一种基于Spark的油气开采大数据的数据挖掘方法与流程
本发明涉及spark、数据挖掘和油气开采大数据,具体涉及到一种基于spark的油气开采大数据的数据挖掘方法。
背景技术:
知识发现(knowledgediscoveryindatabase,kdd),是所谓"数据挖掘"的一种更广义的说法,即从各种媒体表示的信息中,根据不同的需求获得知识。知识发现的目的是向使用者屏蔽原始数据的繁琐细节,从原始数据中提炼出有意义的、简洁的知识,直接向使用者报告。通用的过程应该接收原始数据输入,选择重要的数据项,缩减、预处理和浓缩数据组,将数据转换为合适的格式,从数据中找到模式,评价解释发现结果。知识发现的主要任务包括分类、聚类、预测、关联分析等,涉及的核心技术包括知识表达与推理、挖掘算法等。
数据挖掘是知识发现过程的核心,数据挖掘是从大量的数据中挖掘出有用的信息,用以做决策支持。大数据环境下,由于要挖掘的信息源中的数据都是海量的,传统的集中式串行数据挖掘方法不再是可取方式。因此扩展数据挖掘算法处理大规模数据的能力,并提高运行速度和效率,已经成了一个不可忽视的问题,并行化的数据挖掘成为一种重要的手段。例如中科院的基于云计算的并行分布式大数据挖掘平台——pdminer,以及基于hadoop的数据挖掘等。当然,由于mapreduce是以离线批处理的方式进行计算,其对实时性场合并不能满足要求,就是说传统的基于mapreduce的方式并不能满足大数据的一个特征velocity,即数据挖掘的实时性。鉴于此,研究人员开始利用快速内存计算的spark进行数据挖掘的研究开发,如中科大的可视化数据挖掘。理想情况下,我们可以将离线处理与快速处理结合,并利用cpu-gpu的协同计算能力,进行并行化高效率的数据挖掘。
技术实现要素:
为解决现有技术中的缺点和不足,本发明提出了一种基于spark的油气开采大数据的数据挖掘方法,根据实时获得的数据与历史数据的组合,采用实时与离线结合的大数据处理方式,快速有效地构建相应的模型,对采油量、产能等进行综合预测,并利用云计算技术实现开采数据的高效存储和管理,并能利用这些数据进行生产优化与决策支持。
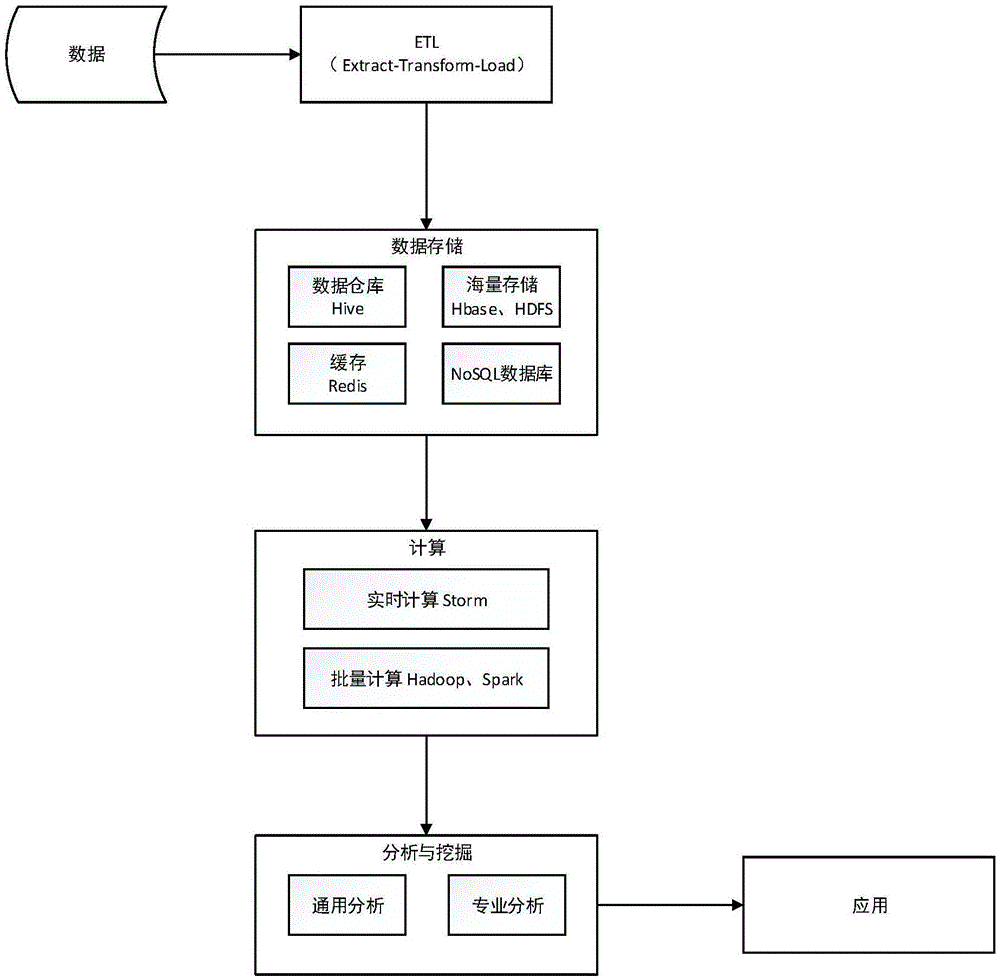
建立大数据挖掘分析和知识发现模型框架,建立通用的大数据分析模式,以支持油气开采大数据的知识挖掘。建立基于spark的通用并行挖掘算法库,包括naivebayes,decisiontree,randomforest,k-means,linearregression,logisticregression,svm,fp-growth等常用算法。如图1所示,该大通用数据分析模式在底层融合了传统的数据挖掘方法,包括etl。数据采集之后,将在规范化后进入数据存储服务。与此同时,一部分需要分析的数据直接进入计算服务,经过基于spark的算法处理得到挖掘的知识。油气开采知识的挖掘在生产过程中起着至关重要的作用,油气开采大数据的分析方法从应用范围上可以分为通用方法分析和专业方法分析。基于所建立的大数据通用分析模型,将通用分析和专业分析二者结合起来全方位挖掘油气开采大数据。
本发明的技术方案为:
步骤(1)、数据预处理,通过数据预处理模块对数据进行预处理;
