一种基于大数据的物流供应链需求预测方法与流程
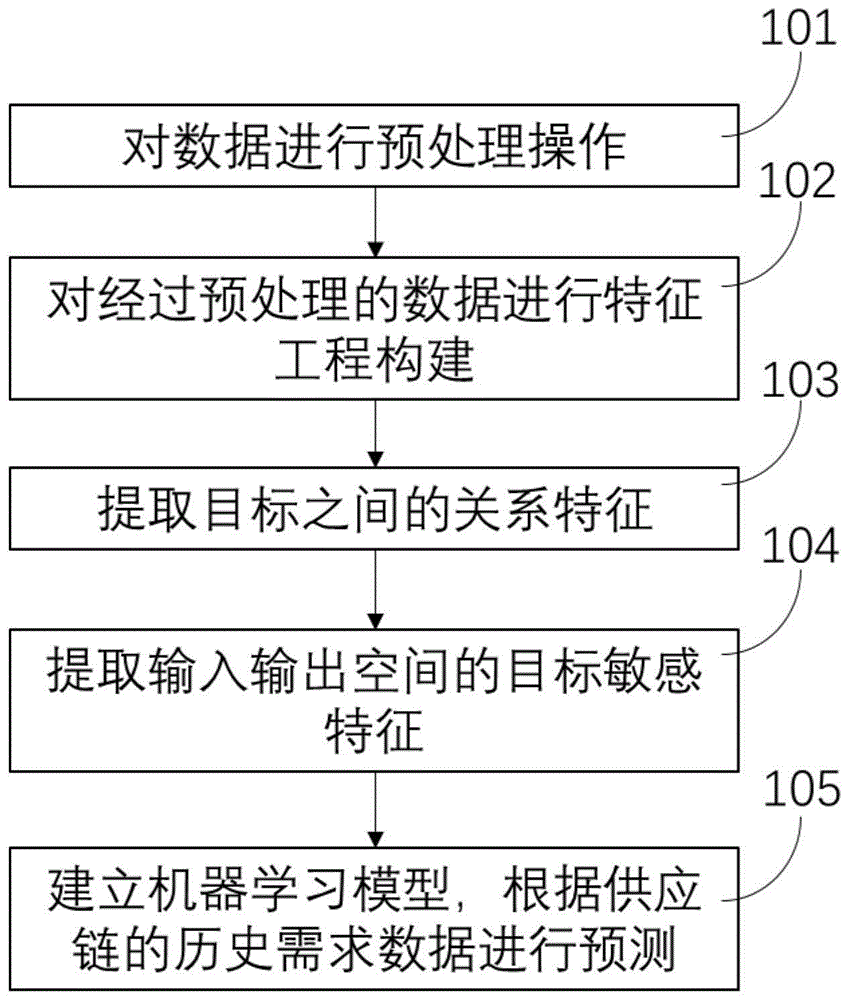
本发明属于机器学习、多目标回归及大数据处理
技术领域:
,尤其基于大数据的物流供应链需求预测方法。
背景技术:
:随着经济全球化和知识经济时代的到来,高新技术的迅猛发展,商品结构越来越复杂,寿命周期越来越短,用户需求的不确定性和个性化程度增加,市场环境竞争日益激烈,人们的需求日益多样化,市场环境由简单静态的卖方市场逐步变成复杂动态的买房市场,供应链管理应运而生。企业管理如何适应新的竞争环境,已成为广大管理理论研究者及实际工作者关注的焦点。需求预测是供应链管理中需求管理的内容,是供应链运作的源头,也是供应链优化的起点。如果预测需求与实际需求误差过大,将会对供应链运作带来巨大的影响,增加供应链运作成本,降低客户满意度。另一方面,提升需求预测准确性,则可以大大降低供应链运作成本,提升服务质量,使供应链成员企业从中受益。现今的市场环境使企业正在面临无止境的计划和决策,对未来需求的预测构成了供应链管理中战略和规划性决策的基础。所有拉动流程又都是根据市场需求的反应来运行的,在上述两种情况下,供应链管理者采用的第一个步骤就是预测顾客未来的需求量。再好的商品,如果不能准确的预测到实际的市场需求,就是造成供应的不足或者过剩,进而影响到企业的库存水平和运作成本。现有的方法通过简单的将历史数据处理后作为训练数据构建模型或者基于历史数据构建时间序列的单目标回归模型,来预测商家客流量,由于没有考虑到多个目标之间对供应链需求行为的影响综合程度,这些方法的预测精度并不是很理想。本专利针对这些方面所做的包括使用层次聚类提取目标之间的关系特征,为每个预测目标提取输入输出空间的目标敏感特征等工作大大提高了针对这一供应链需求预测的精度。同时,需求的预测是驱动整个供应链的重要因素,准确的需求预测可以降低供应链企业所面临的市场不确定性,为决策提供科学依据,可以说,准确的预测使供应链企业追求的共同目标。技术实现要素:本发明提供一种基于大数据的物流供应链需求预测方法对供应链中商品销量数据和供应链信息数据进行分析,旨在有效地预测商家在未来的销量,进而促使供应链企业能够在正确的时间给用户最有效的服务,具有一定的实现意义。本发明的技术方案如下:一种基于大数据的物流供应链需求预测方法,其包括以下步骤:101、对供应链的历史需求数据进行包括异常值在内的预处理操作;102、对经过预处理的数据进行特征工程构建;特征工程构建主要包括:历史需求数据特征、时间特征。103、采用层次聚类得到目标之间的关系特征;104、对含有目标之间的关系的数据,得到输入输出空间的目标敏感特征;105、建立机器学习模型,根据供应链的历史需求数据进行预测。进一步的,所述步骤101对供应链需求历史销量数据预处理操作,包括以下步骤:s1011、将历史数据分为训练集和测试集两部分,统计历史数据中供应链需求历史数据的缺失值个数,并统计供应链各个商品的缺失比例,对于缺失比例低于70%的商品,使用该商家对应星期几的销量均值填充;若缺失比例超过70%,则保留距离目标预测日期最近2周的销量,其他全部删除。进一步的,当保留距离目标预测日期最近2周的销量有缺失时,则使用最近2周均值填充。