一种基于多重CCA算法的柬汉双语词向量模型构建方法与流程
本发明涉及一种基于多重cca算法的柬汉双语词向量模型构建方法,属于自然语言处理技术领域。
背景技术:
当前,双语词向量的研究工作已被研究者们广泛关注。柬汉双语词向量的构建是柬语与汉语匹配对齐工作中的重要环节,近些年来我国与东南亚地区的政治,经济交流越发频繁,柬埔寨作为东南亚地区的重要国家,其与我国之间的关系也颇为密切,所以对柬语的研究工作对于两国交流也显得十分重要。柬汉双语词向量的构建在研究柬语的工作中占有很大的地位,一个高质量的柬汉双语词向量模型可以为柬汉双语的词对齐、相似度分析、命名实体识别以及平行句对获取等工作产生很大的作用。
技术实现要素:
本发明提供了一种基于多重cca算法的柬汉双语词向量模型构建方法,用于解决当前无法直接构建柬汉双语词向量模型的问题,并且通过该方法获得的柬汉双语词向量质量较高,准确率方面有很大的提升。
本发明的技术方案是:一种基于多重cca算法的柬汉双语词向量模型构建方法,所述方法的具体步骤如下:
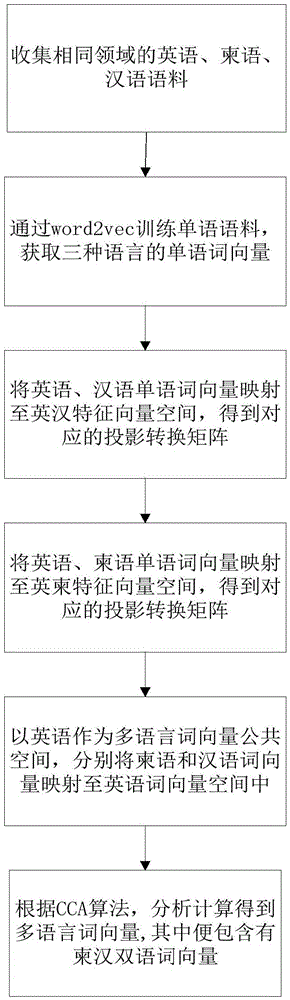
step1、获取英语、柬语、汉语词向量;
step1.1、收集相同领域柬语、英语、汉语单语语料;
step1.2、对收集到的三种语言的单语语料进行分词处理,并将三种单语语料通过word2vec进行词向量训练,分别获得柬语、英语以及汉语的词向量;
step2、将柬语和英语词向量投影至同一向量空间中,对应得到英语词向量和柬语词向量在同一向量空间中的投影转换矩阵;将汉语和英语词向量投影至另一个同一向量空间,对应得到英语词向量和汉语词向量在另一个同一向量空间中的投影转换矩阵;
step3、在上一步完成之后,以英语词向量空间作为多语言词向量公共空间,分别将柬语和汉语词向量映射至英语词向量空间中,并根据典型相关分析cca算法,分析计算投影转换矩阵之间的相关关系,得到多语词向量;多语词向量中便包含有柬汉双语词向量,进而获得柬汉双语词向量模型。
所述步骤step2中将柬语和英语词向量投影至同一向量空间中,对应得到英语词向量和柬语词向量在同一向量空间中的投影转换矩阵;将汉语和英语词向量投影至同一向量空间中,对应得到英语词向量和汉语词向量在同一向量空间中的投影转换矩阵的具体步骤如下:
step2.1、收集到的英语单语语料为15万句,汉语单语语料为10万句,柬语单语语料为5万句,由于所收集到的单语语料规模不同,因此经过第一步后得到的英语、汉语、柬语词向量规模大小并不相同,将其分别记为σ、ω以及φ,σ为英语词向量集,ω为汉语词向量集,φ为柬语词向量集;且
x′=vxy′=wy
其中v和w是σ′和ω′的投影向量;
step2.2、将英语词向量x和与其词义对应的汉语词向量y映射至同一特征空间后,根据cca算法对含有x'和y'之间的相关关系进行计算;
其中,ρ(x',y')为相关系数,cov[x',y']为x'和y'的协方差,var[x']和var[y']分别为x'和y'的方差;
cca算法将映射至同一向量空间的英语和汉语词向量之间的相关系数ρ最大化,并输出投影向量v和w,表示为
step2.3、得到σ′和ω′的投影向量v和w的表示之后,根据以上方法获取英语词向量σ与汉语词向量ω两种语言的全部词汇词向量映射至汉英同一向量空间后所得到的英语、汉语投影转换矩阵分别为v、w,表示为
