视频图像中人物说话的识别方法和装置与流程
本发明涉及移动通信技术,特别是涉及一种视频图像中人物说话的识别方法和装置。
背景技术:
随着计算机视觉的不断发展,人脸识别相关算法不断完善,应用场景的不断增多,人脸识别的技术尽管仍存在一些问题,但较早年已相对成熟。
在现实场景中,人脸识别技术已经应用于数码相机、门禁系统、身份识别、网络应用、娱乐应用等多个相关领域,如:人脸自动对焦和笑脸快门技术、受安全保护的地区可以通过人脸识别辨识试图进入者的身份、电子护照及身份证识别、辅助信用卡网络支付、图片对比等。
现今对于说话人识别的相关领域技术主要为通过对说话人语音信号的分析处理,自动确认是别人是否在所记录的话者集合中,以及进一步确认说话人是谁,主要应用于音频领域的识别。而与判断视频图像中人物是否说话的方法具有相关性的姿态识别算法主要以深度学习的训练为主,与其他深度学习的情况类似,也存在着:需要以大量数据作为训练基础,训练所得的结果难以应用到其他问题上的局限性。
技术实现要素:
有鉴于此,本发明的主要目的在于提供一种视频图像中人物说话的识别方法和装置,易于实现,具有广泛的应用性。
为了达到上述目的,本发明提出的技术方案为:
一种视频图像中人物说话的识别方法,包括:
a、将待检测视频流的起始帧作为当前的检测帧;
b、从当前的检测帧开始,逐帧检测当前是否存在满足说话识别条件的视频帧序列;所述说话识别条件为连续n帧均包含预设的人脸口部特征点集合对应的特征数据,n≥1;
c、当检测到所述视频帧序列时,根据该视频帧序列对应的特征数据,确定当前的说话临界判断值;
d、利用所述说话临界判断值,逐一对所述视频帧序列的后续帧中包含的相应人像的说话状态进行识别,直至当前帧中不存在所述人像或者当前帧为所述视频流的最后一帧;
e、如果当前帧中不存在所述人像且当前帧不是所述视频流的最后一帧,则将本帧作为当前的检测帧,返回步骤b。
较佳地,所述逐帧判断当前是否存在满足说话识别条件的视频帧序列包括:
从当前的检测帧开始,逐帧检测当前帧是否包含人脸且包含了所述人脸口部特征点集合的特征数据,如果是,则记录人脸所在区域的编号,在后续帧中根据所述编号,进行相应的人脸检测,并在检测到连续n帧均包含所述人脸口部特征点集合的特征数据时,将该连续n帧确定为当前满足所述说话识别条件的视频帧序列。
较佳地,步骤c中所述确定当前的说话临界判断值包括:
对于当前满足所述说话识别条件的视频帧序列的每一帧,计算该帧对应的所述人脸口部特征点集合的特征数据的均方差;
按照预设的统计周期或滑动窗口,计算每个所述统计周期或所述滑动窗口内的所述均方差的均值m0和均方差cri;
根据所述均值m0,得到当前的人像说话频率类型;
根据所述人像说话频率类型和所述均方差cri,确定当前的说话临界判断值。
较佳地,所述人像说话频率类型包括:没有说话、少量说话和大量说话。
较佳地,根据所述人像说话频率类型,确定当前的说话临界判断值包括:
当所述人像说话频率类型为没有说话时,按照crireal=crimax+preset,得到当前的说话临界判断值,其中,crireal为当前的说话临界判断值,crimax为所述均方差cri中的最大值;preset为预设的增值系数。
较佳地,根据所述人像说话频率类型,确定当前的说话临界判断值包括:
当所述人像说话频率类型为少量说话时,将所述均方差cri,按照数值的升序进行排序,得到均方差队列;
