基于粘度变化的聚合工艺参数调节方法与流程
本发明属于工艺优化领域,涉及一种基于粘度变化的聚合工艺参数调节方法,特别是涉及一种基于模糊信息粒化和改进的elm的预测熔体特性粘度进而调节聚合工艺参数的方法。
背景技术:
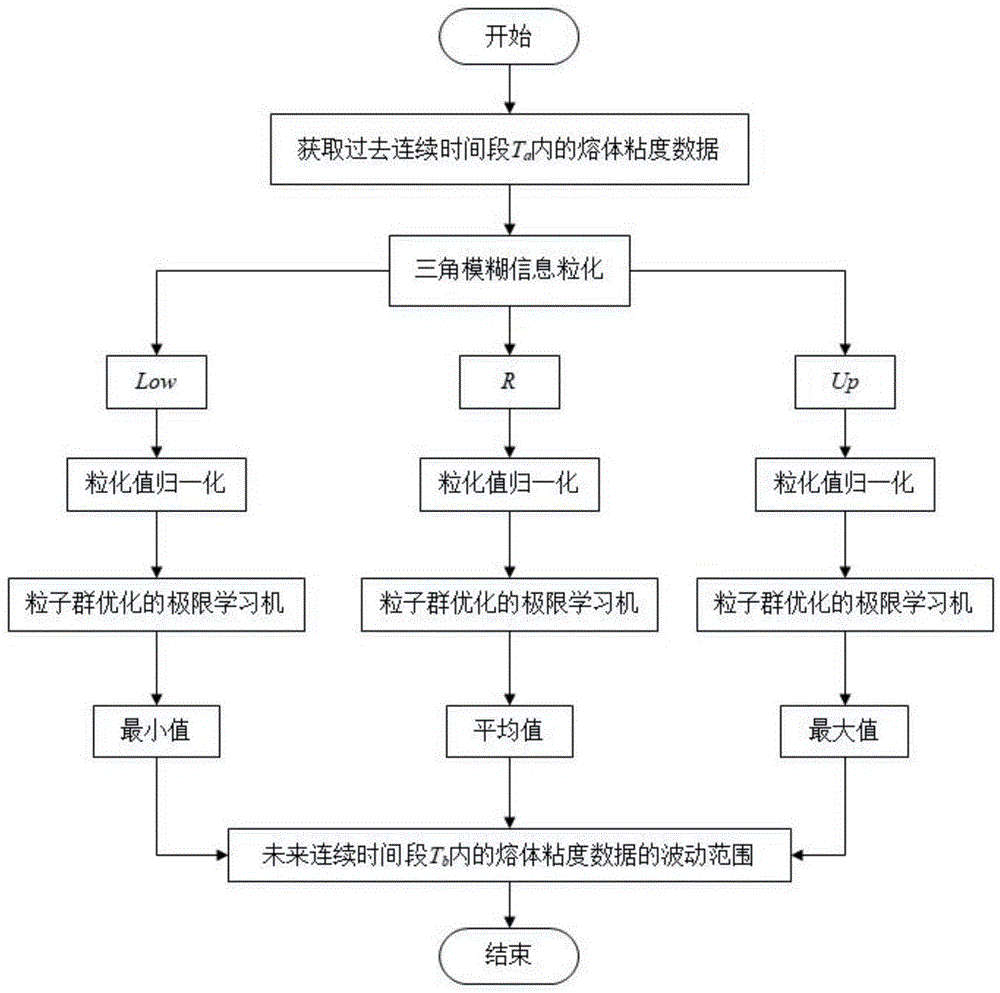
:聚酯纤维不仅弹性高、强度大,还具有良好的化学稳定性、耐磨性、拉伸性和抗折皱性,因此在民用纺织品和工业纤维品领域都有非常广泛的应用。聚合过程是聚酯纤维生产的主体和龙头,聚合过程的水平会直接影响产品的数量和质量。其中,熔体的特性粘度是直接体现聚合水平的指标。因此,对特性粘度的预测能为后续的生产环节提供一定的指导。目前,国内外相关的理论研究主要是利用反应釜的温度、压强及流量等容易测得的变量作为输入,将特性粘度作为输出,利用支持向量机或人工神经网络等方法进行静态预测。然而实际生产数据是动态的,其具有一定的时序性,因而静态预测的准确率不高。所以针对特性粘度构成的时间序列进行分析是有必要的。粘度变化预测侧重于对粘度的走向进行预测,而并不局限于某个时间点的粘度值的精确预测。如生产人员能了解聚合过程中熔体的性能指标的变化,对指导生产是十分有帮助的,可以基于粘度变化相应调整工艺参数以优化其产品品质。因此,进行粘度变化的预测就显得更有意义。而现阶段关于这方面的研究在国内外还是空白。信息粒化这一概念是由fuzzy集创始人l.a.zadeh在1979年首次提出的。l.a.zadeh认为人类的认识和推理是由三个基本概念构成:粒化、组织和因果。粒化是将整体分解成部分,组织则是综合部分成为整体,因果是指因果关系。目前,国内外主要有三种信息粒化模型:基于模糊集理论的模型、基于粗糙集理论的模型和基于商空间理论的模型。用模糊集对时间序列进行模糊粒化,主要可以分为两个步骤:窗口划分和模糊化。窗口划分就是将所给的时间序列分割成一个个的小子列,作为一个个的操作窗口;而模糊化则是将第一步产生的每一个窗口进行模糊化,生成一个个模糊集,也就是模糊粒子。这两种广义模式结合在一起就是模糊信息粒化。模糊信息粒化可以将时间序列缩小为窗口序列,应用于对变化范围的预测。传统的时序预测的方法是根据历史趋势预测未来时间序列的趋势,即通过建立相应的数学模型来拟合历史时间趋势曲线,并根据模型趋势曲线预测未来时间序列,常用的模型有自回归和移动平均模式、自回归综合移动平均模型、向量自回归模型、阈值自回归模型和自回归条件异方差模型等,但是它们只适用于处理线性或简单的非线性数据,无法应用于复杂非线性的工业生产数据;近年来随着深度学习的兴起,深层神经网络被广泛用于时序预测,但是它们的时间代价太高,硬件要求比较严格,不符合工业要求的实时性。极限学习机是一种针对单隐含层前馈神经网络的新算法。极限学习机克服了传统的前馈神经网络训练速度慢、容易陷入局部极小值点和学习率参数的选择敏感的缺点,极限学习机随机产生输入层与隐含层的连接权值及隐含层神经元的阈值,且在训练过程中无需调整,只需要设置隐含层神经元的个数,其具有易于实现、速度快和泛化能力强的优点。然而,采用随机生成初始化参数的方式促使传统极限学习机算法模型不可避免地带来了隐含层节点冗余和预测结果波动性小的缺点,阻碍了它在高精度工程和高指标实验上的应用。