步骤(2)、模型训练,进行相应算法的训练,得到最终模型;
步骤(3)、模型应用,利用训练好的模型进行分析与预测;
步骤(4)、结果展示,将得到的结果展示给用户;
本发明的有益效果:
(1)建立基于spark的通用并行挖掘算法库,在实际中能准确地预测采油量、产能等油气开采数据,从而可以利用这些数据进行生产优化;
(2)本方法通过数据预处理模块大大减少了方法的计算复杂度,同时提高了算法精度;
(3)通过spark来进行算法并行化,加快算法速度,利用cpu-gpu的协同计算能力,进行高效率的数据挖掘。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明大数据挖掘分析和知识发现模型框架图;
图2为本发明基于spark的油气开采大数据的数据挖掘方法的流程图;
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
如图2所示,基于spark的油气开采大数据的数据挖掘方法的流程图包含三个模块:数据预处理模块、模型训练和模型应用模块。
下面结合图2,对基于spark的油气开采大数据的数据挖掘方法的具体流程进行详细说明:
步骤(1)、通过数据预处理模块对数据进行相应的处理得到期望的格式,以便进行训练,其中数据预处理模块包括数据降维、数据去重、文本向量化、数据归一化、缺失值处理等;
步骤(2)、当数据预处理完毕后,对数据进行相应算法的训练,并采用实验集进行测试与验证,不断调优得到最终模型;
步骤(3)、模型应用,可以利用训练好的模型进行分析与预测,并将结果保存到hdfs、hbase等用于结果的可视化展示;
步骤(4)、将得到的结果通过图表等直观的形式展示给用户,为用户提供生产优化的决策支持;
本发明的基于spark的油气开采大数据的数据挖掘方法,将数据挖掘方法和油气开采大数据相结合,通过spark来进行算法并行化,并利用cpu-gpu的协同计算能力,进行高效率的数据挖掘,加快算法速度。再通过数据归一化、数据降维、数据去重、缺失值处理等数据预处理方法有效地提高了计算效率,同时增加了采油量、产能等预测的准确性;且通过交叉试验进一步提升算法精度。
以上所述仅为本发明的较佳实施例而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
技术特征:
技术总结
本发明提出了一种基于Spark的油气开采大数据的数据挖掘方法,其包括数据预处理模块、模型训练和模型应用模块,包括如下步骤:数据预处理,通过数据预处理模块对数据进行预处理;模型训练,进行相应算法的训练,得到最终模型;模型应用,利用训练好的模型进行分析与预测;结果展示,将得到的结果展示给用户。建立大数据挖掘分析和知识发现模型框架,建立通用的大数据分析模式,以支持油气开采大数据的知识挖掘。基于Spark的油气开采大数据的数据挖掘方法,将数据挖掘方法和油气开采大数据相结合,通过Spark来进行算法并行化,并利用CPU‑GPU的协同计算能力,进行高效率的数据挖掘,加快算法速度。
技术研发人员:张卫山;仵海云
受保护的技术使用者:中国石油大学(华东)
技术研发日:2018.11.20
技术公布日:2019.04.05
- 还没有人留言评论。精彩留言会获得点赞!