计算所述均方差队列中每对相邻均方差的差值,从最大的所述差值对应的两个均方差中,选择数值小的平均值mcri作为当前的说话临界判断值。
较佳地,根据所述人像说话频率类型,确定当前的说话临界判断值包括:
当所述人像说话频率类型为大量说话时,计算所述均方差cri的平均值mcri;
从所述均方差cri中,查找出小于所述平均值mcri且最接近所述平均值mcri的均方差,并确定所查找出的均方差对应的帧号i;
将所述视频帧序列的第1帧到第i帧之间的所述均方差cri,按照数值的升序进行排序,得到均方差队列;
计算所述均方差队列中每对相邻均方差的差值,从最大的所述差值对应的两个均方差中,选择数值小的平均值mcri作为当前的说话临界判断值。
较佳地,所述逐一对所述视频帧序列的后续帧中包含的相应人像的说话状态进行识别包括:
如果所述视频帧序列之后的帧包含相应人像,则计算每帧对应的所述人脸口部特征点集合的特征数据的均方差,并按照所述统计周期或滑动窗口,在每个所述统计周期或所述滑动窗口,计算本统计周期或本滑动窗口内的所述均方差的均方差crik;
如果所述crik大于当前的说话临界判断值,则判定所述人像在说话,否则判定所述人像未说话。
较佳地,所述方法进一步包括:
对于所述视频帧序列之后的每帧,逐帧检测当前是否存在满足说话识别条件的视频帧序列,当检测到所述视频帧序列时,根据该视频帧序列对应的特征数据,得到相应的说话临界判断值,利用所述说话临界判断值对当前的说话临界判断值进行更新。
一种视频图像中人物说话的识别装置,包括:
初始化单元,用于将待检测视频流的起始帧作为当前的检测帧;
检测单元,用于从当前的检测帧开始,逐帧检测当前是否存在满足说话识别条件的视频帧序列;所述说话识别条件为连续n帧均包含预设的人脸口部特征点集合对应的特征数据,n≥1;
临界确定单元,用于当检测到所述视频帧序列时,根据该视频帧序列对应的特征数据,确定当前的说话临界判断值;
说话识别单元,用于利用所述说话临界判断值,逐一对所述视频帧序列的后续帧中包含的相应人像的说话状态进行识别,直至当前帧中不存在所述人像或者当前帧为所述视频流的最后一帧;
遍历控制单元,用于如果当前帧中不存在所述人像且当前帧不是所述视频流的最后一帧,则将本帧作为当前的检测帧,触发检测单元执行。
较佳地,所述临界确定单元,用于从当前的检测帧开始,逐帧检测当前帧是否包含人脸且包含了所述人脸口部特征点集合的特征数据,如果是,则记录人脸所在区域的编号,在后续帧中根据所述编号,进行相应的人脸检测,并在检测到连续n帧均包含所述人脸口部特征点集合的特征数据时,将该连续n帧确定为当前满足所述说话识别条件的视频帧序列。
较佳地,所述临界确定单元,用于对于当前满足所述说话识别条件的视频帧序列的每一帧,计算该帧对应的所述人脸口部特征点集合的特征数据的均方差;按照预设的统计周期或滑动窗口,计算每个所述统计周期或所述滑动窗口内的所述均方差的均值m0和均方差cri;根据所述均值m0,得到当前的人像说话频率类型;根据所述人像说话频率类型和所述均方差cri,确定当前的说话临界判断值。
较佳地,所述人像说话频率类型包括:没有说话、少量说话和大量说话。
较佳地,所述临界确定单元,用于当所述人像说话频率类型为没有说话时,按照crireal=crimax+preset,得到当前的说话临界判断值,其中,crireal为当前的说话临界判断值,crimax为所述均方差cri中的最大值;preset为预设的增值系数。