因此,需要选择一种智能算法对输入层权重和隐含层阈值进行优化,提高模型的预测精度。粒子群算法是一种基于群体智能的优化算法。该算法源于对鸟类捕食行为的研究,当鸟类捕食时,每只鸟找到食物最简单有效地方法就是搜寻当前距离食物最近的鸟的周围区域。其优点在于:(1)粒子群算法没有交叉和变异运算,依靠粒子速度完成搜索,并且在迭代进化中只有最优的粒子把信息传递给其它粒子,搜索速度快;(2)粒子群算法具有记忆性,粒子群体的历史最好位置可以记忆并传递给其它粒子;(3)需要调整的参数较少,结构简单,易于工程实现;(4)采用实数编码,直接由问题的解决定,问题解的变量数目直接作为粒子的维数。因此,开发一种基于模糊信息粒化和改进的elm的预测熔体特性粘度进而调节聚合工艺参数的方法极具现实意义。技术实现要素:本发明的目的是克服现有技术的不足,提供一种基于模糊信息粒化和改进的elm的预测熔体特性粘度进而调节聚合工艺参数的方法。本发明的方法将模糊信息粒化方法、粒子群算法及极限学习机有机结合起来,首先通过对采集到的特性粘度数据进行模糊信息粒化构成窗口序列,实现了区间预测;然后通过采用粒子群算法对极限学习机的输入层权值和隐含层阈值进行优化,提高了预测精度和速度;最后基于预测得到的熔体粘度调节聚合工艺参数。为了实现上述目的,本发明采用如下技术方案:基于粘度变化的聚合工艺参数调节方法,将由过去连续时间段ta内的熔体粘度数据预测得到的未来连续时间段tb内的熔体粘度数据的波动范围与参考范围进行比较后根据比较结果调节聚合工艺参数;所述预测的方法为:将过去连续时间段ta内的熔体粘度数据转化为时间序列i后对其进行模糊信息粒化处理得到三个特征向量,再将三个特征向量输入到改进elm中由其输出三个代表未来连续时间段tb内的熔体粘度数据最大值、平均值和最小值的数值,即得到未来连续时间段tb内的熔体粘度数据的波动范围;所述未来连续时间段tb的长度等于对时间序列i进行模糊信息粒化处理时窗口的大小;所述改进的elm是采用粒子群算法优化输入层权值和隐含层阈值后的elm,所述粒子群算法的适应度函数为训练样本的均方误差;所述训练样本的构建过程为:首先采集过去连续时间段tc内的熔体粘度数据构成时间序列ii,然后对时间序列ii进行模糊信息粒化处理得到三个特征向量,最后分别根据三个特征向量构建输入矩阵p和输出矩阵t得到样本集(p,t),再由样本集得到训练样本。输入矩阵p和输出矩阵t的表达式如下:t=[en+1en+2…en+1…e[m/w]];式中,el代表特征向量中第l个元素,l=1,2,...,[m/w]-n,en+l代表特征向量中第n+l个元素,[m/w]代表特征向量中元素的总个数,输入矩阵p中的第l列元素与输出矩阵t中的第l列元素构成训练样本;所述参考范围是已经生产出来的、性能满足使用要求的聚合物在连续时间段tb内的熔体粘度数据的波动范围;所述根据比较结果调节聚合工艺参数是指根据生产经验获得聚合工艺参数与熔体粘度的相关性后调节聚合工艺参数提高或降低熔体粘度进而降低波动范围与参考范围的偏差。作为优选的技术方案:如上所述的基于粘度变化的聚合工艺参数调节方法,所述熔体粘度为特性粘度,单位为dl/g;所述聚合工艺参数为终缩聚反应釜内的温度、压强和传质系数,单位分别为℃、mpa和m/s。