用户偏好趋势挖掘方法与流程
本发明涉及计算机领域,尤其涉及一种用户偏好趋势挖掘方法。
背景技术:
目前的大多通过调查表、问卷等方式获取数据样本,对数据进行分析,得出用户偏好趋势。
这种方法,调查数据获取需要耗费大量的人力成本和时间成本,效率有待提高。
技术实现要素:
本发明实施例提供一种用户偏好趋势挖掘方法,能够更快速从评论数据中进行产品属性分类,挖掘用户偏好趋势。
本发明实施例采用如下技术方案:
一种用户偏好趋势挖掘方法,包括:
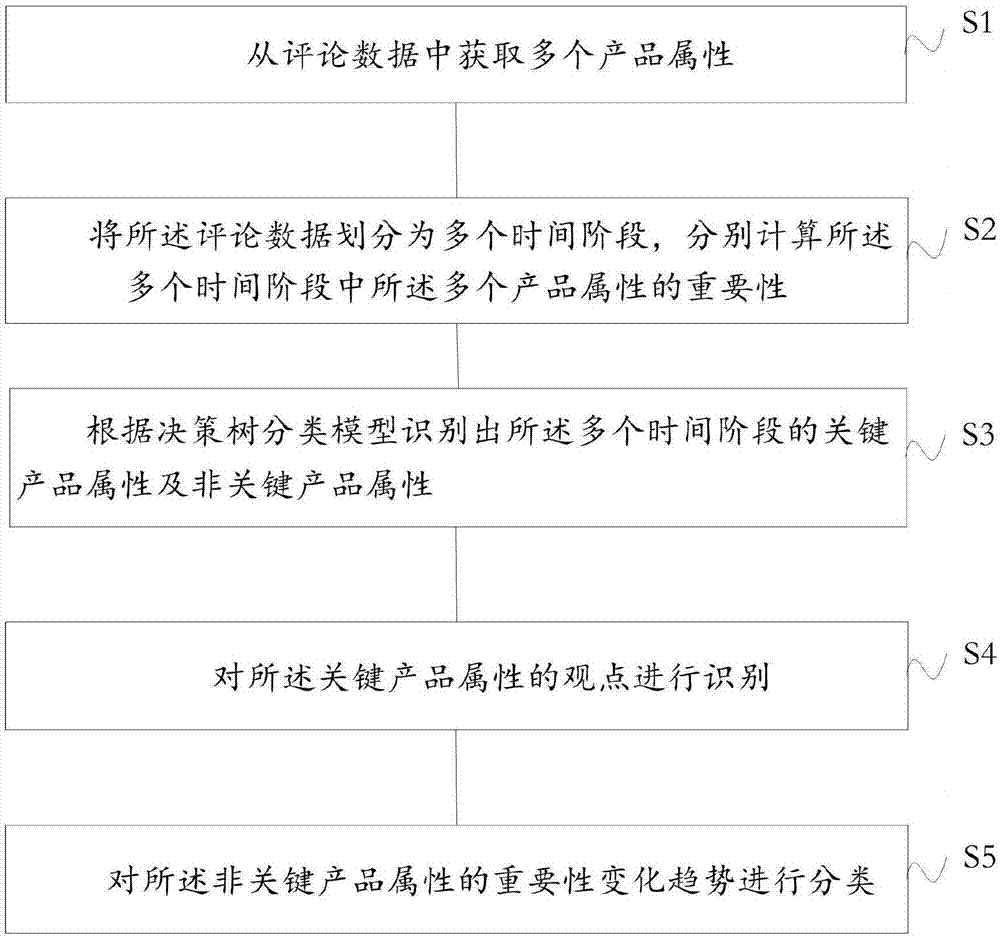
s1、从评论数据中获取多个产品属性;
s2、将所述评论数据划分为多个时间阶段,分别计算所述多个时间阶段中所述多个产品属性的重要性;
s3、根据决策树分类模型识别出所述多个时间阶段的关键产品属性及非关键产品属性;
s4、对所述关键产品属性的观点进行识别;
s5、对所述非关键产品属性的重要性变化趋势进行分类。
本发明实施例提供的用户偏好趋势挖掘方法,从评论数据中获取多个产品属性,将评论数据划分为多个时间阶段,分别计算多个时间阶段中多个产品属性的重要性,识别出关键产品属性及非关键产品属性,对关键产品属性进行观点识别,对非关键产品属性进行分类,从而快速实现从评论数据中进行产品属性分类,挖掘用户偏好趋势。
应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本公开。
附图说明
此处的附图被并入说明书中并构成本说明书的一部分,示出了符合本发明的实施例,并与说明书一起用于解释本发明的原理。
图1a为本发明实施例示出的用户偏好趋势挖掘方法流程图。
图1b为本发明实施例示出的用户偏好趋势挖掘系统示意图。
图2为本发明实施例示出的汽车产品的口碑评论示意图。
图3为本发明实施例示出的产品属性的正负面情感分布示意图。
图4为本发明实施例示出的客户打分分布示意图。
图5为本发明实施例示出的产品属性的重要性测量及预测示意图。
图6为本发明实施例示出的生成的决策树示意图。
具体实施方式
这里将详细地对示例性实施例进行说明,其示例表示在附图中。下面的描述涉及附图时,除非另有表示,不同附图中的相同数字表示相同或相似的要素。以下示例性实施例中所描述的实施方式并不代表与本发明相一致的所有实施方式。相反,它们仅是与如所附权利要求书中所详述的、本发明的一些方面相一致的装置和方法的例子。
本发明实施例利用在线评论替代调研数据,提出了一种客户偏好趋势挖掘方法来预测产品设计趋势。通过信息增益方法测量产品属性对客户满意的重要性,并基于时间序列分析预测下一时间节点产品属性的重要性;通过决策树模型识别出随时间变化的关键产品属性;对于非关键产品属性,根据其趋势模式分成三类:增值属性、过时属性和稳定属性。本发明实施例的属性分类有助于指导产品架构,决策在下一代产品设计中包含或排除某些产品功能。
本发明实施例提供一种用户偏好趋势挖掘方法,如图1a所示该方法包括:
s1、从评论数据中获取多个产品属性。
s2、将所述评论数据划分为多个时间阶段,分别计算所述多个时间阶段中所述多个产品属性的重要性。
s3、根据决策树分类模型识别出所述多个时间阶段的关键产品属性及非关键产品属性。