较佳地,所述临界确定单元,用于当所述人像说话频率类型为少量说话时,将所述均方差cri,按照数值的升序进行排序,得到均方差队列;计算所述均方差队列中每对相邻均方差的差值,从最大的所述差值对应的两个均方差中,选择数值小的平均值mcri作为当前的说话临界判断值。
较佳地,所述临界确定单元,用于当所述人像说话频率类型为大量说话时,计算所述均方差cri的平均值mcri;从所述均方差cri中,查找出小于所述平均值mcri且最接近所述平均值mcri的均方差,并确定所查找出的均方差对应的帧号i;将所述视频帧序列的第1帧到第i帧之间的所述均方差cri,按照数值的升序进行排序,得到均方差队列;计算所述均方差队列中每对相邻均方差的差值,从最大的所述差值对应的两个均方差中,选择数值小的平均值mcri作为当前的说话临界判断值。
较佳地,所述说话识别单元,用于如果所述视频帧序列之后的帧包含相应人像,则计算每帧对应的所述人脸口部特征点集合的特征数据的均方差,并按照所述统计周期或滑动窗口,在每个所述统计周期或所述滑动窗口,计算本统计周期或本滑动窗口内的所述均方差的均方差crik;如果所述crik大于当前的说话临界判断值,则判定所述人像在说话,否则判定所述人像未说话。
较佳地,所述装置进一步包括更新单元,用于对于所述视频帧序列之后的每帧,逐帧检测当前是否存在满足说话识别条件的视频帧序列,当检测到所述视频帧序列时,根据该视频帧序列对应的特征数据,得到相应的说话临界判断值,利用所述说话临界判断值对当前的说话临界判断值进行更新。
一种视频图像中人物说话的识别装置,包括:
存储器;以及耦接至所述存储器的处理器,所述处理器被配置为基于存储在所述存储器中的指令,执行如上述的方法。
一种计算机可读存储介质,其上存储有计算机程序,其特征在于,该程序被处理器执行时实现上述的方法。
综上所述,本发明提出的视频图像中人物说话的识别方法和装置,基于视频中人物图像的口部特征,判断人像当前时刻是否在说话的方法,针对不同应用场景,不同人像的说话特征自行进行判断,无需提前针对特定人物进行数据采集和针对性训练,也不需要借助音频进行识别,因此,易于实现,具有广泛应用性,有效克服了深度学习训练方案所存在的应用受限问题。
附图说明
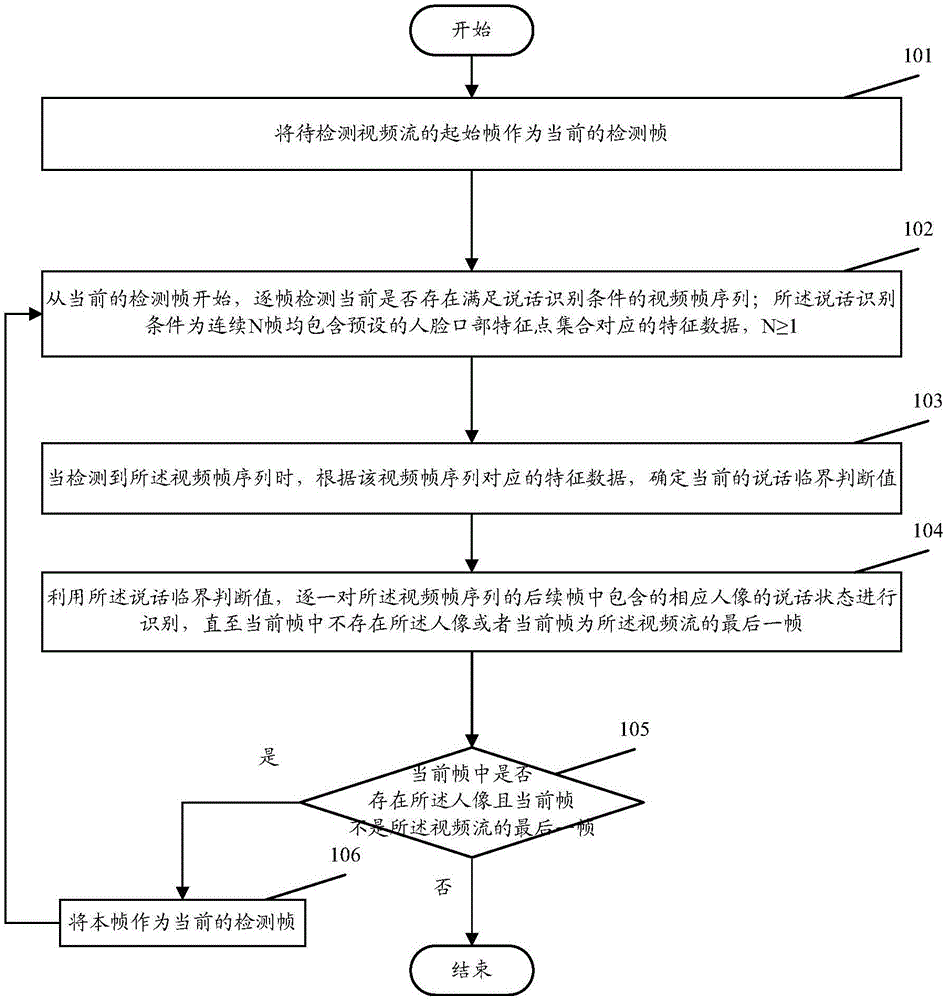
图1为本发明实施例的方法流程示意图;
图2为本发明实施例中根据统计周期获取的均方差cri图表示意图;
图3为本发明实施例中根据滑动窗口获取的均方差cri图表示意图;
图4为本发明实施例的装置结构示意图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面将结合附图及具体实施例对本发明作进一步地详细描述。
图1为本发明实施例的方法流程示意图,如图1所示,该实施例实现的视频图像中人物说话的识别方法主要包括:
步骤101、将待检测视频流的起始帧作为当前的检测帧。
本步骤用于从待检测视频流的起始帧进行检测。
在实际应用中,所述待检测视频流可以为实时视频流,也可以为任意场景下已存储的视频流。
步骤102、从当前的检测帧开始,逐帧检测当前是否存在满足说话识别条件的视频帧序列。
所述说话识别条件为连续n帧均包含预设的人脸口部特征点集合对应的特征数据,n≥1。也就是说,如果检测到连续多帧有人像且每帧都包含人脸口部特征点集合对应的特征数据,则可以对其中的人像进行说话识别。
本领域技术人员可以根据实际需要设置合适的n值,例如可以取值为100帧,但不限于此。
