一种基于AdaBoost-SO的VANETs车辆事故风险预测模型的制作方法
本发明涉及车联网技术领域,具体涉及一种基于adaboost-so的vanets车辆事故风险预测模型。
背景技术:
随着当今社会经济的发展,城市居民对旅行的便利性和舒适性提出了更高的要求,汽车数量增加,城市交通压力加大,道路安全问题也越来越严重。特别是在大城市,交通事故导致交通拥堵,并且车辆事故对人身安全的威胁越来越严重,这使得交通安全研究具有重要意义。与此同时,车载adhoc网络(vanets)作为智能交通系统(its)的关键技术,其快速发展具有提高道路安全性和交通效率的巨大潜力。它为有效研究道路安全提供了原始道路安全信息,并为预测车辆事故风险提供了新思路。从高度异构的资源中收集大量vanets数据,为vanets-bigdata的新时代铺平了道路
随着大数据和机器学习的发展,利用机器学习技术预测交通事故成为新的亮点。文献“thetrafficaccidenthotspotprediction:basedonthelogisticregressionmethod”通过对典型因素的统计和logistic回归分析,研究交通事故,道路类型,车辆类型,驾驶员状态,天气,日期等之间的关系,最后建立事故热点预测模型。文献“thefive-factormodel,conscientiousness,anddrivingaccidentinvolvement”和“determiningpersonalitytraitsofracinggameplayersusingtheopenracingcarsimulator:towardbelievablevirtualdrivers”研究了驾驶员的责任感与驾驶事故之间的关系,证明那些责任心强的人不太可能发生交通事故。文献“trafficbigdataanalysissupportingvehicularnetworkaccessrecommendation”开发了一种由交通大数据分析支持的智能网络推荐系统,建议车辆通过采用分析框架访问适当的网络,并使个体车辆能够基于访问推荐器自动访问网络。
然而,所有这些方法都集中在从现有交通数据中分析交通事故的原因,并且未能获得具有普遍应用价值的事故预测模型。因此,设计一个可以使用实时交通数据,并随时向车辆发出警报,为智能交通系统和驾驶安全辅助提供理论基础的车辆事故风险预测模型是很有必要的。
技术实现要素:
本发明的主要目的在于解决现有技术中存在的问题,本发明提供了一种基于adaboost-so的vanets车辆事故风险预测模型。
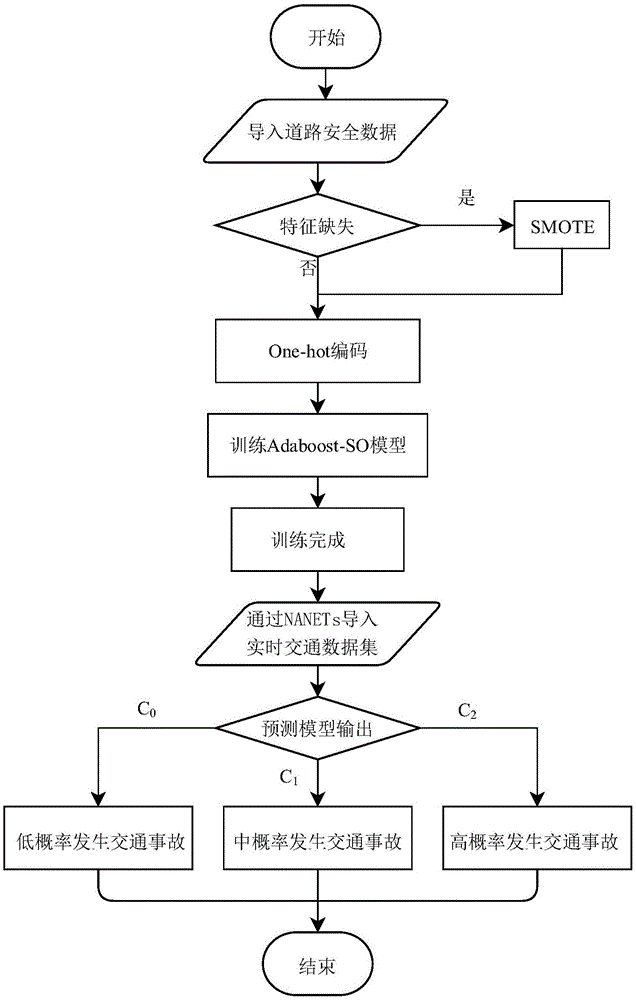
一种基于adaboost-so的vanets车辆事故风险预测模型,所述模型建立的步骤包括:
步骤一:填充研究数据集;
步骤二:用smote算法平衡数据集中的样本,并且将每个样本的离散特征用one-hot编码;
具体的,将syntheticminorityoversamplingtechnique(smote)算法用于解决研究数据集中每个类别的样本数不平衡的问题;
在使用smote算法预处理初始研究数据集之后,可以获得每个类别的相对平衡数量的实验数据集;接下来,将每个样本的离散特征用one-hot编码;one-hot编码方法为使用n比特状态寄存器来编码n个状态,每个状态具有单独的寄存器比特,并且在任何时候只有一个比特有效;
步骤三:用trichotomyadaboost-so算法训练研究数据集获得系统模型;
具体的,首先,构建实验数据集时,将道路安全数据随机分为训练数据和测试数据,并进行6次交叉验证,该方法充分利用了所有样本,它需要6次培训和6次测试;然后,使用trichotomyadaboost算法处理研究数据集;
