一种基于Kinect视觉的唇读研究的方法与流程
本发明属于语音识别领域,具体涉及一种基于kinect视觉的唇读研究的方法。
背景技术:
近年来,随着计算机技术的迅猛发展,尤其是便携式计算机技术的普及,人机交互(hci---humancomputerinterface)已经逐渐成为现代人们的一种重要生活方式。在人类交流的过程中,语音无疑是非常重要的信息媒介,通过语音可以传递一个人的喜怒哀乐。因此,人机交互的方式逐渐以语音的方式为主,因而语音识别技术发展迅猛。语音搜索、语音输入法等语音识别系统已成为当今社会的一大潮流。
但是,即使最优秀的语音识别系统也难以适应现实生活中复杂多变的环境,尤其是高噪声的环境,此时系统的识别性能会大幅下降。与此同时,对于听力受损者或语言障碍者而言,语音识别系统的优势也难以体现。有心理学研究表明,人们在噪声环境下,会不自觉地使用唇动、表情、手势等视觉信息来提高语言的理解力。换言之,人类对于语言的感知是多模态的,即在交流过程中不仅依赖交换音频信息的方式,还依靠视觉信息辅助理解。因此唇读研究的发展不仅对于已有的语音识别系统是极大的辅助,同时对于听力受损者或语言障碍者也是一个福音。因而,唇读研究也吸引了业界的注意力,并得到大力发展。唇读研究主要涉及以下几方面:唇区检测及定位、特征提取和训练识别。其中特征提取处于核心地位。目前的特征提取方法主要分为三类:
1)基于模型的方法,将嘴唇轮廓抽象为一个数学模型,以获得关于嘴唇的几何形状特征。缺点是特定的模型有可能丢掉一些重要的信息。
2)基于像素的方法,该方法将感兴趣区域(roi)的像素信息直接或经过某种变换后作为特征向量,其缺点是特征向量是高维度和高冗余度的。
3)将前两种方法结合提取特征。比如aam(主动外观模型)算法等。在提取特征之后,通过hmm模型对特征进行训练识别。
技术实现要素:
针对现有技术存在的问题,本发明提出一种基于kinect视觉的唇读研究的方法,该方法将获取的图像及深度数据得到唇区(即感兴趣区域roi)的3d坐标信息,分别将坐标及空间角度作为特征进行训练识别,探索基于三维信息的唇读研究;该方法相比于基于模型的方法,保存了更多的信息;相比于基于像素的方法,避免了背景对提取数据的影响,降低了信息维度和冗余度。
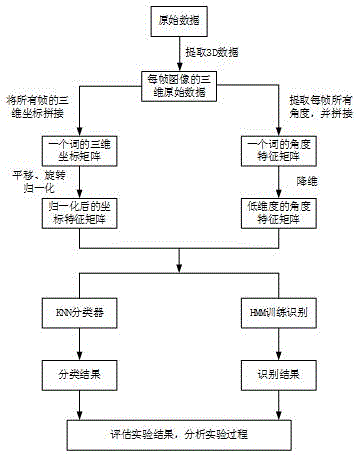
一种基于kinect视觉的唇读研究的方法,具体有以下步骤组成:
步骤一:通过kinect采集所需脸部三维数据,并对数据进行预处理;
步骤二:定位唇区,提取唇部18个特征点,进行编号建模;
步骤三:提取特征,分别是特征点间的角度特征和特征点的坐标特征,并进行归一化处理;
步骤四:采用隐马尔可夫模型(hmm)以及k-近邻算法(knn)对特征进行训练识别。
步骤一对采集的数据进行了预处理,具体步骤如下:
通过采集获得语料库,将获取到的数据加标签及时间戳进行序列化,全部存到一个二进制文件中。将原始数据进行预处理,其一,要把整段音频进行切割,分成每个词一段音频,同时对应的彩色图像及深度数据也要同步的保存到同一位置;其二,我们需要将不合格的数据剔除,并进行重新补录。
步骤二在步骤一的基础上进行唇区定位,具体步骤如下:
在数据采集阶段,我们利用kinect传感器得到了说话人脸部预先定义的121个特征点的三维坐标信息。通过对数据进行大量实验,得到了唇部18个特征点所对应的脸部121个特征点的序号。根据18个点的位置关系,提取得到每个词的每帧图像对应的唇部所有特征点的三维坐标信息。