进一步的,所述步骤102对经过预处理的数据构建特征工程,包括以下步骤:s1021、根据供应链历史需求数据提取商品特征和商品促销行为特征,并添加包括节假日、周末、寒暑假期在内的影响消费的特征;s1022、根据供应链中商品类目进行独热编码,根据商品所属的类目,统计出每个类目所拥有的商品数;进一步的,所述步骤103采用层次聚类提取目标之间的关系特征,具体包括:1)对样本进行层次聚类,如果节点样本数小于阈值maxleaf=20,则停止过程,否则继续,直至完成一棵层次二叉树;2)对除叶子节点外的所有节点添加元分类器hθ(·);3)使用梯度下降算法更新hθ(·)θj:=θj+min(λj,α(yj(i)-hθ(xj(i))))xj(i)其中yj(i)表示样本真实目标,xj(i)表示样本特征,初始梯度θj为0向量,更新步长α为0.01,λj表示对更新梯度的限制并且限制为0.1;4)取得包括测试样本在内的所有样本所属的叶子节点编号,作为目标之间的关系特征来扩展特征。进一步的,所述步骤104对每一个预测目标提取输入输出空间的目标敏感特征来处理输入空间和输出空间的关系,具体为:1)使用分类回归树算法对预测目标j生成一个相似度矩阵mij,其中下标i表示第i次迭代;2)对1)进行迭代,maxiter=500或者下降errori小于10则提前停止,maxiter表示最大迭代次数,为目标j生成矩阵其中wi表示累加矩阵的权重,errori是目标均方损失误差。3)将标签之间的相关性也考虑到迭代结果中,生成相似度矩阵其中wcjk是目标j与目标k之间的余弦相似度。4)对cmj进行k-mediods聚类,得到关于目标j的k个聚类中心pk,然后通过公式xtsf←[cos(d,p1),...,cos(d,pk)]cos(d,p1)表示数据集中每一个样本和聚类中心pk的余弦相似度,xtsf←[cos(d,p1),...,cos(d,pk)]表示得到的相似度即为目标敏感特征。其中d为数据集,pk为得到的聚类中心。进一步的,所述步骤105建立机器学习模型,根据供应链的历史需求数据进行预测,具体包括:对原始特征进行扩展,将目标之间的关系特征和输入输出空间的目标敏感特征附加到原始特征上面,形成新的训练集,然后使用xgboost训练,得到最终预测结果。本发明的优点及有益效果如下:本发明提出了一种基于大数据的物流供应链需求预测方法对物流供应链需求进行预测,同时本发明还涉及到了历史数据的预处理、特征工程的构建、提取目标之间的关系特征、提取输入输出空间的目标敏感特征,通过一系列的步骤和算法得到用户的消费模型。本方法首先通过一个层次聚类算法来提取目标之间在输出空间中的关系特征。层次聚类之后,本方法得到一个二叉树中叶子节点编号,我们认为样本有相似的特点应该被分配到相同的叶子节点,然后这些叶子节点标号作为扩展特征追加到特征空间中。在扩展之后的特征空间中,我们为每一个目标学习一个关联性相似度矩阵,作为聚类算法中衡量距离的指标,得到目标敏感特征并且追加到特征空间中。最后,为每个目标在扩展之后的特征空间中建立模型。·通过学习目标敏感特征,本方法可以灵活的处理复杂的输入输出关系。·本方法在学习过程中为每个目标提取目标敏感特征,可以非常显著的提升预测准确度。·本方法不仅考虑了目标敏感特征并且还同时在学习过程中考虑目标之间的关联性。附图说明图1是本发明提供优选实施例一种基于大数据的物流供应链需求预测的流程图;图2为实施例中商品每天销量统计图;图3为实施例中提取目标之间关系特征的层次聚类说明图;图4为实施例中提取输入输出空间的目标相似度矩阵说明图;图5为实施例中每个目标生成敏感特征说明图。