在实际应用中,所述人脸口部特征点集合包含的特征点具体可由本领域技术人员根据实际需要设置。
例如,在获得单张的人脸图后,基于dlib模型的人脸面部68个特征点,可以在其中所有口部特征的20个特征点中选取编号为51、52、53、57、58、59这六个特征点构成所述人脸口部特征点集合。
较佳地,本步骤中可以采用下述方法逐帧判断当前是否存在满足说话识别条件的视频帧序列:
从当前的检测帧开始,逐帧检测当前帧是否包含人脸且包含了所述人脸口部特征点集合的特征数据,如果是,则记录人脸所在区域的编号,在后续帧中根据所述编号,进行相应的人脸检测,并在检测到连续n帧均包含相应人像的所述人脸口部特征点集合的特征数据时,将该连续n帧确定为当前满足所述说话识别条件的视频帧序列。
这里,当连续n帧均包含所述人脸口部特征点集合的特征数据时,说明连续多帧均检测到相应的人像,且均具有可以用于进行说话识别的特征数据,因此,此时可以进一步利用这些帧确定用于说话识别的参数,并对后续帧的人像进行说话状态的识别。
需要说明的是,上述方法中通过对检测到的人脸所在区域进行编号,并根据该区域的编号进行相应人像的检测和特征数据的提取,这样,当视频流中存在多人图像时,可以对每个人的特征数据进行独立地提取和处理,从而可以实现对每人说话状态的独立判断,提高检测的准确性。
步骤103、当检测到所述视频帧序列时,根据该视频帧序列对应的特征数据,确定当前的说话临界判断值。
较佳地,步骤103中可以采用下述方法确定当前的说话临界判断值:
步骤1031、对于当前满足所述说话识别条件的视频帧序列的每一帧,计算该帧对应的所述人脸口部特征点集合的特征数据的均方差。
步骤1032、按照预设的统计周期或滑动窗口,计算每个所述统计周期或所述滑动窗口内的所述均方差的均值m0和均方差cri。
这里,所述统计周期和滑动窗口可以由本领域技术人员根据实际需要进行设置合适的长度。
对于统计周期,是每隔若干帧为一周期,相邻统计周期之间不会存在时间的交叠,假设统计周期为5帧,则对于100帧视频流而言,每5帧为一个周期,1至5帧为一个周期,6至10帧为一个周期…96至100帧为一个周期。此时,得到的每个周期的均方差cri可以如图2所示。图2中横坐标为周期编号,纵坐标为均方差cri的值。
对于滑动窗口,则和现有的定义相同,假如窗长设为m,则当前帧的滑动窗口包括当前帧和当前帧之前的m-1帧,相邻滑动窗口之间具有错开一帧的特点。这样,每个帧都会计算一个均方差cri。每个滑动窗口的均方差cri可以如图3所示。
由图2、图3可以看出,图3的数据选取方式更为精确,但图3所示方法运算量相对更小,二者所示趋势基本相同,具体选取统计周期方式还是滑动窗口的方式可视需求而定。
步骤1033、根据所述均值m0,得到当前的人像说话频率类型。
本步骤中,基于不同统计周期或滑动窗口内的所述均方差的均值m0,便可以得知当前的人像说话频率情况。具体为,将所有统计周期或滑动窗口内的所述均方差的均值m0进行按照数值的升序进行排序,通过对排序结果中的数据震荡情况,即可得到相应的频率情况,进而可以确定相应的说话频率类型。如此,则可以在后续步骤根据具体说话频率情况,确定相匹配的说话临界判断值用于当前的说话状态识别,以提高识别的准确性。
较佳地,所述人像说话频率类型可以设置为没有说话、少量说话和大量说话三种类型。
步骤1034、根据所述人像说话频率类型和所述均方差cri,确定当前的说话临界判断值。
