一种基于优先级的实时ID拉通引擎方法与流程
本发明涉及大数据处理、流式处理、id拉通技术领域,尤其涉及一种基于优先级的实时id拉通引擎方法。
背景技术:
当前业内已经存在了一种用户id拉通的解决方案,但是该方案只是id拉通的最初级解决方案,它无法解决以下两个问题:
1、业务层面:现有的方案将所有相关联的id全部拉通到一起,形成一个用户的id画像,但是它并未考虑到用户的id会随着时间的推移而变化。比如,某个手机号id在三个月前属于用户a,但在现在该手机号id已经属于用户b,而按照现有的id拉通解决方案,用户a、用户b的其他id将会因为手机号id的关联关系而被拉通到一起,最终,用户a以及用户b将会被视为一个用户。
2、技术层面:现有的用户id拉通的解决方案是一个离线的解决方案,它只能t+1地展示用户的id画像,无法满足一些实时的业务场景,比如推荐系统。
技术实现要素:
本发明旨在提供一种基于优先级的实时id拉通引擎方法,以解决现有的用户id拉通方案的不足。
为了实现上述目的,本发明采用如下技术方案:
一种基于优先级的实时id拉通引擎方法,包括如下步骤:
s1、id拉通引擎从kafka中获取实时的消费行为日志数据,并从行为日志数据中提取出所有的id,然后找到mainid;每条行为日志数据中,mainid将会与除它自己之外的其它id分别建立id关系,即每条行为日志数据产出的id关系的条数为n-1,n为该行为日志数据中id的数量;
s2、根据步骤s1中生成的id关系,更新redis数据库中id关系的权重;
s3、根据id优先级由高到低的排序,逐级计算当前层级的id的superid归属的变更,并更新redis数据库中的superid归属的id列表。
进一步地,步骤s2中,所述更新redis数据库中id关系的权重采用如下两种方式中的任意一种:
1)基于共现次数更新权重:每条id关系在行为日志数据中每出现一次,则权重值提升1;
2)基于最新共现优先更新权重:使用共现时刻的系统时间戳,保证最新共现的id关系之间的权重是最大的。
进一步地,步骤s2中,更新数据库中id关系的权重时,分别更新数据库中mainid保存的与各id之间的权重,以及各id保存的与mainid之间的权重。
进一步地,步骤s3的具体过程为:
s3.1、设定优先级一共分为n级,每层的编号为0~n-1;
s3.2、先确定最高层优先级n-1中各id的superid归属;
s3.3、按照id优先级从高到低依次计算n-2至0层优先级中各id的superid归属;每层优先级中各id的superid归属按如下方式确定:
当一个待确定superid归属的id只与高于自身优先级的一个id相关联时,则该待确定superid归属的id与该高于自身优先级的一个id同属一个superid;
当一个待确定superid归属的id与高于自身优先级的两个或以上的id相关联时:如果该高于自身优先级的两个或以上的id均同属于一个superid,则该待确定superid归属的id就和该高于自身优先级的两个或以上的id同属一个superid;如果该高于自身优先级的两个或以上的id属于不同的id,则比较该待确定superid归属的id与这些高于自身优先级的id之间的权重,该待确定superid归属的id和与自身之间权重最大的那个高于自身优先级的id同属一个superid;
当一个待确定superid归属的id不与其他任一id相关联时,该待确定superid归属的id会独立成组,并单独为该待确定superid归属的id分配一个superid;
当一个待确定superid归属的id既不与任何高于自身优先级的id相关联,也不与相同优先级中其他和高层优先级id具有关联关系的id相关联,该待确定superid归属的id会独立成组,并单独为该待确定superid归属的id分配一个superid;
当一个待确定superid归属的id不与任何高于自身优先级的id相关联,但与相同优先级中其他和高层优先级id具有关联关系的id相关联时,该待确定superid归属的id和该相同优先级的id同属一个superid。
进一步地,所述方法还包括有如下步骤:
s4、产出快照数据:
假设当前时刻为t1,处理完第一批id关系之后时刻为t2,处理完第二批id关系之后时刻为t3,如此类推,处理完第n批id关系之后时刻为tn-1;t1时刻数据库中数据的状态与t2时刻数据库中数据的状态的差异,即为<t1,t2>的快照数据;t2时刻数据库中数据的状态与t3时刻数据库中数据的状态的差异,即为<t2,t3>的快照数据;tn-1时刻数据库中数据的状态与tn时刻数据库中数据的状态的差异,即为<tn-1,tn>的快照数据;