v,w=cca(σ′,ω′)
其中v∈rd×d,w∈rd×d,d是投影转换矩阵v、w的秩,然后d=d1,d1的范围值100-200,由于通过cca算法得到d维度的相关性投影向量大,因此仅通过对前d1个相关维度进行原始单词词向量的投影进行工作;
step2.4、同理,令
p,z=cca(σ',φ')
其中p∈rd×d,z∈rd×d,d=d1。
所述步骤step3中以英语词向量空间作为多语言词向量公共空间,分别将柬语和汉语词向量映射至英语词向量空间中,并根据典型相关分析cca算法,分析计算投影转换矩阵之间的相关关系,得到多语词向量;多语词向量中便包含有柬汉双语词向量,进而获得柬汉双语词向量模型的具体步骤如下:
step3.1、首先将柬语词向量投影至英语词向量空间中,得到在英语词向量空间中柬语的投影转换矩阵:
其中,σ为英语词向量集,φ为柬语词向量集,
step3.2、然后将汉语词向量投影至英语词向量空间中后,两个投影转换矩阵分别为v以及w;与之前获取柬英词向量的方法相同,将汉语词向量投影至英语词向量空间后,得到汉语在英语词向量空间中的转换投影矩阵:
其中,σ为英语词向量集,ω为汉语词向量集,
step3.3、经过以上步骤得到多语词向量,多语词向量中便包含有柬汉双语词向量,进而可获得柬汉双语词向量模型。
本发明的有益效果是:本发明通过现有的方法获取单语词向量,并多次映射单语词向量,根据典型相关分析算法(cca)以英语作为中间语言,分析计算柬语词向量与汉语词向量之间的相关关系,从而得到柬汉双语词向量,生成柬汉双语词向量模型。所提出的方法有效的解决了无法直接构建柬汉双语词向量模型的问题,并且通过该方法获得的柬汉双语词向量质量较高,准确率方面有很大的提升。
附图说明
图1为本发明中构建柬汉双语词向量模型总的流程图;
图2为本发明中根据典型相关分析的双语词向量投影图。
具体实施方式
实施例1:如图1-2所示,一种基于多重cca算法的柬汉双语词向量模型构建方法,所述方法的具体步骤如下:
step1、获取英语、柬语、汉语词向量;
step1.1、收集相同领域柬语、英语、汉语单语语料;
step1.2、对收集到的三种语言的单语语料进行分词处理,并将三种单语语料通过word2vec进行词向量训练,分别获得柬语、英语以及汉语的词向量;
step2、将柬语和英语词向量投影至同一向量空间中,对应得到英语词向量和柬语词向量在同一向量空间中的投影转换矩阵;将汉语和英语词向量投影至另一个同一向量空间,对应得到英语词向量和汉语词向量在另一个同一向量空间中的投影转换矩阵;
step3、在上一步完成之后,以英语词向量空间作为多语言词向量公共空间,分别将柬语和汉语词向量映射至英语词向量空间中,并根据典型相关分析cca算法,分析计算投影转换矩阵之间的相关关系,得到多语词向量;多语词向量中便包含有柬汉双语词向量,进而获得柬汉双语词向量模型。
进一步的,所述步骤step2中将柬语和英语词向量投影至同一向量空间中,对应得到英语词向量和柬语词向量在同一向量空间中的投影转换矩阵;将汉语和英语词向量投影至同一向量空间中,对应得到英语词向量和汉语词向量在同一向量空间中的投影转换矩阵的具体步骤如下:
step2.1、收集到的英语单语语料为15万句,汉语单语语料为10万句,柬语单语语料为5万句,由于所收集到的单语语料规模不同,因此经过第一步后得到的英语、汉语、柬语词向量规模大小并不相同,将其分别记为σ、ω以及φ,σ为英语词向量集,ω为汉语词向量集,φ为柬语词向量集;且