如上所述的基于粘度变化的聚合工艺参数调节方法,所述过去连续时间段ta和过去连续时间段tc的长度为m,m大于等于15min。过去连续时间段ta和过去连续时间段tc的熔体粘度数据来源于某纤维生产工艺的聚合过程,按照每分钟的采样频率,从分散控制系统(distributedcontrolsystem,dcs)中收集得到的。如上所述的基于粘度变化的聚合工艺参数调节方法,所有的时间序列记为矩阵x,表达式为x=[x1,x2,...,xt,...,xm]t,其中,xt为第t分钟的粘度,t=1,2,...,m。如上所述的基于粘度变化的聚合工艺参数调节方法,所有的模糊信息粒化处理的步骤如下:(1)划分窗口;确定粒化窗口的大小为w,将x以每w个数据为单位长度划分为[m/w]个子列窗口,记为δxi,i=1,2,...,[m/w],[m/w]为m/w向前取整数,即如m/w的结果为整数,则[m/w]为m/w,反之,则为(m/w)+1,(m/w)代表m/w的整数部分;(2)建立模糊粒子;分别在每个子列窗口δxi上建立模糊粒子ai;(3)确定模糊粒子的参数;分别确定每个模糊粒子ai的支撑下限ai、支撑上限bi和核mi得到三个特征向量low、r和up;ai和bi的计算公式如下:mi和mi'的取值方式为:将δxi=(xi1,xi2,...,xij,...xid)按从小到大重新排序,当d为偶数时,mi=xi(d/2),mi'=xi[(d+2)/2],当d为奇数时,mi=xi[(d+1)/2],mi'=mi,记mi=x(e),mi'=x(e'),其中d表示第i个子序列中元素的个数,xij表示第i个子序列中第j个元素的值,e和e'分别表示m和m'取值时对应的下标;low、r和up的表达式如下:low=[a1,a2,...,a[m/w]]tr=[m1,m2,...,m[m/w]]t;up=[b1,b2,...,b[m/w]]t其中,low、r和up参数描述的分别是x经过模糊信息粒化后在每个子列窗口上变化的最小水平、平均水平和最大水平。如上所述的基于粘度变化的聚合工艺参数调节方法,所述模糊粒子的形式为三角型、高斯型或抛物线型,本发明中模糊粒子a的形式包括但不限于三角型、高斯型和抛物线型,优选为三角型,因为采用三角型作为模糊粒子a的形式能够得知窗口的最小值、平均值和最大值,有利于实现对特性粘度波动趋势和范围的预测。如上所述的基于粘度变化的聚合工艺参数调节方法,所述模糊粒子的形式为三角型,其隶属函数如下:式中,xi是特性粘度的值。如上所述的基于粘度变化的聚合工艺参数调节方法,所述训练样本还进行归一化处理,归一化公式如下:xrs'=(kmax-kmin)*(xrs-xrmin)/(xrmax-xrmin)+kmin;yrs'=(kmax-kmin)*(yrs-yrmin)/(yrmax-yrmin)+kmin;其中,kmax和kmin为归一化区间[-1,1]的最大值和最小值,xrs为输入矩阵p的第r行第s列的元素,xrmin和xrmax分别是输入矩阵p的第r行元素的最小值和最大值,xrs'为归一化处理后的xrs,yrs为输出矩阵t的第r行第s列的元素,yrmin和yrmax分别是输出矩阵t的第r行元素的最小值和最大值,yrs'为归一化处理后的yrs。