s4、对所述关键产品属性的观点进行识别。
s5、对所述非关键产品属性的重要性变化趋势进行分类。
具体的,对所述非关键产品属性,根据重要性变化规律判定其是否存在明显增长趋势或下降趋势。
具体的,多个时间阶段的关键产品属性识别出来的关键产品属性是有顺序的,在多个时间阶段的顺序变化也体现了用户偏好趋势,多个时间阶段的非关键产品属性的分类可以包括增值属性,过时属性,稳定属性。
图1b为本发明实施例提供的一种用户偏好趋势挖掘系统结构示意图,本发明实施例的用户偏好趋势挖掘方法可以应用该用户偏好趋势挖掘系统的结构实现用户偏好趋势挖掘。
具体的,主要包括客户偏好预测,关键产品属性识别以及非关键产品属性分类。从网站和论坛上获取在线评论,构建属性词典,并结合打分,通过信息增益计算,预测每个属性在各个时间阶段的重要性;运用决策树模型对产品属性进行分类,识别出关键的产品属性,并挖掘其客户观点;而对于非关键属性,运用mann-kendall方法将其分为增值属性、过时属性和稳定属性三个类别。这一过程获得的结果可以为制造企业在开发产品时应该加入何种功能提供参考。
本发明实施例的用户偏好趋势挖掘方法,从评论数据中获取多个产品属性,将评论数据划分为多个时间阶段,分别计算多个时间阶段中多个产品属性的重要性,识别出关键产品属性及非关键产品属性,对关键产品属性进行观点识别,对非关键产品属性进行分类,从而快速实现从评论数据中进行产品属性分类,挖掘用户偏好。
在一个实施例中,所述s1包括:
采用pos词性标记方法从所述评论数据中提取产品属性关联词语;
从所述产品属性关联词语中去除非属性后,进行同义词合并,生成产品属性词典;
依据生成的属性词典,识别所述评论数据中每条评论提及的产品属性,得到所述多个产品属性。
例如,利用预先设置的pos词性分析方法,获取出现次数超过预先设置的次数阈值的名词或者名词短语,得到目标产品的产品术语候选集;通过众包形式剔除所述产品术语候选集中的非产品属性术语;依据同义词库合并剔除非产品属性术语后的产品术语候选集中的产品属性术语,得到产品属性术语库。
其中,s1中的评论数据可以根据不同的场景进行构建。例如,在一个示例中,评论数据收集时选择11款国产suv品牌,包括:传祺gs4,荣威rx5,长安cs75,远景suv,哈弗h6,比亚迪宋,博越,宝骏560,瑞虎5,瑞虎7,帝豪gs。例如,评论数据集可以为图2所示的口碑评论。
相应的,s2中将评论数据集根据时间先后分成13个时间阶段。
在一个实施例中,所述s2包括:
将在所述评论数据包含的满意评论中的产品属性的情感类别标示为正面,将在所述评论数据包含的不满意评论中的产品属性的情感类别标示为负面,得到所述多个产品属性情感类别;
获取用户打分评价,并将所述用户打分评价划分为高、中、低三个类别;
根据所述打分评价的类别及所述多个产品属性情感类别,确定所述多个产品属性中每个产品属性对于客户满意的影响。
具体的,可以产品打分作为类变量,作为客户满意程度。为方便计算,可以将产品打分划分为高、中、低三个类别。结合属性情感(正面、负面)以及客户打分(高、中、低),运用信息增益方法计算每个产品属性对于客户满意的影响大小。
