一种针对机器翻译的译文评估方法及装置与流程
本发明涉及一种译文评估方法及装置,更具体涉及一种针对机器翻译的译文评估方法及装置。
背景技术:
随着现代社会的发展,人类对语言之间的转换需求越来越大。在实际应用中,传统机器翻译以规则为基础,特点是基于语法和语义理论,通过分析上下文的语法搭配关系得到翻译结果。但是由于规则不可能涵盖所有的句子,传统机器翻译大多是句法的直译或句型的转换。
随着人工智能技术的不断发展,基于神经网络的表示学习技术开始在各个领域崭露头角。尤其在以图像识别和语音识别为主的多个任务上,基于表示学习的方法在性能上均超过了传统的以统计学习为主的方法。现代机器翻译方法是以“双语库”为基础,特点是利用一个包含很多句型的双语语料库,在翻译的时候根据语料库中的句型抽取与所输入句子相类似的例句,然后参照双语句型把源语言转化为目标语言。
自然语言是人类智慧的抽象表达,很难通过已有的数据结构表示出来。在自然语言处理过程中,数据的基本单位是字或词。类似于“苹果”,既可以表示一种水果,也可以表示“苹果公司”。“麦克风”和“话筒”表示的是一种物品,但从字面上无法建立起正确的联系。因此,目前大多数翻译系统都能将语句的大致意思正确翻译。但是不同语言之间的词、句用法有着显著差别,翻译的结果大多存在语序错误、词语混用、错用等问题。尤其对于长句,机器翻译不能达到更好的准确度,导致现有技术存在翻译的结果仍需人工评估的技术问题。
技术实现要素:
本发明所要解决的技术问题在于提供了一种针对机器翻译的译文评估方法及装置,以解决现有技术中存在的翻译的结果仍需人工评估的技术问题。
本发明是通过以下技术方案解决上述技术问题的:
本发明实施例提供了一种针对机器翻译的译文评估方法,所述方法包括:
获取语料库中的若干条语料,并将每一条语料中包含的上下文词向量的拼接结果;并对所述若干条语料中包含的不同词性的词语的词向量进行初始化;
将所述拼接结果以及所述词向量作为cbow模型的输入,获取训练后的cbow模型;
获取每一条语料的目标词,并使用训练后的cbow模型进行翻译;
获取待评估模型针对所述目标词的译文,并根据所述待评估模型对应的译文与训练后的cbow模型对应的译文之间的相似度,评估待评估模型译文的准确度。
可选的,所述对所述若干条语料中包含的不同词性的词语的词向量进行初始化,包括:
分别使用互不重合的取值范围,对所述若干条语料中包含的不同词性的词语的词向量进行初始化。
可选的,在所述将所述拼接结果以及所述词向量作为cbow模型的输入,获取训练后的cbow模型之前,所述方法还包括:
将每一条语料中除设定的标点符号以外的标点符号去除,其中,设定的标点符号包括:用于表达语料的语气的标点符号、语料结束的标点符号中的一种或组合。
可选的,所述获取每一条语料的目标词,包括:
利用公式,
p(w|c)为目标词的概率;w为目标词;c为目标词的上下文;exp()为以自然底数为底的指数函数;;x为cbow模型的输入层;∑为求和函数;v为语料库;()t为转置矩阵。
可选的,所述语料为单独的句子。
本发明实施例提供了一种针对机器翻译的译文评估装置,所述装置包括:
获取模块,用于获取语料库中的若干条语料,并将每一条语料中包含的上下文词向量的拼接结果;并对所述若干条语料中包含的不同词性的词语的词向量进行初始化;
将所述拼接结果以及所述词向量作为cbow模型的输入,获取训练后的cbow模型;
获取每一条语料的目标词,并使用训练后的cbow模型进行翻译;