如上所述的基于粘度变化的聚合工艺参数调节方法,所述elm的改进步骤如下:(1)粒子群算法初始化;设定种群规模、最大迭代次数、最大惯性权值、最小惯性权值、学习因子、粒子的最大速度、粒子的最小速度、最大位置、最小位置和粒子的维度d,d=(i+1)×k+(k+1)×o,i为elm输入层节点的个数,k为elm隐含层节点的个数,o为elm输出层节点的个数;(2)选择适应度函数;种群中的每一个粒子都是由elm的输入层权值矩阵和隐含层阈值矩阵两部分组成,可以根据种群的信息,采用elm对训练样本进行计算,以训练样本预测结果的均方误差作为适应度函数f,适应度函数f的表达形式如下:其中,n为训练样本的个数,tu为训练样本输入到elm后elm的实际输出值,为训练样本输入到elm后elm的理论输出值,适应度值为函数值,在训练过程中应使适应度值越小越好;(3)初始化迭代次数z=1;(4)寻找个体极值pub和群体极值pg;每个粒子根据预设的适应度函数计算各自的适应度值,并和当前的个体极值和群体极值进行比较,在pub和pg的选择中,具有较小的均方误差的粒子被选中,其计算公式如下:其中,和分别是第u个粒子的均方误差、第u个粒子最优的均方误差和所有粒子中最优的均方误差;(5)更新种群的惯性权值ω;惯性权值可以调节对解空间的搜索能力,采用更新公式使得惯性权值随着迭代次数的增加而减小,更新公式如下:其中,ωmax和ωmin分别为初始设置的最大惯性权值和最小惯性权值,z和t分别为当前的迭代次数和总的迭代次数;(6)更新粒子的位置和速度向量;进行更新时,组成粒子的所有元素的取值都要限制在区间[-1,1]内,粒子的速度和位置的更新规则如下:其中,c1和c2是学习因子,分别代表了粒子的自身学习能力和社会学习能力,rand1和rand2是区间[0,1]内的随机数,vu(z)和xu(z)分别代表当前时刻粒子的速度和位置,vu(z+1)和xu(z+1)分别代表下一时刻粒子的速度和位置;(7)判断当前迭代次数z是否达到最大迭代次数,如果是则进入步骤(9),反之,进入步骤(8);(8)令z=z+1,返回步骤(4);(9)得到最优的elm的输入层权值和隐含层偏置存在于群体极值pg中,并通过moore-penrose广义逆公式β=h+t求解输出层权值,其中,β为elm的输出层权值,t为elm的输出值,h+为隐含层输出矩阵h的广义逆计算,h=g(ax+b),a为输入层权值,b为隐含层阈值,x为样本的输入矩阵,g(·)为隐含层的激活函数。有益效果:(1)本发明的基于粘度变化的聚合工艺参数调节方法,采用模糊信息粒化能够降低样本维数,有效地将原始数据转换成窗口序列,为预测提供了样本,减小了数据处理量;(2)本发明的基于粘度变化的聚合工艺参数调节方法,采用极限学习机进行预测计算,符合工业数据的复杂非线性和实时性要求,且耗时短;(3)本发明的基于粘度变化的聚合工艺参数调节方法,采用粒子群算法寻优取代极限学习机权值和阈值随机赋值,提高了预测的稳定性、精确度和泛化性能;(4)本发明的基于粘度变化的聚合工艺参数调节方法,填补了特性粘度预测在变化趋势和空间范围这一方面的研究空白,根据特性粘度的预测结果可对聚合工艺参数进行调节以保证产品质量,极具应用前景。