一种镜头类型信息识别方法及装置与流程
本发明属于视频处理技术领域,更具体地说,尤其涉及一种镜头类型信息识别方法及装置。
背景技术:
目前节目录制过程中因为机位、拍摄角度和拍摄场景等因素会产生大量的视频(简称为原素材),这些原素材可由初级剪辑师进行初剪,以减掉原素材中的部分无用的视频,并对剩余的视频人工标注出组成视频的每帧图像的镜头相关信息,如每帧图像的镜头类型标识和每帧图像的镜头类型标识的置信度。而在节目录制过程中可能产生上百小时的原材料,若由初级剪辑师进行初剪则会造成大量的时间成本和人员成本的浪费。
技术实现要素:
有鉴于此,本发明的目的在于提供一种镜头类型信息识别方法及装置,用于自动确定图像的镜头类型信息。技术方案如下:
本发明提供一种镜头类型信息识别方法,所述方法包括:
从视频中抽取一帧待识别图像;
对所述待识别图像进行识别,得到所述待识别图像的识别结果;
判断所述待识别图像的识别结果是否满足预设条件;
如果所述待识别图像的识别结果满足预设条件,则基于所述识别结果中的人脸特征,确定所述待识别图像的镜头类型信息;
如果所述待识别图像的识别结果不满足预设条件,则从所述待识别图像中确定包含人体的检测框信息,并基于所述包含人体的检测框信息,确定所述待识别图像的镜头类型信息。
优选的,所述方法还包括:判断是否完成对所述视频中每帧待识别图像的处理,如果是,则对任一帧待识别图像的镜头类型信息进行修正,如果否,则返回执行从视频中抽取一帧待识别图像的步骤,以从所述视频中抽取没有确定镜头类型信息的待识别图像。
优选的,所述方法还包括:
将修正后的镜头类型信息存储在所述视频的序列中;
将所述视频的序列中的内容转码成json返回结果输出,其中所述json返回结果包括:修正所使用代码中的错误代码、视频信息、所述视频中镜头类型错误的图像信息、各个所述待识别图像对应的镜头段信息。
优选的,所述基于所述识别结果中的人脸特征,确定所述待识别图像的镜头类型信息包括:
基于所述人脸特征,得到人脸的特征距离;
计算所述特征距离和所述待识别图像的高度之间的比值;
基于所述特征距离和所述待识别图像的高度之间的比值,确定所述待识别图像的镜头类型信息。
优选的,所述基于所述包含人体的检测框信息,确定所述待识别图像的镜头类型信息包括:
基于所述包含人体的检测框信息,确定检测框的高度;
计算所述检测框的高度与所述待识别图像的高度之间的比值;
基于所述检测框的高度与所述待识别图像的高度之间的比值,确定所述待识别图像的镜头类型信息。
本发明还提供一种镜头类型信息识别装置,所述装置包括:
抽取单元,用于从视频中抽取一帧待识别图像;
识别单元,用于对所述待识别图像进行识别,得到所述待识别图像的识别结果;
判断单元,用于判断所述待识别图像的识别结果是否满足预设条件;
第一确定单元,用于如果所述待识别图像的识别结果满足预设条件,则基于所述识别结果中的人脸特征,确定所述待识别图像的镜头类型信息;
第二确定单元,用于如果所述待识别图像的识别结果不满足预设条件,则从所述待识别图像中确定包含人体的检测框信息,并基于所述包含人体的检测框信息,确定所述待识别图像的镜头类型信息。
优选的,所述装置还包括:修正单元,用于判断是否完成对所述视频中每帧待识别图像的处理,如果是,则对任一帧待识别图像的镜头类型信息进行修正,如果否,则触发所述抽取单元从所述视频中抽取没有确定镜头类型信息的待识别图像。
优选的,所述装置还包括:
存储单元,用于将修正后的镜头类型信息存储在所述视频的序列中;
输出单元,用于将所述视频的序列中的内容转码成json返回结果输出,其中所述json返回结果包括:修正所使用代码中的错误代码、视频信息、所述视频中镜头类型错误的图像信息、各个所述待识别图像对应的镜头段信息。
优选的,所述第一确定单元,具体用于基于所述人脸特征,得到人脸的特征距离,计算所述特征距离和所述待识别图像的高度之间的比值,并基于所述特征距离和所述待识别图像的高度之间的比值,确定所述待识别图像的镜头类型信息。
优选的,所述第二确定单元,具体用于基于所述包含人体的检测框信息,确定检测框的高度,计算所述检测框的高度与所述待识别图像的高度之间的比值,并基于所述检测框的高度与所述待识别图像的高度之间的比值,确定所述待识别图像的镜头类型信息。
从上述技术方案可知,从视频中抽取一帧待识别图像,对待识别图像进行识别,得到待识别图像的识别结果,若识别结果满足预设条件则基于识别结果中的人脸特征进行镜头类型计算以确定镜头类型信息;若识别结果不满足预设条件则进行人体识别,确定包含人体的检测框信息,并基于包含人体的检测框信息进行镜头类型计算以确定镜头类型信息,由此实现镜头类型信息的自动确定,提高确定镜头类型信息的效率,从而节约时间成本和人员成本,并且通过人脸特征和包含人体的检测框信息确定镜头类型信息的方式,使得在基于人脸特征无法识别的情况下仍可通过包含人体的检测框信息来确定镜头类型信息,提高识别自动化和准确度。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1是本发明实施例提供的一种镜头类型信息识别方法的流程图;
图2是本发明实施例提供的一种确定镜头类型信息方法的流程图;
图3是本发明实施例提供的另一种确定镜头类型信息方法的流程图;
图4是本发明实施例提供的另一种镜头类型信息识别方法的流程图;
图5是本发明实施例提供的一种镜头信息修正方法的流程图;
图6是本发明实施例提供的另一种镜头类型信息修正方法的流程图;
图7是本发明实施例提供的镜头类型信息修正方法的流程展示图;
图8是本发明实施例提供的镜头类型信息中的中景(ms)镜头识别样例;
图9是本发明实施例提供的镜头类型信息中的特写(cu)镜头识别样例;
图10是本发明实施例提供的镜头类型信息中的远景(ws)镜头识别样例;
图11是本发明实施例提供的一种镜头类型信息识别装置的结构示意图;
图12是本发明实施例提供的另一种镜头类型信息识别方法的流程图。
具体实施方式
为了便于理解本发明实施例提供的技术方案,首先对本发明实施例涉及的用语进行说明:
预设的n维向量k,预设比例系数α:n维向量k用于表示待修正镜头类型相关信息和为该待修正镜头类型相关信息确定的参考镜头类型相关信息的重要程度,预设比例系数α用于确定修正参数基于的属性向量中每个向量的系数,且预设的n维向量k和预设比例系数α可以根据实际应用而定,并且在实施过程中可根据实际数据调整。
镜头类型标识的总数为d,且d个镜头类型标识可以是从1开始的连续整数,如d个镜头类型标识如表1所示:
表1d个镜头类型标识与镜头类型的对应关系
当然,镜头类型标识还可以采用其他方式描述,如采用英文字母a至f表示d个镜头类型标识,在此本实施例不限定镜头类型标识采用的表示方式。
