一种用于卷积神经网络加速器的拆分累加器的制作方法
本发明涉及神经网络计算领域,并特别涉及一种用于卷积神经网络加速器的拆分累加器。
背景技术:
深度卷积神经网络已经在机器学习应用中取得了重大进展,例如实时图像识别、检测和自然语言处理等。为了提高准确性,先进的深度卷积神经网络(dcnn)架构拥有复杂的连接和大量的神经元和突触,以满足高精度和复杂的任务的需求。卷积运算时,权重与对应的激活值相乘,最后把积加起来求和。即权重和激活值构成一对。
鉴于传统通用处理器架构的局限性,许多研究人员提出了针对现代dcnn的特定计算模式的专用加速器。dcnn由多个层组成,从几十层到几百层,甚至上千层。在整个dcnn中近98%的计算来自卷积操作。卷积作为影响功率和性能的最主要因素。在不损害学习模型的稳健性的情况下提高卷积的计算效率,成为加速dcnn的有效方法,尤其是在资源有限和有低功耗需求的轻量级设备(如智能手机和自动机器人)上。
为了解决这一挑战,一些现有方法利用定点乘法可以分解为一系列单比特乘法并移位相加的特点,提出在执行mac时使用比特位级串行。然而,基本位(或1)可能出现在定点数的任何位置,因此这种方案必须将位“1”的最坏情况的位置考虑在内,如果是16位定点数(fp16)需要使用16位寄存器保存基本位(“1”)的位置信息。不同的权重或激活值可能在加速过程中产生不同的等待时间,因此产生不可预测的周期。硬件设计必然会覆盖最坏情况,只能将最坏情况的周期作为加速器的周期,不仅会增大处理周期,减小加速器的频率,还会增加设计复杂性。
为了加速这种操作,经典的dcnn加速器通过在每个激活值和权重通道上部署乘法器和加法器,进行乘加操作。为了在加速和准确度之间达到平衡,乘法可以是浮点32位操作数,或者16位定点数和8位整型数。与定点数加法器相比,乘法器决定了卷积操作的延迟,8位定点的2操作数乘法器所需时间是加法器的3.4倍。并且不同的dcnn模型所需精度不同,甚至在同一个模型的不同层都有不同的精度需求,因此为卷积神经网络加速器设计的乘法器必须能够覆盖最坏情况。
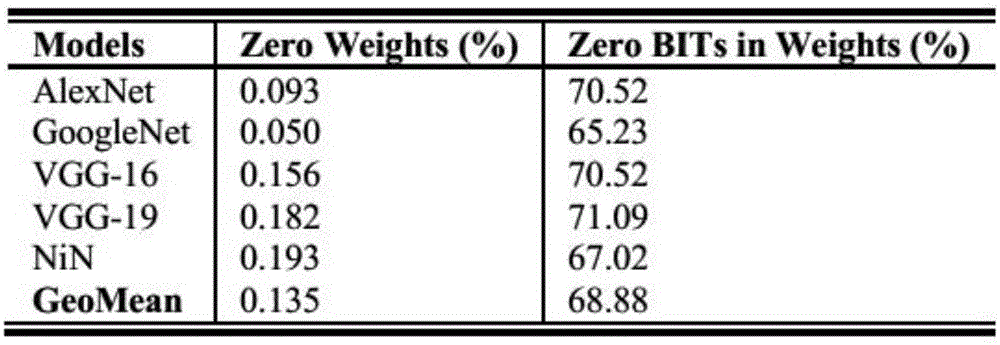
经典dcnn加速器主要部件是乘加器,而乘加器的主要问题是会进行无效运算,无效计算可以表现在两个方面:首先操作数是有很多零值或包括大部分零比特的值。与零位相比,零值在权重中占据了一小部分。这些小部分0可以通过先进的微架构设计或内存级压缩技术轻松消除,并作为输入避免使用乘数。图1显示,与基本位(或1)相比,零位的平均比例高达68.9%。其次乘加运算的中间结果是无用的,例如,y=ab+cd+de,我们只需要y的值,而不需要ab的值。这意味着优化零位和乘加运算将有助于计算效率、降低功耗。
有很多人利用量化技术加速计算。例如,将权重转换为二值,或更精确的三值。因此乘法运算可以转换为纯移位或加法操作。然而,这样做必然会牺牲结果的精度,尤其是在大型数据集中这些方案精度损失非常严重。因此,发明高精度的加速器是非常有必要的。
传统的cnn将每个权重/激活值对都放入处理单元(pe)中,并在一个周期内完成乘加操作,然而无法避免计算零比特。如果我们可以减少无效计算的时间,那么pe的吞吐量将得到提升。本发明将pe中包含“0”比特的位称为“松弛位”。
基本位(或1)的分布有两个特性:(1)在每个位置约为50%~60%的概率是有效的,这也意味着40%~50%的概率是松弛的。(2)某些权重大部分的比特位是松弛。例如,第3~5位仅少于1%的基本位。这些位几乎全部由松弛位组成,但乘法器在执行乘加操作时不会将松弛位和基本位区分开来。如果想要改善卷积操作执行效率,必须利用松弛位。