附图说明图1为本发明的基于粘度变化的聚合工艺参数调节方法中的预测流程图;图2为本发明采用粒子群算法优化极限学习机的流程图;图3、4和5分别为本发明low序列、r序列和up序列的预测值与真实值的对比示意图。具体实施方式下面结合具体实施方式,进一步阐述本发明。应理解,这些实施例仅用于说明本发明而不用于限制本发明的范围。此外应理解,在阅读了本发明讲授的内容之后,本领域技术人员可以对本发明作各种改动或修改,这些等价形式同样落于本申请所附权利要求书所限定的范围。一种基于粘度变化的聚合工艺参数调节方法,其步骤如下:(1)获取过去连续时间段ta内和过去连续时间段tc内的熔体粘度数据,其中过去连续时间段ta和过去连续时间段tc的长度为m,m为5000min,熔体粘度为特性粘度,单位为dl/g;(2)分别将过去连续时间段ta内和过去连续时间段tc内的熔体粘度数据构成时间序列,其中时间序列构成方法如下:将时间序列记为矩阵x,表达式为x=[x1,x2,...,xt,...,xm]t,其中,xt为第t分钟的粘度,t=1,2,...,m;(3)分别对ta和tc的时间序列进行模糊信息粒化处理得到三个特征向量low、r和up,步骤如下:(3.1)划分窗口;确定粒化窗口的大小为w,w=5,将x以每5个数据为单位长度划分为1000个子列窗口,记为δxi,i=1,2,...,1000;(3.2)建立模糊粒子;分别在每个子列窗口δxi上建立模糊粒子ai,模糊粒子ai的形式为三角型,其隶属函数如下:式中,xi是特性粘度的值,ai为ai的支撑下限,bi为ai的支撑上限,mi为ai的核;(3.3)确定模糊粒子的参数;分别确定每个模糊粒子ai的支撑下限ai、支撑上限bi和核mi得到三个特征向量low、r和up;ai、bi和mi的计算公式如下:mflag和mflag′的取值方式为:将δxi=(xi1,xi2,...,xij,...xid)按从大到小重新排序,其中代表向上取整函数,代表向下取整函数。d表示第i个子序列中元素的个数,xij表示第i个子序列中第j个元素的值。low、r和up的表达式如下:low=[a1,a2,...,a1000]tr=[m1,m2,...,m1000]tup=[b1,b2,...,b1000]t;其中,low、r和up参数分别描述的是x经过模糊信息粒化后在每个子列窗口上变化的最小水平、平均水平和最大水平;(4)构建训练样本及测试样本:(4.1)采取单步滚动预测的方式,针对tc对应的三个特征向量low、r和up,分别用前3个窗口的数据预测后面1个窗口的数据,以最小值序列low=[a1,a2,...,a1000]t为例,利用其构建得到的输入矩阵p和输出矩阵t表达形式如下:t=[a4a5a6…a1000];式中,矩阵p的第i列与矩阵t的第i列构成第i个样本,i=1,2,...,997,p与t构成样本集;(4.2)从样本集中选取75%的样本作为训练样本,余下25%作为测试样本;(4.3)分别利用r和up序列构建训练样本和测试样本,步骤同(4.1)和(4.2);(4.4)对所