例如,上述示例中,通过产品属性提取,识别出24个产品属性,统计每个产品属性正负面分布,结果如图3所示。获取的打分分布如图4所示,由于5分和4分的评论远多于其他打分,为确保类变量分布的均衡,本案例研究将5分设定为高分,4分设定为中等分,3分及以下打分为低分。
在一个实施例中,所述根据所述打分评价的类别及所述产品属性情感类别,确定每个所述产品属性对于客户满意的影响包括:
初始信息熵如下:
其中,p(cr)表示所述评论数据集s中的类变量cr的概率,k表示类变量值的个数,根据属性变量的取值划分为n个子数据集,从所述多个产品属性选取一个特定的属性,信息熵是该特定属性的每个唯一值的信息熵的总和,如下所示:
其中,sj表示训练数据s的子集,包含属性的互斥结果值,id3决策树分类算法使用信息增益作为属性选择的度量,属性提供的类变量不确定性的减少量,属性的entropya(s)越低,增益gain(a)越高,如下公式:
gain(a)=entropy(s)-entropya(s)。
其中,信息增益能衡量产品属性对客户满意的影响程度,即产品属性重要性。计算信息增益时,先计算初始信息熵,和确定属性之后的信息熵,两者相减即信息增益。
在一个实施例中,所述多个时间阶段包括下一时间段,所述分别计算所述多个时间阶段中所述多个产品属性的重要性包括:
预测下一时间阶段产品属性的重要性。
本实施例中,时间序列分析模型,可以根据前面多个阶段的重要性,预测下一阶段的重要性。本实施例的趋势挖掘包括:各个属性当前时间是否为关键产品属性;若不是关键产品属性,根据之前阶段重要性变化,识别是否有明显增长趋势或下降趋势;并且可以预测每个产品属性下一个阶段的重要性。
在一个实施例中,所述预测下一时间阶段产品属性的重要性包括:
采用holt-winters指数平滑模型预测所述下一时间阶段的客户偏好,根据加权平均及时间序列中数据趋势和季节性成分,将具有线性趋势、季节变动和随机变动的时间序列进行分解,并结合指数平滑法对属性重要性进行第k步预测,分别对长期趋势、趋势增量和季节变动做出估计,k步提前预测模型可以定义为:
yt(k)=lt+ktt+it-s+k
其中,水平成分lt可表示为:
lt=α(yt-it-s)+(1-α)(lt-1+tt-1)
趋势成分tt可表示为:
tt=γ(lt-lt-1)+(1-γ)tt-1
季节性成分it可表示为:
it=δ(yt-lt)+(1-δ)it-s
其中,数据分割成多个时间段,每个时间阶段的产品属性重要性,组成时间序列。
本实施例,根据当前各个阶段产品属性重要性,预测未来+k时间阶段的产品属性重要性。
其中,yt表示近期时间段t时刻的数据点,yt(k)表示超过yt的第k节时间段的预测值,有yt(k)=yt+k,s表示季节性频率,平滑参数α,γ和δ都在[0,1]范围内,并通过最小化前一个时间段步长的误差平方和来估计。
例如,上述示例中,计算各阶段的产品属性的信息增益,观察其变化趋势,并预测下阶段的产品属性重要性。部分产品属性结果如图5所示。
本发明实施例中预测下阶段的重要性,可以对关键产品属性的变化提供预警,还可以直接加入mann-kendall检测用于非关键产品属性的分类。
在一个实施例中,所述s3包括:
根据产品属性的信息增益,根据决策树模型迭代生成分类规则,出现在所述分类规则中的产品属性为关键产品属性,未出现在所述分类规则中的产品属性为非关键产品属性。
本实施例,选择信息增益最大的产品属性进行划分,然后针对划分的数据集继续分割。例如,上述示例中根据最后时间阶段数据,生成决策树分类规则,结果如图6所示。
在一个实施例中,所述s4中对所述关键产品属性的观点进行识别包括:
根据点互信息(pmi)挖掘所述多个属性的观点,pmi可以用于衡量两个变量之间的相关性,计算公式如下:
其中,p(a,o)表示产品属性与属性观点o共同出现的概率,p(a)表示产品属性出现的概率,p(o)表示观点o出现的概率;
根据pmi值的大小从所述评论数据中识别出所述多个产品属性中每个产品属性的客户观点。
本实施例多个时间阶段的关键产品属性识别,识别出来的关键产品属性是有顺序的,在多个时间阶段的顺序变化也体现了用户偏好趋势。
在一个实施例中,所述s5包括:
根据mann-kendall检测判断属性重要性变化趋势,将所述多个产品属性分为增值属性、过时属性和稳定属性。
在一个实施例中,所述根据mann-kendall检测判断属性重要性变化趋势,将所述多个产品属性分为增值属性、过时属性和稳定属性包括:
统计量s计算如下:
其中,n表示时间序列数据点的总数,xj代表前一时刻数据得到的信息增益,xi代表当前数据得到的信息增益;
标准化统计量s,按照如下公式:
统计量z服从标准正态分布,如果p值小于显著性水平(α=0.05)则存在变化趋势,如果z为负值则为增值属性,如果z为正值则为过时属性,如果p值大于显著性水平则为稳定属性。
例如,上述示例中根据mann-kendall趋势检测将非关键产品属性分类结果如表1所示。
表1
本发明实施例的用户偏好趋势挖掘方法,从评论数据中获取多个产品属性,将评论数据划分为多个时间阶段,分别计算多个时间阶段中多个产品属性的重要性,从多个时间阶段中多个产品属性识别出关键产品属性及非关键产品属性,对关键产品属性进行观点识别,对非关键产品属性进行分类,从而快速实现从评论数据中进行产品属性分类,挖掘用户偏好趋势。
本发明实施例产品属性的重要性测量及预测、识别关键产品属性及其观点、对非关键产品属性分类,采用的在线评论,样本量大,获取成本低,更新速度快,可以准确、及时、低成本地获取客户需求和偏好,有助于制造企业洞察市场变化,并且指导产品架构,包括应该重点加强的产品属性和避免过度投入的产品属性,以最大化满足市场客户的需求和偏好。
以上已经描述了本发明的各实施例,上述说明是示例性的,并非穷尽性的,并且也不限于所披露的各实施例。在不偏离所说明的各实施例的范围和精神的情况下,对于本技术领域的普通技术人员来说许多修改和变更都是显而易见的。本文中所用术语的选择,旨在最好地解释各实施例的原理、实际应用或对市场中的技术的改进,或者使本技术领域的其它普通技术人员能理解本文披露的各实施例。
本领域技术人员在考虑说明书及实践这里公开的公开后,将容易想到本公开的其它实施方案。本申请旨在涵盖本公开的任何变型、用途或者适应性变化,这些变型、用途或者适应性变化遵循本公开的一般性原理并包括本公开未公开的本技术领域中的公知常识或惯用技术手段。
- 还没有人留言评论。精彩留言会获得点赞!