如果先前权重中的松弛位可以被后续权重的基本位替代,就可以减少无效计算,并在一个周期中处理多个权重/激活值对。挤压这些权重,总权重可压缩到其初始体积的近一半。换句话说,可以减少50%的推理时间。然而,实现这一目标将是很困难的,因为需要修改现有的mac计算模式并重新构建硬件架构以支持新的计算模式。
技术实现要素:
为了解决上述技术问题,本发明目的在于提供一种用于卷积神经网络加速器的拆分累加器,包括权重捏合技术,用于卷积神经网络加速器。权重捏合改善了现代dcnn模型中普遍存在的零位松弛。与数据压缩或修剪不同,它减少了权重的数量而没有精度损失。
具体来说,本发明公开了一种用于卷积神经网络加速器的拆分累加器,其中包括:
权重捏合模块,用于获取多组待运算的激活值及其对应的原始权重,将该原始权重按计算顺序排列并按位对齐,得到权重矩阵,剔除该权重矩阵中的松弛位,得到具有空位的精简矩阵,并使得该精简矩阵的每一列中的基本位按该计算顺序递补该空位,得到中间矩阵,剔除该中间矩阵中的空行,并将该中间矩阵的空位置0,得到捏合矩阵,该捏合矩阵的每一行作为捏合权重;
拆分累加模块,用于根据激活值与原始权重中基本位的对应关系,得到该捏合权重中每一位对应激活值的位置信息,将该捏合权重按位分割为多个权重段,根据该位置信息,将该权重段与对应的激活值进行求和处理,并将处理结果发送至加法树,通过对该处理结果执行移位相加,得到输出特征图。
所述的用于卷积神经网络加速器的拆分累加器,还包括分离器和段加法器,该分离器用于对该捏合权重进行按位分割,该段加法器用于对该权重段与对应的激活值进行求和处理。
所述的用于卷积神经网络加速器的拆分累加器,其中该拆分累加模块包括:利用哈夫曼编码保存该捏合权重中每一位对应激活值的该位置信息。
所述的用于卷积神经网络加速器的拆分累加器,其中该激活值为图像的像素值。
本发明的技术进步包括:
1、通过本发明的捏合权重和激活值的方法,以及解析运算捏合值的方式,可实现减少存储并加速运算速度;
2、俄罗斯方块加速器架构,包括sac的结构和分离器的结构,可进一步加速卷积计算。
用vivadohls仿真两种方法得到执行时间,图2显示了dadn以及本发明提出的俄罗斯方块加速器(tetris)的两种模式的推理加速。在这里,我们观察到通过捏合权重,俄罗斯方块方法可以在fp16上实现1.30倍的加速,int8模式可以实现平均1.50倍加速。相比pra可以实现近1.15倍的加速。
附图说明
图1为一些现代深度卷积神经网络模型零值和零比特位占的比例;
图2技术效果对比图;
图3为权重捏合示意图;
图4为拆分累加器sac示意图;
图5为俄罗斯方块加速器架构图;
图6为分离器的结构图;
图7为运算器的寄存器中所存结果示意图。
具体实施方式
本发明重新构建了dcnn模型的推理计算模式。本发明使用分裂累加器(sac)来代替经典的计算模式--mac。没有经典的乘法运算,而是由一系列低运算成本的加法器代替。本发明可以充分利用权重中的基本位,由加法器、移位器等构成,没有乘法器。传统乘法器中每个权重/激活值对都进行一次移位求和运算,其中“权重/激活值”意为“权重和激活值”。而本发明对多个权重/激活值对进行多次累加,只进行一次移位相加求和,从而获得大幅加速。