有的样本进行归一化处理,其中归一化公式如下:xrs'=(kmax-kmin)*(xrs-xrmin)/(xrmax-xrmin)+kmin;yrs'=(kmax-kmin)*(yrs-yrmin)/(yrmax-yrmin)+kmin;其中,kmax和kmin为归一化区间[-1,1]的最大值和最小值,xrs为输入矩阵p的第r行第s列的元素,xrmin和xrmax分别是输入矩阵p的第r行元素的最小值和最大值,xrs'为归一化处理后的xrs,yrs为输出矩阵t的第r行第s列的元素,yrmin和yrmax分别是输出矩阵t的第r行元素的最小值和最大值,yrs'为归一化处理后的yrs;(5)改进elm,改进elm的步骤如图2所示:(5.1)粒子群算法初始化;设定种群规模为100,最大迭代次数为200,最大惯性权值和最小惯性权值分别为0.8和0.4,两个学习因子都为2,限定粒子的最大速度和最小速度分别为-1和1,最大位置和最小位置分别为-1和1,粒子的维度为d=(i+1)×k+(k+1)×o,其中,i为极限学习机输入层节点的个数,k为隐含层节点的个数,o为输出层节点的个数;(5.2)选择适应度函数;种群中的每一个粒子都是由elm的输入层权值矩阵和隐含层阈值矩阵两部分组成,可以根据种群的信息,采用elm对训练样本进行计算,以训练样本预测结果的均方误差作为适应度函数f,适应度函数f的表达形式如下:其中,n为训练样本的个数,tu为训练样本输入到elm后elm的实际输出值,为训练样本输入到elm后elm的理论输出值,适应度值为函数值,在训练过程中应使适应度值越小越好;(5.3)初始化迭代次数z=1;(5.4)寻找个体极值pub和群体极值pg;每个粒子根据预设的适应度函数计算各自的适应度值,并和当前的个体极值和群体极值进行比较,在pub和pg的选择中,具有较小的均方误差的粒子被选中,其计算公式如下:其中,和分别是第u个粒子的均方误差、第u个粒子最优的均方误差和所有粒子中最优的均方误差;(5.5)更新种群的惯性权值;惯性权值可以调节对解空间的搜索能力,采用更新公式使得惯性权值随着迭代次数的增加而减小,更新公式如下:其中,ωmax和ωmin分别为初始设置的最大惯性权值和最小惯性权值,z和t分别为当前的迭代次数和总的迭代次数;(5.6)更新粒子的位置和速度向量;进行更新时,组成粒子的所有元素的取值都要限制在区间[-1,1]内,粒子的速度和位置的更新规则如下:其中,ω是惯性权值,c1和c2是学习因子,分别代表了粒子的自身学习能力和社会学习能力,rand1和rand2是区间[0,1]内的随机数,vu(z)和xu(z)分别代表当前时刻粒子的速度和位置,vu(z+1)和xu(z+1)分别代表下一时刻粒子的速度和位置;(5.7)判断当前迭代次数z是否达到最大迭代次数,如果是则进入步骤(5.9),反之,进入步骤(5.8);(5.8)令z=z+1,返回步骤(5.4);(5.9)得到最优的elm的输入层权值和隐含层偏置存在于群体极值pg中,并通过广义逆公式β=h+t求解输出层权值,其中,β为elm的输出层权值,t为elm的输出值,h+为隐含层输出矩阵h的广义逆计算,h=g(ax+b),a为输入层权值,b为隐含层