一种时序数据库系统的制作方法
本发明属于实时数据库技术领域,特别涉及一种时序数据库系统。
背景技术:
时序数据即时间序列数据,指带时间标签(按照时间的顺序变化,即时间序列化)的数据。时序数据主要由电力、化工、冶金等各类型实时监测、检查与分析设备所采集、产生的数据,这些工业数据的典型特点是:产生频率快(每一个监测点一秒钟内可产生多条数据)、严重依赖于采集时间(每一条数据均要求对应唯一的时间)、测点多信息量大(常规的实时监测系统均有成千上万的监测点,监测点每秒钟都产生数据,每天产生几十gb的数据量)。
目前,对于时序数据的存储和处理方法主要有文件系统、关系型数据库软件和实时数据库软件。其中,关系型数据库主要有mysql,mssqlserver,oracle,db2等,实时数据库软件有osisoftpi,wonderwareinsql,geihistorian等。文件系统和关系型数据库软件因缺乏针对时序数据库的索引、压缩,存在占用空间大、读写速度慢问题。实时数据库软件多采用有损压缩方法降低存储空间提高读取写速度,例如osisoftpi采用的旋转门压缩算法。缺少一种无损压缩、高效读写的时序数据库系统。
技术实现要素:
本发明的目的在于提供一种时序数据库系统,解决各种类型时序数据的无损压缩、高效写入和高效读取问题。
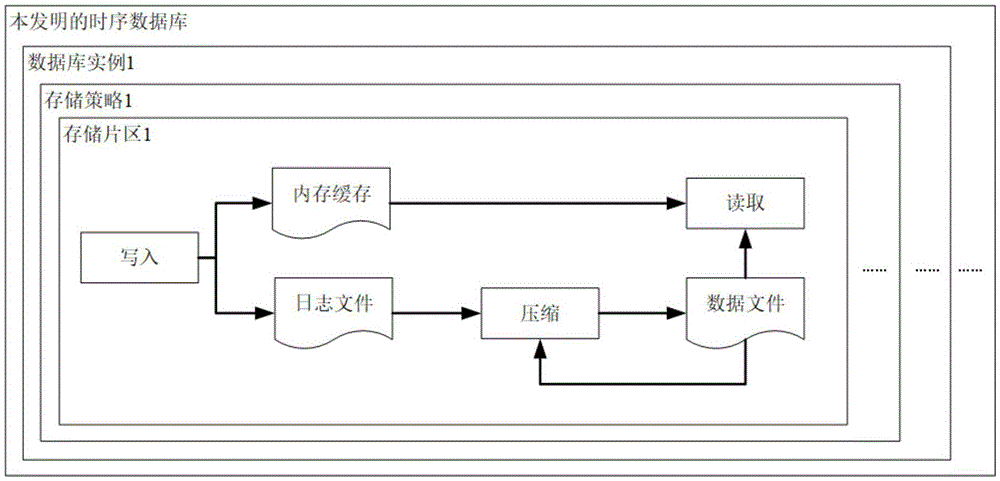
本发明的系统包括至少一台联网的计算机,构成了系统的硬件平台;在计算机上运行本系统的软件,包括数据写入模块、数据压缩模块和数据读取模块,数据写入模块负责接收新数据,将数据分别写入内存缓存和日志文件;数据压缩模块负责将日志文件的数据按照本发明设计的压缩方法和索引结构压缩成数据文件;读取模块响应读取请求,综合内存缓存和数据文件查询结果后返回。
通过本系统的软件,可以创建数据库实例,每个数据库实例可以包含不同存储策略用于指定不同的存储时限,每个存储策略包含存储片区用于存储一定时间范围内的数据,每个存储片区拥有一个内存缓存区、一个日志文件和一个或以上数据文件。
本发明为各种类型时序数据设计了专门的压缩方法。时序数据类型包括整数、浮点数、布尔、字符串、时标五种数据类型,针对这五种数据类型分别设计的压缩方法如下:
整数的压缩方法为,第一个整数不压缩,从第二个整数开始计算与前一个数的差值,并对差值进行zigzag(由谷歌公司在protocol-buffers协议中首先提出)编码,将差值为负数的变为正数,然后分三种情况进行压缩:1、如果连续两个以上差值相等,则只存储差值及差值出现的次数;2、如果差值超过十六进制数值0x0800000000000000(相当于十进制数值576460752303423488),不压缩;3、否则,将差值采用simple8b算法(来自论文:annandmoffat,"indexcompressionusing64-bitwords")进行压缩。
浮点数的压缩方法为,第一个浮点数不压缩,从第二个浮点数开始与前一个数进行异或计算,得到一个64位无符号整数作为差值。当两个浮点数数值接近时得到的差值很小,当差值为0时仅存1位0;不为零时存1位1,然后用5位存储64位中位于左端的0的数量,用6位存储居右端的0的数量,再将非零位截取出来存储。
布尔值的压缩方法为,直接将布尔值用1位存储到字节末尾(每个字节有8位),当存满8位后分配一个新字节。
字符串的压缩方法为,将字符串顺序添加到字节流后用snappy算法(由谷歌公司在http://google.github.io/snappy/提供的开源算法)压缩。
时标数的压缩方法为,第一个时标数不压缩,从第二个时标数开始与前一个数进行差值计算,第一个差值不压缩,然后从第二个差值开始计算与前一个差值的差值,如果差值的差值为0(当数据的存储间隔相同时),仅存储0和0出现的次数;否则采用simple8b存储该差值的差值。