最后,本发明提出了俄罗斯方块加速器,以挖掘权重捏合技术和分裂累加器sac的最大潜力。俄罗斯方块加速器由一系列分裂累加器sac单元构成,并使用捏合的权重和激活值,以实现高吞吐量和低功耗的推理计算。通过高级综合工具的实验证明了与现有技术相比,俄罗斯方块加速器达到了最好的效果。第一层的激活值就是输入,第二次的激活值是第一层的输出,以此类推。如果输入是图像,第一层的激活值就是图像的像素值。
具体来说,本发明包括:
步骤1、获取多组待运算的激活值及其对应的原始权重,将该原始权重按计算顺序排列并按位对齐,得到权重矩阵,剔除该权重矩阵中的松弛位,即将松弛位删除后变为空位,得到具有空位的精简矩阵,并使得该精简矩阵的每一列中的基本位按该计算顺序递补该空位,得到中间矩阵,剔除该中间矩阵中的空行,空行即该中间矩阵中整行均为空位的行,并将提出空行后的该中间矩阵的空位置0,得到捏合矩阵,该捏合矩阵的每一行作为捏合权重;
步骤2、根据激活值与原始权重中基本位的对应关系,得到该捏合权重中每一位(元素)对应激活值的位置信息;
步骤3、将该捏合权重送入拆分累加器,该拆分累加器将该捏合权重按位分割为多个权重段,根据该位置信息,将该权重段与对应的激活值进行求和处理,并将处理结果发送至加法树,通过对该处理结果执行移位相加,得到输出特征图。
其中,该拆分累加器包括分离器和段加法器,该分离器用于对该捏合权重进行按位分割,该段加法器用于对该权重段与对应的激活值进行求和处理。
为让本发明的上述特征和效果能阐述的更明确易懂,下文特举实施例,并配合说明书附图作详细说明如下。
图3显示了捏合权重的方法。假设将6组权重作为一批,通常需要6个周期完成6对权重/激活乘加操作。松弛出现在两个正交维度:(1)在权重内尺寸,即w1、w2、w3、w4、和w6,松弛表示任意分配;(2)松弛位也出现在权重维度,即w5,是一个全零比特(零值)权重,因此它不会出现在图3(b)中。通过捏合优化基本位和松弛位,6个mac的计算周期将减少到3个循环如图3(c)所示。本发明通过权重捏合获得w’1、w’2和w’3,但每一位都是w1~w6的基本位组合。如果允许更多权重,这些松弛位将会被基本位填充,本发明称之为“权重捏合”操作,即使用后续原始权重的基本位替代先前原始权重中的松弛位。显然,权重捏合的好处一方面是它可以自动消除零值的影响并不需要引入额外的操作。另一方面,零位也被基本位替换捏合,它避免了二维松弛的影响。然而,捏合的权重表明了当前捏合权重需要和多个激活值进行运算,而不是与单独激活值进行运算。
为了支持这种高效的计算,探索加速器架构的必要性是非常重要的,这种架构与经典mac的传统架构不同。我们使用等效移位加shift-and-add获得一个部分和,部分和不完全是一系列权重/激活值乘法的总和。因此,在计算一个捏合权重w'之后不必立即移位b位。移b位的最终和可以在捏合权重计算之后进行。b的大小是根据移位相加的原理来的。例如,激活值a有4位,权重w也有4位,分别为w1,w2,w3,w4,w1为高位,则a*w=a*w1*23+a*w2*22+a*w3*21+a*w4*20。乘以23即左移3位,乘以22即左移2位,乘以21即左移1位。因此传统乘法器每算完一个w*a都有移位相加的操作。而本发明减少了移位相加的次数,本发明的处理模式不同于传统的mac和规范位序列化方,在本发明中将其称为“sac”,sac表示“拆分和累加”。sac操作首先分割捏合的权重,引用激活值并最终将每个激活值累积到特定的段寄存器。图4显示了每个权重/激活值对的sac过程。该图仅作为sac的示例展示其概念,而在实际使用中,采用捏合权重sac,即数据先经过权重捏合,然后送入sac进行计算,多个sac组成阵列构成本发明的加速器。