步骤四:通过vanets导入实时交通数据集,获得预测模型的输出;
具体的,输出值为c={c0,c1,c2},表示预测对象是否属于事故发生率高;c0表示车祸概率低或仅发生轻微碰撞事故,c1意味着可能发生更严重的意外伤害,c2表明车祸的概率很高或可能发生意外事故。
进一步地,所述步骤一中,具体的,在重建数据之前,找到并修改不确定或不完整的道路安全数据,以改进数据集;通常的实现方案包括填充可用特征的平均值,特殊值,类似样本的平均值,并直接忽略具有缺失值的样本。
进一步地,所述步骤二中,smote算法实现过程是:
步骤2-1,对于少数类别中的每个样本x,欧几里德距离用作标准来计算与少数类别中所有其他样本的距离,以获得其k最近样本;
步骤2-2,根据样本不平衡比设置采样率n,对于每个少数类样本x,假设所选择的邻近样本是k,从其k邻近样本随机选择若干样本;
步骤2-3,对于每个选定的邻居,根据如下公式,使用原始样本构建新样本;
进一步地,所述步骤三中,所述6次交叉验证的具体实施步骤如下:
步骤3-1-1,将整个研究数据集s划分为6个相同大小的相互不相交的子集;假设训练样本的数量是m,则每个子集将具有
步骤3-1-2,将一个子集作为测试集,然后将其他五个子集作为训练集;
步骤3-1-3,通过训练数据训练模型,使用测试数据验证模型的准确性并重复六次;
步骤3-1-4,计算6个评估误差的平均值作为模型的真实分类精度。
进一步地,所述步骤三中,使用trichotomyadaboost算法处理研究数据集,其具体实施步骤如下:
步骤3-2-1,输入训练数据集t=(x1,y1),(x2,y2)...,(xn,yn),xi是样本的特征向量,y∈{1,2,3},本发明中使用的弱分类器是决策树;
步骤3-2-2,训练数据的权重初始化为:
步骤3-2-3,对于第m次迭代,m=1,2,...,m:使用具有权重分布的训练数据集dm进行训练,获得基本分类器:
gm(x):χ→{1,2,3}
χ是要训练的数据,根据训练数据的分类结果计算gm(x)错误率,wmi表示第m次迭代中第i个样本的权重:
由于在每个步骤中权重被标准化,分母不需要除以样本权重的总和;
步骤3-2-4,trichotomyadaboost的错误率阈值em设置为
根据系数am更新训练数据集的权重分布:
dm+1=(wm+1,1,...,wm+1,i,...wm+1,n)
可以化简为:
其中,zm作为归一化因子使得dm+1成为概率分布:
在训练之后,基本分类器gm(x)的错误分类样本的权重不断扩大,而正确分类的样本的权重减小,因此,错误分类的样本在下一次迭代中发挥更大的作用;
步骤3-2-5,构造基本分类器的线性组合以获得最终分类器:
线性组合f(x)实现m个基本分类器的加权投票,f(x)值确定实例x的类别,并指示分类的置信度,将训练的弱分类器组合成强分类器以获得车辆事故风险预测模型。
与现有技术相比,本发明的有益效果是:最大迭代值为100的系统模型保证了普通道路状态下事故预测的最大精度,特殊情况下最大迭代值较小的系统模型可以提高时效性。在预测中,可以发挥系统的最大性能。
附图说明
图1为本发明所述方法的流程示意图。
图2为trichotomyadaboost-so模型架构。
具体实施方式
下面结合说明书附图对本发明的技术方案做进一步的详细说明。
一种基于adaboost-so的vanets车辆事故风险预测模型,所述模型建立的步骤包括:
步骤一:填充研究数据集。
具体的,在重建数据之前,找到并修改不确定或不完整的道路安全数据,以改进数据集;通常的实现方案包括填充可用特征的平均值,特殊值,类似样本的平均值,并直接忽略具有缺失值的样本。