设定系统启动之前的时刻为t0,此时redis数据库中无任何数据,则保存<t0,t1>、<t1,t2>…<tn-1,tn>的快照数据。
本发明的有益效果在于:
本发明方法在实时id拉通中将id优先级、id关系、id关系权重和superid归属等结合起来,可以解决用户id随着时间推移而变化这一现实问题;同时,准实时的实现(5s内)也可以满足互联网中推荐等其它技术的实时需求。
附图说明
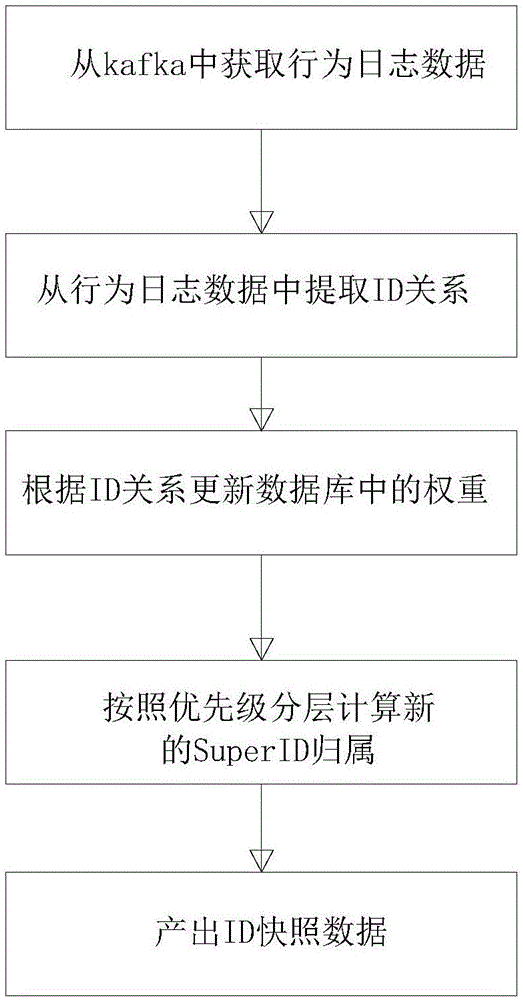
图1为本发明实施例中的方法实施流程图;
图2为本发明实施例中建立id关系的示意图;
图3为本发明实施例中更新superid归属的示意图;
图4为本发明实施例中产出快照数据的示意图。
具体实施方式
以下将结合附图对发明作进一步的描述,需要说明的是,本实施例以本技术方案为前提,给出了详细的实施方式和具体的操作过程,但本发明的保护范围并不限于本实施例。
以下先对本实施例中将涉及到的专业术语和数据格式作简单解释。
专业术语:
id:一个人的某种标识、属性。如一个手机号、设备号、身份证号等等都可以作为一个id,在业务系统中它通常和一些行为联系到一起。如通过手机号进行订餐,通过身份证号购买高铁票等等。
id优先级:不同的id类型之间是有优先级的,优先级的定义为:在业务系统中,哪类id更能代表一个用户。如银行系统中,资金账号比身份证号更能标识一个用户;通信系统中,手机号比邮箱账号更能标识一个用户。那么可以得出结论:在银行系统中,资金账号比身份证号的优先级高;在通信系统中,手机号比邮箱账号的优先级高。
id关系:如上文所述,业务系统中id常常和一些行为联系到一起,那么当一个行为中包含两个乃至多个id时,则认为这些id大概率上同属于一个人。如某人通过自己的手机使用自己的身份证号购买了高铁票,那么这个手机和身份证号即构成了一个id关系,它描述了id的共现。
id关系的权重:表示的含义是id关系的牢固程度。如当前存在一个qq,它与idcard1的id关系的权重要高于与它与其它id的id关系的权重,那么该qq与idcard1有较大可能为同一人所有。在id拉通引擎中,通过使用id关系出现的次数来标识id关系的权重;同时,也支持基于实际的业务场景定制化实现不同的权重算法。
superid:表示的含义是同一人。比如多个id同属于一个superid,代表了这些id为一个人所拥有,这个人使用该superid来标识。superid标识由id拉通程序产出,可以使用不同的算法,只需要保证不同人使用的superid标识唯一即可。当前使用的生成算法为java标准库中的java.util.uuid.randomuuid方法,它可以保证生成的字符串全局唯一,满足superid标识的唯一性约束。
mainid:在行为日志中,可能会出现多个不同类型的id,在这些id中,id优先级最高的id被称为该行为日志的mainid。id关系数据的生成便是藉由该mainid来生成的。
rootid:在一个业务系统内确认完不同id之间的id优先级之后,优先级最高的id类型被称为rootid。它包含以下特性:在业务系统中它可以唯一标识一个用户;在id拉通结果中,一个superid对应的id列表里最多只会出现一个rootid。
数据格式:
1、id与superid的字符串标识
2、id之间的关联关系
以id作为redis的key,id所属的superid以及id之间的关联关系(权重)对应的json转换成的字符串作为值。注意,下面的样例中,描述的值都是jsonobj的格式。但是为了支持id拉通代码的批量读写功能,实际在redis中存储的值是jsonobj转换成的字符串。
3、superid到id的关联关系
以superid作为redis的key,superid所包含的id列表对应的json转换成的字符串作为值。注意,下面的样例中,描述的值都是jsonobj的格式。但是为了支持id拉通代码的批量读写功能,实际在redis中存储的值是jsonobj转换成的字符串。
4、kafka数据读取的偏移量记录
5、快照数据
以下对本实施例提供的一种基于优先级的实时id拉通引擎方法作出详细描述。
一种基于优先级的实时id拉通引擎方法,如图1所示,包括如下步骤:
s1、id拉通引擎从kafka中获取实时的消费行为日志数据,并从行为数据中提取出所有的id,然后找到mainid;每条行为日志数据中,mainid将会与除它自己之外的其它id分别建立id关系,即每条行为日志数据产出的id关系的条数为n-1,n为该行为日志数据中id的数量,如图2所示;
s2、根据步骤s1中生成的id关系,更新redis数据库中id关系的权重,为后续的id到superid的归属的变更计算做准备;
具体地,更新redis数据库中id关系的权重的方式可以采用如下两种方式中的任意一种:
1、基于共现次数更新权重:每条id关系在行为日志数据中每出现一次,则权重值提升1;
2、基于最新共现优先更新权重:使用共现时刻的系统时间戳,保证最新共现的id关系之间的权重是最大的。
步骤s2中,更新数据库中id关系的权重时,分别更新数据库中mainid保存的与各id之间的权重,以及各id保存的与mainid之间的权重。通过这样的“拆分-更新”的方法,能够保证在更新数据库时可以并行执行,而不会出现缓存读写不一致的问题。
s3、根据id优先级由高到低的排序,逐级计算当前层级的id的superid归属的变更,并更新redis数据库中的superid归属的id列表。整体的计算逻辑如下伪代码所示:
id拉通引擎的拉通逻辑中引入了优先级,目的是为了实现更切合实际业务场景的拉通逻辑:
优先级较低的id的superid归属的变更不会对优先级较高的id造成任何影响;
优先级较高的id的superid归属的变更会对优先级较低的关联id造成影响。
因此,需要根据id优先级由高到低的排序,逐级计算当前层级的id的superid归属的变更。
具体过程为:
s3.1、设定优先级一共分为n级,每层的编号为0~n-1;
s3.2、先确定最高层优先级n-1中各id的superid归属;
s3.3、按照id优先级从高到低依次计算n-2至0层优先级中各id的superid归属;每层优先级中各id的superid归属按如下方式确定:
当一个待确定superid归属的id只与高于自身优先级的一个id相关联时,则该待确定superid归属的id与该高于自身优先级的一个id同属一个superid;
当一个待确定superid归属的id与高于自身优先级的两个或以上的id相关联时:如果该高于自身优先级的两个或以上的id均同属于一个superid,则该待确定superid归属的id就和该高于自身优先级的两个或以上的id同属一个superid;如果该高于自身优先级的两个或以上的id属于不同的id,则比较该待确定superid归属的id与这些高于自身优先级的id之间的权重,该待确定superid归属的id和与自身之间权重最大的那个高于自身优先级的id同属一个superid;
当一个待确定superid归属的id不与其他任一id相关联时,该待确定superid归属的id会独立成组,并单独为该待确定superid归属的id分配一个superid;
当一个待确定superid归属的id既不与任何高于自身优先级的id相关联,也不与相同优先级中其他和高层优先级id具有关联关系的id相关联,该待确定superid归属的id会独立成组,并单独为该待确定superid归属的id分配一个superid;
当一个待确定superid归属的id不与任何高于自身优先级的id相关联,但与相同优先级中其他和高层优先级id具有关联关系的id相关联时,该待确定superid归属的id和该相同优先级的id同属一个superid。
以下通过举例对每层优先级中各id的superid归属的确定方式作进一步的说明。
如图3所示,图中涉及的id包括:ida1、ida2、ida3、idb1、idb2、idb3、idb4、idb5、idb6、idb7、idc1、idc2,id优先级有三层。
其中ida1、ida2、ida3同属相同的id优先级,也是最高层的id优先级;idb1、idb2、idb3、idb4、idb5、idb6、idb7同属相同的id优先级,是第二层id优先级;idc1、idc2同属相同的id优先级,为最底层id优先级。
图中出现的id关系包括:<ida1,idb1>、<ida2,idb1>、<ida3,idb2>、<idb2,idb6>、<idb2,idb7>、<idb3,idb4>、<idb3,idc2>、<idb6,idc1>。
假设接下来要计算idb*这一层级的id的superid归属,包括:idb1、idb2、idb3、idb4、idb5、idb6、idb7。
按照拉通逻辑,当前时刻ida*这一层级的id的superid归属都已经计算完毕,即此时可以确保ida1、ida2、ida3都已经确保对应了各自的superid。
