一种基于RDF推理进行测试用例约简的方法与流程
本发明给出了一种测试用例约简的方法,主要利用rdf推理机制找出页面元素间的隐含关系,并生成rdf图,对照rdf图与已生成的测试用例,对已经生成的测试用例进行约简,从而生成覆盖面广的测试用例。
背景技术:
随着科学技术的不断发展,以计算机硬件为载体、软件为灵魂的计算机应用已经渗透到各行各业,在为人们提高工作效率、工作质量和改造传统产业中起着越来越重要的作用。科学迅速发展,给人们的生活带来了极大的便利的同时,也带来了安全问题。软件质量问题和软件产品生产率低下等问题越来越受到人们高度重视,并已经成为制约计算机应用产业发展的瓶颈。当前,软件质量已经严重影响着人们的生活、学习和工作,并日益成为影响社会生产力发展的重要因素,对信息产业和国民经济发展有着极为明显的推动作用。
为保证软件的质量,需要对软件进行充分的测试,然而在软件测试中,穷尽测试时不可能的,也没有必要,因此如何选取少量的测试用例,进行高效的测试一直是个备受关注的问题。选择好的测试用例不仅能减少软件测试的工作量,而且能够降低测试成本,因此测试用例的选择至关重要。
首先对测试需求进行,根据各种测试需求生成一系列测试用例,然后对生成的测试用例集进行约简操作,最终获得精简的测试用例,达到数量既少,价值又高的要求。目前常用的约简技术有贪心算法、启发式算法和整数规划方法等。
为了能够对测试用例集进行约简,贪心算法每次从测试用例集中选择一个尽可能满足多个测试需求的测试用例,直到最后满足所有的测试需求为止。m.j.harrold等提出一种根据测试用例的重要性来选择测试用例的启发式方法;在贪心算法和m.j.harrold等提出的启发式算法的基础上,人们又提出一种将这两种方法进行有机结合的新方法。这种方法首先选出必不可少的重要测试用例,然后利用贪心算法选出能多地满足未被满足的测试需求的测试用例。t.y.chen和m.f.lau在这些算法的基础上提出一个新的测试用例集简化的启发式算法,在这个算法中不仅结合了贪心算法、m.j.harrold等提出的启发式算法的优点,而且充分考虑了剔除1-1冗余策略,并用仿真方法研究这几种算法的性能,给实际使用这几个算法提供了一些参考和指导,不过这些方法不能保证产生的结果是优的。j.g.lee和c.g.chung提出了一种将原问题转化为整数规划问题,利用整数规划方法求优解的方法,可以保证选出的测试用例集是原测试用例集优的约简。
rdf推理机制主要是利用一些已有的推理原则对已有的rdf资源之间的关系进行推理,并且推理规则可根据原型的需要进行自定义,从而找出资源间隐含的数据关系,生成关系更全面的rdf图,再根据rdf图生成测试用例的原理,对已生成的测试用例进行约简,去除不需要的测试用例,增加满足新关系的测试用例,保证最终的测试用例能够全面的覆盖测试需求。
技术实现要素:
技术问题:本发明提出了一种基于rdf推理的测试用例约简的方法。该方法将初始的rdf图根据推理规则进行推理,找出rdf图中数据之间的隐含关系,依据关系丰富的rdf图对已经生成的测试用例进行约简,最终生成能够满足测试需求的精简测试用例集。该方法可以找出数据之间隐含的关系,可以生成更全面的测试用例,最终给出精简的测试用例。
技术方案包括以下步骤:
步骤1)预处理步骤:首先从含有rdfa信息的html源代码中提取出对应的rdfa信息,并根据其xml文档,生成rdf图。
步骤2)owl建模:首先分析rdf的xml文档,分析其中的元素类型及元素间的关系,其次,分析owl建模所需的信息,再将之前分析的信息进行扩充与完善,最后,更具完善的信息,利用工具进行owl建模。
步骤3)初步推理:首先利用步骤2已经建好的owl模型,添加完备的属性信息,利用简单的推理工具进行初步推理,进行关系的简单完善。
步骤4)进一步推理:首先分析源代码中元素间的联系,尽可能找出元素间的所有关系其次,分析已有的规则库,了解大概的推理规则数量与内容,更具模型特点进行编写查找规则的代码,最终实现推理。并根据推理后信息进行rdf图完善。
