别生成三维体数据,重新调整形状为五维数组,基于规则在三个方向上裁剪生成若干1×64×64×64×1大小的图像块用于训练和验证;
举例来说,s2具体包括:
s21、将pet、ct经过处理后的suv、hu值图像分别生成三维体数据存在ndarray中,以下称为3d图像块,体数据大小为128×128×n,其中n为对应患者pet、ct图像切片数量;
s22、根据维度[n,h,w,d,c]将三维数组重新变换为五维数组,形状为[1,128,128,28,1];
s23、对体数据进行裁剪,采样间隔为32个像素,在图像高度/宽度/深度三个方向上裁剪生成1×64×64×64×1大小的图像块;
s24、根据全部91个患者的pet、ct图像裁剪3d图像块共6084个,随机采样5237个3d图像块作为训练集,随机采样847个3d图像块作为验证集。
s3、定义同时优化图像相似性度量和正则化项形变场平滑度,其中正则化项形变场平滑度为位移矢量场矩阵中元素的一阶偏导,构建多分辨率全卷积神经网络,并调整网络结构;
举例来说,s3具体包括:
s31、定义同时优化图像相似性度量和正则化项形变场平滑度的损失函数,其中相似性度量为归一化互相关ncc和wasserstein距离,正则化项形变场平滑度为位移矢量场矩阵中元素的一阶偏导;
s32、构建多全卷积神经网络,调整网络结构。
s4、设置全卷积神经网络参数,具有的包括以下参数:输入图像大小、训练batch_size、正则化项权重λ、迭代次数、网络学习率,设置优化器并初始化权重参数,图像块归一化后输入网络中,训练网络,保存模型权重;
举例来说,s4具体包括:
s41、设置神经网络参数,其中输入图像的大小为64×64×64,训练时batch_size设置为16,正则化项权重为设置为0.5,迭代次数为设置为500,网络学习速率设置为0.001;
s42、设置神经网络优化器,并初始化权重参数;
s43、网络读入数据时将每个图像块进行归一化,变为均值为0标准差为1的正态分布;
s44、开始训练网络,迭代500次后,保存模型权重。
s5、输入待配准pet、ct图像对,通过网络进行预测,生成配准pet图像;
举例来说,s5具体包括:
s51、加载网络模型和网络权重,输入待配准图像对;
s52、得到配准后输出图像块,进行可视化。
实施例三
运行在intel内核的windows10系统环境中,基于python和tensorflow框架进行医学图像配准。如图4所示,本实施的操作步骤如下:
301、读取每个患者的每一幅二维pet、ct图像,分别计算出suv值和hu值,调整suv值和hu值显示范围,并且调整图像分辨率。
301a、遍历读取全部91个患者的pet、ct二维图像,根据ge公司给出的公式1和公式2分别计算出suv值和hu值。
公式1:suv=pixels×lbm×1000/injecteddose
其中,pixels为pet图像的像素值,lbm为瘦体重,injecteddose为注射示踪剂计量;
公式2:hu=pixels×slopes+intercepts
其中,pixels为ct图像的像素值,slopes为hu值计算公式中的斜率;intercepts为hu值计算公式中的截距;
301b、增强图像对比度,通过np.clip函数调整hu值窗宽窗位[-90,300]suv值限制在[0,5]范围内。
301c、通过cv2.resize函数调整512×512大小ct图像分辨率至pet图像相同大小,即128×128。
302、对于pet、ct经过处理后的图像分别生成三维体数据,重新调整形状为五维数组,基于规则在三个方向上裁剪生成若干1×64×64×64×1大小的图像块用于训练和验证,具体步骤如下:
302a、将pet、ct经过处理后的suv、hu值图像分别生成三维体数据存在ndarray中,体数据大小为128×128×n,其中n为对应患者pet、ct图像切片数量。
302b、根据维度[n,h,w,d,c]将三维数组通过np.reshape函数调整为五维数组,形状为[1,128,128,n,1],其中n为对应患者pet和ct图像切片数量。
302c、通过gen_3d_volume函数对体数据进行裁剪,采样间隔为32个像素,在图像高度/宽度/深度三个方向上裁剪生成1×64×64×64×1大小的图像块。
302d、根据全部91个患者的pet、ct图像裁剪3d图像块共6084个,随机采样5237个3d图像块作为训练集,随机采样847个3d图像块作为验证集。
303、定义同时优化图像相似性度量和正则化项形变场平滑度,即位移矢量场矩阵中元素的一阶偏导,获取损失函数,构建多分辨率全卷积神经网络,调整网络结构,具体步骤如下:、
303a、定义同时优化图像相似性度量和正则化项形变场平滑度的损失函数如公式3所示:
公式3:l(f,m,dv)=lsim(f,mdv)+λlsmooth(dv);
式中,lsim为相似性度量,f为ct图像块,mdv为,lsmooth为形变场的平滑度,dv为位移矢量矩阵,λ为常数;
通过公式4可知,相似性度量lsim包括归一化互相关ncc部分和wasserstein距离emd部分;
公式4:lsim=ncc+emd;
其中,ncc表示归一化互相关,emd为wasserstein距离;
公式5:
t表示模板,s表示子图,s(r,z)表示模子图的像素值,t(r,z)表示模板图像素值,e(s)表示子图的平均灰度,e(t)表示模板的平均灰度,r和z均为常数,r和z均为坐标索引;
公式6:
p表示一幅图像的特征,q表示另一幅图像的特征,dij表示两个图之间的距离,fij表示p和q特征权重总和的最小值,m和n均为常数;
wpi表示p的权重,wqj表示q的权重;
用于进行失真校正的正则化项形变场平滑度lsmooth为位移矢量场矩阵中元素的一阶偏导如公式7所示:
公式7:
其中,ω为位移矢量矩阵空间,p为当前位移矢量矩阵,dv为位移矢量矩阵,
303b、构建多分辨率全卷积神经网络,调整网络结构。
304:设置神经网络参数,包括:输入图像大小、训练batch_size、正则化项权重λ、迭代次数、网络学习率,设置优化器并初始化权重参数,将3d图像块归一化后输入网络中,训练网络,保存模型权重,具体步骤如下:
304a、设置神经网络参数,其中输入图像的大小image_size为64×64×64,训练时batch_size为16,正则化项权重λ为0.5,迭代次数epoch_num为500,网络学习速率learning_rate为0.001。
304b、通过设置神经网络优化器,并初始化权重参数。
304c、网络读入数据时将每个图像块进行归一化,根据公式8变为均值为0标准差为1的正态分布。
公式8:
式中,μ为均值,σ为标准差。
304d、开始训练网络,迭代500次后,保存模型权重。
305、输入待配准pet、ct图像对,通过网络进行预测,生成配准后pet图像,具体步骤如下:
305a、加载网络模型和网络权重,输入待配准图像对;
305b:得到配准后输出图像块,进行可视化。
本发明利用全卷积神经网络实现端到端的的多分辨率的弹性配准,本发明通过多目标优化来进行不同分辨率下的空间变换,即同时结合ct图像和配准图像对之间的相似性度量以及限制形变场平滑度,从而限制图像的过度形变;本发明计算量小,配准效率高。
最后应说明的是:以上所述的各实施例仅用于说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述实施例所记载的技术方案进行修改,或者对其中部分或全部技术特征进行等同替换;而这些修改或替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围。
- 还没有人留言评论。精彩留言会获得点赞!