以下分别对idb*这一层级的所有id的superid归属进行重新计算:
idb1:idb1同时与高于自身优先级的ida1、ida2相关联,因此idb1属于哪个superid取决于ida1、ida2。如果当前ida1与ida2同属于相同的superid,则idb1也会归属于这个superid;如果当前ida1与ida2属于不同的superid,则需要比较权重weight(<ida1,idb1>)与权重weight(<ida2,idb1>)的大小:如果weight(<ida1,idb1>)>weight(<ida2,idb1>),则idb1将与ida1归属于同一个superid;反之,idb1将与ida2归属于同一个superid。
idb2:idb2只与高于自身优先级的ida3相关联,因此idb2将与ida3归属于同一个superid。
idb3、idb4:idb3、idb4不与任何高于自身id优先级的id相关联,也不关联于相同id优先级中其他与高于自身优先级的id有关联的id,因此它们无法通过高于自身id优先级的id确定superid的归属。这种情况下,它们将会独立成组:idb3、idb4归属于相同的superid。
idb5:idb5不与任一id相关联,因此它会独立成组:单独为idb5分配一个superid,该superid只包含idb5。
idb6、idb7:idb6、idb7不与任何高于自身id优先级的id相关联,但与等同于自身id优先级的idb2相关联,idb2通过高于自身优先级的ida3确定了superid,因此idb6、idb7将会与idb2一起归属于同一个superid。
当计算完毕,即上文伪代码描述中的recalc(cur_level_ids)计算完毕之后,将会返回affected_ids_arr,按照拉通结果,affected_ids_arr[idb*层级]的值为[idc1,idc2],即为下轮迭代时,需要重新计算superid归属的id列表。
s4、产出快照数据:
id快照数据是指在id拉通引擎获取消费行为日志后,id关系的权重变更、id到superid的归属变更的记录。快照数据产出逻辑如图4所示:
假设当前时刻为t1,处理完第一批id关系之后时刻为t2,处理完第二批id关系之后时刻为t3,如此类推,处理完第n批id关系之后时刻为tn-1;t1时刻redis数据库中数据的状态与t2时刻redis数据库中数据的状态的差异,即为<t1,t2>的快照数据;t2时刻redis数据库中数据的状态与t3时刻redis数据库中数据的状态的差异,即为<t2,t3>的快照数据;tn-1时刻redis数据库中数据的状态与tn时刻redis数据库中数据的状态的差异,即为<tn-1,tn>的快照数据;
那么当redis数据库中的数据与t1时刻保持一致时,如果有<t1,t2>的快照数据,即可得到t2时刻的redis数据库中的数据的状态;如果有<t1,t2>、<t2,t3>的快照数据,即可得到t3时刻的redis数据库中的数据的状态。
因此,设定系统启动之前的时刻为t0(redis数据库中无任何数据),那么只需要保有<t0,t1>、<t1,t2>…<tn-1,tn>的快照数据,即可恢复到tk(1<=k<=n)时刻的redis数据库中数据状态。
该部分数据是为了方便与其它业务系统对接以及数据灾备而考虑的。定期将id快照数据落入磁盘存储系统中,除了可以交给其它业务系统使用之外,还可以起到一个容灾的功能:在必要时刻进行数据恢复工作。
使用本实施例所提供的一种基于优先级的实时id拉通引擎方法,可以解决用户id随着时间推移而变化这一现实问题;同时,准实时的实现(5s内)也可以满足互联网中推荐等其它技术的实时需求。
例如,在手机号注销后重新被启用的场景中,手机号phone1在之前归属于用户a,即经常和用户a的客户标识uida共现而被拉通到一起;后来手机号phone1被用户a注销,用户b重新申请了手机号phone1;随着phone1与用户b的客户标识uidb不断共现,phone1与uidb关系的权重会越来越高,直到该权重超过phone1与uida关系的权重之后,phone1将会和uidb拉通到一起,即认为是用户b的手机号。
对于本领域的技术人员来说,可以根据以上的技术方案和构思,给出各种相应的改变和变形,而所有的这些改变和变形,都应该包括在本发明权利要求的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!