原始镜头类型标识序列:l={l1,l2,...,li,...lm},其中m为原始镜头类型标识序列的长度,li为原始镜头类型标识序列中的第i个镜头类型标识,即同一个视频中第i帧图像的镜头类型标识,i为非负int型变量,代表镜头类型标识的索引号。
原始镜头类型标识的置信度序列:c={c1,c2,...,ci,...cm},其中m为原始镜头类型标识的置信度序列的长度,ci原始镜头类型标识的置信度序列中第i个置信度,即原始镜头类型标识序列中第i个镜头类型标识的置信度,ci为非负float型变量,在本实施例中可从原始镜头类型标识序列和原始镜头类型标识的置信度序列中选取待修正镜头类型相关信息。
平滑后镜头类型标识序列:l'={l'1,l'2,...,l'i,...l'm},是对原始镜头类型标识序列中每个镜头类型标识进行修正后得到的序列,其中m为镜头类型标识序列的长度,li为镜头类型标识序列中的第i个镜头类型标识,即对原始镜头类型标识序列中的第i个镜头类型标识修正得到的标识,i为非负int型变量,代表镜头类型标识的索引号。
平滑后镜头类型标识的置信度序列:c'={c'1,c'2,...,c'i,...c'm},是对原始镜头类型标识的置信度序列中每个置信度进行修正后得到的序列,其中m为镜头类型标识的置信度序列的长度,c'i为镜头类型标识的置信度序列中第i个镜头类型标识的置信度,ci为非负float型变量。
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
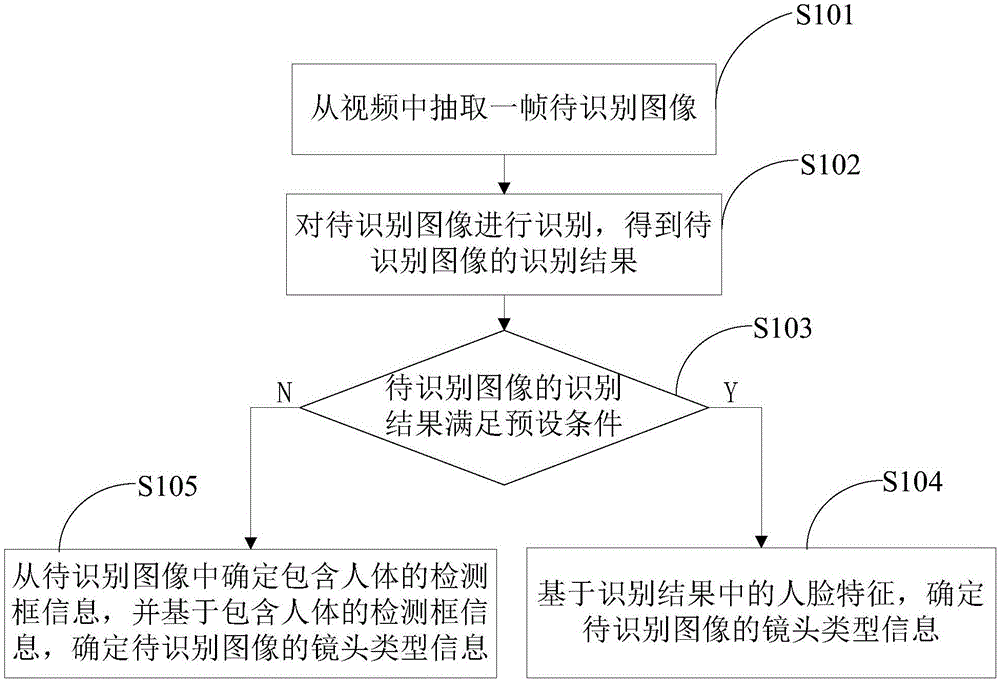
请参阅图1,其示出了本发明实施例提供的一种镜头类型信息识别方法的流程图,用于自动确定待识别图像的镜头类型信息,以提高确定镜头类型信息的效率,其中图1所示镜头类型信息识别方法可以包括以下步骤:
s101:从视频中抽取一帧待识别图像。其中待识别图像可以是视频中的原始图像,或者是对原始图像进行调整后的图像,如对原始图像进行格式调整,得到一张w*h的待识别图像,其中w为预设的待识别图像的宽度,h为预设的待识别图像的高度,以保证待识别图像之间的格式统一,从而降低因格式问题导致镜头类型信息有误,对于预设的待识别图像的宽度和预设的待识别图像的高度可以基于实际应用而定。
在实际应用中,从视频中抽取一帧待识别图像可以是从视频的第一帧开始依次抽取来进行镜头类型信息计算,其中视频的总帧数total_frames、视频每秒传输帧数fps和跳帧数skip_frame,从视频的帧号current_frame=0(第一帧)开始依次得到待识别图像。
s102,对待识别图像进行识别,得到待识别图像的识别结果。例如通过人脸识别技术对待识别图像进行识别,得到人脸特征,该人脸特征可作为待识别图像的识别结果中的内容,其中人脸特征包括但不限于:两眼特征点(如两个眼球各自的中心点)、嘴巴特征点(如嘴巴的两个嘴角特征点)、鼻子特征点(如一个鼻尖点)等,当然在得到人脸特征点之后还可以通过人脸特征点中的各个特征点来计算出人脸的不同部位(如眼睛和嘴巴)之间的距离,将通过人脸特征点中的各个特征点计算出的人脸的不同部位之间的距离也可以视为是待识别图像的识别结果中的部分结果。
又或者预先得到一个人脸识别模型,该人脸识别模型将待识别图像作为输入,将人脸特征点作为输出,这样在抽取到任一待识别图像后可以将该待识别图像输入到人脸识别模型中,通过人脸识别模型输出人脸特征点,对于该人脸识别模型输出人脸特征点的内容可以根据实际应用而定,如输出上述两眼特征点(如两个眼球各自的中心点)、嘴巴特征点(如嘴巴的两个嘴角特征点)、鼻子特征点(如一个鼻尖点)等中的至少一种,对于人脸识别模型的训练过程和修正过程,本实施例不在阐述。
s103,判断待识别图像的识别结果是否满足预设条件。如果满足预设条件则执行步骤s104,如果不满足预设条件则执行步骤s105。例如判断人脸特征点是否满足预设条件,如果满足预设条件则执行步骤s104,如果不满足预设条件则执行步骤s105,其中预设条件可以是成功识别面部特征点,进一步的还可以限定人脸特征点符合预设内容,所谓预设内容可以是人脸特征点中包括的所有特征点的个数不超过预设个数和/或人脸特征点中包含预设类型的特征点,如包含两眼特征点和嘴巴特征点,对于预设个数和预设类型,本实施例不加以限定。当然预设条件也可以根据实际应用发生变化,对此本实施例也不再阐述。
步骤s104,基于识别结果中的人脸特征,确定待识别图像的镜头类型信息。在本实施例中,基于人脸特征确定镜头类型信息的一种可行方式如图2所示,可以有如下步骤:
s201,基于人脸特征,得到人脸的特征距离,可行方式是:基于人脸特征中的两眼特征点和两个嘴角特征点得到人脸的特征距离,如基于两个眼球各自的中心点得到两个眼球之间的中心点,基于两个嘴角特征点得到两个嘴角的中心点,计算两个眼球之间的中心点和两个嘴角的中心点之间的距离,该距离视为人脸的特征距离,当然还可以采用其他特征点得到人脸的特征距离,对此本实施例不再一一阐述。
s202,计算特征距离和待识别图像的高度之间的比值。如特征距离为a,待识别图像的高度为h,则a除以h为特征距离和待识别图像的高度之间的比值。
s203,基于特征距离和待识别图像的高度之间的比值,确定待识别图像的镜头类型信息。例如预先设置镜头类型与特征距离和待识别图像的高度之间的比值的对应关系,具体的预先设置镜头类型对应的比值区间,也就是说设置多个比值区间,每个比值区间对应一种镜头类型,且每个比值区间之间的数值不冲突,这样就可以确定特征距离和待识别图像的高度之间的比值所在的比值区间,然后将所确定的比值区间对应的镜头类型作为待识别图像的镜头类型。例如比值0.333在比值区间(0,0.5)内,而该比值区间对应的镜头类型是远景,则可以确定待识别图像的镜头类型为中景镜头,如图8所示的中景(ms)镜头,特写镜头的示例如图9所示,远景镜头的示例如图10所示。
在这里需要说明的一点是:通过人脸识别模型除能够输出待识别图像中的人脸特征点之外,人脸识别模型还能够输出置信度,具体的,若人脸识别模型从待识别图像中识别到人脸特征点,则会同时输出置信度,该置信度可以作为基于人脸特征点确定的待识别图像的镜头类型的置信度,若人脸识别模型从待识别图像中没有能够识别到人脸特征点,则人脸识别模型输出内容为空,以表示无法从待识别图像中识别到人脸特征点,更无法得到置信度。
步骤s105,从待识别图像中确定包含人体的检测框信息,并基于包含人体的检测框信息,确定待识别图像的镜头类型信息。例如将待识别图像输入预先得到的镜头识别模型中,得到预先得到的镜头识别模型输出的包含人体的检测框信息,其中预先得到的镜头识别模型可以使用开源代码的深度学习网络模型进行构建,对此本实施例不再阐述。当待识别图像输入到预先得到的镜头识别模型中,预先得到的镜头识别模型则会输出诸如但不限于诸如:[xmin,ymin,xlen,ylen]的检测框信息,其中,xmin为检测框的左上角点坐标的x值,ymin为检测框的左上角点坐标的y值,xlen为检测框的宽度,ylen为检测框的高度。而基于包含人体的检测框信息,确定待识别图像的镜头类型信息的过程如图3所示,有如下步骤:
s301,基于包含人体的检测框信息,确定检测框的高度,如从包含人体的检测框信息中提取出检测框的高度,如上述ylen,若上述包含人体的检测框信息中不包含检测框的高度,则可以基于包含人体的检测框信息中的各个参数计算得到,对此本实施例不再详述,而检测框则是用于将待识别图像中人体所在区域包住的框。
s302,计算检测框的高度和待识别图像的高度之间的比值。如将检测框的高度与待识别图像的高度进行相比,得到两个高度的比值。
s303,基于检测框的高度和待识别图像的高度之间的比值,确定待识别图像的镜头类型信息,其可行方式请参阅上述步骤s203中的说明,对此本实施例不再阐述。
此外,预先得到的镜头识别模型还用于输出镜头类型的置信度,也就是说在训练得到镜头识别模型时,设置镜头识别模型的输出包括:检测框信息和镜头类型的置信度,这样当输入任一待识别图像之后,就可以同时输出包含人体的检测框信息和镜头类型的置信度。
从上述技术方案可知,从视频中抽取一帧待识别图像,对待识别图像进行识别,得到待识别图像的识别结果,若识别结果满足预设条件则基于识别结果中的人脸特征进行镜头类型计算以确定镜头类型信息;若识别结果不满足预设条件则进行人体识别,确定包含人体的检测框信息,并基于包含人体的检测框信息进行镜头类型计算以确定镜头类型信息,由此实现镜头类型信息的自动确定,提高确定镜头类型信息的效率,从而节约时间成本和人员成本,并且通过人脸特征和包含人体的检测框信息确定镜头类型信息的方式,使得在基于人脸特征无法识别的情况下仍可通过包含人体的检测框信息来确定镜头类型信息,提高识别自动化和准确度。
在此介绍对待识别图像进行识别,得到待识别图像的识别结果的一种方式,其过程可以包括:将待识别图像输入到卷积神经网络进行处理,得到待识别图像中的候选参照物的区域图像,提取待识别图像中的候选参照物的区域图像的特征点,将该提取到的特征点作为待识别图像的识别结果。若基于卷积神经网络得到的候选参照物的区域图像是人脸的区域图像且能够从人脸的区域图像中提取到人脸的特征点,则可能得到满足预设条件的识别结果,若基于卷积神经网络得到的候选参照物的区域图像不是人脸的区域图像或者虽然得到人脸的区域图像但提取不到人脸的特征点,则可能得到不满足预设条件的识别结果。
在本实施例中将待识别图像输入到卷积神经网络进行处理并提取特征点的具体过程为:将待识别图像输入到第一卷积神经网络进行候选区域图像粗选处理,得到候选参照物的位置信息;将所述每个候选参照物位置信息所框出区域的图像输入到第二卷积神经网络进行候选参照物精选处理,得到候选参照物的区域图像,并将待识别图像中的所述候选参照物的区域图像输入到第三卷积神经网络按照设定参照物参照点进行特征提取,得到候选参照物的多个特征点。
其中,将待识别图像输入到第一卷积神经网络是一个粗选处理过程,也即是初选处理过程,该第一卷积神经网络(cnn,convolutionalneuralnetwork)为:候选参照物粗选阶段中的卷积神经网络,该卷积神经网络由6层组成,即l1,l2,l3,l4,l5和l6。所述l1为10个3*3卷积核组成,步长为1的卷积层;l2为2*2池化核组成,步长为1的池化层;l3为16个3*3卷积核组成,步长为1的卷积层;l4为32个3*3卷积核组成,步长为1的卷积层;l5为2个1*1卷积核组成,步长为1的卷积层;l6为4个1*1卷积核组成,步长为1的卷积层。其中,卷积神经网络中,l1到l4中,前一层的输出作为后一层的输入,l4的输出分别作为l5,l6的输入,l5的输出作为l6的输入,即l4和l5的输出作为l6的输入,l5的输出为判断当前区域是否为参照物的概率,l6的输出为选参照物的位置区域信息,即候选参照物所在矩形左上和右下的坐标信息。
其中,l5输出的是一个数值,表示是否为参照物的概率,概率大于等于阈值就是参照物的概率,小于不是,而阈值是通过训练获得的。
也就说该实施例中,假如输入第一卷积神经网络的待识别图像的分辨率为1024*786,那么输入第一卷积神经网络的就是1024*768*3(*3是因为rgb三个通道,同样是公知)的矩阵,经过l1后输出1024*768*10的特征矩阵,送入l2生成1024*768*10的特征矩阵,送入l3输出1024*768*16的特征矩阵,送入l4输出1024*768*32的特征矩阵,将该矩阵送入l5,l6,l5输出一个1*4的向量(a,b),a表示l6输出的区域坐标是参照物的概率,b表示l6输出的区域坐标不是参照物的概率;l6输出一个1*4的向量(c,d,e,f),(c,d)为参照物所在矩形左上角坐标,(e,f)为参照物所在矩形右下角坐标。
将待识别图像输入到由第一卷积神经网络(即由多个卷积层组成的卷积神经网络),输出多个候选参照物的位置信息(该实施例中,位置信息以两个点坐标,(x1,y1),(x2,y2)为例,两个点坐标分别表示候选参照物所在的矩形框的左上点坐标和右下点坐标);该过程中的第一卷积网络构成比较简单,处理整张图像时,运算相对较少,输出为候选参照物的位置信息,作为后面复杂的第二卷积神经网络的输入。通过第一卷积神经网络对候选区域图像进行粗选处理,可以使待识别图像中不是候选区域的图像不经过后续复杂的第二卷积神经网络运算,减少大量的运算,从而大幅减少模型推理时间。
相对于第一卷积神经网络,第二卷积神经网络为候选参照物精选阶段中的卷积神经网络,该网络由7层组成:l1,l2,l3,l4,l5,l6和l7。所述l1由28个3*3卷积核组成,步长为1的卷积层;l2为3*3池化核,步长为2的池化层;l3由48个3*3卷积核组成,步长为1的卷积层;l4为3*3池化核,步长为2的池化层;l5由64个2*2卷积核组成,步长为1的卷积层;l6输出为128的全连接层;l7由2个1*1卷积核组成,步长为1的卷积层。其中,第二卷积神经网络中,l1到l7中,前一层的输出作为后一层的输入,l1的输入为候选参照物粗选阶段中网络输出的是候选参照物的位置信息,即候选参照物位置区域信息所框出的图像,l7先判断当前区域的图像是否为参照物的概率,如果是,则输出的是候选参照物的区域图像。
其中,l7先判断当前区域的图像是否为参照物的概率,如果概率大于等于阈值就是参照物的概率,小于不是,如果概率大于等于,则输出候选参照物的区域图像,而阈值是通过训练获得的。
