一种基于改进的多种群全局最优的自适应鸽群优化方法与流程
本发明多目标问题优化技术领域,特别是涉及一种多目标粒子群全局优化技术。本发明的基于鸽群优化的方法即是在典型多目标优化问题——zdt问题(zitzler–deb–thiele'sfunction)的具体应用。
背景技术:
现代的工业过程是一个复杂的系统,其过程数据具有动态性、非线性和多约束性的特征。为了提高工业生产过程的效率,减少事故的发生,多目标优化方法受到广泛关注。多目标进化算法有很好的全局探索能力,且并不需要了解问题的数学模型。由于其简洁、高效的特点,多目标进化算法解决了工业过程领域的许多难题。
目前,多目标进化算法主要有:多目标蚁群算法、多目标遗传算法、多目标差分进化算法。而多目标粒子群优化(multi-objectiveparticleswarmoptimization,mopso)算法是一种基于鸟群或鱼群行为的启发式算法。通过个体粒子之间相互合作,表现出复杂的智能行为;利用个体间的信息交互实现种群的进化。实现了以种群为主而非优异的独立个体的智慧的进化。
然而,目前的mopso算法解决的问题大多是静态优化问题,但实际应用中的问题不但目标之间互相冲突,而且具有很强的时变性,现有的mopso算法无法动态调整适应,因此无法获得优秀的效果。
技术实现要素:
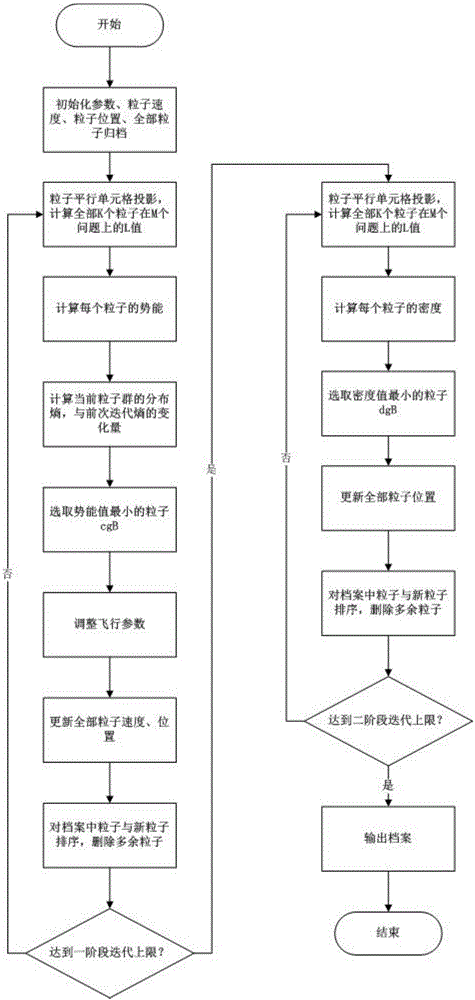
为了克服上述现有技术的不足,本发明提供了一种基于改进的多种群全局最优的自适应鸽群优化方法。将每次迭代过程中的粒子投影到平行单元格中。评价每个粒子的分布与收敛情况,从中选出倾向于收敛性的全局最优粒子或是倾向于多样性的全局最优粒子;根据粒子群的情况动态的调整粒子的飞行参数。解决了粒子群算法容易陷入局部最优的问题。在保证粒子收敛性的同时,提高了解的多样性。
鸽子飞行分为两个阶段:一阶段依靠磁石与太阳;二阶段依靠地标。
第一阶段:在距目的地较远时,它们都是依靠磁石与太阳。鸽子可以通过体内的磁石感知地球磁场,并于大脑中塑造地图。它们把太阳的高度做为罗盘从而调整方向。
分析鸽子的行为发现:在距目标较远时,鸽子的飞行过程倾向于全局搜索。因此,我所设计的多目标鸽群算法在第一阶段专注于全局搜索也就是收敛性。
第二阶段:在距目的地较近时,它们会依赖附近的地标。如果鸽子熟悉地标,它们将直接飞往目的地。如果它们不熟悉地标,它们会跟随那些熟悉地标的鸽子。
分析鸽子的行为发现:在距目标较近时,鸽子的飞行过程倾向于局部搜索。因此,我所设计的多目标鸽群算法在第二阶段专注于局部搜索也就是多样性。
本发明采用了如下的技术方案及实现步骤:
把工业过程中待调的参数值进行组合,构成向量。每个向量是参数值的一种可能解,将这样的向量称为粒子。
a.粒子收敛性阶段:
1)设置多目标鸽群算法的参数,随机初始化粒子位置、速度,
将全部粒子归档;
2)将粒子投影到平行单元格中,计算当前时刻每个粒子在每个目标上的适应度值,其中当前时刻第k个粒子在第m个目标上的适应度值lk,m,具体公式如下;
其中,[x]是向上取整函数,k表示粒子总数,
3)计算当前时刻每个粒子的势能,其中第i个粒子的势能值的计算公式如下:
m为目标个数;
4)分析全局粒子
i.计算当前迭代次数下全局粒子的分布熵,其中第t次迭代时全局粒子的分布熵计算公式如下:
其中,cellk,m是粒子投影产生的平行单元中第k行第m列的单元格中点的个数,k为全部粒子个数,m为目标个数,t从1开始;
ii.计算当前迭代次数与前次迭迭代间熵的变化量,0时刻的熵值设为0,公式如下:
δentropy(t)=entropy(t)-entropy(t一1)
5)根据步骤3选取势能值最小的粒子,此粒子为收敛全局最优cgb;
