一种基于神经网络的视频图像实时去模糊方法与流程
本发明涉及一种基于神经网络的视频图像实时去模糊方法,属于图像处理技术领域。
背景技术:
信息化时代,便携成像设备在视频监控、视觉导航、车牌照自动识别、遥感、医疗以及太空探测等领域都得到了广泛的应用。成像设备在曝光时由于相机与拍摄物体之间的相对运动以及拍摄物体与相机光心距离的不合适将造成运动模糊和散焦模糊。模糊图像由于缺失了图像中的细节信息,对一些对细节要求极高的应用造成了诸多不便。所以,从模糊图像中恢复出清晰的、细节丰富的图像具有非常重要的应用价值。
目前的图像去模糊算法通常是基于图像先验信息,利用正则化技术构造图像去模糊模型,并对模型求解获得清晰的复原图像。图像的先验信息获取大体可分为两类。一类是基于统计的先验模型,另一类是通过学习方法获得。统计先验模型包括梯度重尾分布先验,归一化稀疏先验,l0正则化梯度先验等。统计先验模型的不足之处在于其对图像特征的表达不完全,图像细节恢复能力有限。基于学习的图像先验信息获取包括基于单幅图像的去模糊方法以及基于视频序列的去模糊方法。然而这些算法的计算复杂度较高,难以应用于对实时性要求高的场景。
与单幅图像的去模糊方法相比,视频序列图像去模糊算法可以利用图像的时序信息,从相邻图像中获取辅助信息,因此可以获得更好的去模糊效果。
技术实现要素:
本发明是为了克服已有的视频去模糊算法处理速度过慢或者恢复效果较差的缺陷,为实时地解决相机与拍摄物体之间由于相对运动而产生的图像模糊问题,提出一种基于神经网络的视频图像去模糊方法,该方法具有处理速度快、恢复效果好的优势。
实现本发明的技术方案如下:
一种基于神经网络的视频图像去模糊方法,具体过程为:
一、构建神经网络
构建主要由编码器、动态融合网络以及解码器组成的神经网络;
(1)编码器:编码器由两层卷积、级联层和四个单层残差结构依次堆叠而成,其中第一个卷积层将输入的图像映射到多个通道,第二个卷积层将输入的图像降采样,所述级联层中级联的图像为降采样得到的特征图和上一个去模糊阶段解码器中保存的特征图fn-1;
(2)动态融合网络:动态融合网络用于将上一个去模糊阶段自身保存的特征图与当前阶段编码器得到的特征图进行加权融合;
(3)解码器:解码器包含四个单层残差结构,所述四个单层残差结构上连接有两条分支,第一条分支上设有一个反卷积层和一个卷积层,其输出为清晰图像;第二条分支上设有一个卷积层,输出一组特征图fn;
神经网络最终输出的图像为输入图像序列的中间帧图像与解码器第一条分支输出图像相加得到的图像;
二、构造损失函数,并对神经网络进行训练;
三、利用训练好的神经网络进行视频图像去模糊。
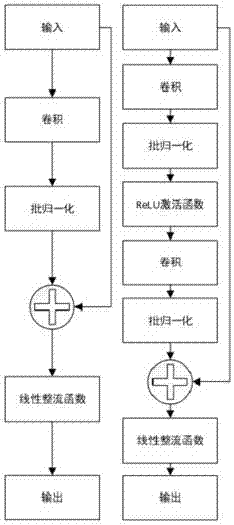
进一步地,本发明所述单层残差结构主要由卷积层,批归一化层以及线性整流函数构成。
进一步地,本发明利用感知损失作为损失函数。
与现有技术相比,本发明的有益效果为:
第一、本发明构建由编码器、动态融合网络以及解码器构成的神经网络,在动态融合网络和解码器中会各自保存一组特征图作为下一阶段的输入,通过这种方式可以利用更多临近帧的图像信息,并且可以提高感受野,从而获得更好的去模糊效果。
第二、本发明引入全局残差,整个网络只需学习清晰图像和模糊图像的残差,提升了训练速度以及最终的去模糊效果。
第三、本发明使用感知损失函数,提升了图像纹理细节的恢复效果。
第四、本发明使用单层残差结构,在对去模糊效果没有明显影响的情况下提升了去模糊速度。
利用以上改进,本发明方法能够对不同尺度的图像进行快速的去模糊,对640×480分辨率的图像可以达到每秒40帧的处理速度,并且可实现与目前最佳去模糊算法相近的效果。在ar/vr,机器人导航,目标检测等多种任务中可以得到广泛应用。
附图说明
图1为本发明实施方式的网络架构图;
图2为编码器、解码器网络层图;
图3为单双层残差结构的对比图;
图4为动态融合网络结构。
具体实施方式
下面结合附图并结合具体实现对本发明方法的实施方式做进一步详细说明。