也就是说,该候选参照物精选阶段的网络模型同样为卷积神经网络,相对粗选阶段中的卷积神经网络,精选阶段的卷积神经网络模型更为复杂,网络输入为粗选阶段网络出入的参照物坐标点框出的矩形区域的图像,输出为布尔值,其中,布尔值是"真"true或"假"false中的一个,即判断当前输入的图像是否为参照物,如果是,为真,继续保留该图像,如果否,为假,则从候选组中剔除,从而对粗选阶段网络输出的候选参照物进行精选。
具体的,在通过第一卷积神经网络后,获得多个候选参照物的坐标,选取参考物概率前n个大的坐标截取图片,作为第二卷积神经网络的输入,假设当前送入网络的后期选参照物的分辨率为400*200,那么送入网络的矩阵即为:400*200*3(*3是因为rgb三个通道,同样是公知),经过l1后输出400*200*28的特征矩阵,送入l2生成200*100*28的特征矩阵,送入l3输出200*100*48的特征矩阵,送入l4输出100*50*48的特征矩阵,送入l5输出100*50*64的特征矩阵,送入l6输出100*1的特征矩阵,送入l7输出2*1的向量(g,h),其中,g表示输入图片是参照物的概率,h表示输入图片不是参照物的概率;将前m大的h所对应的参照物图片送入下一网络,即作为第三卷积神经网络的输入。
在第三卷积神经网络处理过程中,该步骤中,将第二卷积神经网络输出的所述候选参照物的区域图像输入到第三卷积神经网络按照设定参照物参照点进行特征提取,得到候选参照物的多个特征点。其中,特征点的定义和个数与预选的参照物类型有关,以人脸为例,参照点有五个,眼睛两个,鼻尖一个,嘴角两个等。
其中,第三卷积神经网络是候选参照物特征点提取阶段中所述的卷积神经网络,该第三卷积神经网络由9层组成,即l1,l2,l3,l4,l5,l6,l7,l8和l9,其中,所述的l1由32个3*3卷积核组成,步长为1的卷积层;l2为3*3池化核,步长为2的池化层;l3由64个3*3卷积核为组成,步长为1的卷积层;l4为3*3池化核,步长为2的池化层;l5由64个3*3卷积核为组成,步长为1的卷积层;l6为2*2池化核,步长为2的池化层;l7由128个2*2卷积核组成,步长为1的卷积层;l8的输出为256的全连接层,l9输出为10的全连接层。l1到l9中,前一层的输出作为后一层的输入,l1的输入为候选参照物精选阶段中网络输出的是参照物的矩形框所框出的图像,l9的输出为当前图像中的特征点坐标,本实施例以人脸的五个点坐标为例。
假设经过第二卷积神经网络的输出的图像的分辨率为400*200,那么送入第三卷积神经网络的也是400*200*3的矩阵,经过l1后输出400*200*32的特征矩阵,经过l2后输出200*100*32的特征矩阵,经过l3后输出200*100*64的特征矩阵,经过l4后输出100*50*64的特征矩阵,经过l5后输出100*50*64的特征矩阵,经过l6后输出500*25*64的特征矩阵,经过l7后输出100*50*128的特征矩阵,经过l8后输出256*1的特征矩阵,经过l4后输出10*1的向量(i,j,k,l,m,n,o,p,q,r),每两个是一组征特点的坐标(左眼球,右眼球,鼻尖,左嘴角,右嘴角)。
需要说明的是,该阶段的网络模型还是卷积神经网络,但是比前两个更为复杂,输入为经过精选的参照物的图像,输出为多个参照物的特征点,以人脸为例,参照点有五个,眼睛两个,鼻尖一个,嘴角两个等,但并不限于此,还可以是其他特征点,本实施例不作限制。
请参阅图4,其示出了本发明实施例提供的另一种镜头类型信息识别方法的流程图,用于对镜头类型信息进行修正,以提高确定镜头类型信息的准确度,其中图4所示镜头类型信息识别方法可以包括以下步骤:
s401,从视频中抽取一帧待识别图像。
s402,对待识别图像进行识别,得到待识别图像的识别结果。
s403,判断待识别图像的识别结果是否满足预设条件。如果满足预设条件则执行步骤s404,如果不满足预设条件则执行步骤s405。
s404,如果所述待识别图像的识别结果满足预设条件,基于识别结果中的人脸特征,确定待识别图像的镜头类型信息。该步骤与上述步骤s104原理相同不再赘述。
s405,如果待识别图像的识别结果不满足预设条件,则从待识别图像中确定包含人体的检测框信息,并基于包含人体的检测框信息,确定待识别图像的镜头类型信息
在本实施例中,步骤s401至步骤s405:步骤s101至步骤s105原理相同不再赘述。
s406,判断是否完成对视频中每帧待识别图像的处理,具体的判断当前处理的待识别图像是否为视频中的最后一帧图像,如当前处理的待识别图像的帧号current_frame与视频的总帧数total_frames的大小关系,如果当前处理的待识别图像的帧号current_frame等于视频的总帧数total_frames则说明完成对视频中每帧待识别图像的处理,进而执行步骤s407,如果当前处理的待识别图像的帧号current_frame小于视频的总帧数total_frames,则说明视频中仍有没有被处理的待识别图像,则进行下一个待识别图像的识别,即返回执行步骤s401。
s407,对任一帧待识别图像的镜头类型信息进行修正,以通过修正方式提高镜头类型信息的准确度,具体请参阅后续说明。
s408,将修正后的镜头类型信息存储在视频的序列中,将视频的序列中的内容转码成json返回结果输出。
例如将经过修正之后的镜头类型信息以序列的形式存储,如将经过修正之后的镜头类型信息中的镜头类型标识存储在平滑后镜头类型标识序列l'={l'1,l'2,...,l'i,...l'm}中,将经过修正之后的镜头类型信息中的镜头类型的置信度存储在平滑后镜头类型标识的置信度序列c'={c'1,c'2,...,c'i,...c'm}中,并将这两个序列视为是视频的序列,将视频的序列中的内容转码成json返回结果输出,从而便于了解镜头类型信息的处理结果情况,提高镜头类型信息的可读性。
json返回结果中包括:修正所使用代码中的错误代码error_code、错误信息error_msg和镜头段信息shot_type,其中错误信息包括但不限于:视频信息、时间信息、错误种类和错误帧数;镜头段信息包括:镜头类型标识label、镜头类型标识表明的镜头类型label_name、置信度prob、开始时间strat_time和结束时间stop_time。
其中镜头段信息可以视为是镜头类型标识相同且相邻的图像帧组成的视频中的一段;开始时间是镜头段中第一帧图像的时间,结束时间是镜头段中最后一帧图像的时间,开始时间和结束时间可通过帧数进行转换,如t=1000*f/fps,t为当前第f帧所对应的时间,这样将一个镜头段中第一帧图像在视频中的帧号和最后一帧图像在视频中的帧号分别输入到转换公式中,即可得到一个镜头段的开始时间和结束时间;视频信息包括当前处理视频名称、帧率、fps和分辨率;时间信息为出现错误的镜头类型标识对应的图像在视频中的时间;错误代码表明出现错误的镜头类型标识。