6)调整飞行参数值ω(t),公式如下:
其中,stepω=ω/t,stepω为更新步长,ω为惯性因子,t为一阶段迭代次数。
7)更新所有粒子的速度、位置,第i个粒子的速度与位置的更新公式如下:
vi(t)=ω(t)·vi(t一1)+rand·(cgb-xi(t-1))
xi(t)=xi(t-1)+vi(t)
rand为(0,1)间的随机数,vi(t)为第i个粒子第t次迭代时的速度;xi(t)为第i个粒子第t次迭代时的位置;
8)对档案中的粒子与第7步更新后的粒子位置x(t)进行非支配解排序,删除名次低的解直至符合档案大小,完成归档。
9)回到步骤2进行迭代,直至达到一阶段迭代次数上限,进入下一阶段,到步骤10;
b.粒子多样性阶段:
10)对粒子重新投影,计算每个粒子的密度值:
i.计算每个粒子与其他粒子的距离,其中第i个粒子与第j个粒子的距离公式描述如下:
ii.计算所有粒子在当前粒子群中的密度,其中第i个粒子在当前粒子群中的密度值公式如下:
11)根据步骤10选取密度值最小的粒子,此粒子为多样全局最优dgb;
12)更新所有粒子位置,其中第i个粒子的位置更新公式如下,粒子的起始位置继承收敛性阶段结束时位置:
xi(t)=xi(t-1)+rand·(dgb-xi(t-1))
13)对档案中的粒子与第12步更新后的粒子位置x(t)进行非支配解排序,删除名次低的解直至符合档案大小,完成归档;
14)回到步骤10进行迭代,直至达到二阶段迭代次数上限,此时的档案即为所求多目标问题的最优解集,输出档案。
有益效果
与现有技术相比,本发明将解的收敛性和多样性分成了两个阶段。考虑到了影响解的性质的两个方面,提高了解的质量。原始的鸽群优化算法的飞行参数不适宜多目标问题的求解,并且没有自适应能力。因此本发明方法中设计了参数的动态调整功能,弥补了原始方法的不足,提高了算法的性能。
附图说明
图1为本发明的方法流程图;
图2为鸽群算法惯性参数变化图;
图3为本文算法惯性参数变化图;
图4为粒子分布熵变化图;
图5为粒子δentropy值变化图;
图6(a)为多目标鸽群在zdt1问题结果图;
图6(b)为本文算法在zdt1问题结果图;
图7(a)为多目标鸽群在zdt2问题结果图;
图7(b)为本文算法在zdt2问题结果图;
图8为粒子平行单元格投影举例
具体实施方式
本文所提出的算法可以解决工业过程中参数调整的多目标问题。通过把待调的参数值组成向量,把这种向量称为粒子。通过粒子群(即大量粒子)有倾向的随机飞行,高效的求解工业过程参数设置的最优值。
算法的有效性将用zdt问题进行测试。首先,介绍一下zdt问题,zdt问题是多种目标函数对的统称。表1列出了每个zdt实例的pareto真实前沿的特征,维度和简单尺寸。每个zdt问题都有一对目标函数,问题的最终目的是令两个函数输出值都尽量最小(或最大)。但zdt问题一个函数输出值的减小通常会导致令另一个函数输出值增大,因此权衡输入值使输出值都较小(大)是zdt问题的目标。对于一个粒子x,x=(x1,x2,…,xn),x1到xn为控制变量,如在青霉素生产过程中有:空气流量、搅拌功率、底物添加速率、ph值、温度等。通过将x代入适应度函数计算适应度,参考适应度值从而得到控制变量适合的设定值。适应度公式的设置由实际工厂需求决定,如:生产成本计算公式,产物浓度计算公式等。本次实验选择的适应度函数为zdt问题自带的函数;
表1标准测试函数参数设置
a.粒子收敛性阶段:
步骤1:初始化粒子群参数,包括粒子个数、粒子维度、一阶段迭代次数、二阶段迭代次数、全局最优存档大小、惯性因子、随机生成粒子初始速度与位置,将粒子全部存入档案中;
表2粒子群参数初始值