x′=vxy′=wy
其中v和w是σ′和ω′的投影向量;
step2.2、将英语词向量x和与其词义对应的汉语词向量y映射至同一特征空间后,根据cca算法对含有x'和y'之间的相关关系进行计算;
其中,ρ(x',y')为相关系数,cov[x',y']为x'和y'的协方差,var[x']和var[y']分别为x'和y'的方差;
cca算法将映射至同一向量空间的英语和汉语词向量之间的相关系数ρ最大化,并输出投影向量v和w,表示为
step2.3、得到σ′和ω′的投影向量v和w的表示之后,根据以上方法获取英语词向量σ与汉语词向量ω两种语言的全部词汇词向量映射至汉英同一向量空间后所得到的英语、汉语投影转换矩阵分别为v、w,表示为
v,w=cca(σ′,ω′)
其中v∈rd×d,w∈rd×d,d是投影转换矩阵v、w的秩,然后d=d1,d1的范围值100-200,由于通过cca算法得到d维度的相关性投影向量大,因此仅通过对前d1个相关维度进行原始单词词向量的投影进行工作;
step2.4、同理,令
p,z=cca(σ',φ')
其中p∈rd×d,z∈rd×d,d=d1。
进一步的,所述步骤step3中以英语词向量空间作为多语言词向量公共空间,分别将柬语和汉语词向量映射至英语词向量空间中,并根据典型相关分析cca算法,分析计算投影转换矩阵之间的相关关系,得到多语词向量;多语词向量中便包含有柬汉双语词向量,进而获得柬汉双语词向量模型的具体步骤如下:
step3.1、首先将柬语词向量投影至英语词向量空间中,得到在英语词向量空间中柬语的投影转换矩阵:
其中,σ为英语词向量集,φ为柬语词向量集,
step3.2、然后将汉语词向量投影至英语词向量空间中后,两个投影转换矩阵分别为v以及w;与之前获取柬英词向量的方法相同,将汉语词向量投影至英语词向量空间后,得到汉语在英语词向量空间中的转换投影矩阵:
其中,σ为英语词向量集,ω为汉语词向量集,
step3.3、经过以上步骤得到多语词向量,多语词向量中便包含有柬汉双语词向量,进而可获得柬汉双语词向量模型。
本发明创新性地引入多次映射单语词向量以及多重cca算法这两种方法构建柬汉双语词向量模型。首先应用现有的成熟技术word2vec对英、柬、汉三种单语语料进行词向量训练,得到三种语料对应的单语词向量;其次将柬、英词向量投影至同一特征向量空间,将汉、英词向量投影至同一特征向量空间,分别得到各自的投影转换矩阵;然后以英语词向量空间作为公共词向量空间,分别将柬语和汉语词向量映射至英语词向量空间中;并根据典型相关分析(cca)算法,分析计算投影转换矩阵之间的相关关系,得到柬英以及汉英双语词向量;最终以英语作为中间语言,将同时拥有相同英语单词词向量的柬英双语词向量和汉英双语词向量匹配在一起,得到柬汉双语词向量。本发明与现有技术相比,解决了小语种语料因语料稀缺无法通过现有双语词向量模型获取双语词向量的问题,并且通过本发明提出的方法获得的柬汉双语词向量质量较高,准确率方面有很大的提升。
上面结合附图对本发明的具体实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化。
- 还没有人留言评论。精彩留言会获得点赞!