较佳地,根据所述人像说话频率类型不同,具体可以采用下述方法确定当前的说话临界判断值:
1)当所述人像说话频率类型为没有说话时,采取最大振幅自增的方式确定当前的说话临界判断值:
按照crireal=crimax+prese,t得到当前的说话临界判断值,其中,crireal为当前的说话临界判断值,crimax为所述均方差cri中的最大值;preset为预设的增值系数。
2)当所述人像说话频率类型为少量说话时,采取最大跨度振幅的方式确定当前的说话临界判断值:
将所述均方差cri,按照数值的升序进行排序,得到均方差队列;
计算所述均方差队列中每对相邻均方差的差值,从最大的所述差值对应的两个均方差中,选择数值小的平均值mcri作为当前的说话临界判断值。
3)当所述人像说话频率类型为大量说话时,采取有效说话范围截取的方式确定当前的说话临界判断值:
计算所述均方差cri的平均值mcri;
从所述均方差cri中,查找出小于所述平均值mcri且最接近所述平均值mcri的均方差,并确定所查找出的均方差对应的帧号i;
将所述视频帧序列的第1帧到第i帧之间的所述均方差cri,按照数值的升序进行排序,得到均方差队列;
计算所述均方差队列中每对相邻均方差的差值,从最大的所述差值对应的两个均方差中,选择数值小的平均值mcri作为当前的说话临界判断值。
上述方法中考虑到大量说话的场景下仅需要部分的帧即可确定出说话临界判断值,从而既可以有效确保说话临界判断值的准确性,又可以减少运算开销,提高处理效率。
步骤104、利用所述说话临界判断值,逐一对所述视频帧序列的后续帧中包含的相应人像的说话状态进行识别,直至当前帧中不存在所述人像或者当前帧为所述视频流的最后一帧。
较佳地,可以采用下述方法逐一对所述视频帧序列的后续帧中包含的相应人像的说话状态进行识别:
如果所述视频帧序列之后的帧包含相应人像,则计算每帧对应的所述人脸口部特征点集合的特征数据的均方差,并按照所述统计周期或滑动窗口,在每个所述统计周期或所述滑动窗口,计算本统计周期或本滑动窗口内的所述均方差的均方差crik;
如果所述crik大于当前的说话临界判断值,则判定所述人像在说话,否则判定所述人像未说话。
步骤105~106、如果当前帧中不存在所述人像且当前帧不是所述视频流的最后一帧,则将本帧作为当前的检测帧,返回步骤102。
较佳地,在得到所述说话临界判断值之后,若连续多帧人脸始终处于说话状态,则可以对临界值进行参数更新,以提高判断精度。具体可以采用下述方法实现这一目的。
对于所述视频帧序列之后的每帧,逐帧检测当前是否存在满足说话识别条件的视频帧序列,当检测到所述视频帧序列时,根据该视频帧序列对应的特征数据,得到相应的说话临界判断值,利用所述说话临界判断值对当前的说话临界判断值进行更新。
图4为与上述方法对应的一种视频图像中人物说话的识别装置结构示意图,如图4所示,该装置包括:
初始化单元,用于将待检测视频流的起始帧作为当前的检测帧。
检测单元,用于从当前的检测帧开始,逐帧检测当前是否存在满足说话识别条件的视频帧序列;所述说话识别条件为连续n帧均包含预设的人脸口部特征点集合对应的特征数据,n≥1。
临界确定单元,用于当检测到所述视频帧序列时,根据该视频帧序列对应的特征数据,确定当前的说话临界判断值。
说话识别单元,用于利用所述说话临界判断值,逐一对所述视频帧序列的后续帧中包含的相应人像的说话状态进行识别,直至当前帧中不存在所述人像或者当前帧为所述视频流的最后一帧。