本发明一种基于神经网络的视频图像去模糊方法,旨在借助神经网络,利用视频序列实时地解决由于相机和拍摄场景之间相对运动导致的图像模糊问题。具体过程为:
一、构建神经网络:
如图1所示,本实例构建端到端的神经网络,主要由编码器、动态融合网络以及解码器组成,各部分具体实现如下:
(1)编码器:如图2a所示,由两层卷积层、级联层和四个单层残差结构组成,其中第一层卷积层的卷积核大小为5×5、步长为1,第二层卷积层的卷积核大小为3×3、步长为2;编码器首先使用卷积核大小为5×5、步长为1的卷积层将输入图像映射到64个通道;其次使用卷积核大小为3×3、步长为2的卷积层进行降采样并将通道数降低到32;再次将得到的特征图与上一阶段解码器中保存的特征图fn-1进行级联,得到64通道的特征图;最后使用四个单层残差结构,进一步提取图像特征,输出特征图hn。
单层残差结构:在编码器和解码器之中都使用了四个单层残差结构,如图3所示,本实例使用单层残差结构,每个残差结构包含一层卷积层,卷积核大小为3×3、步长为1,通道数为64;卷积层之后接一个批归一化层以及线性整流函数。残差结构对级联之后的特征图进行卷积、批归一化处理,并使用线性整流函数作为激活函数,与传统残差结构差异如图3所示。
(2)动态融合网络:如图4所示,该结构包含级联层、卷积层、权重计算层及特征融合;所述动态融合网络将编码器输出的特征图hn与上一阶段保存的特征图
wn=min(1,|tanh(d)|+β))(2)
其中,d代表经动态融合网络中卷积层卷积后得到的特征图,β代表偏置,取值在0-1之间由神经网络训练得到,tanh()表示激活函数,符号
(3)解码器:解码器包含四个单层残差结构,所述四个单层残差结构上连着两个分支,如图2b所示。分支一依次连接两个卷积层,第一层卷积核大小为4×4,步长为1,第二层卷积核大小为4×4,步长为1;特征图
全局残差:网络使用全局残差即将输入图像序列的中间帧直接和解码器第一条分支输出的图像相加得到最终的输出图像,如图1所示,整个网络只需学习清晰图像和模糊图像的残差,从而提高了网络训练速度和最终去模糊效果。
如图1所示,在动态融合网络和解码器中会各自保存一组特征图作为下一阶段的输入,通过这种方式可以利用更多临近帧的图像信息,并且可以提高感受野,从而获得更好的去模糊效果。
二、构造损失函数
使用感知损失作为损失函数,感知损失利用已经训练好的分类网络(如vgg19,vgg16)计算图像损失,具体形式为:
公式(1)中,w,h分别代表特征图φi,j的宽和高;φi,j代表分类网络(vgg19)中的第i个池化层(分类网络里的一层,如上述提到的分类网络vgg19,vgg16)之后的第j个卷积层输出的特征图;is代表真实清晰图像;ib代表输入到网络的模糊图像;g(ib)表示网络输出的清晰图像,x,y表示像素坐标。
具体为:使用vgg19分类网络的conv3_3卷积层计算损失函数,vgg19在训练过程中参数固定,训练时将神经网络得到的清晰图像g(ib)输入vgg19得到一组特征图φ3,3(g(ib))x,y,同时将真实的清晰图像is输入vgg19得到另一组特征图φ3,3(is)x,y,然后计算两组特征图的l2范数的均方误差,即
三、训练神经网络
实验中使用tensorflow搭建神经网络,使用gopro公开数据集进行训练。训练时使用三张(bn-1,bn,bn+1)连续的图像作为神经网络的输入,bn对应的清晰图像sn作为目标图像,使用adam优化方法降低感知损失。
测试神经网络
测试时每次输入连续的三张模糊图像,输出为中间帧对应的清晰图像。经测试,本实例中的方法处理1280×720的图像每帧耗时约88毫秒,处理640×480的图像每帧耗时约25毫秒,在处理640×480的图像时可以满足实时性的要求。
四、利用训练好的神经网络对视频图像进行去模糊处理。
自此,就实现了基于视频图像序列的实时去模糊算法。
综上所述,以上仅为本发明的较佳实施例而已,并非用于限定本发明的保护范围。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!