步骤三在步骤一和步骤二的基础上进行特征提取,具体步骤如下:
有两种特征中可以选择,对应不同的选取及归一化方法。其一,是与传统的特征提取方式进行类比,以特征点间的角度作为特征,是使用knn(k-近邻法)选取得到;其二,是以唇部18个特征点的坐标直接作为特征,进行归一化之后进行训练识别。
步骤四在步骤一、步骤二和步骤三的基础上对归一化的数据进行训练识别,具体步骤如下:
按照训练集和测试集配比为3:2以及全训练全识别的方式进行训练识别,训练识别的方式采用knn算法分类和hmm模型训练识别。通过比较识别结果与测试集的标签,可以得到识别率。
一种基于kinect视觉的唇读研究的方法,使用三维坐标与空间角度作为特征进行训练识别,相比于现有的方法,提高了识别准确率。
首先,唇读研究对于辅助完善语音识别系统有很大的帮助。相对于音频单通道的语音识别系统,结合了视频通道信息的识别系统将会在复杂的环境中有更好的表现,也更加鲁棒。比如:清辅音字母/p/和/k/,浊辅音字母/b/和/d/等字母对,单依赖音频通道很难区分,但是在结合唇部特征后,将大大提高系统的识别准确率。
其次,在实际应用领域,唇读研究还可以辅助个人身份识别、以及手语识别等方面。同时,唇读对于后天聋哑人士说话功能的恢复有着重要的作用。在当代,口型语言分析学也在辅助刑事侦查及反恐方面提供技术支持。通过对唇动规律的研究,唇读技术也将在说话者识别、唇动合成、语音驱动的人脸图像编码、语音驱动的头部运动合成等方面有着重要的作用,相应的应用领域包括——编码、动画唇动合成、网络自动代理中的虚拟人和配音中对口型等。
最后,在理论研究方面。它涉及模式识别、计算机视觉、自然语言处理、图像处理等多个领域。多个研究领域的内容相互推动,也互相检验及发展。
附图说明
图1是本发明唇读研究方法流程示意图;
图2是kinect三维坐标系示意图;
图3是人脸121个特征点示意图;
图4是唇区特征点重新编号示意图。
具体实施方式
下面结合附图和具体实施实例对本发明作进一步说明,但本发明所要保护的范围并不限于此。
一种基于kinect视觉的唇读研究的方法,如图1所示,为本发明具体实施例的过程示意图,包括:
步骤s0101:预处理中的数据是使用kinect跟踪采集到的三维数据,kinect坐标系统输出的三维跟踪结果为:(x,y,z)。其中,z轴是传感器到用户的距离,y轴是上下指向,x轴是左右指向。数据都是以米为计量单位。坐标系如图2所示。
某一时刻的人脸的三维坐标是由同一时刻的彩色图像、深度图像经处理得到。facetrackingsdk预先在人脸定义了121个特征点,包含了脸部的全部轮廓特征,其中唇部区域有18个特征点,如图3所示。
步骤s0201:在得到唇区的3d数据后,对唇部进行3d建模,首先对18个特征点进行重新编号,内唇顺时针顺序为1至8,外唇顺时针顺序为9至18,如图4所示。
步骤s0202:由于我们所得到的唇部信息是三维坐标,在二维图像中很难体现其优越性。因此,根据唇区的三维坐标使用matlab对其进行三维建模,得到三维唇部轮廓模型。
步骤s0301:在角度特征提取中,唇部的轮廓有18个坐标点,如果选取角度作为特征,则需要分析每个角度的可信程度,也就是每个角度的识别率。18个特征点排列组合得到2448个角度,在这里使用knn方法进行分类,得到每个词的分类正确率,据此得到角度的可信度降序排列,选取高可信的角度作为角度特征进行提取。