阈值,x为样本的输入矩阵,g(·)为隐含层的激活函数;(6)如图1所示,将步骤(3)得到的ta对应的low、r和up输入到步骤(5)得到改进elm中由其输出三个代表未来连续时间段tb内的熔体粘度数据最大值、平均值和最小值的数值,即得到未来连续时间段tb内的熔体粘度数据的波动范围,未来连续时间段tb的长度等于ta的长度;(7)经未来连续时间段tb内的熔体粘度数据的波动范围与参考范围进行比较后根据比较结果调节聚合工艺参数,参考范围是已经生产出来的、性能满足使用要求的聚合物在连续时间段tb内的熔体粘度数据的波动范围,根据比较结果调节聚合工艺参数是指根据生产经验获得聚合工艺参数(终缩聚反应釜内的温度、压强和传质系数,单位分别为℃、mpa和m/s)与熔体粘度的相关性后调节聚合工艺参数提高或降低熔体粘度进而降低波动范围与参考范围的偏差,具体为:根据生产经验可知终缩聚反应釜内的温度和传质系数与熔体粘度正相关,压强与熔体粘度负相关,假设参考范围为[qa,za],波动范围为[qb,zb],依次比较qa、qb和za、zb的大小。如果qa≤qb且za≥zb,则说明波动范围在参考范围内,粘度值属于正常情况,无需调整工艺参数;如果qa≥qb且za≥zb,则说明波动范围超出了参考范围,粘度值低于正常值,则可以采取增大温度、增大传质系数或降低压强等措施;如果qa≤qb且za≤zb,则说明波动范围超出了参考范围,粘度值高于正常值,则可以采取降低温度、降低传质系数或增大压强等措施;如果qa≥qb且za≤zb,则说明波动范围超出了参考范围,该段时间内的粘度值既出现了低于正常值的情况,也出现了高于正常值的情况,则可以先采取增大温度、增大传质系数或降低压强等措施消除粘度值低于正常值的情况,再采取增大压强、降低传质系数或降低温度等措施。根据经验,将0.01dl/g设为粘度波动范围与参考范围的偏差单位值,则相应的工艺参数的调整单位值为15℃、0.075mpa和0.04m/s。为了验证改进elm的准确性,本发明还将由过去连续时间段tc对应的三个特征向量low、r和up得到的测试样本输入到改进elm中,由其输出预测值,并结合真实值计算均方误差mse和相关系数r1,计算公式如下:其中,n为测试样本的个数,yi为预测值,为真实值,为y、的协方差,d(y)、分别为y、的方差,计算结果如表1所示,其中low、r和up序列预测值与真实值的比较示意图如图3、4和5所示。表1评价指标测试时间mse(均方误差)r1(相关系数)low序列0.009s0.006900.88899r序列0.009s0.005220.91805up序列0.009s0.005840.91023平均结果0.009s0.005970.90576由图3~图5可以看出,本发明的预测方法所得的预测结果符合特性粘度实际的变化状态(真实值所对应的曲线),其均方误差小,相关系数较高,结合表1可以发现,本发明的基于粘度变化的聚合工艺参数调节方法对未来时刻粘度的变化预测精确,稳定性好,反应迅速,根据特性粘度的预测结果可对聚合工艺参数进行调节以保证产品质量,极具应用前景。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1