在上述转码json返回结果输出的方法可知,将修正后的镜头类型信息存储在视频的序列中,将视频的序列中的内容转码成json返回结果输出,从而了解镜头类型信息的处理结果情况,提高镜头类型信息的可读性。
下面将上述待识别图像的镜头类型信息视为待修正镜头类型信息,结合附图5对待修正镜头类型信息的修正过程进行说明,其中图5所示镜头类型信息修正方法可以包括以下步骤:
s501,确定待修正镜头类型信息的参考镜头类型信息。
可以理解的是:将上述一个视频中图像(即上述待识别图像)的镜头类型信息存储在序列中,如镜头类型信息包括镜头类型标识和镜头类型标识的置信度,将每个图像的镜头类型标识存储在原始镜头类型标识序列中,将每个图像的镜头类型标识的置信度存储在原始镜头类型标识的置信度序列中,并且对每个图像来说,该图像的镜头类型标识在原始镜头类型标识序列中的排序与其置信度在原始镜头类型标识的置信度序列中的排序相同,从而便于获取同一个图像的镜头类型标识和置信度,防止镜头类型标识和置信度获取有误。
在将每个图像的镜头类型信息存储在对应序列的情况下,可以从序列中确定出待修正镜头类型信息和参考镜头类型信息,如依次选取序列中各个信息作为待修正镜头类型信息,将序列中除作为待修正镜头类型信息之外的至少部分信息确定为参考镜头类型信息,如将与待修正镜头类型信息相邻的信息确定为参考镜头类型信息。
以原始镜头类型标识序列和原始镜头类型标识的置信度序列为例,从这两个序列中选取第一个信息作为待修正镜头类型信息,则这两个序列中除第一个信息之外的其他信息中的至少部分则可以作为参考镜头类型信息,如这两个序列中与第一个信息相邻的第二个信息作为参考镜头类型信息。由于待修正镜头类型信息和参考镜头类型信息是同一个视频中每个图像的信息,所以待修正镜头类型信息和参考镜头类型信息具有上文关系和下文关系中的至少一种。
例如:在从视频中每提取一帧图像:确定出该帧图像的镜头类型标识和置信度之后,将该帧图像的镜头类型标识存储在原始镜头类型标识序列,将该帧图像的镜头类型标识的置信度存储在原始镜头类型标识的置信度序列,以使图像的镜头类型信息在序列中的排序和图像在视频中的出现相关,例如依据图像在视频中的出现时间决定图像的镜头类型信息在序列中的排序,以使得序列中的镜头类型信息之间具有上下文关系,相对应的在从具有上下文关系的镜头类型信息中选取的待修正镜头类型信息和确定的参考镜头类型信息之间具有上文关系和下文关系中的至少一种,如若待修正镜头类型信息对应图像的出现时间早于参考镜头类型信息对应图像的出现时间,则待修正镜头类型信息相对于参考镜头类型信息具有上文关系,反之具有下文关系,也就是说上文关系是指待修正镜头类型信息和参考镜头类型信息各自对应的图像中的一个图像是由另一个图像发展而来,下文关系是指待修正镜头类型信息和参考参考镜头类型信息各自对应的图像中从一个图像向另一个图像发展。
s502,基于待修正镜头类型信息和参考镜头类型信息,确定待修正镜头类型信息的修正参数。
在本实施例中,确定待修正镜头类型信息的修正参数的一种可行方式是:基于待修正镜头类型信息和参考镜头类型信息,确定待修正镜头类型信息的属性向量;确定融合矩阵中各个元素的取值,并基于属性向量和融合矩阵中各个元素的取值,得到待修正镜头类型信息的修正向量,并将修正向量确定为修正参数,其中融合矩阵为n×d的矩阵,d为预先设定的镜头类型的总数,n-1为参考镜头类型信息的总数。
在本实施例中,融合矩阵的获取方式可以是:首先初始化一个元素的取值均为零的n×d矩阵f,然后从循环参数e=1开始,如果e小于等于n,则矩阵f中的元素f[e][le]=1,并对e执行加一操作,继续执行“如果e小于等于n,则矩阵f中的元素f[e][le]=1,并对e执行加一操作”直至e大于n,结束,此时得到的矩阵f为融合矩阵。在元素f[e][le]=1中le为待修正镜头类型信息和参考镜头类型信息中的各个镜头类型标识组成的序列中的第e个镜头类型标识,根据e和le更改矩阵f中元素f[e][le]的取值。
相对应的属性向量的获取方式有但不限于下述三种方式:
一种方式:对待修正镜头类型信息和参考镜头类型信息中任一镜头类型标识的置信度:基于该镜头类型标识的置信度和预设置信度变换规则,得到该镜头类型标识的置信度对应的第一属性的取值,其中第一属性的取值用于表明该镜头类型标识在本次修正所需的所有镜头类型标识(即步骤s601中的待修正镜头类型信息和确定的参考镜头类型信息中的所有镜头类型标识)中的重要程度;由每个镜头类型标识的置信度对应的第一属性的取值组成属性向量。
另一种方式:对待修正镜头类型信息和参考镜头类型信息中任一镜头类型标识:基于该镜头类型标识和预设镜头类型变换规则,得到该镜头类型标识对应的第二属性的取值,第二属性的取值用于防止待修正镜头类型信息中的镜头类型标识发生跃变;由每个镜头类型标识对应的第二属性的取值组成属性向量。所谓跃变表明镜头类型标识从某一个标识跳变至与其间隔在预设间隔范围的标识,以上述表1为例,当镜头类型标识从1跳变至5时,则说明存在跃变;若镜头类型标识从1跳变至2,则说明不存在跃变,在本实施例中通过第二属性的取值可以缩小待修正镜头类型信息中的镜头类型标识与参考镜头类型信息中的镜头类型标识之间的差值,以此来防止待修正镜头类型信息中的镜头类型标识发生跃变,对于预设间隔范围可以是实际应用而定,本实施例不对其进行限定。
再一种方式:对待修正镜头类型信息和参考镜头类型信息中任一镜头类型标识的置信度:基于该镜头类型标识的置信度和预设置信度变换规则,得到该镜头类型标识的置信度对应的第一属性的取值;对待修正镜头类型信息和参考镜头类型信息中任一镜头类型标识:基于该镜头类型标识和预设镜头类型变换规则,得到该镜头类型标识对应的第二属性的取值;由每个镜头类型标识的置信度对应的第一属性的取值组成属性向量中的第一属性向量,并由每个镜头类型标识对应的第二属性的取值组成属性向量中的第二属性向量。
其中预设置信度变换规则和预设镜头类型变换规则是根据已有数据总结出的变换规则,如预设置信度变换规则和预设镜头类型变换规则可由映射函数表示,如由双曲函数,relu函数,elu函数,prelu函数等中的任意一种,若预设置信度变换规则和预设镜头类型变换规则选用同一种映射函数,还可以采用同一种映射函数的不同计算方式,下面以双曲函数为例进行说明:
预设置信度变换规则可以是:wi=f(ki×ci),i∈[1,n],f()是作为预设置信度变换规则的双曲函数,ki为n维向量中的第i个元素,ci为由待修正镜头类型信息和参考镜头类型信息中的各个镜头类型标识组成的序列(排序与在原始镜头类型标识序列中的排序相同)中的第i个镜头类型标识的置信度,wi为第i个镜头类型标识对应的第一属性的取值。