具体实施方式下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、详细地描述。所描述的实施例仅仅是本发明的一部分实施例。本发明解决上述技术问题的技术方案是:实施例一为进一步阐述本发明方案,特以2017年3月1日到2018年3月16日供应链企业历史需求流量记录以及各个商品的信息、促销活动情况作为历史数据,来预测2018年5月1日,5月8日,5月15日,5月22日,5月29日起5周的商品销量为例,对本技术方案进行详尽阐述。获取的信息是商品在用户中的表现数据(点击、加购、收藏、购买次数)、商品信息、商品销售数据(实际售价、吊牌价)、商品促销价格表、供应链企业活动时间表,预测供应链在未来5周每周的需求量。因为该问题存在多个预测目标,这是典型的多目标回归问题。图1为本实施例提供的一种基于大数据的物流供应链需求预测方法流程图;步骤1:收集商品在用户的表现数据,包含点击,加购,收藏等数据。fieldtypedescriptiondata_datedatetime时间yyyymmddgoods_idstring商品idgoods_clickint商品点击次数cart_clickint商品加购次数favorites_clickint商品收藏次数sales_uvint商品购买人数onsale_daysint在售天数表1商品在用户的表现数据收集商品信息,包含类目层级,季节属性,品牌id。fieldtypedescriptiongoods_idstring商品idcat_level1_idstring一级类目idcat_level2_idstring二级类目idcat_level3_idstring三级类目idcat_level4_idstring四级类目idcat_level5_idstring五级类目idgoods_seasonint商品季节属性brand_idstring品牌id表2商品信息收集商品销售数据,包含每日商品销量,平均价格,吊牌价格。表3商品销售数据收集商品促销价格表,包含商品标价,促销价,促销日期。fieldtypedescriptiondata_datedatetime日期yyyymmddgoods_idstring商品idshop_pricedouble商品标价promote_pricedouble商品促销价promote_start_timedatetime促销开始时间promote_end_timedatetime促销结束时间表4商品促销价格表收集平台活动时间表,包含活动类型,节奏类型。fieldtypedescriptiondata_datedatetime日期yyyymmddmarketingstring活动类型idplanstring活动节奏id表4供应链企业活动时间表数据预处理包括供应链商品销量数据的处理,根据两个数据表的描述进行如下处理:步骤1:通过供应链平台获取2017年3月1日到2018年3月16日的历史商品在用户的表现数据、商品信息、商品销售数据、商品促销价格表、供应链企业活动时间表。其中,在商品销售数据中,需要对异常值进行清洗,例如删除原始数据集中商品销量突然变得很大或者很小的数据。从图2可以看出,该商品id为20001,虽然该商品的历史销量没有缺失,但从十二月底到一月底可以明显看出异常,故直接将这段时间的数据剔除;同时,部分商品的销量存在缺失值,统计历史数据中商品销量的缺失值个数,并进一步统计各个商品销量数据的缺失比例,对于缺失比例低于70%的商品,使用该商品对应星期几的销量均值填充;若缺失比例超过70%,如果距离目标预测日期最近2周的销量(如有缺失,则使用最近2周均值填充),其他全部删除。