获取待评估模型针对所述目标词的译文,并根据所述待评估模型对应的译文与训练后的cbow模型对应的译文之间的相似度,评估待评估模型译文的准确度。
可选的,所述获取模块,用于:
分别使用互不重合的取值范围,对所述若干条语料中包含的不同词性的词语的词向量进行初始化。
可选的,所述装置还包括:去除模块,用于将每一条语料中除设定的标点符号以外的标点符号去除,其中,设定的标点符号包括:用于表达语料的语气的标点符号、语料结束的标点符号中的一种或组合。
可选的,所述获取模块,用于:
利用公式,
p(w|c)为目标词的概率;w为目标词;c为目标词的上下文;exp()为以自然底数为底的指数函数;;x为cbow模型的输入层;∑为求和函数;v为语料库;()t为转置矩阵。
可选的,所述语料为单独的句子。
本发明相比现有技术具有以下优点:
应用本发明实施例,由于上下文语序对于翻译起到了重要的作用,因此,将每一条语料中包含的上下文词向量的拼接结果,可以得到更加准确的翻译模型,进而可以使用本发明实施例训练的模型对现有技术中的模型的翻译结果进行校对,相对于现有技术中需要人工评估,本发明实施例可以自动对译文结果进行准确性评估。
附图说明
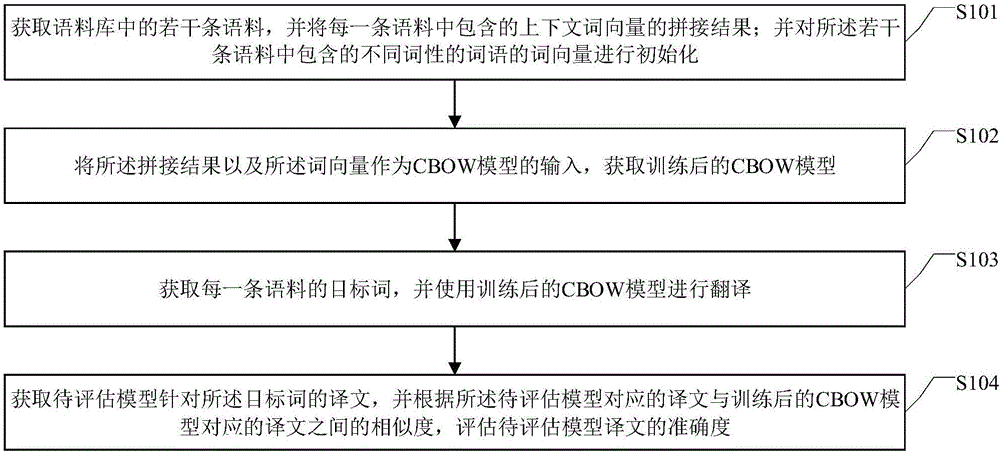
图1为本发明实施例提供的一种针对机器翻译的译文评估方法的流程示意图;
图2为本发明实施例提供的一种cbow模型的结构示意图;
图3为本发明实施例提供的一种针对机器翻译的译文评估装置的结构示意图。
具体实施方式
下面对本发明的实施例作详细说明,本实施例在以本发明技术方案为前提下进行实施,给出了详细的实施方式和具体的操作过程,但本发明的保护范围不限于下述的实施例。
本发明实施例提供了一种针对机器翻译的译文评估方法及装置,下面首先就本发明实施例提供的一种针对机器翻译的译文评估方法进行介绍。
图1为本发明实施例提供的一种针对机器翻译的译文评估方法的流程示意图,如图1所示,所述方法包括:
s101:获取语料库中的若干条语料,并将每一条语料中包含的上下文词向量的拼接结果;并对所述若干条语料中包含的不同词性的词语的词向量进行初始化;
具体的,可以分别使用互不重合的取值范围,对所述若干条语料中包含的不同词性的词语的词向量进行初始化。所述语料为单独的句子。
示例性的,可以从大规模语料库中学习建立语言模型。由于语言模型的好坏直接影响到对句子正确性的判断,所以选取合适的语料较为重要。中文语料可以选取维基百科中文词条进行建模。
s102:将所述拼接结果以及所述词向量作为cbow模型的输入,获取训练后的cbow模型;
图2为本发明实施例提供的一种cbow模型的结构示意图,如图2所示,cbow模型(continuousbagofwords,连续词袋模型)包括:输入层x和输出层y。输入层接收不同的短语,进行翻译后由输出层输出。
s103:获取每一条语料的目标词,并使用训练后的cbow模型进行翻译。
具体的,可以利用公式,
p(w|c)为目标词的概率;w为目标词;c为目标词的上下文;exp()为以自然底数为底的指数函数;;x为cbow模型的输入层;∑为求和函数;v为语料库;()t为转置矩阵。
(w,c)为从语料中选出的一个n元短语wi-(n-1)/2,...,wi+(n-1)/2,一般n选奇数,可以保证上下文的词语数量一致。
模型的优化目标可以:
d为语料库。
s104:获取待评估模型针对所述目标词的译文,并根据所述待评估模型对应的译文与训练后的cbow模型对应的译文之间的相似度,评估待评估模型译文的准确度。