预设镜头类型标识变换规则可以是:di=1-abs(g(ki×li-1))),i∈[2,n],且d1=1,g()是作为预设镜头类型标识变换规则的双曲函数,abs()为绝对值函数,di为第i个镜头类型标识对应的第二属性的取值。
在本实施例中,第一属性的一种表现形式可以是权重,即通过上述预设置信度变换规则得到待修正镜头类型信息和参考镜头类型信息中任一镜头类型标识对应的权重的取值,以基于权重的取值确定任一镜头类型标识在本次修正的所有镜头类型标识中的重要程度,第二属性的一种表现形式可以是距离,之所以采用距离表示是因为距离越大对应的可信度越低,距离越小对应的可信度越高,由此基于距离来防止镜头类型跃变。并且从上述三种属性向量的获取方式可知,本实施例中属性向量可以表明待修正镜头类型信息和参考镜头类型信息的重要程度,和/或防止待修正镜头类型信息发生跃变。
下面以原始镜头类型标识序列l={1,1,1,1,1,1,4,4,1,1,1,1,1),原始镜头类型标识的置信度序列c={0.95,0.85,0.75,0.88,0.75,0.89,0.87,0.87,0.84,0.89,0.87,0.97,0.97},预设的n维向量k=[0.7,0.8,0.91,0.9,0.8,0.7],预设比例系数α=0.6为例,对原始镜头类型标识序列中的第7个镜头类型标识和原始镜头类型标识的置信度序列中的第7个镜头类型标识的置信度进行修正(第7个镜头类型标识和置信度即为待修正镜头类型信息),参考镜头类型信息则为第7个镜头类型标识前3位和后3位的数据,则待修正镜头类型信息和参考镜头类型信息组成的类型标识序列为:{1,1,1,4,4,1,1},组成的置信度序列为{0.88,0.75,0.89,0.87,0.87,0.84,0.89,0.87}。采用上述预设置信度变换规则:wi=f(ki×ci)得到的各个取值如下:
w1=f(k1×c1)=f(0.7×0.88)=f(0.616)=0.5483
w2=f(k2×c2)=f(0.8×0.75)=f(0.600)=0.5370
w3=f(k3×c3)=f(0.9×0.89)=f(0.801)=06646
w4=f(k4×c4)=f(1.0×0.87)=f(0.870)=0.7014
w5=f(k5×c5)=f(0.9×0.84)=f(0.756)=0.6387
w6=f(k6×c6)=f(0.8×0.89)=f(0.712)=0.6119
w7=f(k7×c7)=f(0.7×0.87)=f(0.609)=0.5434
故第一属性向量w=[0.5483,0.5370,0.6646,0.7014,0.6387,0.6119,0.5434]。
采用上述预设镜头类型标识变换规则:di=1-abs(g(ki×(li-li-1)))得到的各个取值如下:
d1=1
d2=1-abs(g(k2×(l2-l2-1)))=1-abs(g(0.8×1-1)))=1.0000
d3=1-abs(g(k3×(l3-l3-1)))=1-abs(g(0.8×1-1)))=1.0000
d4=1-abs(g(k4×(l4-l4-1)))=1-abs(g(0.8×4-1)))=0.7645
d5=1-abs(g(k5×(l5-l5-1)))=1-abs(g(0.8×4-4)))=1.0000
d6=1-abs(g(k6×(l6-l6-1)))=1-abs(g(0.8×1-1)))=0.7645
d7=1-abs(g(k7×(l7-l7-1)))=1-abs(g(0.8×1-1)))=1.0000
故第二属性向量d=[1.0000,1.0000,1.0000,0.7645,1.0000,0.7645,1.000]。
融合矩阵f为:
相应的,基于上述第一属性向量、第二属性向量和融合矩阵得到的修正向量如下:
a=w×f×a+d×f×(1-α)=[4.6018,0,0,1.8628,0,0]。
若直接将上述第一属性向量作为属性向量,则得到修正向量基于的计算公式可以是:a=d×f×α,若直接将上述第二属性向量作为属性向量,则得到修正向量基于的计算公式可以是:a=d×f×α,当然还可以采用其他方式,对此本实施例不再一一阐述。
此外预设置信度变换规则和预设镜头类型标识变换规则还可以采用其他方式,如在视频中相邻图像的镜头类型标识相同的几率较大且发生跃变的几率较小,基于此可以预先根据参考镜头类型信息相对于待修正镜头类型信息在序列中的排序间隔来设置第一属性和第二属性的计算参数,则预设置信度变换规则和预设镜头类型标识变换规则可以是:记录计算参数与排序间隔之间的对应关系。这里需要说明的是:本实施例中的预设置信度变换规则和预设镜头类型标识变换规则仅是举例说明,其他适用于本实施例中的规则都属于本实施例的保护范围。
除将修正向量作为修正参数之外,本实施例还可以采用其他方式来得到修正参数,如预设待修正镜头类型信息和参考镜头类型信息中各个镜头类型标识的权重,基于各个镜头类型标识的权重和各个镜头类型标识,得到用于修正待修正镜头类型信息中的镜头类型标识的修正参数,如基于各个镜头类型标识的权重对各个镜头类型标识进行加权求和平均。同样的还可以预设待修正镜头类型信息和参考镜头类型信息中各个镜头类型标识的置信度的权重,基于各个置信度的权重和各个置信度,得到用于修正待修正镜头类型信息中镜头类型标识的置信度的修正参数。
s503,基于修正参数,对待修正镜头类型信息进行修正。以上述修正向量作为修正参数为例,对待修正镜头类型信息进行修正的过程如下:
从作为修正参数的修正向量中确定符合预设条件的元素,并获取符合预设条件的元素在修正向量中的排序,基于符合预设条件的元素在修正向量中的排序,确定待修正镜头类型信息中的镜头类型标识,并基于符合预设条件的元素的取值和修正向量中各个元素的取值,得到待修正镜头类型信息中的镜头类型标识的置信度。
如将符合预设条件的元素在修正向量中的排序确定为待修正镜头类型信息的镜头类型标识,例如符合预设条件的元素为修正向量中取值最大的元素,则将该取值最大的元素在修正向量中的排序确定为待修正镜头类型信息的镜头类型标识,而置信度的获得方式可以是:将取值最大的元素和修正向量中所有元素的取值之和的比值确定为待修正镜头类型信息的镜头类型标识的置信度。
以上述修正向量a=w×f×a+d×f×(1-α)=[4.6018,0,0,1.8628,0,0]为例,取值最大的元素为4.6018,其在修正向量中的排序为1,则待修正镜头类型信息的镜头类型标识从4修改为1,置信度则为:
4.6018÷(4.6018+0+0+1.8628+0+0)=0.7118。