图4所示的拆分累加器(sac),与mac不同,它旨在精确计算的成对乘法;它首先分割权重,根据分割结果将对于激活值在对应的段加法器中求和。在一定数量的权重/激活值对完成处理之后,执行最终的移位加(shift-and-add)操作以获得最终和。“一定数量”是由实验得出来的,与卷积神经网络模型的权重分布相关,可以根据特定模型设置比较好的值,也可选择一个折中的适合大多数模型的值。详细来说,sac是拆分累加器。数据进入之后,先经过权重捏合,权重捏合的输出作为sac的输入。分离器(spliter)是sac的一部分,权重进入sac后,先经过分离器,将权重解析(分割权重),并分配给后续的段寄存器和段加法器。然后经过加法树(addertree)得到最终结果。
sac根据所需比特长度实例化“分离器”:如果对每个权重值使用16位定点数,那么就需要16个段寄存器(图中p=16)和16个加法器,根据精度与速度要求决定定点数的位数。精度越高速度越慢,这个选择根据不同需求而定。而且不同模型对精度敏感程度也不同,有的模型8位就很好,有的模型要16位。通常,分离器负责用于将每个段分散到其对应的加法器中,例如,如果权重的第二位是基本位,激活在图中传递给s1。相同操作适用于其他位。在“分裂”这个权重后,随后的权重以相同的方式处理,因此每个权重段寄存器累加了新的激活。后续的加法器树执行一次移位相加获得最终的部分和。与mac不同,sac不会尝试获得中间部分和。原因在于真正的cnn模型,输出特征图仅需要“最终”和,即卷积核的所有通道的总和及其相应的输入特征图。尤其是当使用捏合权重时,其好处与mac相比更明显。如图3和图7所示。用mac计算6对权重和激活值,需要先计算a1*w1,然后计算a2*w2以此类推,需要6次乘法操作。而sac需要3个周期,虽然sac有读取激活值位置信息的操作,但这都是寄存器内的,耗时非常短,远远小于一次乘法操作。卷积运算最耗时的是乘法操作,本发明并没有乘法操作。而且移位操作也比mac少。虽然本发明为此牺牲了非常少的额外存储,但这种牺牲是值得的。
图5.俄罗斯方块加速器架构。每个sac单元由16个并行组织的分离器(即图6)组成,接受一系列捏合权重和激活值,由捏合步幅(ks)参数表示,相同数量的分段加法器以及后面的加法器树负责计算最终的部分和。其中俄罗斯方块指的是本发明采用的捏合过程类似俄罗斯方块的堆叠过程。
在传统的加速器设计中,成对的累加器不能提高推理效率,因为它不区分无效计算,因此即使权重的当前位为零,它仍然会计算对应权重/激活值对。因此,本发明提出的俄罗斯方块加速器,利用捏合权重,sac仅将激活值分配给分段加法器以进行累积。图5显示了俄罗斯方块的架构。每个sac单元都接受权重/激活值。具体而言,加速器由对称的sac单元矩阵组成,与节流缓冲器连接,接受来自片上edram的捏合权重。如果使用定点16位权重,每个单元包含16个分离器,组成分离器阵列。分离器根据参数ks,激活值和权重值。ks,即ks个权重捏合。有16个输出数据路径用于激活以到达每个分离器的目标段寄存器,因此它在分离器阵列和分段加法器之间形成完全连接的结构。
分离器微架构如图6所示。权重捏合技术要求分离器可以接受一组捏合权重的激活值,并且每个基本位必须是可识别的,以指示ks范围内的相关激活值。俄罗斯方块方法在分离器中使用<wi,p>来表示与特定基本位相关的激活。ks代表p位数表示的范围,即4比特的p指的是16个权重的揉捏步幅。它分配一个比较器以确定捏合权重的位是否为零,因为即使在捏合之后,某些位置也可能是无效的,即图3(c)中的w’3,这取决于ks。如果是松弛,则比较器之后的多路复用器输出零到后面的结构。否则,它将解码p并输出相应的激活值。