在实际应用中,对于一句译文,利用滑动窗口进行多次判断。例如:窗口大小为5,分别以译文的第1,2,…个词为中间词进行判断。每次判断得到一个相似度值,再计算相似度的平均值,最后得到的相似度为对这句译文的打分值,打分值越高说明译文的正确性越高。
应用本发明图1所示实施例,由于上下文语序对于翻译起到了重要的作用,因此,将每一条语料中包含的上下文词向量的拼接结果,可以得到更加准确的翻译模型,进而可以使用本发明实施例训练的模型对现有技术中的模型的翻译结果进行校对,相对于现有技术中需要人工评估,本发明实施例可以自动对译文结果进行准确性评估。
具体的在本发明实施例的一种具体实施方式中,在s102步骤之前,所述方法还包括:
将每一条语料中除设定的标点符号以外的标点符号去除,其中,设定的标点符号包括:用于表达语料的语气的标点符号、语料结束的标点符号中的一种或组合。
在训练模型前,处理语料库时,对于特殊符号予以去除,保留对模型有用的标点符号。例如:句号、感叹号、问号等。
本发明通过改进语言模型,增加了词序、词性、标点符号等语句信息,提高了语言模型的表示能力,可以表示更加复杂的语句。通过语言模型的改进,结合机器翻译,可以判断机器翻译译文的正确性,提高机器翻译的准确率。
用于本发明图1所示实施例相对应,本发明实施例还提供了一种针对机器翻译的译文评估装置。
图3为本发明实施例提供的一种针对机器翻译的译文评估装置的结构示意图,如图3所示,所述装置包括:
获取模块301,用于获取语料库中的若干条语料,并将每一条语料中包含的上下文词向量的拼接结果;并对所述若干条语料中包含的不同词性的词语的词向量进行初始化;
将所述拼接结果以及所述词向量作为cbow模型的输入,获取训练后的cbow模型;
获取每一条语料的目标词,并使用训练后的cbow模型进行翻译;
获取待评估模型针对所述目标词的译文,并根据所述待评估模型对应的译文与训练后的cbow模型对应的译文之间的相似度,评估待评估模型译文的准确度。
应用本发明图1所示实施例,由于上下文语序对于翻译起到了重要的作用,因此,将每一条语料中包含的上下文词向量的拼接结果,可以得到更加准确的翻译模型,进而可以使用本发明实施例训练的模型对现有技术中的模型的翻译结果进行校对,相对于现有技术中需要人工评估,本发明实施例可以自动对译文结果进行准确性评估。
在本发明实施例的一种具体实施方式中,所述获取模块301,用于:
分别使用互不重合的取值范围,对所述若干条语料中包含的不同词性的词语的词向量进行初始化。
在本发明实施例的一种具体实施方式中,所述获取模块301,用于:所述装置还包括:去除模块,用于将每一条语料中除设定的标点符号以外的标点符号去除,其中,设定的标点符号包括:用于表达语料的语气的标点符号、语料结束的标点符号中的一种或组合。
在本发明实施例的一种具体实施方式中,所述获取模块301,用于:利用公式,
p(w|c)为目标词的概率;w为目标词;c为目标词的上下文;exp()为以自然底数为底的指数函数;;x为cbow模型的输入层;∑为求和函数;v为语料库;()t为转置矩阵。
在本发明实施例的一种具体实施方式中,所述语料为单独的句子。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内所作的任何修改、等同替换和改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!