步骤2:利用适应度函数(本文所用为zdt问题自带的函数)与投影公式对当前时刻的全部粒子进行平行单元格投影,即对每个粒子(共k个)在每个目标(共m个)上的相对适应度值lk,m。如图8为粒子计算适应度值lk,m的平行单元投影直观显示,行数为粒子个数,列数为目标个数,即为9个粒子3个目标的投影结果。图中pkfm表示第k个粒子在第m个目标上相对全部粒子的适应度,也就是lk,m值,可以根据前文中的公式计算得到。每个单元格中的点表示粒子在第m个目标上的投影。每个粒子在每列的高度就是其相应的lk,m值,比如第一个粒子在第3个目标上的适应度值l1,3从图中可以直接得出为1,由图可以直观的看出粒子经过平行单元格投影后的情况。
步骤3:计算当前时刻全部粒子的势能,公式见前文,对于9个粒子3个目标的情况,当前时刻第1个粒子的势能值为第1个粒子在三个目标上的适应度值之和,由此可以得知全部9个粒子势能值的计算方法;
步骤4:根据公式计算当前时刻整个粒子群的分布熵,
并与上一时刻的分布熵求差值,得到δentropy,公式见前文,其中,entropy(0)=0;
步骤5:选出势能值最小的粒子,使其成为收敛全局最优cgb;
步骤6:用上一步得到的δentropy与阈值
步骤7:更新粒子当前时刻的速度与位置,rand为区间[0,1]中的随机数。
vi(t)=ω(t)·vi(t-1)+rand·(cgb-xi(t-1))
xi(t)=xi(t-1)+vi(t)
步骤8:对档案中的粒子与新生成的粒子进行非支配解排序。删除末尾的粒子直至符合档案大小;
步骤9:如未达到一阶段最大迭代次数,回到步骤2;如达到一阶段最大迭代次数,到步骤10
b.粒子多样性阶段:
步骤10:粒子位置继承上一阶段结束时状态。对当前时刻的全部粒子进行平行单元格投影,得到即在每个目标上的相对适应度,即l值。计算当前时刻全部粒子的密度。
首先计算每个粒子与其他单个粒子的距离。计算方法为求粒子与其他粒子在每个目标上差的绝对值并加和。公式如下:
之后计算某个粒子与其他粒子间距离倒数的平方,相加即为此粒子的密度值,公式如下:
步骤11:选出密度值最小的粒子,使其成为收敛全局最优cgb;
步骤12:更新当前时刻粒子的位置,其中dgb为密度值最小的粒子,公式如下,
xi(t)=xi(t-1)+rand·(dgb-xi(t-1))
步骤13:对档案中的粒子与新生成的粒子进行非支配解排序。删除末尾的粒子直至符合档案大小;
步骤14:如未达到二阶段最大迭代次数,回到步骤10;如达到二阶段最大迭代次数,此时的档案即为所求多目标问题的最优解集,结束程序。输出档案。
上述步骤即为本发明方法在多目标问题基础测试函数上的具体应用。
为了对比飞行参数的变化,图2、图3分别显示出鸽群算法与本文所提算法惯性参数的变化过程。其中可以发现,鸽群算法的变化曲线为单纯的指数函数,并且数值下降速度过快,导致粒子的全局探索能力差。而从本文所提算法的惯性参数可以发现,在算法的开始阶段,ω的值倾向于减小,即加强局部探索能力快速收敛;而当找到一定量的非支配解后,ω的值倾向于增大,即加强全局探索能力增加多样性。
本文中所提的算法与鸽群算法的性能在五个zdt问题上进行了测试。为了验证本方法的有效性,与鸽群算法进行了对比。得到的实验结果见图6至图7,图中绘出了帕鲁托前沿、多目标鸽群或本文算法所得到的解。其中pareto前沿由点表示;算法所得到的解由正方形表示。如果曲线pareto前沿与解重合的越紧密,说明解的收敛性越好;如果解分布的越均匀,说明解的多样性越好。
从图中,无论是在收敛性还是多样性方面,本发明方法效果均比传统鸽群算法有所提升,提高了粒子群算法解的性能。
- 还没有人留言评论。精彩留言会获得点赞!