一种基于上下文信息的非线性拓展的人脸幻构方法与流程
本发明涉及图像识别技术,尤其涉及一种基于上下文信息的非线性拓展的人脸幻构方法。
背景技术:
超分辨率在各种实际应用中扮演着重要的角色,例如遥感、医学成像和视频监控。人脸幻构是一种典型的超分辨率算法,它是指从单个或多个低分辨率(low–resolution,lr)图像中恢复出一个高分辨率(high–resolution,hr)图像。
从如何对映射函数进行建模,可以将人脸超分辨率算法分为两类:线性方法和非线性方法。
线性方法假设每个输入图像可以通过字典原子的线性组合来表示,或者直接使用lr和hr关系的线性回归。wang等提出了一个全局线性模型来表示特征脸空间中的lr图像。虽然线性方法简单有效,但线性假设限制了训练数据中先验信息的表达能力。非线性方法使用虚拟的非线性方法来模拟lr和hr关系,以克服线性方法的局限性。许多使用非线性方法的超分辨率算法取得了很好的效果。最近,深度学习为超分辨率任务提供了一个端到端的学习模型。深层网络结构通过非线性方法描述图像特征。dong等人首先提出了利用非线性映射进行超分辨率的卷积神经网络。kim等人通过深度残差网络,利用递归子网络单元来准确表示图像。ledig等利用对抗生成网络渲染图像的逼真度。
上述的人脸幻构方法达到了良好的重建效果。然而,这些方法有两个缺点:首先,以上方法在重建时优先考虑位置信息,而忽略图像中的上下文信息和成像的非线性本质。其次,基于深度学习的方法具有非线性表示能力,但训练网络是依赖硬件(gpu)并且非常耗时。基于上下文信息块的启发,我们提出了一种简单有效的上下文信息的非线性扩展方法,以获得更好的重建性能。通过高斯核函数将原始数据扩展到高维核空间,然后使用协作表达约束来表示上下文信息。最后,在残差域重建hr图像。
我们所提出的非线性方法易于实施,且其性能优于一些基于深度学习的方法。通过描述lr和hr图像之间的复杂关系,以探索准确的高频信息。我们提出的上下文信息非线性拓展是与深度学习不同的非线性表示方法。在本文中,和基于位置块的方法相比,我们提出的方法能够利用上下文块提供更多的非局部信息,而且,在残差域也会比像素域具有更好的表示能力。
技术实现要素:
本发明要解决的技术问题在于针对现有技术中的缺陷,提供一种基于上下文信息的非线性拓展的人脸幻构方法。
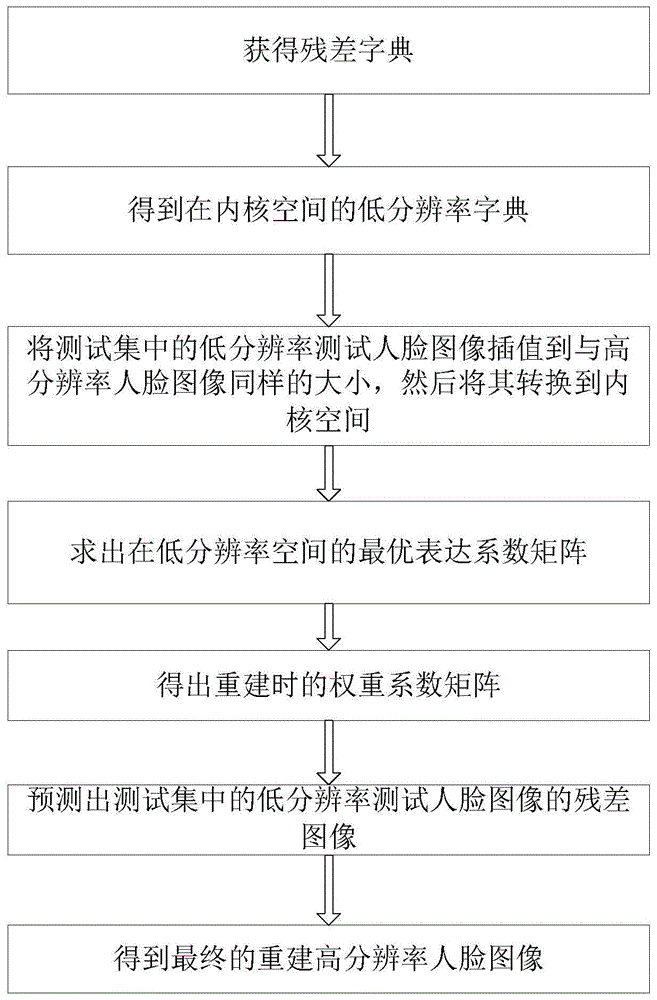
本发明解决其技术问题所采用的技术方案是:一种基于上下文信息的非线性拓展的人脸幻构方法,包括以下步骤:
s1,根据训练集中的高分辨率人脸图像获得残差字典:对训练集中的高分辨率人脸图像进行加模糊下采样得到对应的低分辨率人脸图像,再将低分辨率人脸图像插值到与原高分辨率人脸图像同样的大小后,对高分辨率人脸图像和低分辨率人脸图像通过上下文块对上下文信息进行重叠取块,形成相应的上下文hr字典
和上下文lr字典
然后将高分辨率字典减去低分辨率字典得到残差字典;
s2,运用高斯核函数,将低分辨率字典转换到内核空间,得到在内核空间的低分辨率字典
s3,将测试集中的低分辨率测试人脸图像插值到与高分辨率人脸图像同样的大小,然后对插值后的低分辨率测试人脸图像进行取块后,运用高斯核函数,将其转换到内核空间,使测试图像和训练样本保持在同一空间;