采用内存缓存和日志文件来保证高效写入,内存缓存目的是代替日志文件提供对临近数据的高效读取,日志文件的目的是在系统重启后能够重建内存缓存,日志文件不用于读取数据。由于磁盘的顺序写入速度快而随机写入速度慢(寻道和旋转延迟),而时序数据的特点是大量数据不断采集、不断写入,为了提高写入效率将一批数据(一般为5000到10000点)按照点名、点数、时标、值、时标、值…顺序编码为字节流,再利用snappy算法(由谷歌公司在http://google.github.io/snappy/提供的开源算法)压缩后写入日志文件。同时,将写入日志文件的数据以点名、时标、值的结构存入内存缓存区,内存缓存与区日志文件保持同步。日志文件大小固定,当达到规定大小时自动生成一个新的日志文件。
为时序数据设计了专门的数据文件结构,以便提高读取速度、降低硬盘空间占用。数据文件中包含一个或以上数据块和一个索引块,数据块为数据点的一组按时间排序后的数据经过前述该点数据类型对应的压缩方法压缩后的字节数组,索引块由点名、数据类型、数据库数量、数据库索引1、数据库索引2…构成,每个数据库索引包含数据块起始时间、数据块结束时间、数据块在文件中的起始位置、数据块字节数构成。
为数据文件设计了多级压缩机制逐步提高数据的压缩率,减少数据文件数量。首先是从日志文件开始压缩,得到一级数据文件,然后是从一级数据文件压缩得到二级数据文件,如此层层压缩,压缩完成后删除被压缩的低级别的数据文件,直到只剩下一个数据文件或数据文件达到规定大小为止。
本发明的优点在于,相比文件系统和关系型数据库,磁盘占用少、读写速度快。首先,数据经过压缩后占用磁盘空间更少,与mysql数据库变比,磁盘空间占用仅为35%;其次,数据写入速度更快,与mysql数据库变比,写入速度提高3倍;最后,数据读取速度更快,与mysql数据库变比,读取速度提高20倍。相比一般实时数据库采用有损压缩存在信息损失的问题,本发明采用无损压缩方法没有信息损失。
附图说明
图1为系统的逻辑结构图。
图2为数据压缩流程图。
图3为数据文件的结构图。
图4为数据文件压缩流程图。
具体实施方式
如图1所示,系统包括一个或以上数据库实例,每个数据库实例包含一个或以上存储策略,每个存储策略包含一个或以上存储片区,每个存储片区包含一个内存缓存区、一个日志文件、一个或以上数据文件,以及写入、压缩、读取三个数据处理模块。在写入时,系统根据数据点所属数据库实例名找到数据库实例,然后由数据库实例找到数据点所属数据存储策略,然后由存储策略根据数据的时标范围找到命中的存储片区,如果片区不存在则创建片区,然后将数据分发给片区执行写入。存储片区负责将数据同时写入到内存缓存与日志文件中,日志文件定时压缩为数据文件,数据文件再逐步压缩为更大的数据文件。在读取时,系统采用与读取同样的逻辑找到所有命中的片区,由片区判断是从其内存缓存中读取还是从其数据文件中读取,如果是从数据文件中读取,利用文件中的索引快速定位数据位置,读取后由系统将所有命中片区返回的结果按照时间先后顺序合并返回最终查询结果。
如图2所示,时序数据包含点名、时标和数值信息,写入一组时序数据时,写入模块遍历每个点,判断数值的数据类型是整数、浮点数、布尔值还是字符串,分别调用相应的压缩方法进行压缩,时标调用时标压缩方法压缩,将两者压缩得到的字节数组合并后写入到数据文件中。
如图3所示,数据文件由文件头、数据块区、索引块和文件尾构成。其中文件头固定大小用于保存系统的版本号,文件尾固定大小用于保存索引块在文件中的位置。数据块区存放数据块,数据块由图2流程压缩后产生。索引块依次存放数据点名、点的数据类型、数据块数量、数据块1的开始时间、数据块的结束时间、数据块在文件中的起始位置和所占的字节数…。
如图4所示,当有新数据写入且系统判断内存缓存区大小达到上限,或者较长时间没有新数据写入,系统压缩日志文件得到1级数据文件。当有2个或以上n级数据文件且文件大小未达到设定上限时,系统压缩同级数据文件得到n+1级数据文件,并删除被压缩的n级数据文件,如此直到不再有新数据写入并且最多只有一个大小未达到设定上限时,数据文件压缩结束。
通过上述实施过程,可以得到一个时序数据库系统,在一台thinkpadt550笔记本电脑上测试运行,可实现每秒5万点数据写入、压缩。目前本发明正在某大型钢铁企业环保监控系统中应用,未来可广泛用于工厂过程监控和物联网领域。
- 还没有人留言评论。精彩留言会获得点赞!