步骤s0302:在角度特征归一化过程中,每个词的特征矩阵为n×l,其中n为相应词对应的图片帧数,l为每帧图像对应的特征维数,即选取的角度个数。将特征矩阵进行归一化,即对每维数据进行归一化至区间[-1,1]。这里直接对每个角度进行求余弦值,得到区间[-1,1]的归一化结果。
步骤s0303:在三维坐标特征提取中,每帧图像对应唇部的18个特征点的三维信息,即对于三维数据的特征而言就是从这18个点中分析提取。考虑到18个点的三维坐标本身即是一种信息,我们直接以18个点的三维坐标拼接得到一帧图像的特征信息。
假设18个点的坐标为[xi,yi,zi],其中i=1,2,…,18。则拼接之后得到的特征为[x1,x2,…,x18,y1,y2,…,y18,z1,z2,…,z18]。然后将一个词的所有图像帧对应的三维坐标都按照上面的方法拼接,然后得到这个词所对应的三维数据的特征矩阵,即为n×18,其中n为这个词对应的图片帧数。比如,某人的“操作”一词,与整段音频对应的图像帧数为51,则意味着同时对应着51帧三维数据信息,得到的特征矩阵大小为51×18。
步骤s0304:在三维坐标特征归一化过程中,我们对所有的三维数据进行平移,使之在坐标轴上显示在同一位置。具体做法是,统一以每帧对应数据的第9个特征点,即左边的外唇端点,也就是人的右嘴角。然后我们对图像进行旋转,即以左右嘴角的连线,也就是特征点9和特征点15的连线作为x轴,其他的点都相应的旋转。旋转后的坐标即作为最后的坐标特征。
步骤s0401:当我们训练好knn分类器后,对测试集进行分类,这里对于测试集也有同样的要求,需要拼接成如训练集一样的特征矩阵,且具有同样的列,即每个样本的维度保持一致。
在对测试集分类的过程中,需要的数据包括:
1)测试集,格式如同训练集,应有对应的标签,为了在分类后比较得到分类的正确率;
2)k值,即在分类时,考虑待分类点周围的k个邻居的类别属性,然后以所占邻居数目最多的类别作为此点的类别;
3)分类规则,即knn的度量距离的模式,常用的距离有欧几里得距离、曼哈顿距离、汉明距离等。
得到这些数据后,得出对于测试集中每个样本的分类结果,通过与测试集的标签比较,即可以得到分类的正确率。
步骤s0402:训练hmm模型的具体步骤如下:
第一步,先获取数据集。首先需从特征文件(特征提取过程中经knn选取角度后得到的指定角度的特征文件)中随机提取五分之三数据作为训练样本(其余的五分之二为测试集),并同时附带标签(标注类别名称)。
第二步,训练hmm模型。在获得数据集后,对于同一类别的训练集,训练得到hmm模型。在这个过程中需要定义hmm的一些参数:包括hmm模型的状态数,高斯混合部分数量。在给定状态数及高斯混合参数后,我们就可以对hmm模型进行初始化,然后对其进行迭代更新,得到这个词的hmm模型。
步骤s0403:识别过程也就是hmm的三个基本问题中的解码问题,给定测试集,即我们已知观察序列,搜寻hmm模型中最可能的隐藏状态序列,我们可以得到一个概率,通过比较所有hmm模型各自得到的概率,选择其中概率最大的hmm模型作为识别结果。通过比较识别结果与测试集的标签,我们可以得到识别率。
- 还没有人留言评论。精彩留言会获得点赞!