若基于预设权重得到用于修正待修正镜头类型信息的镜头类型标识的修正参数和用于修正待修正镜头类型信息的镜头类型标识的置信度的修正参数,则基于这两个修正参数修正待修正镜头类型信息的的方式可以是:对用于修正待修正镜头类型信息的镜头类型标识的修正参数进行向上取整,将得到的取值作为待修正镜头类型信息的镜头类型标识,将用于修正待修正镜头类型信息的镜头类型标识的置信度的修正参数作为待修正图像的置信度。
从上述修正镜头类型信息方法可知,在确定待修正镜头类型信息的参考镜头类型信息的情况下,基于待修正镜头类型信息和参考他镜头类型信息,确定待修正镜头类型信息的修正参数,基于修正参数对待修正镜头类型信息进行修正;由于待修正镜头类型信息和参考镜头类型信息具有上文关系和下文关系中的至少一种,而具有上文关系和下文关系中的一种关系的参考镜头类型信息和待修正镜头类型信息具有相似性,所以通过具有上文关系和下文关系中的一种关系的参考镜头类型信息来修正待修正镜头类型信息,以此提高待修正镜头类型信息的准确度。
请参阅图6,其示出了本发明实施例提供的另一种镜头类型信息修正方法,可以包括以下步骤:
s601,对存储待修正镜头类型信息的序列进行边界填充,得到填充序列。所谓边界填充是指在存储待修正镜头类型信息的序列的左侧和右侧中的至少一次进行填充,如在左侧和右侧分别填充,其中存储待修正镜头类型信息的序列是原始镜头类型标识序列和原始镜头类型标识的置信度序列中的至少一个序列,这样在任一待修正镜头类型信息进行修正时,均可以基于该待修正镜头类型信息在序列中的排序,从其排序前后分别得到参考镜头类型信息,以防止待修正镜头类型信息修正后对应的序列的维度与原始镜头类型标识序列的维度不同。
在本实施例中,边界填充的一种方式是:若存储待修正镜头类型信息的序列包括原始镜头类型标识序列,则在原始镜头类型标识序列的左侧填充j个第一预设数,在原始镜头类型标识序列的右侧填充k个第二预设数,其中第一预设数和第二预设数据可以相同,如两者都可以为-1,或者第一预设数和第二预设数也可以不同,对此本实施例不再阐述。
若存储待修正镜头类型信息的序列包括原始镜头类型标识的置信度序列,则在原始镜头类型标识的置信度序列的左侧填充j个第三预设数,在原始镜头类型标识序列的右侧填充k个第四预设数,其中第三预设数和第四预设数据可以相同,如两者都可以为-0,或者第三预设数和第四预设数也可以不同,对此本实施例不再阐述。
在这里需要说明的一点是:原始镜头类型标识的置信度序列的填充方向与原始镜头类型标识序列的填充方向相同,如原始镜头类型标识序列在左侧填充,则原始镜头类型标识的置信度序列也需要在左侧填充。
s602,基于待修正镜头类型信息在填充序列的排序,从填充序列中确定出待修正镜头类型信息的参考镜头类型信息,如将填充序列中位于排序之前的j个信息和位于排序之后的k个信息确定为参考镜头类型信息,j和k均为大于等于1的自然数。
若仅对存储待修正镜头类型信息的序列的一侧进行填充,则对于没有填充一侧的第一个待修正镜头类型信息来说,仅能选取其一侧的参考镜头类型信息。如仅对存储待修正镜头类型信息的序列的左侧进行填充,则右侧的第一个待修正镜头类型信息,仅能选取其左侧的信息为参考镜头类型信息。
通过上述方式确定参考镜头类型信息之后,该待修正镜头类型信息对应有一个滑动计算区,该滑动计算区的长度o=j+k+1,其中j为已平滑参考区(即填充序列中位于该待修正镜头类型信息之前的区域),k为待平滑参考区(即填充序列中位于该待修正镜头类型信息之后的区域)。即确定的参考镜头类型信息和待修正镜头类型信息组成一个滑动计算区,通过滑动计算区中的参考镜头类型信息对待修正镜头类型信息进行修正,在实际应用中,可以从原始镜头类型标识序列和原始镜头类型标识的置信度序列中的第1个元素作为待修正镜头类型信息,通过确定参考镜头类型信息来确定该第1个元素对应的滑动计算区,然后为第2个元素确定滑动计算区,以此类推为每个元素分别确定一个滑动计算区,且相邻的两个元素之间的滑动计算区中后一个元素的滑动计算区是在前一个元素的滑动计算区的基础上向后滑动一个元素,而这一过程视为是一个平滑过程,因此本实施例中对待修正镜头类型信息的修正是在平滑选取滑动计算区的基础上进行修正,该修正过程包括了滑动计算区的平滑过程,对待修正镜头类型信息进行修正后得到的序列视为是平滑后镜头类型标识序列和平滑后镜头类型标识的置信度序列。
在这需要说明的一点是:虽然对存储待修正镜头类型信息的序列进行边界填充,但是在修正时仍仅从存储待修正镜头类型信息的序列中的第1个数据开始修正,而非填充序列的第1个元素开始。以存储待修正镜头类型信息的序列为原始镜头类型标识序列为例,在修正时仍仅从原始镜头类型标识序列中的第1个镜头类型标识开始修正,而非填充序列的第1个元素开始
s603,基于待修正镜头类型信息和参考镜头类型信息,确定待修正镜头类型信息的修正参数。
s604,基于修正参数,对待修正镜头类型信息进行修正。
在本实施例中,步骤s703和步骤s704:与上述方法实施例中的步骤s602至步骤s603相同,对此本实施例不再阐述。
以修正参数为修正向量,且计算修正向量采用的属性向量包括:第一属性向量(权重向量)和第二属性向量(距离向量)为例,结合图7对本实施例提供的镜头信息修正方法进行说明:
原始镜头类型标识序列进行两个边界填充,得到类型标识序列,从类型标识序列中隶属原始镜头类型标识序列的第1个镜头类型标识开始进行修正,以原始镜头类型标识序列的第i个镜头类型标识为例,选取第i个镜头类型标识的已平滑参考区和待平滑参考区,以获得第i个镜头类型标识的滑动计算区,基于该滑动计算区得到修正第i个镜头类型标识所需参考的镜头类型标识和所需参考的镜头类型标识的置信度,由第i个镜头类型标识和得到的镜头类型标识组成类型标识序列,由第i个镜头类型标识和得到的镜头类型标识的置信度组成置信度序列,基于类型标识序列、预设的n维向量和作为预设镜头类型标识变换规则的映射函数,得到距离向量,基于置信度序列、预设的n维向量和作为预设置信度变换规则的映射函数,得到权重向量。
基于距离向量、权重向量和预设比例系数,得到作为修正参数的修正向量,基于修正向量对待修正镜头类型信息中的镜头类型标识和镜头类型标识的置信度进行修正,实现对待修正图像的镜头信息的修正。
从上述技术方案可知,通过对存储待修正镜头类型信息的序列的两个边界的填充,使得任一待修正镜头类型信息可以基于与其具有上文关系和下文关系的参考镜头类型信息进行修正,提高修正准确度,并且在对任一待修正镜头类型信息进行修正后,得到的平滑后序列(平滑后镜头类型标识序列和平滑后镜头类型标识的置信度序列中的至少一个序列,由对待修正镜头类型信息中的哪些信息修正决定)的维度与存储待修正镜头类型信息的序列的维度相同,从而防止待修正镜头类型信息的丢失。
与上述方法实施例相对应,本发明实施例还提供一种镜头类型信息识别装置,其结构如图11所示,可以包括:抽取单元11、识别单元12、判断单元13、第一确定单元14和第二确定单元15。