步骤二:用smote算法平衡数据集中的样本,并且将每个样本的离散特征用one-hot编码。
具体的,将syntheticminorityoversamplingtechnique(smote)算法用于解决研究数据集中每个类别的样本数不平衡的问题。所述smote算法实现过程是:
步骤2-1,对于少数类别中的每个样本x,欧几里德距离用作标准来计算与少数类别中所有其他样本的距离,以获得其k最近样本。
步骤2-2,根据样本不平衡比设置采样率n。对于每个少数类样本x,假设所选择的邻近样本是k,从其k邻近样本随机选择若干样本。
步骤2-3,对于每个选定的邻居,根据如下公式,使用原始样本构建新样本。
在使用smote算法预处理初始研究数据集之后,可以获得每个类别的相对平衡数量的实验数据集。接下来,将每个样本的离散特征用one-hot编码。
one-hot编码方法为使用n比特状态寄存器来编码n个状态,每个状态具有单独的寄存器比特,并且在任何时候只有一个比特有效。
步骤三:用trichotomyadaboost-so算法训练研究数据集获得系统模型。
具体的,首先,构建实验数据集时,将道路安全数据随机分为训练数据和测试数据,并进行6次交叉验证,该方法充分利用了所有样本,它需要6次培训和6次测试。所述6次交叉验证的具体实施步骤如下:
步骤3-1-1,将整个研究数据集s划分为6个相同大小的相互不相交的子集;假设训练样本的数量是m,则每个子集将具有
步骤3-1-2,将一个子集作为测试集,然后将其他五个子集作为训练集。
步骤3-1-3,通过训练数据训练模型,使用测试数据验证模型的准确性并重复六次。
步骤3-1-4,计算6个评估误差的平均值作为模型的真实分类精度。
然后,使用trichotomyadaboost算法处理研究数据集,其具体实施步骤如下:
步骤3-2-1,输入训练数据集t=(x1,y1),(x2,y2)...,(xn,yn),xi是样本的特征向量,y∈{1,2,3},本发明中使用的弱分类器是决策树。
步骤3-2-2,训练数据的权重初始化为:
步骤3-2-3,对于第m次迭代,m=1,2,...,m:使用具有权重分布的训练数据集dm进行训练,获得基本分类器:
gm(x):χ→{1,2,3}
χ是要训练的数据。根据训练数据的分类结果计算gm(x)错误率,wmi表示第m次迭代中第i个样本的权重:
由于在每个步骤中权重被标准化,分母不需要除以样本权重的总和。
步骤3-2-4,trichotomyadaboost的错误率阈值em设置为
根据系数am更新训练数据集的权重分布:
dm+1=(wm+1,1,...,wm+1,i,...wm+1,n)
可以化简为:
其中,zm作为归一化因子使得dm+1成为概率分布:
在训练之后,基本分类器gm(x)的错误分类样本的权重不断扩大,而正确分类的样本的权重减小,因此,错误分类的样本在下一次迭代中发挥更大的作用。
步骤3-2-5,构造基本分类器的线性组合以获得最终分类器:
线性组合f(x)实现m个基本分类器的加权投票,f(x)值确定实例x的类别,并指示分类的置信度,将训练的弱分类器组合成强分类器以获得车辆事故风险预测模型。
步骤四:通过vanets导入实时交通数据集,获得预测模型的输出。
具体的,输出值为c={c0,c1,c2},表示预测对象是否属于事故发生率高。c0表示车祸概率低或仅发生轻微碰撞事故,c1意味着可能发生更严重的意外伤害,c2表明车祸的概率很高或可能发生意外事故。
以上所述仅为本发明的较佳实施方式,本发明的保护范围并不以上述实施方式为限,但凡本领域普通技术人员根据本发明所揭示内容所作的等效修饰或变化,皆应纳入权利要求书中记载的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!