遍历控制单元,用于如果当前帧中不存在所述人像且当前帧不是所述视频流的最后一帧,则将本帧作为当前的检测帧,触发检测单元执行。
较佳地,所述临界确定单元,用于从当前的检测帧开始,逐帧检测当前帧是否包含人脸且包含了所述人脸口部特征点集合的特征数据,如果是,则记录人脸所在区域的编号,在后续帧中根据所述编号,进行相应的人脸检测,并在检测到连续n帧均包含所述人脸口部特征点集合的特征数据时,将该连续n帧确定为当前满足所述说话识别条件的视频帧序列。
较佳地,所述临界确定单元,用于对于当前满足所述说话识别条件的视频帧序列的每一帧,计算该帧对应的所述人脸口部特征点集合的特征数据的均方差;按照预设的统计周期或滑动窗口,计算每个所述统计周期或所述滑动窗口内的所述均方差的均值m0和均方差cri;根据所述均值m0,得到当前的人像说话频率类型;根据所述人像说话频率类型和所述均方差cri,确定当前的说话临界判断值。
较佳地,所述人像说话频率类型包括:没有说话、少量说话和大量说话。
较佳地,所述临界确定单元,用于当所述人像说话频率类型为没有说话时,按照crireal=crimax+preset,得到当前的说话临界判断值,其中,crireal为当前的说话临界判断值,crimax为所述均方差cri中的最大值;preset为预设的增值系数。
较佳地,所述临界确定单元,用于当所述人像说话频率类型为少量说话时,将所述均方差cri,按照数值的升序进行排序,得到均方差队列;计算所述均方差队列中每对相邻均方差的差值,从最大的所述差值对应的两个均方差中,选择数值小的平均值mcri作为当前的说话临界判断值。
较佳地,所述临界确定单元,用于当所述人像说话频率类型为大量说话时,计算所述均方差cri的平均值mcri;从所述均方差cri中,查找出小于所述平均值mcri且最接近所述平均值mcri的均方差,并确定所查找出的均方差对应的帧号i;将所述视频帧序列的第1帧到第i帧之间的所述均方差cri,按照数值的升序进行排序,得到均方差队列;计算所述均方差队列中每对相邻均方差的差值,从最大的所述差值对应的两个均方差中,选择数值小的平均值mcri作为当前的说话临界判断值。
较佳地,所述说话识别单元,用于如果所述视频帧序列之后的帧包含相应人像,则计算每帧对应的所述人脸口部特征点集合的特征数据的均方差,并按照所述统计周期或滑动窗口,在每个所述统计周期或所述滑动窗口,计算本统计周期或本滑动窗口内的所述均方差的均方差crik;如果所述crik大于当前的说话临界判断值,则判定所述人像在说话,否则判定所述人像未说话。
较佳地,所述装置进一步包括更新单元,用于对于所述视频帧序列之后的每帧,逐帧检测当前是否存在满足说话识别条件的视频帧序列,当检测到所述视频帧序列时,根据该视频帧序列对应的特征数据,得到相应的说话临界判断值,利用所述说话临界判断值对当前的说话临界判断值进行更新。
本发明还提供了一种视频图像中人物说话的识别装置实施例,包括:
存储器;以及耦接至所述存储器的处理器,所述处理器被配置为基于存储在所述存储器中的指令,执行如上述任一项所述的方法实施例。
相应地,本发明进一步提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现上述任一项所述的方法实施例。
综上所述,以上仅为本发明的较佳实施例而已,并非用于限定本发明的保护范围。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!