抽取单元11,用于从视频中抽取一帧待识别图像。其中待识别图像可以是视频中的原始图像,或者是对原始图像进行调整后的图像,如对原始图像进行格式调整,得到一张w*h的待识别图像,其中w为预设的待识别图像的宽度,h为预设的待识别图像的高度,以保证待识别图像之间的格式统一,从而降低因格式问题导致镜头类型信息有误,对于预设的待识别图像的宽度和预设的待识别图像的高度可以基于实际应用而定。
在实际应用中,从视频中抽取一帧待识别图像可以是从视频的第一帧开始依次抽取来进行镜头类型信息计算,其中视频的总帧数total_frames、视频每秒传输帧数fps和跳帧数skip_frame,从视频的帧号current_frame=0(第一帧)开始依次得到待识别图像。
识别单元12,用于对待识别图像进行识别,得到待识别图像的识别结果。例如通过人脸识别技术对待识别图像进行识别,得到人脸特征,该人脸特征可作为待识别图像的识别结果中的内容,其中人脸特征包括但不限于:两眼特征点(如两个眼球各自的中心点)、嘴巴特征点(如嘴巴的两个嘴角特征点)、鼻子特征点(如一个鼻尖点)等,当然在得到人脸特征点之后还可以通过人脸特征点中的各个特征点来计算出人脸的不同部位(如眼睛和嘴巴)之间的距离,将通过人脸特征点中的各个特征点计算出的人脸的不同部位之间的距离也可以视为是待识别图像的识别结果中的部分结果。
又或者预先得到一个人脸识别模型,该人脸识别模型将待识别图像作为输入,将人脸特征点作为输出,这样在抽取到任一待识别图像后可以将该待识别图像输入到人脸识别模型中,通过人脸识别模型输出人脸特征点,对于该人脸识别模型输出人脸特征点的内容可以根据实际应用而定,如输出上述两眼特征点(如两个眼球各自的中心点)、嘴巴特征点(如嘴巴的两个嘴角特征点)、鼻子特征点(如一个鼻尖点)等中的至少一种,对于人脸识别模型的训练过程和修正过程,本实施例不在阐述。
判断单元13,用于判断待识别图像的识别结果是否满足预设条件。其中预设条件可以是成功识别面部特征点,进一步的还可以限定人脸特征点符合预设内容,所谓预设内容可以是人脸特征点中包括的所有特征点的个数不超过预设个数和/或人脸特征点中包含预设类型的特征点,如包含两眼特征点和嘴巴特征点,对于预设个数和预设类型,本实施例不加以限定。当然预设条件也可以根据实际应用发生变化,对此本实施例也不再阐述。
第一确定单元14,用于如果待识别图像的识别结果满足预设条件,则基于识别结果中的人脸特征,确定待识别图像的镜头类型信息。例如一种确定方式是:基于人脸特征,得到人脸的特征距离,计算特征距离和待识别图像的高度之间的比值,并基于特征距离和待识别图像的高度之间的比值,确定待识别图像的镜头类型信息,具体请参阅方法实施例中的相关说明。
第二确定单元15,用于如果待识别图像的识别结果不满足预设条件,则从待识别图像中确定包含人体的检测框信息,并基于包含人体的检测框信息,确定待识别图像的镜头类型信息。例如一种确定方式是:基于包含人体的检测框信息,确定检测框的高度,计算检测框的高度与待识别图像的高度之间的比值,并基于检测框的高度与待识别图像的高度之间的比值,确定待识别图像的镜头类型信息,具体请参阅方法实施例中的相关说明。
从上述技术方案可知,从视频中抽取一帧待识别图像,对待识别图像进行识别,得到待识别图像的识别结果,若识别结果满足预设条件则基于识别结果中的人脸特征进行镜头类型计算以确定镜头类型信息;若识别结果不满足预设条件则进行人体识别,确定包含人体的检测框信息,并基于包含人体的检测框信息进行镜头类型计算以确定镜头类型信息,由此实现镜头类型信息的自动确定,提高确定镜头类型信息的效率,从而节约时间成本和人员成本,并且通过人脸特征和包含人体的检测框信息确定镜头类型信息的方式,使得在基于人脸特征无法识别的情况下仍可通过包含人体的检测框信息来确定镜头类型信息,提高识别自动化和准确度。
请参阅图12,其示出了本发明实施例提供的另一种镜头类型信息识别装置的结构,在图11基础上还可以包括:修正单元16,用于判断是否完成对视频中每帧待识别图像的处理,如果是,则对任一帧待识别图像的镜头类型信息进行修正,如果否,则触发抽取单元11从视频中抽取没有确定镜头类型信息的待识别图像。
其中对待识别图像的镜头类型信息修正是指对待识别图像的镜头类型信息中的镜头类型标识和镜头类型标识的置信度中的至少一种进行修正,而镜头类型标识的置信度可以由第一确定单元14和第二确定单元15得到,对于这两种信息的修正过程请参阅方法实施例,对此本实施例不再详述。
相对应的,本实施例提供的镜头类型信息识别装置还可以包括:存储单元和输出单元。存储单元,用于将修正后的镜头类型信息存储在视频的序列中,如将经过修正之后的镜头类型信息中的镜头类型标识存储在平滑后镜头类型标识序列l'={l1',l'2,...,li',...l'm}中,将经过修正之后的镜头类型信息中的镜头类型的置信度存储在平滑后镜头类型标识的置信度序列c'={c1',c'2,...,ci',...c'm}中。输出单元,用于将视频的序列中的内容转码成json返回结果输出,其中json返回结果包括:修正所使用代码中的错误代码、视频信息、视频中镜头类型错误的图像信息、各个待识别图像对应的镜头段信息,从而便于了解镜头类型信息的处理结果情况,提高镜头类型信息的可读性,对于json返回结果包括的信息的说明请参阅方法实施例。
此外,本发明实施例还提供一种网络设备,该网络设备包括存储器和处理器,其中处理器用于实现上述镜头类型信息识别方法,存储器用于存储经过上述镜头类型信息识别方法得到的镜头类型信息。
本发明实施例还提供一种存储介质,该存储介质上存储有计算机程序代码,计算机程序代码执行时实现上述镜头类型信息识别方法。
需要说明的是,本说明书中的各个实施例均采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似的部分互相参见即可。对于装置类实施例而言,由于其与方法实施例基本相似,所以描述的比较简单,相关之处参见方法实施例的部分说明即可。
最后,还需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个……”限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。
对所公开的实施例的上述说明,使本领域技术人员能够实现或使用本发明。对这些实施例的多种修改对本领域技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本发明的精神或范围的情况下,在其它实施例中实现。因此,本发明将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!