步骤2:根据记录时间把预处理后的数据划分为训练集和测试集:根据供应链商品数据的分析以及预测时间段,训练集的历史区间为2017年3月1日至2018年2月16日,标签区间为2017年2月17日至2018年3月16日,测试集的历史区间为2018年5月1日至2018年5月29每周的销量;使用商品销量的历史记录作为特征,同时整合商品自身特征(商品点击、加购、收藏、购买次数,类目信息,活动时间信息)。步骤3:因为数据在步骤2已经完成特征构建,形成能供机器学习算法使用的数据集。考虑数据集属于多目标回归,一个数据样本由一个特征向量和一个输出向量组成。我们假设在输出空间中(输出目标之间),相互关联的输出目标之间共享着一些相似的特征。我们通过对输出空间进行层次聚类来处理目标之间的相似性。我们使用层次聚类算法将所有的样本分配到叶子节点上。然后,每一个样本都可以获得一个index。这个index表示样本所属相应的叶子节点。然后我们把这个index追加到原始特征上面。1)对样本进行层次聚类,如果节点样本数小于阈值maxleaf=20,则停止过程,否则继续,直至完成一棵层次二叉树;2)对除叶子节点外的所有节点添加元分类器hθ(·);3)使用梯度下降算法更新hθ(·)θj:=θj+min(λj,α(yj(i)-hθ(xj(i))))xj(i)其中yj(i)表示样本真实目标,xj(i)表示样本特征,初始梯度θj为0向量,更新步长α为0.01,λj表示对更新梯度的限制并且限制为0.1;4)取得包括测试样本在内的所有样本所属的叶子节点编号,作为目标之间的关系特征来扩展特征。图3说明了这个层次聚类的过程。步骤4:完成了步骤3,即已经完成了提取输出目标之间的关系特征,现在对输入输出空间之间的关系进行处理。也就是说对每一个预测目标提取输入输出空间的目标敏感特征来处理输入空间和输出空间的关系,具体为:1)使用分类回归树算法对预测目标j生成一个相似度矩阵mij,其中下标i表示第i次迭代;2)对1)进行迭代,maxiter=500或者下降errori小于10则提前停止,maxiter表示最大迭代次数,为目标j生成矩阵其中wi表示累加矩阵的权重,errori是目标均方损失误差。3)将标签之间的相关性也考虑到迭代结果中,生成相似度矩阵其中wcjk是目标j与目标k之间的余弦相似度。4)对cmj进行k-mediods聚类,得到关于目标j的k个聚类中心pk,然后通过公式xtsf←[cos(d,p1),...,cos(d,pk)]cos(d,p1)表示数据集中每一个样本和聚类中心pk的余弦相似度,xtsf←[cos(d,p1),...,cos(d,pk)]表示得到的相似度即为目标敏感特征。其中d为数据集,pk为得到的聚类中心。构造目标敏感特征如图5所示。步骤5:对原始特征进行扩展,将目标之间的关系特征和输入输出空间的目标敏感特征附加到原始特征上面,形成新的训练集。然后使用xgboost训练,得到最终预测结果。以上这些实施例应理解为仅用于说明本发明而不用于限制本发明的保护范围。在阅读了本发明的记载的内容之后,技术人员可以对本发明作各种改动或修改,这些等效变化和修饰同样落入本发明权利要求所限定的范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1