分离器只在必要时在节流缓冲区中获取目标激活值,并且不需要多次存储激活值。新引入的位置信息p将占用一小部分空间,但p的使用仅解码激活,并且仅由几个比特组成,即16个激活需要4比特,因此它不会在加速器中引入大量的片上资源和功率开销。
对于每个段加法器,它接收来自所有16个分离器的激活值和自本地段寄存器的值相加。中间段和存储在s0~s15寄存器中,并且一旦完成所有可相加的任务,通过“控制信号”通知多路复用器将每个段值传递给后面的加法器树。加法器树的最后一级生成最终的和,并将其传递给输出非线性激活函数,该非线性激活函数是由网络模型决定的,例如relu,sigmoid。在节流缓冲单元中,通过标记表示可加的激活/权重对的末端,将其发送给每个sac单元中检测器。如果所有标记到达结尾,则加法器树输出最终和。由于我们使用ks作为参数来控制捏合的权重,不同的通道将具有不同数量的捏合权重,因此在大多数情况下,标记可以驻留在节流缓冲器的任何位置。如果新的激活值/权重对填充到缓冲区中,则标记向后移动,因此它不会影响每个段部分和的计算。
简而言之,权重先经过捏合存至自片上edram,从edram获得捏合权重,经过sac的分离器将权重解析,并分配给后续的段寄存器和加法器。然后经过加法树得到最终结果。改最终结果就是特征图,即下一层的输入。
w’的每一位有可能对应不同的a(激活值),如果这位是‘1’需要额外开销存储这一位是对应的哪个a,如果这一位是‘0’就不用存储了。至于额外存储的位置信息(对应的是哪个a),本发明不限制编码方式,比较常用编码方式例如利用哈夫曼编码。将w’和额外存储的位置信息送入sac,sac将这些权重和激活值送入相应的运算器。
根据图3捏合权重,运算器的寄存器中结果如图7所示,然后将寄存器中结果移位相加得到最后结果。
以下为与上述方法实施例对应的系统实施例,本实施方式可与上述实施方式互相配合实施。上述实施方式中提到的相关技术细节在本实施方式中依然有效,为了减少重复,这里不再赘述。相应地,本实施方式中提到的相关技术细节也可应用在上述实施方式中。
本发明还公开了一种用于卷积神经网络加速器的拆分累加器,其中包括:
权重捏合模块,用于获取多组待运算的激活值及其对应的原始权重,将该原始权重按计算顺序排列并按位对齐,得到权重矩阵,剔除该权重矩阵中的松弛位,得到具有空位的精简矩阵,并使得该精简矩阵的每一列中的基本位按该计算顺序递补该空位,得到中间矩阵,剔除该中间矩阵中的空行,并将该中间矩阵的空位置0,得到捏合矩阵,该捏合矩阵的每一行作为捏合权重;
拆分累加模块,用于根据激活值与原始权重中基本位的对应关系,得到该捏合权重中每一位对应激活值的位置信息,将该捏合权重按位分割为多个权重段,根据该位置信息,将该权重段与对应的激活值进行求和处理,并将处理结果发送至加法树,通过对该处理结果执行移位相加,得到输出特征图。
所述的用于卷积神经网络加速器的拆分累加器,还包括分离器和段加法器,该分离器用于对该捏合权重进行按位分割,该段加法器用于对该权重段与对应的激活值进行求和处理。
所述的用于卷积神经网络加速器的拆分累加器,其中该拆分累加模块包括:利用哈夫曼编码保存该捏合权重中每一位对应激活值的该位置信息。
所述的用于卷积神经网络加速器的拆分累加器,其中该激活值为图像的像素值。
- 还没有人留言评论。精彩留言会获得点赞!