步骤s2提到的
s4,对于对插值后的低分辨率测试人脸图像,使用协作表达和设置阈值求出在低分辨率空间的最优表达系数矩阵;
s5,根据流形一致性假设,将低分辨率协作表达系数保持在高分辨率空间,也即是高低分辨率空间的表达系数相同,得出重建时的权重系数矩阵;
根据线性可分的情况,我们把数据分为线性空间和非线性空间(内核空间);根据流形学习分析,我们把图片分为高分辨率空间和低分辨率空间;
s6,利用步骤s5得到的重建系数矩阵和步骤s1得到的残差字典进行线性组合,预测出测试集中的低分辨率测试人脸图像的残差图像;
s7,将插值后的低分辨率测试人脸图像与步骤s6得到的残差图像相加得到最终的重建高分辨率人脸图像。
按上述方案,所述步骤s4中低分辨率图像的表达系数表示如下:对于输入的图像块yi,低分辨率图像的表达系数:
αi=(g+λi)-1f(·,yi);
其中,f(·,yi)=[f(l1,yi),…,f(lk,yi)]t表示通过核函数建立测试样本与表达字典之间的非线性关系,低分辨率字典
按上述方案,所述步骤s4中采用如下公式通过一个阈值k来确定lr字典
其中,
按上述方案,所述步骤s3)中使测试图像和训练样本保持在同一空间采用方法具体如下:
将每个输入的低分辨率图像块
本发明产生的有益效果是:本发明提供了基于上下文信息的非线性拓展的人脸幻构方法,所提出的非线性方法易于操作,其性能优于一些基于深度学习的方法。比起基于位置块的方法,上下文的残差学习方法被证实具有较好的重建能力。增强的性能来自于上下文信息,这些信息总是包含更多的非局部信息和残差学习,这些信息总是比像素域的方式具有更好的表达能力。
附图说明
下面将结合附图及实施例对本发明作进一步说明,附图中:
图1是本发明实施例的方法流程图;
图2是本发明实施例的的实验结果对照图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
如图1所示,一种基于上下文信息的非线性拓展的人脸幻构方法,包括以下步骤:
步骤1,低分辨率训练库中包含低分辨率人脸样本图像,高分辨率训练库中包含高分辨率人脸样本图像。其中,低分辨率人脸样本图像是对高分辨率人脸图像进行加模糊下采样得到的对应的低分辨率人脸图像,我们将低分辨率人脸图像插值到与高分辨率人脸图像同样的大小后,对高分辨率人脸图像和低分辨率人脸图像通过上下文块对上下文信息进行重叠取块,形成相应的高分辨率字典和低分辨率字典后,然后将高分辨率字典减去低分辨率字典得到残差字典。
本实施例中采用的是cas-peal-r1脸部数据库,选择了1000张图片作为训练样本,其余40张图片进行测试。hr图像的大小为128×112像素。从相应的hr图像(比例因子t=4)采样下来的lr图像通过加模糊形成(模糊的内核是4像素),因此lr的脸图像的大小32×28像素。
实例中,在训练样本人脸图像时,对用插值处理的低分辨率人脸图像通过上下文块对上下文信息进行抽样,我们定义的上下文块的大小
实例中,对高分辨率的图像也进行重叠取块采样得到对应的上下文信息块后形成高分辨率字典,每个输入图像块
再用如下公式得到残差字典:
步骤2,运用高斯核函数,将低分辨率字典转换到内核空间,得到在内核空间的低分辨率字典(表达字典)。定义内核函数
f(yi,lj)=exp(-τ||yi-lj||2)(3)
上式中,τ是一个标量参数和lj是lr字典原子在相应的
步骤3,将低分辨率测试人脸图像加模糊,再插值到与高分辨率人脸图像同样的大小,然后对其进行取块后,运用高斯核函数,将其转换到内核空间,使测试图像和训练样本保持在同一空间。每个输入的低分辨率图像块
步骤4,对于低分辨率的测试样本,使用协作表达和设置阈值求出在低分辨率空间的最优表达系数矩阵。对于输入yi,采用如下公式通过一个阈值k来确定lr字典
其中,λ是平衡非线性稀疏表达的参数,αi[j]代表αi的第j个权重系数和ck(yi)表示离yi最近的k个字典原子以及相应的重建字典
通过求解方程(4)可以得到低分辨率空间的表达系数:
αi=(g+λi)-1f(·,yi)(5)
步骤5,依据流形一致性假设,将低分辨率协作表达系数保持在高分辨率空间,也即是高低分辨率空间的表达系数相同,得出重建时的权重系数矩阵
步骤6,将残差字典中与权重系数矩阵进行重建得出残差人脸图像;通过以下公式重建残差图像:
步骤7,输出目标高分辨率人脸图像。通过以下公式输出目标高分辨率图像:
其中
测试实例我们在caspeal-r1人脸数据库中选择1000张图片作为训练样本,其余40张图片进行测试。高分辨率图像的大小为128×112个像素。将每张高分辨率图像4倍下采样得到32×28的低分辨率的图像。在这里,我们将低分辨率图像图像插值到与高分辨率图像同样大小。我们设置的图像块大小为12×12个像素,4个像素重叠。所有实验都在相同条件下进行比较。
用公式(1)(2)做数据准备,用公式(3)来转换空间,将低分辨率字典转换到内核空间,得到在内核空间的低分辨率字典(表达字典),至此,字典学习完毕,重建过程转化为求解表达系数。
然后将低分辨率测试人脸图像加模糊,再插值到与高分辨率人脸图像同样的大小,然后对其进行取块后,运用高斯核函数,将其转换到内核空间,使测试图像和训练样本保持在同一空间,用公式(4)求出低分辨率空间的最优表达系数矩阵,依据流形一致性假设,将低分辨率协作表达系数保持在高分辨率空间,也即是高低分辨率空间的表达系数相同,得出重建时的权重系数矩阵。用公式(6)重建残差图像,用公式(7)输出目标高分辨率图像。
本发明与其他的一些先进的超分辨率算法不同,以下提供实验对比说明本方法的有效性。
实验通过psnr和ssim评价图像重建性能作为算法标准。实验结果对比如下表所示:
表一不同方法的平均psnr和ssim值
从以上表格明显看出,与lsr、wsr、lle、lcr、clne和tlcr,以及深度学习算法(srcnn,vdsr)相比,本发明算法的psnr和ssim均高于其他算法。
图2为不同算法的实验结果图。从左到右依次为:lr输入;lsr;wsr;lle;lcr;clne;tlcr;srcnn;vdsr;our和hr图片。
应当理解的是,对本领域普通技术人员来说,可以根据上述说明加以改进或变换,而所有这些改进和变换都应属于本发明所附权利要求的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!