步骤5)测试用例约简:将已生成的测试用例与完善的rdf图进行对比,根据rdf图生成测试用例的原理:每一条路径即为一个测试用例的规则,对之前的测试用例进行增删改操作,删除没有价值的测试用例,增加没有的测试用例,因此生成覆盖范围广的测试用例集。
有益效果
本发明对比已有技术具有以下显著创新点及优点:
(1)rdf的信息提取,rdfa直接添加在html源代码中不影响页面的显示,需要rdf信息时只要直接提取html中的rdf信息即可,减轻负担,提高效率。
(2)owl建模,rdf表示的数据间的关系是有限的,owl能够更完整的描述数据间的关系,弥补了rdf的缺陷,可以推理出更多的关系。
(3)jena提供了更全面完整的推理规则,而且可以自定义推理规则,更有扩展性,可以更全面的推理出数据间的隐含关系。
(4)虽然rdf图生成测试用例的方法可以生成一系列的测试用例,但所有的测试用例都是基于数据间有直接的关系而产生的,如果推理规则不够全面就会导致产生的测试用例覆盖的范围不够广,因此使用rdf图进行测试用例的约简可以对产生的测试用例进行查漏补缺,会让之前的测试用例更加完善,提高测试质量。
附图说明
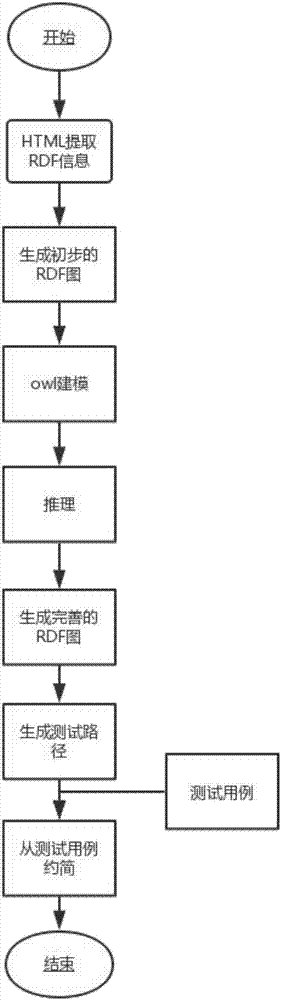
图1为整体流程图;
图2为测试用例约简流程图。
具体实施方式
以下结合附图具体说明本发明技术方案(如附图1,2所述)
一种基于rdf推理进行测试用例约简的方法,从页面的html源代码开始,利用工具提取出rdfa的信息并保存为xml文件,生成rdf图,分析页面元素间的关系,利用jena工具进行推理,生成关系完善的rdf图的同时生成测试路径,与之前的测试用例进行对比,进行测试用例的增删改,最终得到满足测试需求的精简测试用例集。图1给出了本发明方法的整体流程,具体实现步骤如下:
所述步骤1的具体步骤为:
步骤1.1,源代码进行分析,提取rdf的信息
通过使用工具或自己编写将源代码中的rdfa信息提取出来,保存为xml文件。
步骤1.2,画出rdf图
所述步骤2的具体步骤为:
步骤2.1,owl类建立
根据owl文件中的类,在工具(工具为protégé)中建立对应的类,并将各个类之间的属性添加完整,如互斥,子类等关系。
步骤2.2,属性建立
根据owl文件分析模型中所涉及的属性,分析属性间是否有从属关系等,进行属性建立,同时添加各属性的相关约束,如eat与eated是互逆的,is-part-of属性具有传递性等。
步骤2.3,类与属性关系建立
查看xml文件,将每个类之间的关系通过属性连接起来,比如有植物和动物两个互斥的类,植物和动物两个大类中有树叶和草食性动物等子类,食草性动物通过吃这个属性将树叶这个类连接,这样就完成了某个关系的建立。而owl模型就是由一系列关系组成的。
所述步骤3的具体步骤为:
步骤3.1,初步推理
在protégé中导入reasoner工具,进行初步的推理,并且生成通过初步推理的关系图。
步骤3.2,owl模型导出
将初步推理后的owl模型的文件保存导出。
所述步骤4的具体步骤为:
步骤4.1,推理规则
准备推理规则。
步骤4.2,推理
首先利用jena进行推理的java代码编写,结合步骤4,1准备的推理规则,进行推理。
步骤4.3,xml文件完善
将推理出的结果以xml文件的格式添加到步骤1中的xml文件中。
步骤4.4,rdf图完善
根据完善的xml文件画出关系完善后的rdf图
所述步骤5的具体步骤为:
步骤5.1,测试路径
分析rdf图中的连线关系图,对连线进行标号,采用rdf图生成测试用例的原理,根据rdf关系图生成所有的测试路径。
步骤5.2,测试用例增删改
将事先生成的测试用例与步骤5.1生成的测试路径进行比对,对之前生成的测试用例进行增删改,删除不合理的测试用例,增加按照路径生成的测试用例,最终生成一个覆盖范围广,数量少的测试用例集。
- 还没有人留言评论。精彩留言会获得点赞!